K8s組件和架構
k8s 主要由以下核心組件組成:
- API Server:提供了資源操作的唯一入口,并提供認證、授權、訪問控制、API 注冊和發行等機制,該服務運行在Master節點上。
- etcd:保存了整個集群的狀態,該服務運行在Master節點上。
- Controller Manager:負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等,該服務運行在Master節點上。
- Scheduler:負責資源的調度,按照預定的調度策略將 Pod 調度到相應的機器上,該服務運行在Master節點上。
- Kubelet:負責維護容器的生命周期,同時也負責Volume(CVI)和網絡(CNI)的管理。該服務運行在所有的Master和node節點上。
- Container Runtime:負責鏡像管理以及 Pod 和容器的真正運行(CRI)。該服務運行在所有的Master和node節點上。
- Kube-proxy:負責為 Service 提供 Cluster 內部的服務發現和負載均衡。該服務運行在所有的Master和node節點上。
以下是 K8s 架構圖。
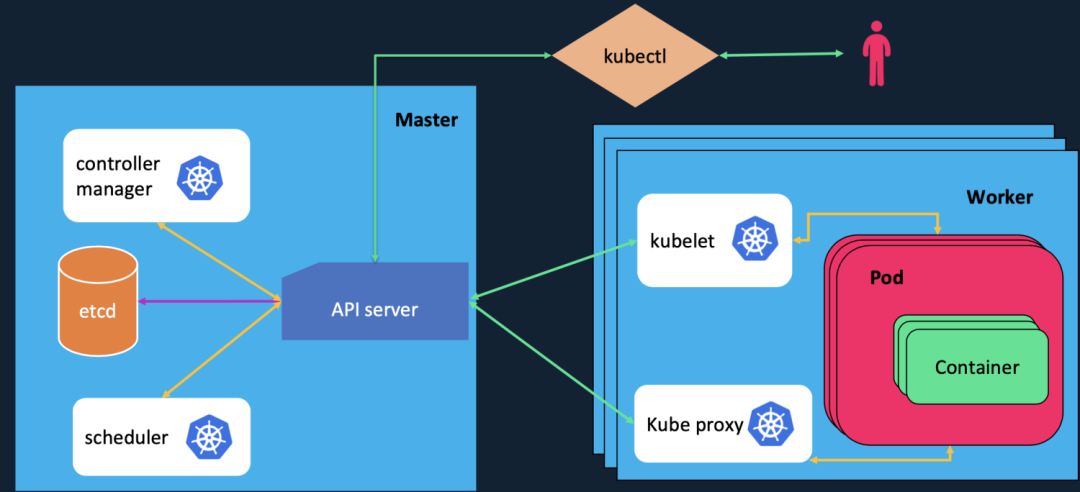
Master控制節點
Master節點是Kubernetes集群的控制節點,每個Kubernetes集群里至少有一個Master節點,它負責整個集群的決策(如調度),發現和響應集群的事件。一個集群通常運行多個Master控制節點,提供容錯性和高可用性。Master節點可以運行在集群中的任意一個節點上,但是最好將Master節點作為一個獨立節點,不在該節點上創建容器,因為如果該節點出現問題導致宕機或不可用,整個集群的管理就會失效。
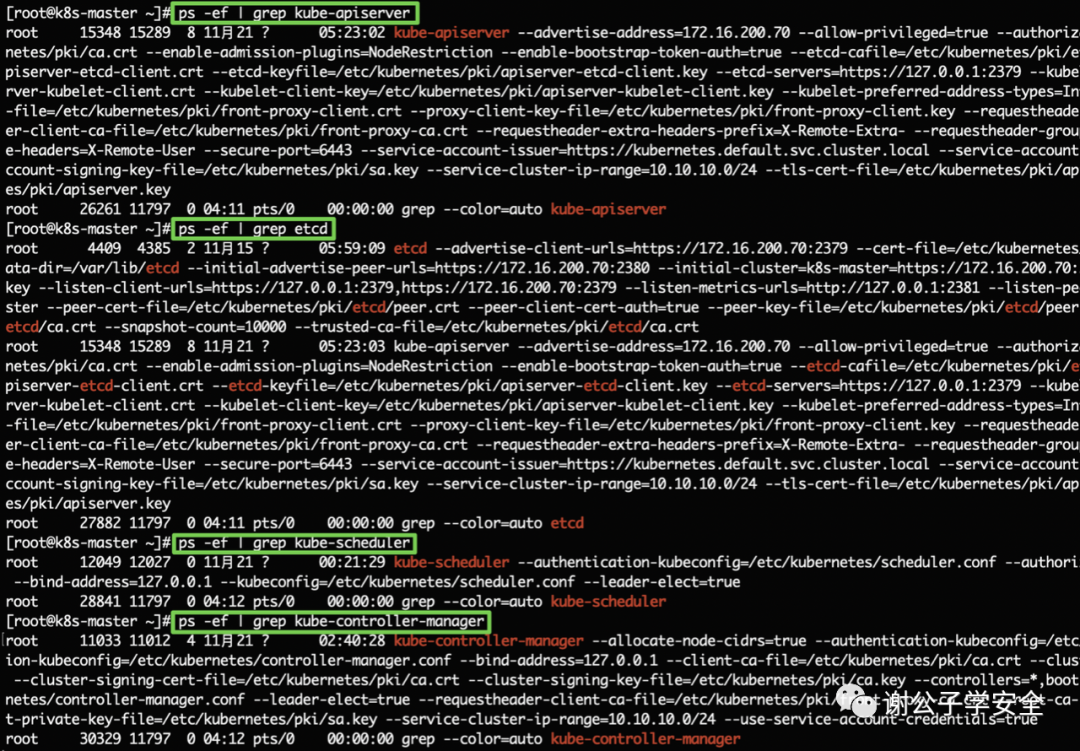
在Master節點上,會運行以下服務:
- kube-apiserver
- etcd
- kube-scheduler
- kube-controller-manager
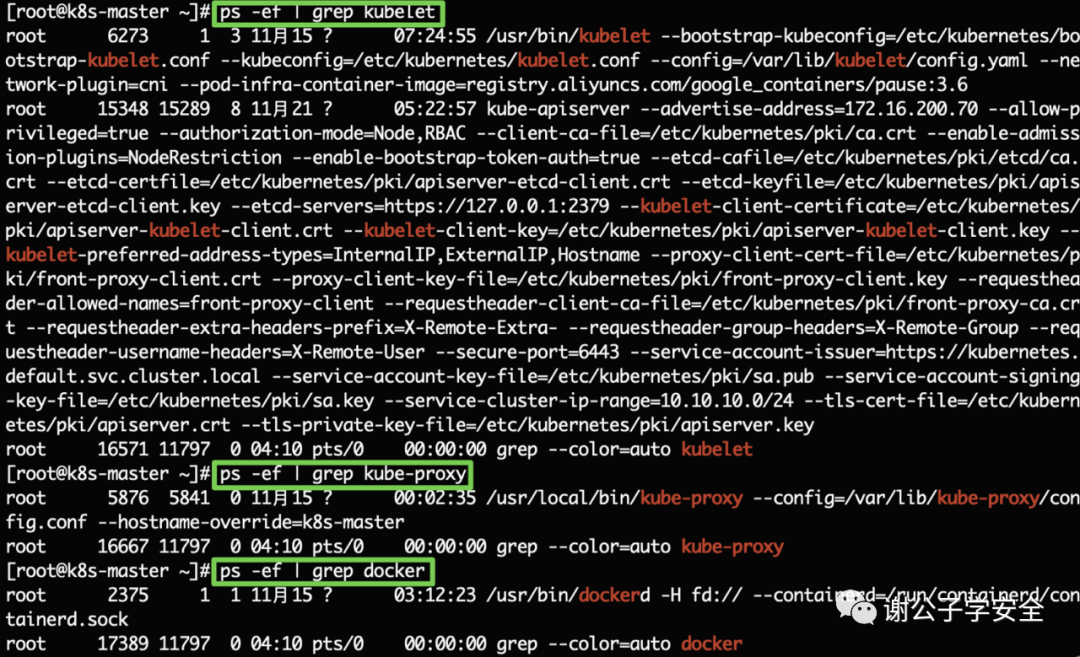
在Master節點上,還會運行以下服務:
- kubelet
- kube-proxy
- Container Runtime:在集群內每個節點上都會安裝Container Runtime容器運行時環境,以使Pod可以在上運行。可以是Docker或者其他容器平臺如container。
