 Autopsy中文使用教程(用戶版)
Autopsy中文使用教程(用戶版)關鍵字搜索模塊
它有什么作用
關鍵字搜索模塊既方便了搜索的攝取部分,也支持在攝取完成后進行手動文本搜索(請參閱臨時關鍵詞搜索)。它從正在提取的文件,其他模塊生成的選定報告以及其他模塊生成的結果中提取文本。然后,將提取的文本添加到Solr索引中,然后可以對其進行搜索。
尸檢會盡最大努力從要編制索引的文件中提取最大數量的文本。首先,索引將嘗試從受支持的文件格式中提取文本,例如純文本文件格式,MS Office文檔,PDF文件,電子郵件等。如果標準文本提取器不支持該文件,則“尸檢”將退回到字符串提取算法。未知文件格式或任意二進制文件上的字符串提取通常可以從文件中提取大量文本,通常足以為審閱者提供其他線索。字符串提取不會從加密文件中提取文本字符串。
尸檢帶有一些內置列表,這些列表定義了正則表達式,并使用戶可以搜索電話號碼,IP地址,URL和電子郵件地址。但是,啟用其中一些非常通用的列表可能會產生大量匹配,其中許多可能是假陽性。正則表達式可能需要很長時間才能完成。
將文件放入Solr索引后,可以快速搜索它們以查找特定的關鍵字,正則表達式或可以包含關鍵字和正則表達式混合的關鍵字搜索列表。可以在提取運行期間或提取結束時自動執行搜索查詢,具體取決于當前設置和提取圖像所需的時間。
有關指定正則表達式和其他類型的搜索的更多詳細信息,請參閱臨時關鍵字搜索。
關鍵字搜索配置對話框
關鍵字搜索配置對話框具有三個選項卡,每個選項卡都有其自己的用途:
列表標簽
列表選項卡用于創建/導入內容并將內容添加到關鍵字列表。要創建列表,請選擇“新建列表”按鈕,然后為新的關鍵字列表選擇一個名稱。創建列表后,可以向其中添加關鍵字(有關關鍵字類型的更多信息,請參見創建關鍵字)。可以將列表添加到關鍵字搜索攝取過程中;當內容添加到索引時,搜索將定期進行。
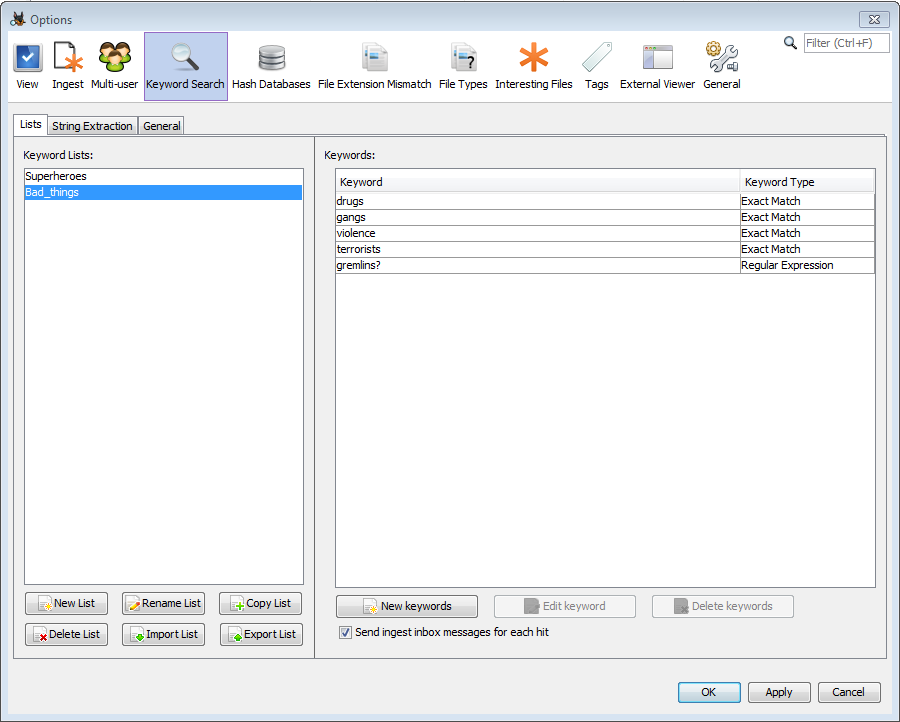
關鍵字列表可以在面板的左側找到。可以創建新列表,可以重命名,復制,導出或刪除現有列表,還可以導入列表。驗尸支持導入Encase制表符分隔的列表以及以前使用驗尸創建的列表。對于Encase列表,文件夾結構和層次結構將被忽略。當前無法導出與Encase一起使用的列表,但是可以導出列表以在尸檢用戶之間共享。
一旦選擇了關鍵字列表,該列表中的所有關鍵字將顯示在選項卡的右側。“新關鍵字”按鈕可用于將一個或多個條目添加到列表,“編輯關鍵字”和“刪除關鍵字”按鈕可更改現有條目。
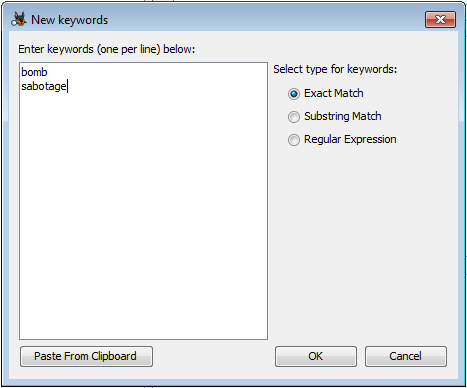
可以在對話框中輸入新條目或從剪貼板粘貼新條目。一次添加的所有條目都必須是相同的匹配類型(完全匹配,子字符串或正則表達式),但是可以多次使用該對話框將關鍵字添加到關鍵字列表中。有關每種關鍵字類型的說明,請參閱“ 創建關鍵字”部分。
在“關鍵字”列表下是用于為每個匹配發送摘要收件箱消息的選項。如果啟用此功能,則可以通過“關鍵字列表”按鈕旁邊的黃色三角形訪問該列表的每個關鍵字命中。此功能使您可以快速查看最重要的關鍵字搜索結果。

