Kubernetes 中 CPU 調度管理的現狀與限制
CPU 管理的現狀與限制
kubelet 將系統的 CPU 分為 2 個資源池:
- 獨占池(exclusive pool):同時只有一個任務能夠分配到 CPU
- 共享池(shared pool):多個進程分配到 CPU
原生的 K8s cpuManager 目前只提供靜態的 CPU 分配策略。當 K8s 創建一個 pod 后,pod 會被分類為一個 QoS:
- Guaranteed
- Burstable
- BestEffort
并且 kubelet 允許管理員通過 –reserved-cpus 指定保留的 CPU 提供給系統進程或者 kube 守護進程(kubelet, npd)。保留的這部分資源主要提供給系統進程使用。可以作為共享池分配給非 Guaranteed 的 pod 容器。但是 Guaranteed 類 pod 無法分配這些 cpus。
目前 K8s 的節點側依據 cpuManager 的分配策略來分配 numa node 的 cpuset,能夠做到:
- 容器被分配到一個 numa node 上。
- 容器被分配到一組共享的 numa node 上。
cpuManager 當前的限制:
- 最大 numa node 數不能大于 8,防止狀態爆炸(state explosion)。
- 策略只支持靜態分配 cpuset,未來會支持在容器生命周期內動態調整 cpuset。
- 調度器不感知節點上的拓撲信息。下文會介紹相應的提案。
- 對于線程布局(thread placement)的應用,防止物理核的共享和鄰居干擾。CPU manager 當前不支持。下文有介紹相應的提案。
相關 issues
1、針對處理器的異構特征,用戶可以指定服務所需要的硬件類別[1]。
異構計算的異構資源有著不同額性能和特征和多級。比如 Intel 11th gen,性能內核(Performance-cores, P-cores)是高性能內核,效率內核(Efficiency-cores,)是性能功耗比更優的內核。
ref:https://www.intel.cn/content/www/cn/zh/gaming/resources/how-hybrid-design-works.html
這個 issue 描述的用戶場景是,可以將 E-cores 分配給守護進程或者后臺任務,將 P-cores 分配給性能要求更高的應用服務。支持這種場景需要對 CPU 進行分組分配。但是 issue 具體的方案討論。因為底層硬件差異,目前無法做到通用。目前 K8s 層需要設計重構方案。
當前相關需求的落地方案都是在 K8s 上使用擴展資源的方式來標識不同的異構資源。這種方法會產生對于原生 CPU/ 內存資源的重復統計。
2、topologyManager 的 best-effort 策略優化[2]。
issue 提到 best-effort 的策略,迭代每個 provider hint,依據位與運算聚合結果。如果最后的結果為 not preferred,topologyManager 應該盡力依據資源的傾向做到 preferred 的選擇。這個想法的初衷是因為 CPU 資源相比其他外設的 numa 親和更重要。當多個 provider hint 相互沖突時,如果 CPU 有 preferred 的單 numa node 分配結果,應該先滿足 CPU 的分配結果。比如 CPU 返回的結果為 [‘10’ preferred, ‘11’ non-preferred]),一個設備返回的結果 [‘01’, preferred]。topologyManager 應該使用 '10’ preferred 作為最后的結果,而不是合并之后的 '01’ not preferred。
而社區對于這種的調度邏輯的改變,建議是創建新的 policy 以提供類似調度器優選(scoring)的算法系統。
3、嚴格的 kubelet 預留資源[3]。
希望提供新的參數 StrictCPUReservation,表示嚴格的預留資源,DefaultCPUSet 列表會移除 ReservedSystemCPUs.