“
kube-apiserver
此服務負責公開K8s API并處理請求,可以通過K8s API查詢和操縱K8s中對象的狀態。
“
etcd
一致且高度可用的Key-Value鍵值存儲,用作Kubernetes的所有群集數據的后備存儲,在K8s中有兩個服務需要用到etcd來協同和配置,分別如下
網絡插件 flannel、對于其它網絡插件也需要用到 etcd 存儲網絡的配置信息
Kubernetes 本身,包括各種對象的狀態和元信息配置
注意:flannel 操作 etcd 使用的是 v2 的 API,而 Kubernetes 操作 etcd 使用的 v3 的 API,所以在下面我們執行 etcdctl 的時候需要設置 ETCDCTL_API 環境變量,該變量默認值為 2。
etcd實現原理:http://jolestar.com/etcd-architecture/
“
kube-scheduler
調度器,運行在Master上,用于監控節點中的容器運行情況,并挑選節點來創建新的容器。調度決策所考慮的因素包括資源需求,硬件/軟件/策略約束,親和性和排斥性規范,數據位置,工作負載間干擾和最后期限。
“
kube-controller-manager
控制和管理器,運行在Master上,每個控制器都是獨立的進程,但為了降低復雜性,這些控制器都被編譯成單一的二進制文件,并以單獨的進程運行。
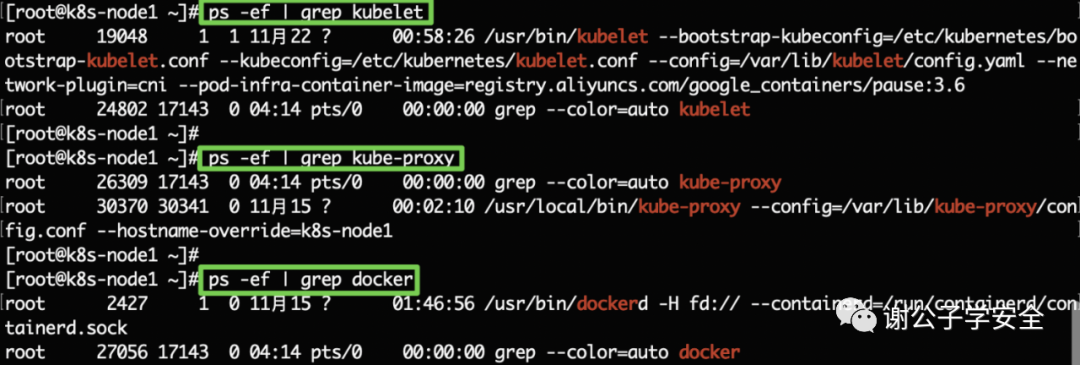
Node工作節點
Node 節點是 Kubernetes 集群的工作節點,每個集群中至少需要一臺Node節點,它負責真正的運行Pod,當某個Node節點出現問題而導致宕機時,Master會自動將該節點上的Pod調度到其他節點。Node節點可以運行在物理機上,也可以運行在虛擬機中。
Node節點可以在集群運行期間動態增加,只要整個節點已經正確安裝配置和啟動了上面的進程。在默認情況下,kubelet會向Master自動注冊。一旦Node被接入到集群管理中,kubelet會定時向Master節點匯報自身的情況(操作系統,Docker版本,CPU內存使用情況等),這樣Master便可以在知道每個節點的詳細情況的同時,還能知道該節點是否是正常運行。當Node節點心跳超時時,Master節點會自動判斷該節點處于不可用狀態,并會對該Node節點上的Pod進行遷移。