字符串提取選項卡
字符串提取設置定義了如何從無法正常提取文本的文件中提取字符串,因為不支持其文件格式。任意二進制文件(例如頁面文件)和代表已刪除文件的未分配空間大塊就是這種情況。當我們從二進制文件中提取字符串時,我們需要根據可能的文本編碼和所用腳本/語言的不同,將字節序列解釋為文本。在許多情況下,我們無法預先知道文本的特定編碼/語言是什么。但是,如果研究人員正在尋找特定的語言,這將有所幫助,因為通過選擇較少的語言,索引性能將得到改善,并且數量會有所增加。誤報的數量將減少。
默認設置是僅搜索編碼為UTF8或UTF16的英語字符串。此設置具有最佳性能(最短的攝取時間)。用戶還可以首先使用String Viewer并嘗試不同的腳本/語言設置,并查看對于與調查相關的文本類型,哪些設置可以提供令人滿意的結果。然后,可以將適用于調查的相同設置應用于關鍵字搜索攝取。

還有一個啟用光學字符識別(OCR)的設置。如果啟用,則可以從支持的圖像類型中提取文本。啟用此功能將使關鍵字搜索模塊花費更長的時間才能運行,結果也不盡人意。下面顯示了一個包含文本的示例圖像:

在啟用了OCR選項的情況下運行關鍵字搜索模塊時,“索引文本”選項卡顯示結果。如果我們要使用“關鍵字搜索”來查找“取證”一詞,則此文件將是一個匹配項。
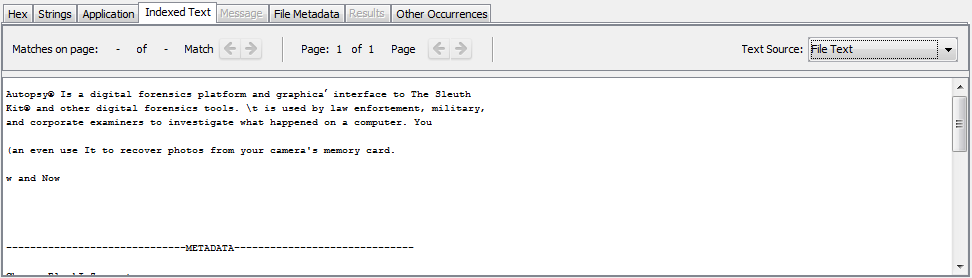
默認情況下,OCR僅配置為英文文本。它的配置取決于存在于尸檢可以理解的位置的語言文件(稱為“ traineddata”文件)。為了增加對更多語言的支持,您將需要下載其他“ traineddata”并將其移至正確的位置。以下步驟為您分解了此過程:
- 導航至https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
- 在標題為“版本4.00的數據文件(2016年11月29日)”的部分下,您將找到一個表,其中包含代表每種語言的文件。這些文件的擴展名為“ .traineddata”。
- 要下載所需的語言,請單擊表格最右邊一欄中的鏈接。您可以下載任意數量的文件。請注意,您只能從此表中進行選擇。不保證其他任何部分下的語言文件也可以在尸檢中使用。