4、bug:釋放 init container 的資源時,釋放了重新分配給 main container 的資源[4]。
這個 issue 已經修復:在 RemoveContainer 階段,排除還在使用的容器的 cpuset。剩下的 cpuset 才可以釋放回 DefaultCPUSet。
5、支持原地垂直擴展:針對已經部署到節點的 pod 實例,通過 resize 請求,修改 pod 的資源量[5]。
原地垂直擴展的意思是:當業務調整服務的資源時,不需要重啟容器。
原地垂直擴容是個復雜的功能,這里大致介紹設計思路。詳細實現可以看 PR: https://github.com/kubernetes/kubernetes/pull/102884。
kube-scheduler 依然使用 pod 的 Spec…Resources.Requests 來進行調度。依據 pod 的 Status.Resize 狀態,判斷緩存中 node 已經分配的資源量。
- Status.Resize = “InProgress” or “Infeasible”,依據 Status…ResourcesAllocated(已經分配的值)統計資源量。
- Status.Resize = “Proposed”,依據 Spec…Resources.Requests(新修改的值) 和 Status…ResourcesAllocated(已經分配的值,如果 resize 合適,kubelet 也會將新 requests 更新這個屬性),取兩者的最大值。
kubelet 側的核心在 admit 階段來判斷剩余資源是否滿足 resize。而具體 resize 是否需要容器重啟,需要依據 container runtime 來判斷。所以這個 resize 功能其實是盡力型。通過 ResizePolicy 字段來判斷:

還值得注意點是當前 PR 主要是在 kata、docker 上支持原地重啟,windows 容器還未支持。
有趣的社區提案
調度器拓撲感知調度
Redhat 將他們實現的一套拓撲調度[6]的方案貢獻到社區:https://github.com/kubernetes/enhancements/pull/2787
擴展 cpuManager 防止理核不在容器間共享:
kep:https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2625-cpumanager-policies-thread-placement
防止同一個物理核的虛擬分配帶來的干擾。
設計文檔里引入新參數 cpumanager-policy-options:full-pcpus-only,期望分配獨占一個物理 CPU。當指定了 full-pcpus-only 參數以及 static 策略時,cpuManager 會在分配 cpusets 會額外檢查,確保分配 CPU 的時候是分配整個物理核。從而確保容器在物理核上的競爭。
具體例子比如,一個容器申請了 5 個獨占核(虛擬核),CPU 0-4 都分配個了服務容器。CPU 5 也被鎖住不能再分配給容器。因為 CPU 5 和 CPU 4 同在一個物理核上。

增加 cpuMananger 跨 numa 分散策略:distribute-cpus-across-numa[7]
full-pcpus-only:上面已經描述:full-pcpus-only確保容器分配的 CPU 物理核獨占 。distribute-cpus-across-numa:跨 numa node 均勻分配容器。
開啟 distribute-cpus-across-numa 時,當容器需要分配跨 numa node 時,statie policy 會跨 numa node 平均分配 CPU。非開啟的默認邏輯是優選填滿一個 numa node。防止跨 numa node 分配時,在一個余量最小的 numa node 上分配。從整個應用性能考慮,性能瓶頸收到落在剩余資源較少的 numa node 上性能最差的 worker(process?)。這個選項能夠提供整體性能。