在Node節點上,通常會運行以下服務:
- kubelet: 此服務會在集群中每個master和Node節點運行,負責K8s Master控制節點和Node工作節點之間的通信,還負責Pod對應的容器創建,啟動和停止等任務,以實現集群管理的基本功能。
- kube-proxy: 此服務會在集群中每個master和Node節點運行,是集群中每個Node節點上運行的網絡代理,是實現K8s服務概念的一部分。它維護節點上的一些網絡規則,這些網絡規則會允許從集群內部或外部的網絡會話與Pod進行網絡通信。
- Container Runtime: 在集群內每個節點上都會安裝Container Runtime容器運行時環境,以使Pod可以在上運行。可以是Docker或者其他容器平臺如container。
Pod
Pod是K8s中最小的調度資源單位,是容器或容器的集合,一個Pod中可以有多個容器 ,彼此共享網絡和存儲等。Pod中的容器都是統一進行調度,并且運行在共享上下文中。一個Pod被定義為一個邏輯的host,它包括一個或多個相對耦合的容器。
Pod的共享上下文,實際上是一組由namespace、cgroups和其他資源的隔離的集合,意味著Pod中的資源已經是被隔離過了的,而在Pod中的每一個獨立的container又對Pod中的資源進行了二次隔離。
一個 Pod 總是運行在工作節點。工作節點可以有多個 Pod 。控制節點會根據每個工作節點上可用資源的情況,自動調度 Pod(容器組)到最佳的工作節點上。如果運行實例的工作節點關機或被刪除,則 Kubernetes Deployment Controller 將在群集中資源最優的另一個工作節點上重新創建一個新的實例。這提供了一種自我修復機制來解決機器故障或維護問題。
Replication Controller
Replication Controller為Kubernetes的一個核心內容,應用托管到Kubernetes之后,需要保證應用能夠持續的運行,Replication Controller就是這個保證的key,主要的功能如下:
- 確保pod數量:它會確保Kubernetes中有指定數量的Pod在運行。如果少于指定數量的pod,Replication Controller會創建新的,反之則會刪除掉多余的以保證Pod數量不變。
- 確保pod健康:當pod不健康,運行出錯或者無法提供服務時,Replication Controller也會殺死不健康的pod,重新創建新的。
