基于動態信任的接入管控體系構建
摘 要:
近年來,伴隨著企業的數字化轉型快速落地,內部數據泄露和受高級可持續威脅攻擊(Advanced Persistent Threat,APT)的風險不斷升級,傳統的接入管控模式暴露出一系列問題。針對廣域網和云計算環境下接入訪問的高度動態化特點,設計動態信任度量的接入管控體系,通過信任持續度量實現對接入訪問的動態管控,在不斷變化的環境下保障用戶接入與訪問的安全。同時,針對信任度量核心問題,提出了一種基于隨機森林的信任度量算法,有效解決模型應用中樣本數量不平衡的問題,加快學習收斂。該算法可應用在廣域網絡和云平臺等不同的網絡環境。
內容目錄:
1 相關研究現狀
1.1 傳統的訪問控制模型研究
1.2 基于零信任的安全架構
1.2.1 零信任安全理念
1.2.2 軟件定義邊界
2 基于持續信任的接入控制模型
3 接入管控體系設計
3.1 總體架構接入管控體系
3.1.1 接入代理
3.1.2 接入控制
3.1.3 用戶管理
3.1.4 終端管理
3.1.5 流量監測
3.1.6 信任評估引擎
3.1.7 授權管理
3.1.8 態勢管理
3.2 工作流程
3.2.1 c身份認證
3.2.2 信任建立
3.2.3 信任持續度量
3.2.4 策略動態調整
4 信任度量算法
4.1 信任度量算法研究現狀
4.2 改進的隨機森林的信任度量算法
4.2.1 隨機森林算法
4.2.2 算法改進
4.2.3 算法實現
5 結 語
隨著云計算、移動互聯網、物聯網等新技術的逐漸普及,企業的數字化轉型成為近年來的熱點,越來越多的企業將業務搬上了云平臺和互聯網,員工與客戶通過遠程訪問的方式進行辦公、運維、客服等活動。新的業務模式改變了企業網絡信息基礎設施的架構,帶來了網絡攻擊面擴大,接入人員和終端更具多樣性,以及業務數據流動復雜性增加等影響,導致企業信息網絡已不存在清晰的、固定的安全邊界,因此依靠傳統的網絡接入與邊界防護的解決方案已無法應對有組織的高級持續攻擊,而需要全新的網絡接入安全架構應對企業數字轉型中面臨的網絡安全風險。
1
相關研究現狀
1.1 傳統的訪問控制模型研究
使用最廣泛的訪問控制模型包括自主訪問控制(Discretionary Access Control,DAC)模型和強制訪問控制(Mandatory Access Control,MAC)模型兩類。DAC 模型允許合法訪問主體或主體組對客體資源進行訪問,通過訪問控制表(Access Control List,ACL)描述訪問主體對訪問資源的權限,具有簡單、直觀、授權靈活等優點,但客體資源的所有者對訪問權限進行管理,易造成訪問權限被惡意擴大等問題。
MAC 模型訪問主體的權限統一通過系統管理員人為設置,或由操作系統自動地按照嚴格的安全策略與規則進行設置,其優點是具有較強的訪問約束機制,安全級別高,但過于強調信息的保密性,對訪問關系變化等不敏感,通常被用于軍事、黨政等對安全級別要求較高的領域。
鑒于 DAC 和 MAC 的不足,研究者提出了基于 角 色 的 訪 問 控 制(Role-Based Access control,RBAC)模型。該模型的基本思想就是將用戶與訪問權限分離開來,通過角色建立間接的聯系,系統可通過生成或取消用戶角色的方式實現高效的權限管理,有利于系統對授權關系進行統一管理。然而,RBAC 模型仍存在不足,包括不能根據上下文環境動態管理權限,屬性體系過于單一,無法實現復雜的訪問控制,以及角色作為一種靜態屬性無法滿足系統對動態訪問控制的要求。