接下來介紹幾個社區 slack 里討論的幾個提案:
- CPU Manager Plugin Model
- Node Resource Interface
- Dynamic resource allocation
CPU Manager Plugin Model
CPU Manager Plugin Model:kubelet cpuManager 的插件框架。在不改動資源管理主流程前提下,支持不同的 CPU 分配場景。依據業務需求,實現更細粒度的控制 cpuset。
kubelet 在 pod 綁定成功之后,會將 pod 壓入本地調度隊列里,依次執行 pod 的 cpuset 的調度流程。調度流程本質上借鑒了 kube-scheduler 的調度框架。
插件可擴展點:
一個插件可以實現 1 個或多個可擴展點:
- Sort:將調度到節點上的 pod 排序處理。例如依據 pod QoS 判定的優先順序。
- Filter:過濾無法分配給 pod 的 CPU。
- PostFilter:當沒有合適的 CPU 時,可以通過 PostFilter 進行預處理,然后將 pod 重新進行處理。
- PreScore:對于單個 CPU 評分,提供給后面流程來判定分配組合的優先級。
- Select:依據 PreScore 的結果選擇一個 CPU 組合的最優解,最優解的結構是一組 CPU。
- Score:依據 Select 的結果——CPU 分配組合評分。
- Allocate:在分配 cpuset 之后,調用該插件。
- Deallocate:在 PostFilter 之后,釋放 CPU 的分配。
三個評分插件的區別:
- PreScore:返回以 CPU 為 key,value 為單個 CPU 對于 pod 容器的親和程度。
- Select:依據插件的領域知識(比如同一個 numa 的 CPU 分配結構聚合),將 CPU 組合的分數聚合。返回是一組最佳 CPU。
- Score:依據所有的 CPU 組合,評分分配組合依據插件強約束邏輯。
方案提出了兩種擴展插件的方案。當前在 kubelet 的容器管理中,topologyManager 主要完成下列事項:
- 調度用 hintProvider,獲得各個子管理域的可分配情況
- 編排整體的拓撲分配決策
- 提供“scopes”和 policies 參數來影響整體策略
其他子管理域的子 manager(如 cpuManager)作為 hintProvider 提供單個分配策略。在 CPU Manager Plugin Model 中,子 manager 作為模型插件接口提供原有功能。
方案 1:擴展子 manager,讓 topologyManager 感知 cpuset
通過當前的值回去 numa node 的分配擴展到能夠針對單個 cpuset 的分配傾向。擴展插件以 hint providers 的形式執行,主流程不需要修改。
缺點:其他 hintProvider(其他資源的分配)并不感知 CPU 信息,導致 hintProvider 的結果未參考 CPU 分配。最終聚合的結果不一定是最優解。
方案 2:擴展 cpuManager 為插件模型
topologyManager 依然通過 GetTopologyHints() 和 Allocate() 調用 cpuManager,cpuManager 內部進行擴展調度流程。具體的擴展方式可以通過引入新的 policy 配置,或者通過調度框架的方式直接擴展。
缺點:cpuManager 的結果并不決定性的,topologyManager 會結合其他 hints 來分配。
可以看到 CPU Manager Plugin Model 當前提案還出于非常原始的階段,主要是 Red Hat 的人在推。并未在社區充分討論。