- 下載語言文件后,只需將其拖放到用戶文件夾下的“ AppData \ Roaming \ autopsy \ ocr_language_packs”文件夾中即可。
- 啟動尸檢,您將準備就緒。如果正在運行“尸檢”,則需要重新啟動才能生效。
現在,在“關鍵字搜索設置”中啟用OCR時,將支持語言文件。
常規設置選項卡
NIST NSRL支持
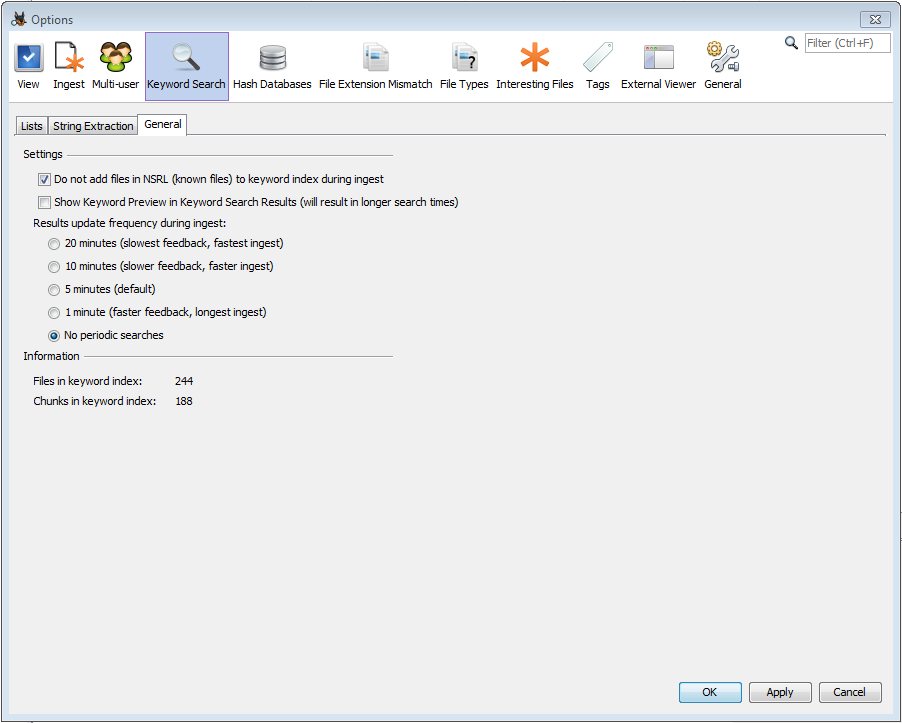
哈希查找接收服務可以配置為使用NIST NSRL已知文件的哈希集。關鍵字搜索高級配置對話框的“常規”選項卡包含一個選項,用于跳過關鍵字索引,并搜索先前標記為“已知”和不感興趣的文件。選擇此選項可以大大減小索引的大小并改善提取性能。在大多數情況下,用戶不需要用關鍵字搜索“已知”文件。
攝取期間的結果更新頻率
為了控制攝取期間執行搜索的頻率,用戶可以調整關鍵字搜索高級配置對話框“常規”選項卡中可用的時間設置。將分鐘數設置為較低將導致更頻繁地執行索引更新和搜索,并且用戶將能夠實時查看更多結果。但是,更頻繁的更新可能會影響總體性能,尤其是在低端系統上,并且可能會延長提取完成所需的總體時間。
也可以選擇不進行定期搜索。這將加快攝取速度。一旦完成整個關鍵字搜索索引,選擇此選項的用戶便可以運行其關鍵字搜索。
使用模塊
用戶可以在任何時候手動執行搜索查詢,只要有一些文件已被索引并且可以進行搜索。自然,在完成索引之前進行搜索將僅搜索已編譯的索引。
見攝取的攝取上一般的更多信息。
索引中一旦包含文件,便可以隨時使用“ 臨時關鍵字搜索”來手動搜索。
攝取設置
關鍵字搜索模塊的提取設置允許用戶啟用或禁用特定的內置搜索表達式,電話號碼,IP地址,電子郵件地址和URL。使用“高級”按鈕(如下所示),可以添加自定義關鍵字組。

看到結果
關鍵字搜索模塊將保存搜索結果,無論搜索是由攝取過程執行還是由用戶手動執行。保存的結果在左側面板的目錄樹中可用。
關鍵字結果將顯示在“關鍵字匹配”下的樹中。每個關鍵字搜索詞將顯示匹配項的數量,并且可以擴展以顯示匹配項。從這里,單擊其中一個匹配項,將在屏幕右側顯示文件列表。選擇一個文件,然后轉到“索引文本”選項卡以查看文件中匹配項的確切位置。


推薦文章: