基于數據挖掘與關聯分析的工控設備異常運行狀態自動化檢測方法分析
摘 要:
以準確、高效地檢測工控設備異常為目的,研究基于數據挖掘與關聯分析的工控設備異常運行狀態自動化檢測方法。以采集的某電廠 DCS 網絡全流量數據形成的工控設備運行狀態日志序列為輸入,通過預處理、特征提取等方式獲取待監測的工控設備運行狀態數據的特征向量,通過凝聚型層次聚類算法聚類特征向量初步區分工控設備正常、異常運行狀態數據,再利用基于矩陣的 Apriori 算法,挖掘工控設備正常運行狀態構建正常行為模式庫,以關聯分析獲取的工控設備正常運行狀態規則集為參照,通過相似度對比輸出工控設備異常運行狀態的自動化檢測結果。實驗結果表明:該方法能夠準確檢測出工控設備異常運行狀態,檢測效率高、誤差小。
內容目錄:
1 工控設備異常運行狀態自動化檢測
1.1 DCS 網絡全流量數據分析
1.1.1 DCS 網絡全流量綜述
1.1.2 DCS 網絡全流量數據統計
1.1.3 DCS 網絡通信結構
1.2 日志數據預處理
1.3 日志特征提取
1.4 日志分析
1.4.1 日志聚類
1.4.2 日志關聯分析
1.5 日志檢測
2 實驗分析
3 結 論
當前針對電廠機組跳閘后的事件分析,主要依賴于汽輪機緊急跳閘系統(Emergency Trip System,ETS)的跳閘輸出記錄和分散控制系統(Distributed Control Systems,DCS)的事件順序(Sequence of Event,SOE)記錄。因 ETS 系統及 SOE 記錄采集數據受限,導致部分機組跳閘事件無法分析。針對這一情況,舒斐等人 結合深度置信網絡(Deep Belief Networks,DBN)算法和隨機森林(RandomForest,RF)算法,對工控設備的異常進行識別;吳英友等人 采用兩階段聚類的方法檢測工控設備的異常狀態。但是前者的適用性較弱,后者的精準程度較低。
為此,本文研究基于數據挖掘與關聯分析的工控設備異常運行狀態自動化檢測方法,通過獲取工控設備運行狀態數據間的關聯規則展開數據挖掘,準確、高效地實現工控設備異常運行狀態自動化檢測。
1工控設備異常運行狀態自動化檢測
在分布式系統中,工控設備往往扮演著主機的角色,若由工控設備控制的整個系統因未能及時重啟而停止工作,將造成事故或經濟損失,因此,有必要根據 DCS 網絡全流量數據和日志數據,逐一分析工業控制設備的異常運行狀態。
1.1 DCS 網絡全流量數據分析
某電廠在 1 月內連續 2 次出現過不明原因的非計劃停機,嚴重影響電廠及電網安全運行,應電廠要求我司專業人員于 8 月 7 日到達現場開展機組異常跳閘檢查分析。對電廠前期已進行的檢查工作再次梳理,對機組進行模擬啟動全仿真試驗,通過超速保護控制單元(Over speed Protect Controller,OPC)超速試驗復現了機組異常停機,基于 DCS 網絡全流量分析技術,真實還原機組跳閘的全過程,從而對電廠機組異常停機事件進行精準的定性分析。
1.1.1 DCS 網絡全流量綜述
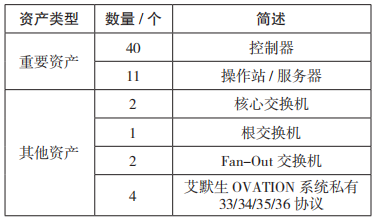
試驗期間采集的全流量數據事件記錄時間范 圍:2020-8-7 14:04:34~2020-8-7 18:31:55,采集流量會話、IP 資產、所使用的通信協議情況如表 1、表 2 所示。
表 1 流量總體情況
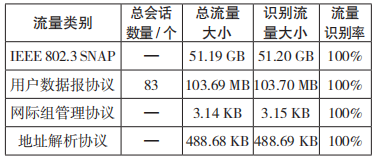
表 2 流量資產、協議情況
1.1.2 DCS 網絡全流量數據統計
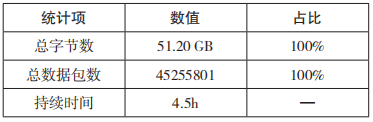
(1)原始流量采集情況(時間、跨度)。本次分析采集了該電廠 #2 機組一區 DCS 系統數據,2020-8-7 14:04:34~2020-8-7 18:31:55 時 間段的流量,共計 134.14 GB,如表 3 所示。
表 3 原始流量采集情況
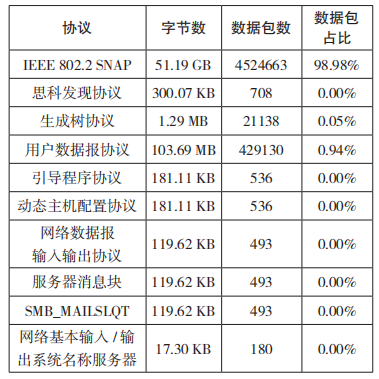