Node Resource Interface
該方案來自 containerd。主要是在 CRI 中擴展 NRI 插件。
containerd
containerd 主要工作在平臺和更底層的 runtime 之間。平臺是指 docker、k8s 這類容器平臺,runtime 是指 runc, kata 等更底層的運行時。containerd 在中間提供容器進程的管理,鏡像的管理,文件系統快照以及元數據和依賴管理。下圖是 containerd 架構總覽圖:
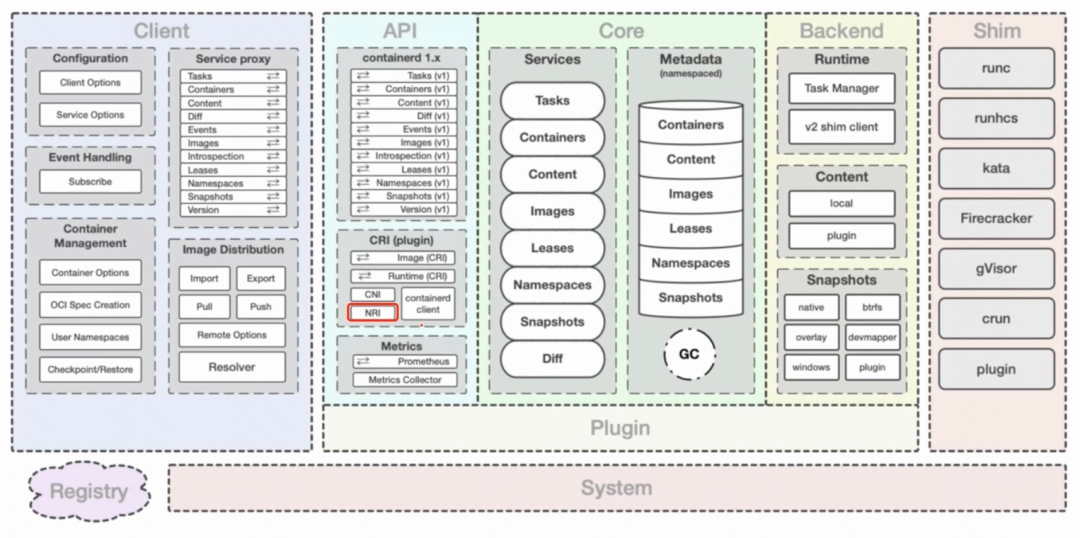
- client 是用戶交互的第一層,提供接口給調用方。
- core 定義了核心功能接口。所有的數據都通過 core 管理存儲(metadata store),所有其他組件 / 插件不需要存儲數據。
- backend 中的 runtime 負責通過不同 shim 與底層 runtime 打交道。
- api 層主要提供兩大類 gRPC 服務:image,runtime。提供了多種插件擴展。
在 CRI 這一層,包含了 CRI、CNI、NRI 類型的插件接口:
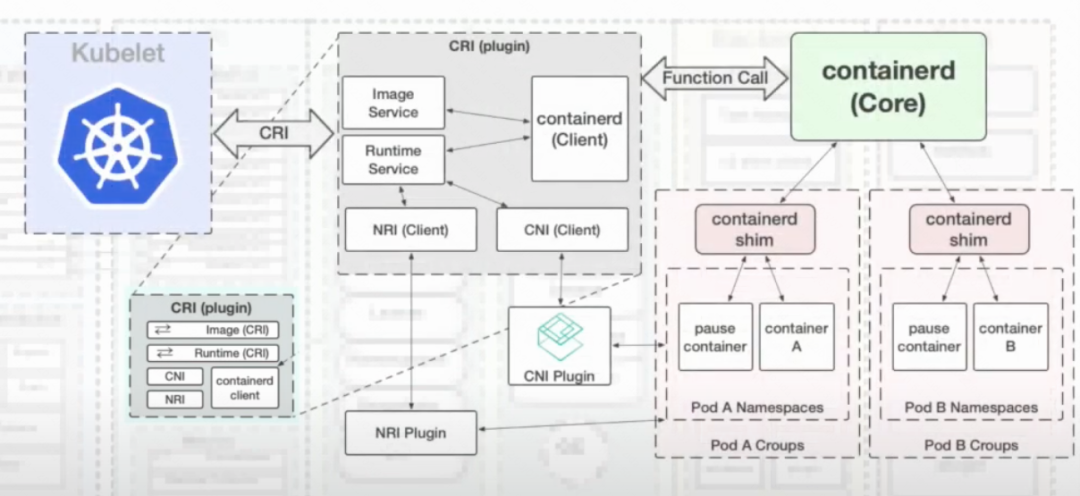
- CRI plugin:容器運行時接口插件,通過共享 namespace、cgroups 給 pod 下所有的容器,負責定義 pod。
- CNI plugin:容器網絡接口插件,配置容器網絡。當 containerd 創建第一個容器之后,通過 namespace 配置網絡。
- NRI plugin:節點資源接口插件,管理 cgroups 和拓撲。
NRI
NRI 位于 containerd 架構中的 CRI 插件,提供一個在容器運行時級別來管理節點資源的插件框架。
cni 可以用來解決批量計算,延遲敏感性服務的性能問題,以及滿足服務 SLA/SLO、優先級等用戶需求。例如性能需求通過將容器的 CPU 分配同一個 numa node,來保證 numa 內的內存調用。當然除了 numa,還有 CPU、L3 cache 等資源拓撲親和性。
當前 kubelet 的實現是通過 cpuManager 的處理對象只能是 guaranteed 類的 pod, topologyManager 通過 cpuManager 提供的 hints 實現資源分配。
kubelet 當前也不適合處理多種需求的擴展,因為在 kubelet 增加細粒度的資源分配會導致 kubelet 和 CRI 的界限越來越模糊。而上述 CRI 內的插件,則是在 CRI 容器生命周期期間調用,適合做 resoruce pinning 和節點的拓撲的感知。并且在 CRI 內部做插件定義和迭代,可以做到上層 kubernetes 以最小代價來適配變化。
在容器生命周期中,CNI/NRI 插件能夠注入到容器初始化進程的 Create 和 Start 之間:
Create->NRI->Start
以官方例子clearcfs[8]:在啟動容器前,依據 qos 類型調用 cgroup 命令,cpu.cfs_quota_us 為-1 表示不設上限。
可以分析出 NRI 直接控制 cgroup,所以能有更底層的資源分配方式。不過越接近底層,處理邏輯的復雜度也越高。
Dynamic resource allocation
KEP 里翻到了這個動態資源分配,方案提供了一套新的 K8s 管理資源和設備資源的模型。核心思想和存儲類型(storageclass)類似,通過掛載來實現具體設備資源的聲明和消費,而不是通過 request/limit 來分配一定數量的設備資源。
用例:
- 設備初始化:為 workload 配置設備。基于容器需求的配置,但是這部分配配置不應該直接暴露給容器。
- 設備清理:容器結束后清理設備參數 / 數據等信息 .