針對 RBAC 模型的不足,研究者提出了多種改進方案,文獻 [1] 提出了一種動態自適應訪問控制模型,以資源生命周期為中心,使資源訪問控制策略能夠隨著資源生命周期所處階段的變化而自動變化,并以資源生命周期為節點進行訪問控制。文獻 [2] 將行為、時態狀態和環境狀態引入控制模型,提出了基于行為的訪問控制模型,并將 RBAC 中權限到角色的映射轉化為權限到行為的映射。文獻 [3] 提出了一種基于用戶行為信任的云平臺訪問控制模型,引入層次分析法(Analytic Hierarchy Process,AHP)綜合評估用戶行為信任度,建立基于行為信任等級的用戶服務等級動態分配機制。
1.2 基于零信任的安全架構
1.2.1 零信任安全理念
2010 年 Google 公司首次提出了零信任網絡,2020 年 美 國 國 家 標 準 與 技 術 研 究 院(National Institute of Standards and Technology,NIST)發布了零信任架構標準第二版。目前,零信任構建的新型網絡安全架構被認為是數字時代下提升信息化系統和網絡整體安全性的有效方式,逐漸得到關注和應用。零信任更多的是一種安全理念,其核心原則簡單地說就是“永遠不要相信”和“始終驗證”[4]。零信任假設傳統內網并不信任任何訪問行為,而均需接受評估才能放行,并且安全管理者需不斷分析和評估其內部資產和業務功能的風險,然后制定保護措施以降低安全風險。零信任有許多實現技術,包括軟件定義邊界(Software Defined Perimeter,SDP)、身份與訪問控制 管 理(Identity and Access Management,IAM)、微隔離等。其中,影響最為廣泛的是 SDP 技術。
1.2.2 軟件定義邊界
SDP 是 由 國 際 云 安 全 聯 盟(Cloud Security Alliance,CSA)在 2013 年提出的一個安全模型。SDP作為零信任的最佳實踐落地技術架構,通過網絡隱身保護技術,為企業構建起一個虛擬邊界,結合信任評估機制和動態訪問控制機制,對網絡訪問業務活動進行持續監控,不斷更新網絡訪問實體的信任評分,動態地調整控制策略和訪問權限來應對網絡攻擊,有效保護企業的數據資產安全。SDP 安全模型由 SDP 連接發起主機、SDP 連接接受主機和 SDP 控制器 3 部分組成 [5]。SDP 控制器是整個架構的大腦,主要進行主機認證和策略下發,還可以用于認證和授權 SDP客戶端和配置到 SDP 網關的連接。SDP 模型的主要特征包括最小特權原則、細粒度的上下文訪問控制、以用戶為中心、單包授權和傳輸層保護,以及只允許合法用戶在合適的時間訪問允許的資源。
2
基于持續信任的接入控制模型
基于持續信任的接入控制模型是一個動態的接入控制模型,與傳統的接入控制模型有兩點不同之處:一是引入環境上下文作為接入控制判決的重要因素,并以訪問行為的信任度作為判決的依據;二是對信任度的度量是持續活躍在整個訪問過程的,并且接入控制策略隨著行為和環境的變化而動態調整。基于信任的訪問控制模型如圖 1 所示。
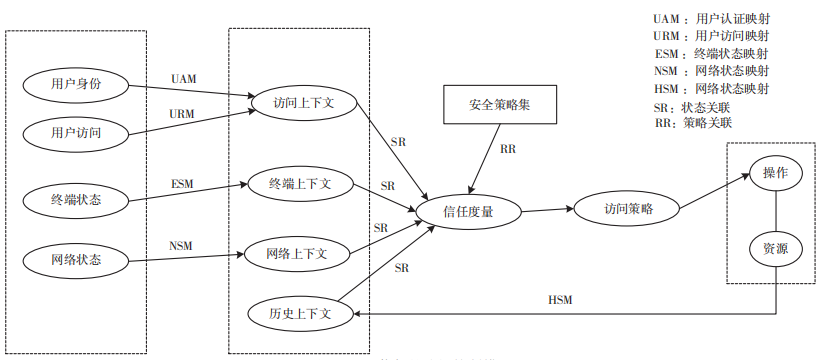
圖 1 基于信任的訪問控制模型
在圖 1 所示的模型中,用戶身份和用戶訪問行為映射為用戶上下文,終端狀態映射為終端上下文,網絡狀態包括網絡流量、安全事件等信息,映射為網絡上下文。另外,這些訪問行為和環境狀態在時間窗口映射為歷史上下文。利用所有上下文通過信任度量計算出當前信任度,結合預設的安全策略生成接入控制策略并執行,然后將執行狀態等信息反饋到歷史上下文,作為下一次信任度量的輸入,形成持續的信任度量。