- 彈性伸縮 :在業務高峰或者低峰期的時候,可以通過Replication Controller動態的調整pod的數量來提高資源的利用率。同時,配置相應的監控功能(Hroizontal Pod Autoscaler),會定時自動從監控平臺獲取Replication Controller關聯pod的整體資源使用情況,做到自動伸縮。
- 滾動升級:滾動升級為一種平滑的升級方式,通過逐步替換的策略,保證整體系統的穩定,在初始化升級的時候就可以及時發現和解決問題,避免問題不斷擴大。
Deploment
在kubernetes中,Pod是最小的控制單元,但是kubernetes很少直接控制Pod,一般都是通過Pod控制器來完成的。Pod控制器用于Pod的管理,確保Pod資源符合預期的狀態,當pod的資源出現故障時,會嘗試進行重啟或重建Pod。在kubernetes中Pod控制器的種類有很多,Deployment 是最常用的那種。Deployment是K8s用于管理Pod的資源對象,用來保證K8s中Pod的多實例、高可用與滾動更新、灰度部署等。可以說,Deployment是K8s中最常用最有用的一個對象,多用來發布無狀態的應用。
單獨創建pod的時候就不會有deployment出現,但是創建deployment的時候一定會創建pod,因為pod是一個基礎的單位。任何的控制器單位的具體實現必須落到pod去實現。
Deployment是比Replication Controller更高級的一種資源,它不但可以控制Pod的副本數,同時還可以控制Pod的版本,所以這么高級的資源并不是時時刻刻都需要的,比如你就想暫時性的部署一個小程序,用完就不要了,那么你就沒有必要使用RS或者RC,更沒有必要去用Deploment。
從開發者角度看,deployment顧明思意,既部署,對于完整的應用部署流程,除了運行代碼(既pod)之外,需要考慮更新策略,副本數量,回滾,重啟等步驟,而運行代碼的方式有很多種,例如有一次性的也就是job,有定時執行的也就是crontabjob,有排號的也就是sts,為了復用運行代碼的功能所以抽象為pod,從而進行復用。
從用戶角度看,我們操作時也會根據不同的代碼副本進行查看,例如日志,資源占用都是實例級別的也需要這么一個抽象。