(2)流量統計概況。IP-Top-ALL 表是指通過統計原始流量得到的 IP 端點表,總計 63 個IP 地址。IP 會話表是指通過統計原始流量得到的,總計 66 個 IP 會話。協議流量統計是指通過統計原始流量得到使用的協議所占流量大小情況,具體如表 4 所示。用戶數據報協議(User Datagram Protocol,UDP)會話是通過統計原始流量得到的 UDP 會話表,總計 188 個 UDP 會話。主要資產信息是對采集流量進行整理,通過物理會話可以定位 DCS 主副控制器與操作站,其包含主控制器 20 個,副控制器 20 個,工程師站、操作員站、歷史站 11 個。
表 4 協議流量統計情況
1.1.3 DCS 網絡通信結構
通過對采集的 DCS 網絡全流量 IP 節點、會話、協議進行分析,可從流量數據分析中提取以下內容:過程控制數據實時上報;操作事件記錄日志;過程控制報警上報;DCS 系統網絡時間協議(Network Time Protocol,NTP)對時;DCS 系統核心交換機的雙機熱備。
1.2 日志數據預處理
以上述 DCS 網絡全流量數據作為工控設備運行狀態數據,其是一種結構多為無結構化或半結構化的日志數據,涵蓋了事件發生的具體時間與內容。為提升日志數據的挖掘質量,需利用應用數據預處理技術來獲取干凈、準確的數據源 [8]。數據預處理的流程如圖 1 所示。
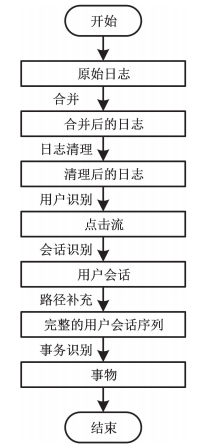
圖 1 數據預處理流程
將原始工控設備運行狀態數據的日志進行合并后,展開日志清理,根據挖掘任務處理日志文件,清理與挖掘關聯性不強的對象之間的引用;對清理后的日志進行用戶識別,以用戶記錄的形式來表示同一個用戶的日志活動序列,得到一個點擊流;通過會話識別從點擊流數據中重構頁面信息,以此獲取用戶瀏覽網頁的實際行為序列 ;經路徑補充能夠將遺漏的請求填充在用戶會話中優化識別出正確的用戶會話,獲取完整的用戶會話序列;采用事務識別把訪問的網頁順序分割為能夠代表所有用戶會話的邏輯單元,找到最有含義的會話訪問路徑,最終獲取日志數據中需要應用的事務數據。
1.3 日志特征提取
日志的特征挑選是工控設備運行狀態自動化檢測的關鍵,其特征的差異會嚴重影響后續結果。當日志分解為獨立事件后,還需對其進行編碼,獲取一個數字特征向量,實現運行狀態自動化檢測模型的輸入。日志的劃分應用窗口機制包括固定、滑動和會話 3 種窗口。由于現實中事務日志具有差異,使得其運行狀態自動化檢測重要度也存在差異,所以需采用逆文檔頻率(Inverse Document Frequency,IDF)對差異事務日志的權重展開計算,該技術是一種能夠實現信息搜索的術語加權技術 ,能夠獲取某術語在某文檔中的重要程度。把每個工控設備運行狀態的事務日志當作一個術語,以各日志序列為一文檔。若某事務日志多次出現于多個日志序列內,則該事務日志在工控設備運行狀態自動化檢測中的權重較低。IDF 的計算公式表示為:
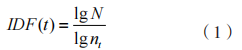
其中,N、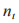 分別為日志序列總數與事務 t出現的序列數。通過 IDF 的計算公式,可從事務計數矩陣中獲取事務權重矩陣,得出日志的特征矩陣。
分別為日志序列總數與事務 t出現的序列數。通過 IDF 的計算公式,可從事務計數矩陣中獲取事務權重矩陣,得出日志的特征矩陣。
1.4 日志分析
日志分析主要包括聚類分析和關聯規則挖掘兩個部分。其中,聚類分析是應用凝聚型層次聚類算法,通過聚類特征向量初步區分工控設備的正常、異常運行狀態數據;關聯規則挖掘是應用 Apriori 改進算法,關聯規則挖掘工控設備正常運行產生的日志數據集,利用所挖掘的工控設備正常運行狀態構建正常行為模式庫。
1.4.1 日志聚類
通過聚類較為相似的日志數據來區分工控設備正常、異常運行狀態。由于在目標工控設備內獲取的日志數據無標簽,所以一般采用凝聚型層次聚類算法過濾海量日志數據中的正常日志數據,獲取工控設備異常運行狀態數據候選集。凝聚型層次聚類算法內的距離度量利用歐氏距離,則日志序列 Si 與 Sj 的歐氏距離為:
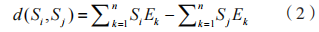
其中, 、
、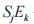 分別表示第 i、j 個日志序列中的第 k 個事件。
分別表示第 i、j 個日志序列中的第 k 個事件。
聚類時,先把所有日志序列當作一個類簇,計算類簇之間的距離,合并距離最近的兩個簇。為實現簇的合并,需要先對其距離度量展開定義,以各簇內日志序列間的最大距離為其距離度量,聚類結束的條件為距離閾值 e,在簇間的最大距離大于 e 的情況下結束聚類。
工控設備運行狀態自動化檢測階段,需要求取給定日志序列與目前簇的向量距離,若其與最近簇之間的歐氏距離低于閾值,則分割該日志序列特征向量至最近簇,反之則生成一個新簇。若距離最近的簇是正常的日志序列,則為正常,反之則為異常。
1.4.2 日志關聯分析
以日志聚類中獲取的工控設備正常運行狀態數據特征為輸入,展開日志關聯分析,輸出表示工控設備正常運行狀態的頻繁集和關聯規則信息,通過關聯分析挖掘海量日志數據中的工控設備正常運行狀態數據,構建工控設備正常運行的模式規則庫。
關聯規則挖掘算法的主要目的是搜索分析蘊含于項集之間類似 的規則,通過經典的 Apriori 算法可有效實現該目的,Apriori 算法的應用過程如下文所述。
的規則,通過經典的 Apriori 算法可有效實現該目的,Apriori 算法的應用過程如下文所述。
(1)項目和項集。令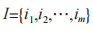 表示項集。其中,所有
表示項集。其中,所有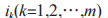 為項目。項集長度為項集 I 中所含項目的數量 k。
為項目。項集長度為項集 I 中所含項目的數量 k。
(2)事務和事務數據庫。所有事務均為 I中子集,將其表示為 T,得到 T ? I。利用事務ID 區分差異事務,有利于查找、累計頻繁集。所有事務集表示為事務數據庫 D,通過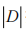 描述 D 中所含事務數。
描述 D 中所含事務數。
(3)項集的支持度。針對項集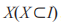 ,通過 count(X ? T) 代表 D 中所含 X 的事務數,得 到 X 的支持度為:
,通過 count(X ? T) 代表 D 中所含 X 的事務數,得 到 X 的支持度為:
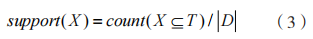
(4)項集的最小支持度和頻繁集。搜索關聯規則時,項集必須符合特定支持度閾值(項集最小支持度),將其表示為 。在某項集支持度大于或等于的情形下,將該項集稱作頻繁集;不符合要求的稱作非頻繁集。
。在某項集支持度大于或等于的情形下,將該項集稱作頻繁集;不符合要求的稱作非頻繁集。
(5)關聯規則。定義關聯規則形式為:

其中,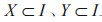 且
且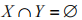 ,X、Y 分別表示規則 R 的條件、結果。R 意為在某事務內存在 X 時,有一定概率也存在 Y。
,X、Y 分別表示規則 R 的條件、結果。R 意為在某事務內存在 X 時,有一定概率也存在 Y。
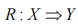 表示在 X 內的項目存在時,Y 內的項目也對應存在。
表示在 X 內的項目存在時,Y 內的項目也對應存在。
(6)關聯規則的支持度。當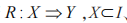 。
。
 時,R 的支持度可以通過 D 內同時存在 X、Y 的事務數和全部事務數的比值描述,用
時,R 的支持度可以通過 D 內同時存在 X、Y 的事務數和全部事務數的比值描述,用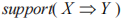 表示:
表示:
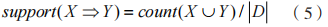
(7)關聯規則的可信度。當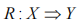 ,
,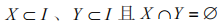 時,可以通過同時存在 X、Y 的事務數和存在 X 的事務數的比值描述可信度,其映射了事務內存在 X 的同時存在 Y的概率,用
時,可以通過同時存在 X、Y 的事務數和存在 X 的事務數的比值描述可信度,其映射了事務內存在 X 的同時存在 Y的概率,用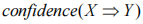 表示:
表示:
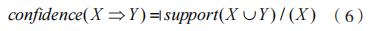
(8)連接和剪枝。當同長度的兩個頻繁集中僅有某一不同項時,連接獲取候選頻繁集為連接。當已知頻繁集的每個子集都為頻繁時,修剪候選頻繁集的流程為剪枝。
在 Apriori 算法中,工控設備運行狀態數據挖掘時不斷形成候選頻繁集,經其支持度計算形成頻繁集,通過連接、剪枝獲取新候選集,迭代至不能形成新的頻繁集時算法結束。
由于 Apriori 算法在計算過程中存在形成的候選集多、運行效率低等問題,本文提出了基于矩陣的 Apriori 算法,以矩陣的形式描述事務數據庫,提升 Apriori 算法的性能,基于矩陣的Apriori 算法的定義域與實現步驟如下文所述。
定 義 1:針 對 任 意 給 定 D 存在映射關系: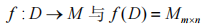 ,其中,m、n 分別表示項目數、事務數,Mij 定義為:
,其中,m、n 分別表示項目數、事務數,Mij 定義為:
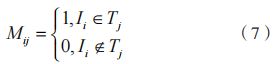
定義 i 和 j 為兩個不同的事務數據庫候選集,得出事務數據庫的支持度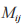 ,
,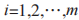 ,
,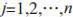 。
。
定義 2:D 中所有項 Ii 的向量表示為:
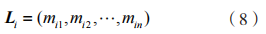
其中,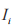 的支持度計數表示為:
的支持度計數表示為:
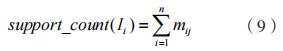
定義 3:兩項集 的向量公式為:
的向量公式為:
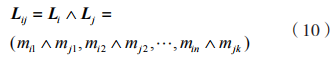
其中,k 為項集長度,兩項集的支持度計數通過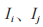 的向量內積描述,得到:
的向量內積描述,得到:
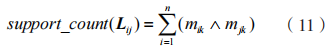
定義 4:K項集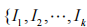
 的向量為
的向量為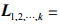
 ,則其支持度計數為:
,則其支持度計數為:
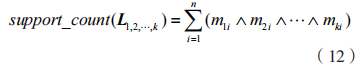
算法具體步驟為:
步驟 1:按照定義 1,將 D 映射成相應布爾矩陣,其中行、列分別表示“項”“事務”;按照定義 2 求取完成轉換的矩陣所有行的向量和,得出所有項的支持度計數,最小支持度的項為頻繁集。
步驟 2:按照所得 K 項集連接形成候選集,對候選集剪枝。
步驟 3:結合定義 3 和定義 4,重新掃描 D相應矩陣的行向量內積獲取對應支持度計數,若結果高于最小支持度計數,則為 K 項集。
1.5 日志檢測