3
接入管控體系設計
3.1 總體架構接入管控體系
架構對業務提供接入認證、持續信任度量和動態訪問控制等關鍵能力。基于對用戶的身份認證、對終端的基線核查和對網絡流量的采集分析,匯集各種當前數據和歷史數據,進行當前狀態的信任度量,并根據信任度對訪問策略進行動態調整。總體架構如圖 2 所示。
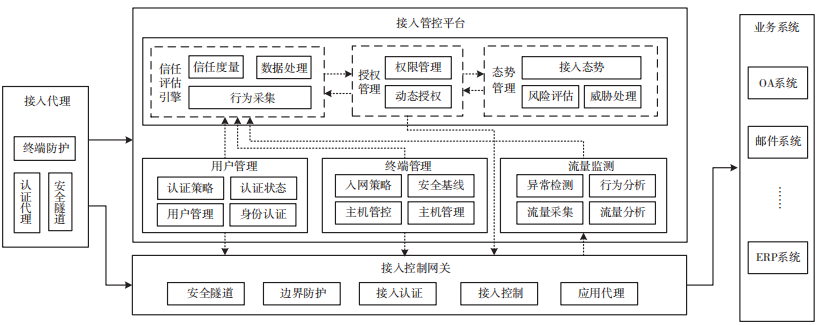
圖 2 接入管控體系架構
3.1.1 接入代理
接入代理一般部署在業務訪問的終端上,是業務安全訪問的起點,提供終端安全防護、身份認證代理、安全隧道封裝等功能。
3.1.2 接入控制
網關接入控制網關一般部署在局域網絡入口或骨干網絡邊緣處,是用戶接入和業務訪問的第一道關卡,用于驗證用戶身份,并根據管控平臺的信任度量結果,對用戶訪問進行相應的控制。
3.1.3 用戶管理
對全網用戶身份進行統一管理,可提供身份認證服務,并對用戶認證策略和認證狀態進行管理。用戶管理將用戶認證狀態信息上報給信任評估引擎。
3.1.4 終端管理
對全網終端進行統一管理,可對主機防護策略、入網主機等進行管理,并可制定終端基線核查策略和入網策略。終端管理將終端入網狀態和基線核查狀態等信息上報給信任評估引擎。
3.1.5 流量監測
對接入用戶的網絡流量進行安全監測,分析用戶訪問行為,發現異常網絡行為。流量監測將分析后的流量信息和訪問行為等信息上報給信任評估引擎。
3.1.6 信任評估引擎
對用戶訪問行為進行信任度評估,采集用戶、終端、流量等上下文數據,通過信任度量算法評估當前用戶訪問的信任度,作為動態訪問控制的依據。
3.1.7 授權管理
生成動態訪問控制策略。基于用戶訪問權限,根據用戶訪問信任度進行動態調整,產生訪問控制策略,下發到接入控制網關。
3.1.8 態勢管理
對全網接入狀態進行管理,生成接入態勢,并進行總體風險評估。
3.2 工作流程
整個系統主要的工作流程包含 4 步。
3.2.1 c身份認證
用戶發起訪問時,首先需要進行身份認證,接入代理基于數字證書、生物特征、用戶名或口令等方式,向接入控制網關發起認證請求。接入控制網關接收到認證請求后,將相應的認證信息發送到用戶管理,對用戶身份進行鑒別。如果認證失敗,則拒絕用戶接入,并記錄異常信息。
3.2.2 信任建立
基于信任的接入控制理念表明,僅對用戶進行身份鑒別是遠遠不夠的,還需要依據多維上下文信息進行信任度量,才能夠建立信任關系。多維上下文信息包括身份認證信息、終端狀態信息、網絡環境信息,這些信息分別通過不同處理模塊收集和產生,并傳送到信任評估引擎。信任評估引擎采用智能化的信任度量算法,對身份、終端、網絡信息進行綜合評估,計算當前用戶訪問業務的信任度,最后參照業務資源的安全等級,建立用戶與訪問業務數據之間的信任關系。
3.2.3 信任持續度量
信任建立后需要進行持續的信任度量。持續信任度量的流程和信任建立階段類似,不同之處在于,用戶訪問過程中不斷產生的數據作為訪問歷史上下文數據,參與持續度量的計算,得出當前的信任度。
3.2.4 策略動態調整
當信任度發生變化時,授權管理模塊需要比對信任度與訪問業務數據的授權策略,如果與當前策略不一致,則進行策略動態調整。
4
信任度量算法
對用戶訪問行為的信任度量涉及許多因素,包括用戶身份、終端環境、網絡環境、業務環境、安全策略等,因此,可信度具有多維屬性。研究適用于網絡接入環境的信任度量方法,是動態信任接入管控的核心問題。
4.1 信任度量算法研究現狀