Deployment同樣為Kubernetes的一個核心內容,主要職責同樣是為了保證pod的數量和健康,90%的功能與Replication Controller完全一樣,可以看做新一代的Replication Controller。但是,它又具備了Replication Controller之外的新特性:
- Replication Controller全部功能:Deployment繼承了上面描述的Replication Controller全部功能。
- 事件和狀態查看:可以查看Deployment的升級詳細進度和狀態。
- 回滾:當升級pod鏡像或者相關參數的時候發現問題,可以使用回滾操作回滾到上一個穩定的版本或者指定的版本。
- 版本記錄: 每一次對Deployment的操作,都能保存下來,給予后續可能的回滾使用。
- 暫停和啟動:對于每一次升級,都能夠隨時暫停和啟動。
- 多種升級方案:Recreate:刪除所有已存在的pod,重新創建新的; RollingUpdate:滾動升級,逐步替換的策略,同時滾動升級時,支持更多的附加參數,例如設置最大不可用pod數量,最小升級間隔時間等等。
“
Replication Set
前面提到,Deployment是Pod的其中一個管理者,這其實也不準確,Deployment控制器也不直接操縱Pod。應用存在副本、版本,如果直接Deployment控制器直接管理Pod,對于版本管理、灰度部署、滾動更新等功能就比較麻煩,因此在Deployment和Pod直接還存在一個ReplicaSet的對象,它是對對應著不同不Pod版本,是Pod直接管理者。Deployment通過操縱ReplicaSet間接的管理Pod:
如圖所示描述了在 replicas=5 的設置下,灰度部署(滾動更新)2/5的時候,Deployment的狀態。我們不用直接創建ReplicaSet,在創建Deployment的時候,K8s會默認創建ReplicaSet,并由Deployment控制器進行管理。K8s也不建議人工管理ReplicaSet。

“
創建deployment
執行如下命令輸出一個yaml模板
kubectl create deploy nginx-deploy --image=nginx:alpine --dry-run=client -o yaml

- spec下面的replicas參數代表的是副本數,用戶描述希望創建多少個pod,默認為1。通過副本數字段,我們可以提高應用的可用性,減少因意外導致舊Pod被刪除、新Pod未起引起可用性下降的問題。此外,K8s集群會監控Deployment的中Pod的狀態,如果Pod因意外被刪除,導致集群中的Pod數量低于期望的replicas,K8s會自動創建Pod,以達到yaml中對replicas的期望值。