- Partial allocation:支持部分分配,一個設備共享多個容器。
- optional allocation:支持容器聲明軟性 (可選的) 資源請求。例如:GPU and crypto-offload engines 設備的應用場景。
- Over the Fabric devices:支持容器使用網絡上的設備資源。
動態資源分配的設計目的是提供更靈活控制、用戶友好的 api,資源管理插件化不需要重新構建 K8s 組件。
通過定義動態資源分配的資源分配協議和 gRPC 接口來管理新定義 K8s 資源 ResourceClass 和 ResourceClaim:
- ResourceClass 指定資源的驅動和驅動參數
- ResourceClaim 指定業務使用資源的實例
立即分配和延遲分配:
- 立即分配:ResourceClaim 創建時就分配。對于稀缺資源的分配能夠有效使用(allocating a resource is expensive)。但是沒有保障由于其他資源(CPU,內存)導致節點無法調度。
- 延遲分配:調度成功才分配。能夠處理立即分配帶來的問題。
調用流程
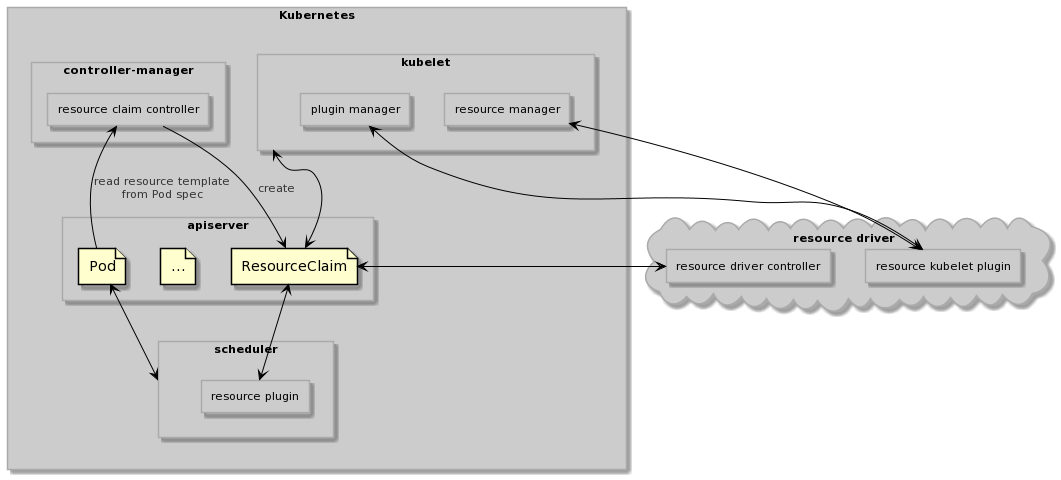
- 用戶創建 帶有 resourceClaimTemplate 配置的 pod。
- 資源聲明 controller 創建 resourceClaim。
- 依據 resourceClaim 的 spec 中,立即分配(immediate allocation)和延遲分配(delayed allocation)處理。
- 立即分配:資源驅動 controller 發現 resourceClaim 的創建時并 claim。
- 延遲分配:調度器首先處理,過濾不滿足條件的節點,獲得候選節點集。資源驅動再過濾一次候選節點集不符合要求的節點。
- 當資源驅動完成資源分配之后,調度器預留資源并綁定節點。
- 節點上的 kubelet 負責 pod 的執行和資源管理(調用驅動插件)。
- 當 pod 刪除時,kubelet 負責停止 pod 的容器,并回收資源(調用驅動插件)。
- pod 刪除之后,gc 會負責相應的 resourceClaim 刪除。
這塊文檔沒有具體描述:在立即分配的場景中,如果沒有調度器工作,resoruce driver controller 來節點選擇機制是怎么樣的。
總 結
可以看到未來社區會對 kubelet 容器管理做一次重構,來支持更復雜的業務場景。近期在 CPU 資源管理上會落地的調度器拓撲感知調度,和定制化的 kubelet CPU 分配策略。在上述的一些 case 中,有發展潛力的是 NRI 方案。
- 支持定制化擴展,kubelet 可以直接載入擴展配置無需修改自身代碼。
- 通過與 CRI 交互,kubelet 將部分復雜的 CPU 分配需求下放到 runtime 來處理。