文獻 [6] 基于云服務商相關屬性計算直接信任度,并根據第三方用戶的推薦計算間接信任度,最后通過權重計算得到實體綜合信任值。文獻 [7] 將灰色系統理論和粗糙集理論與屬性權重結合,建立適用于復雜網絡環境的動態信任評價模型。文獻 [8]提出了一種基于 Hopfield 神經網絡的信任模型以及網絡可信度的評估方法,但未提出具體的算法描述。文獻 [9] 提出了一種基于遺傳神經網絡的算法用于計算機網絡安全評估,但沒有給出具體的指標體系。文獻 [10] 提出了一種多層次分析框架,采用隨機森林算法構建網絡安全評估模型。借鑒以上研究,考慮到接入控制環境的實際情況,本文提出一種改進的隨機森林算法,對用戶接入和訪問行為進行信任度量。
4.2 改進的隨機森林的信任度量算法
4.2.1 隨機森林算法
隨機森林是在集成學習理論 的基礎上結合隨機子空 間 方 法(Random Subspace method, RSM)提出的基于決策樹的一種集成學習算法。構造隨機森林的具體步驟如下文所述。(1)樣本選取。假如有樣本庫 D,則有放回地隨機選取 N 個樣本。選取好的樣本用來訓練一棵決策樹。(2)每個樣本有 M 個屬性,決策樹在每個節點需要分裂時,隨機從這 M 個屬性中選取 m 個屬性,然后從這 m 個屬性中采用某種策略選擇其中一個屬性。常見的決策樹算法有 ID3 決策樹算法、C4.5 決策樹算法和分類回歸樹(Classification And Regression Tree,CART)算法。其中,ID3 決策樹算法以香農信息論的信息增益率為衡量標準,C4.5決策樹算法通過信息增益率來選擇屬性,而 CART決策樹算法以基尼不純度為劃分準則。(3)每一棵決策樹的形成過程都按照步驟 2來分裂,直至所有葉子節點形成,整個決策樹形成過程中沒有剪枝步驟。(4)按照步驟(1)~(3),建立包含 S 棵樹的隨機森林。當對一個新的樣本數據進行分類時,隨機森林中的 S 棵決策樹都需要對樣本數據進行分類判斷。隨機森林將每一棵決策樹的分類結果進行匯總,最終的分類結果由隨機森林匯總的結果決定,一般采用“多數優先”的投票方式或者判斷是否超過某一個閾值,來決定數據是否被劃為這一類。隨機森林建立的整個過程如圖 3 所示。
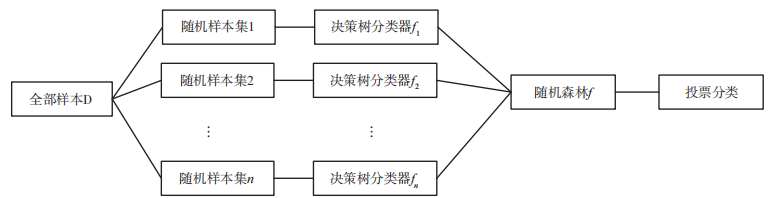
圖 3 隨機森林建立過程
4.2.2 算法改進
考慮到網絡接入控制系統的實際應用環境,在使用隨機森林算法時需要注意兩個方面的問題:一是在實際環境中,有安全風險的接入行為和訪問行為是少數,大多數是可信任的行為,采集的樣本是不平衡的;二是實際環境應用時,需要盡可能快地訓練出可用的模型用于信任度量,但信任度量面臨大量樣本和復雜的多維數據,需要加快模型訓練速度。因此,可以從以下兩個方面進行改進。
(1)對訓練樣本進行處理
可采用改進的合成少數過采樣技術(Synthetic Minority Oversampling Technique,SMOTE) 對 樣本數據進行處理,減少不平衡樣本帶來的影響。SMOTE 本質上是一個過采樣(oversampling)算法。該算法對劣勢類別的樣本,選取 k ∈ [1,n],其中 n為劣勢類別的數量,直接對于 k 個數據取平均,得到新的數據樣本,
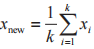
這樣得到的新數據是對原數據的輕微擾動,并且能夠保證新數據在原有的數據簇中。
(2)加快學習收斂時間
隨機森林的學習時間與樣本數量、決策樹數量、決策樹選取的樣本屬性數量密切相關。可結合 AHP方法,首先對樣本屬性的權重進行計算、排序,其次根據權重值選取前1/2的屬性作為樣本基礎屬性,既降低樣本屬性數量,又同時保留對訓練結果有影響的重要屬性。