- spec下面的selector參數作用是“篩選”出要被 Deployment 管理的 Pod 對象,篩選的規則是通過下面的“matchLabels”字段,定義了 Pod 對象應該攜帶的 label。它必須和“template”里 Pod 定義的“labels”完全相同(指name相同的label值相同,不是要具有Pod所有的labels),否則 Deployment 就會找不到要控制的 Pod 對象,apiserver 也會告訴你 yaml 格式校驗錯誤無法創建。
- spec下面的template參數定義了pod應該是什么樣的,它其實就是Pod資源對象中的內容。K8s會根據spec.replicas字段,創建出spec.replicas個Pod,每個Pod描述樣子就是spec.template所描述的。
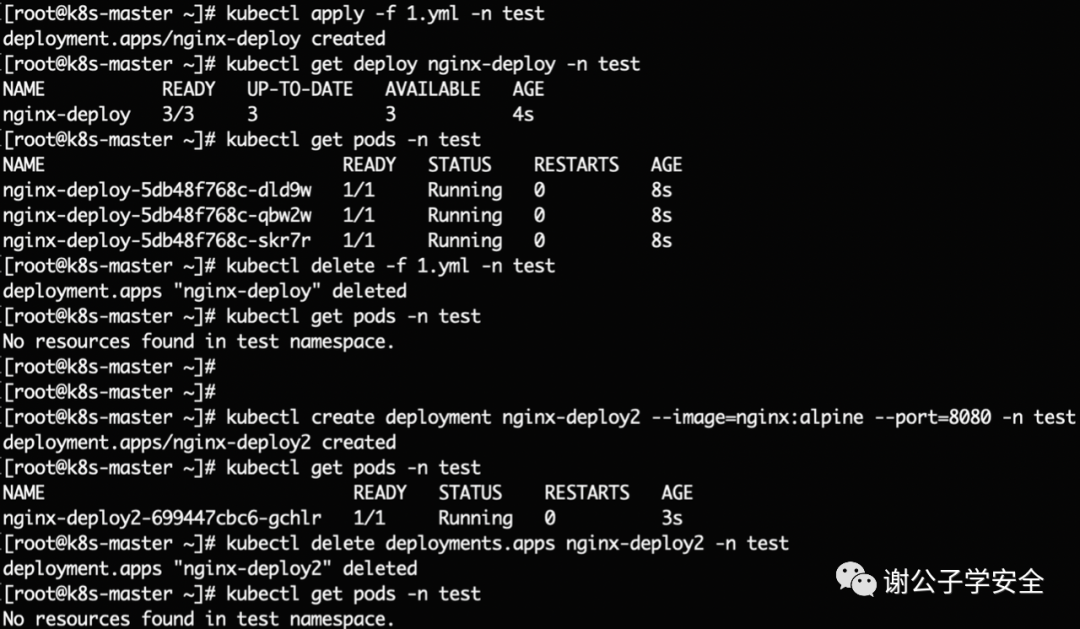
我們將這個yaml模板spec下的replicas參數修改為3,然后保存為1.yml文件,執行如下命令在指定test命名空間下進行部署。
#使用yml文件在指定test命名空間下創建部署kubectl apply -f 1.yml -n test#查看部署kubectl get deploy nginx-deploy -n test#查看指定命名空間下的podkubectl get pods -n test#查看 Deployment 創建的 ReplicaSetkubectl get replicaSet -A#使用yam文件在指定test命名空間下刪除部署kubectl delete -f 1.yml -n test #在指定test命名空間下創建一個名為nginx的deployment部署kubectl create deployment nginx-deploy2 --image=nginx:alpine --port=8080 -n test#使用名字刪除部署kubectl delete deployments.apps nginx-deploy2 -n test
如圖所示,因為spec下的replicas參數為3,所以創建了3個pod。
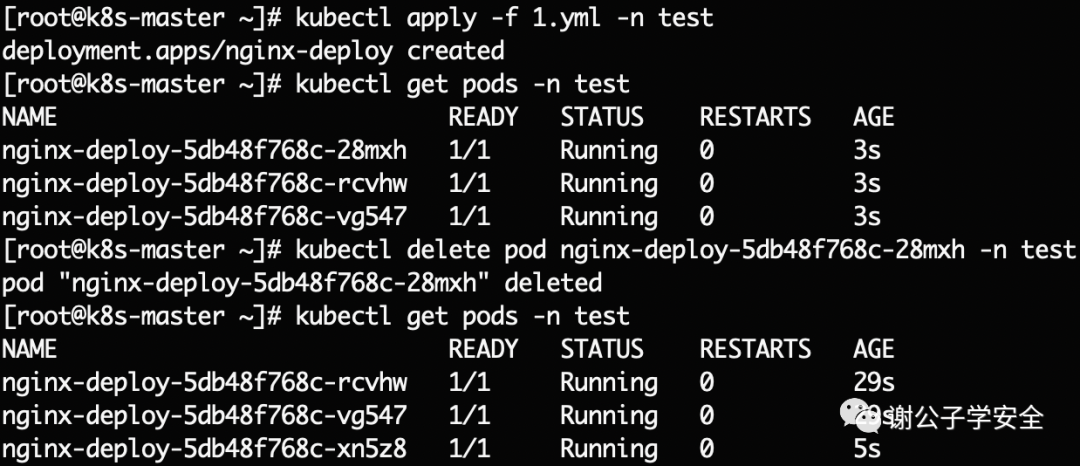