4.2.3 算法實現
(1)信任度分類
隨機森林是一種有監督的分類算法,而在基于信任度量的接入控制中是通過計算信任度的高低來決定是否允許接入。因此,本文在運用隨機森林算法時,首先將信任度根據取值區間劃分為 5 類:信任度在 [0,40] 范圍為極不信任,在 [41,60] 范圍為不信任,在 [61,80] 范圍為基本信任,在 [81,90] 范圍為信任,在 [91,100] 范圍為非常信任。接入控制策略可依據不同的信任值類型來制定。
(2)信任度量指標體系
對用戶接入與訪問的信任度量,應綜合考慮用戶行為與所處環境的多種因素。因此,借鑒網絡安全等級保護 2.0 等標準要求,接入控制系統的信任度量指標體系應包括用戶、終端、網絡、應用、安全、策略等方面,具體如下文所述。
①用戶認證與行為(U1~U16)
包括用戶類型等級、角色等級、認證方式、歷史信任度、接入頻率、接入時間、平均接入時間、選擇接入方式的概率、接入失敗頻率、訪問業務頻率、時間頻率、時長、訪問資源頻率、時間頻率、時長、用戶與 IP 關聯情況等。
②終端防護(H1~H7)
包括終端防護軟件、高 / 中漏洞數量、常見危險端口、殺毒軟件、病毒庫版本、操作系統用戶類型、安全基線評分等。
③網絡環境(N1~N12)
總體流量情況包括網絡層流量大小、五元組會話數量、包長分布、新建連接數量、上行 / 下行流量比值、syn 數量比值等。用戶流量情況包括終端發起的新建連接數量、五元組數量、包長分布、流量大小、上行 / 下行流量比值、syn 數量比值等
④應用防護(S1~S5)
根 據 每 種 協 議 制 定, 例 如 超 文 本 傳 輸 協 議(Hyper Text Transfer Protocol,HTTP),包括訪問時間、訪問資源頻率、HTTP 應用類型、請求方法、上行和下行流量比值等。
⑤網絡攻擊(NA1~NA5)
包括攻擊數量、攻擊類型、攻擊威脅程度、與終端 IP 相關的攻擊數量、與目的 IP 相關的攻擊數量等。
⑥安全裝備與策略(P1~P6)
包括終端防護功能、局域網邊界防護功能、骨干網邊界防護功能、業務網絡邊界防護功能、過濾策略開啟情況、傳輸保護策略開啟情況等。
(3)樣本數據處理
包括數據歸一化處理和樣本平衡梳理。很多采集的數據不是數值類型,可轉化為數值類型數據,并進行歸一化處理。例如終端防護功能的開啟,將它分為登陸控制、外設監控、軟件監控、網絡外聯控制、終端可信加固 5 個功能,每開啟 1 個功能,加 0.2,那么終端防護功能的取值分布在 [0,1] 之間。其他類型數據采用類似的方式處理。樣本數據的平衡處理參照前述的 SMOTE 方法進行處理。
(4)樣本數據屬性的優選
采用 AHP 方法對以上指標進行權重計算,選擇權重大的 1/2 指標用于后續的隨機森林構建。在計算權重時,可按照指標體系的大類分別計算,例如安全裝備與策略一類,根據專家系統初步判斷其重要性比重依次為 1,2,3,4,5,6,構造判斷矩陣 A,并根據判斷矩陣得到歸一化矩陣 A-,兩個矩陣如下:

得出這幾種安全事件的一致性向量,經過一致性檢查后,可得出權重向量為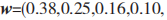
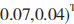 。計算得到各指標的權重后,按照降序排列,選取前 1/2 的指標作為構建決策樹的屬性。
。計算得到各指標的權重后,按照降序排列,選取前 1/2 的指標作為構建決策樹的屬性。
(5)隨機森林生成參數的選擇
①樹的數目