此時刪除指定的pod,可以看到,指定的pod確實刪除了,但是又新生成了重新的pod。因為spec下的replicas參數值為3,所以這個deployment需要3個pod。
Namespace
K8s使用命名空間實現集群內部的邏輯隔離,Namespace可實現容器隔離及一些權限控制等。Namespace用于對k8s中資源對象的分組。namespace之間沒有嵌套或層級關系。一個資源對象只能屬于一個namespace。不同組之間的對象是隔離的,互相不可見。
以下是K8s安裝完成后默認的一些namespace。
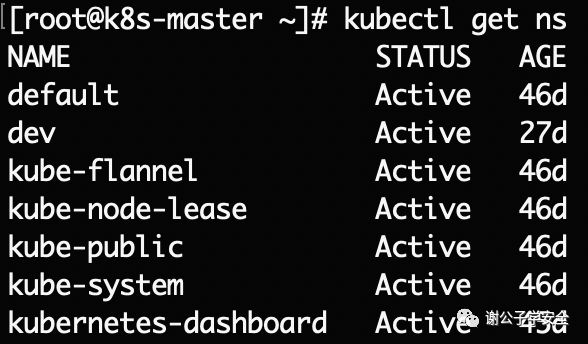
注意:namespace無法保證網絡的隔離性,比如說service可以跨namespace訪問。
“
kube-system
K8s系統自己運行所需的資源對象所在的namespace。
“
kube-public
k8s自動創建的namespace,對所有用戶可見。適合放置集群范圍都可見的服務。kube-public 含有一個單一的 ConfigMap 對象 cluster-info,它有助于發現和安全引導。該命名空間默認不允許被刪除。

“
kube-node-lease
kube-node-lease 這個命名空間含有與每個節點關聯的 Lease 對象。節點 lease 允許 kubelet 發送 heartbeat(心跳),以便控制平面(節點控制器)可以檢測節點故障。那么,如果刪除了 kube-node-lease,會發生什么?Kubernetes 通常會為每個節點創建另一個帶有 Lease 對象的對象,但有時命名空間移除操作會在終止狀態卡住。到那時我們會有一個節點 Lease,過時的 heartbeat 可能會告訴節點控制器:該節點訪問不了,從而影響節點之間的整體通信。
“
default
K8s默認的namespace,如果操作不指明namespace,默認會操作名為default的namespace。
“
kubernetes-dashboard
如果安裝了dashboard,那么該命名空間為dashboard所在的namespace。
非常感謝您讀到現在,由于作者的水平有限,編寫時間倉促,文章中難免會出現一些錯誤或者描述不準確的地方,懇請各位師傅們批評指正。
如果你想一起學習內網滲透、域滲透、云安全、紅隊攻防的話,可以加入下面的知識星球一起學習交流。