森林中樹的棵數一般的取值范圍為(0,1 000),由于接入控制系統需要更快的收斂,本文默認情況下為 100 棵樹,后期可根據實際情況調優。②隨機屬性個數單棵樹在生成時,隨機選擇的屬性個數,本文設定為 M/3,其中 M 為優選后的屬性總數。
(6)算法步驟
有訓練數據集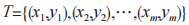 ,屬性集
,屬性集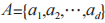 ,訓練步驟如圖 4 所示。其中,在產生葉子節點時,確定葉子的特征采用基尼指數算法,算法流程如下:假定當前訓練數據集 T,屬性集合 A,其中 T的第 k 類樣本所占的比例為
,訓練步驟如圖 4 所示。其中,在產生葉子節點時,確定葉子的特征采用基尼指數算法,算法流程如下:假定當前訓練數據集 T,屬性集合 A,其中 T的第 k 類樣本所占的比例為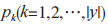 ,基尼值為:
,基尼值為:
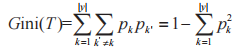
假定屬性 a 有 v 個可能的取值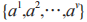 ,若使用a對訓練集T進行劃分,則會產生v個分支節點。對于第 v 個分支節點包含了 T 中所有在屬性 a 上取值為
,若使用a對訓練集T進行劃分,則會產生v個分支節點。對于第 v 個分支節點包含了 T 中所有在屬性 a 上取值為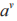 的樣本,記為
的樣本,記為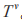 。可計算屬性 a 的基尼指數為:
。可計算屬性 a 的基尼指數為:
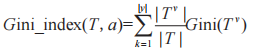
選擇候選屬性集合 A 中基尼指數最小的屬性作為最優劃分屬性,即:
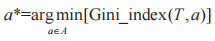
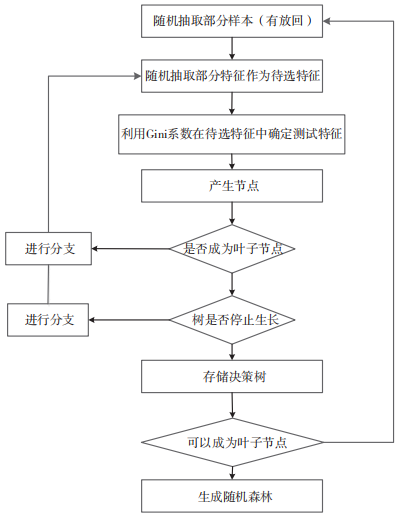
圖 4 基于隨機森林的信任度量算法步驟
5
結 語
本文提出了基于持續信任度量的接入控制模型,并基于此模型設計了動態信任的接入管控體系和工作流程,同時,提出了一種基于隨機森林的信任度量方法,結合 SMOTE 和 AHP 對多維樣本屬性進行處理和優選,解決了樣本數不平衡和加快訓練收斂的問題。基于動態信任度量的接入管控體系實現了從靜態認證到動態信任模式的轉變,在廣域網絡和云平臺等環境中有廣泛的應用前景。
引用本文:廖竣鍇 , 程永新 , 張建輝 . 基于動態信任的接入管控體系構建 [J]. 通信技術 ,2022,55(4):473-479.
作者簡介 >>>
廖竣鍇,男,碩士,高級工程師,主要研究方向為信息安全;
程永新,男,碩士,高級工程師,主要研究方向為信息安全;
張建輝,男,學士,工程師,主要研究方向為信息安全。
選自《通信技術》2022年第4期(為便于排版,已省去參考文獻)
商務合作 | 開白轉載 | 媒體交流 | 理事服務
請聯系:15710013727(微信同號)
《信息安全與通信保密》雜志投稿
聯系電話:13391516229(微信同號)
郵箱:xxaqtgxt@163.com
《通信技術》雜志投稿
聯系電話:15198220331(微信同號)
郵箱:txjstgyx@163.com
謝謝您的「分享|點贊|在看 」一鍵三連