以采集的 DCS 網絡全流量數據形成的工控設備運行狀態日志序列為輸入,通過預處理、特征提取等方式獲取待監測的工控設備運行狀態數據的特征向量,通過基于矩陣的 Apriori 算法挖掘到待測數據的規則集,以關聯分析獲取的工控設備正常運行狀態規則集為參照,對比兩者的相似度,輸出工控設備異常運行狀態的自動化檢測結果。
設置關聯規則 ,
,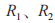 的支持度、置信度分別為
的支持度、置信度分別為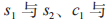
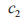 ,相似度為:
,相似度為:
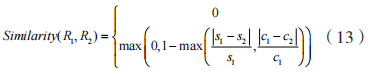
其 中, 相 似 度 為 0 的 條 件 是 或
或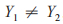 ,相似度最大的限定條件為
,相似度最大的限定條件為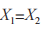 且
且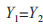 ,規則集
,規則集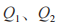 的相似度為:
的相似度為:
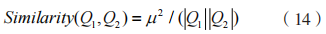
其中,運行狀態規則集為:
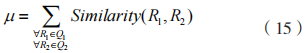
此時設定一個異常判別閾值,若規則集相似度大于異常判別閾值,則工控設備運行狀態為正常,反之則為異常。
日志自動化檢測的流程如圖 2 所示。
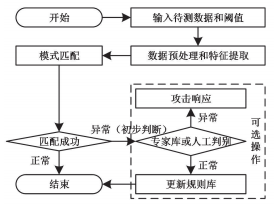
圖 2 異常檢測
日志自動化檢測的目的是對工控設備運行狀態進行分析與檢測,為保證工控設備異常運行狀態自動化檢測的準確性與效率,可在匹配異常時加入專家庫或人工進行判別。
2 實驗分析
為驗證 Apriori 算法改進后的優越性,對比其與傳統 Apriori 算法在差異最小支持度、事務數據量下的執行時間,結果如圖 3、圖 4 所示。
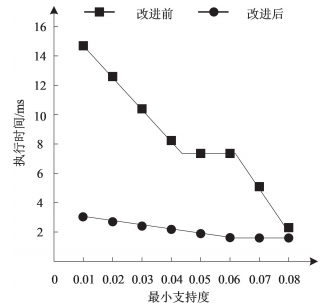
圖 3 差異最小支持度下算法改進前后的執行時間
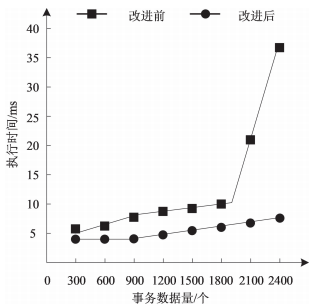
圖 4 差異事務數據量下算法改進前后的執行時間
通過圖 3、圖 4 可以看出,在數據庫大小一定的情況下,最小支持度為 0.01 時,Apriori 算法改進前后的執行時間差異較大,算法改進后的執行效率較高;在最小支持度一定的情況下,隨著事務數據量的提升,Apriori 算法改進后的執行時間低于改進前,說明 Apriori 算法改進后的執行效率高。
為了驗證本文方法的性能,選取某電場工控設備作為實驗對象進行相關的實驗分析,將工控設備數據庫作為測試數據集。選用文獻 [6]的 DBN-RF 的工控設備狀態檢測方法和文獻 [7]的兩階段聚類的工控設備狀態檢測方法作為實驗對比方法。
分別采用 3 種方法對工控設備異常運行狀態進行檢測,得到 3 種方法的檢測誤差對比,結果如圖 5 所示。
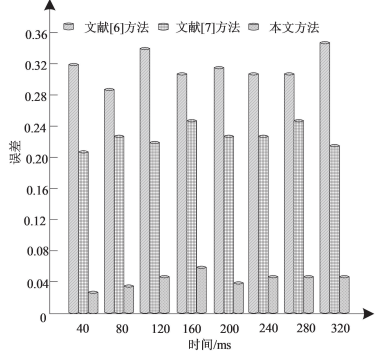
圖 5 檢測誤差對比
分析圖 5 可知,其他 2 種方法對工控設備異常運行狀態進行檢測的誤差顯著高于本文方法的誤差,其他 2 種方法的平均誤差分別約為0.3、0.2;而采用本文方法的平均誤差約為 0.05,說明本文方法對工控設備異常運行狀態的檢測精度較高。
分析本文方法檢測工控設備異常運行狀態的能力,結果如圖 6 所示。
分析圖 6 可知,本文方法可將數據集內異常運行的工控設備檢測出來,不受維度和設備故障類型數量的影響。利用本文方法檢測時,聚類的故障類型在三維空間內的距離較近,聚類的故障類型分布邊緣清晰。綜上所述,本文方法可有效檢測工控設備異常運行狀態,具備良好的應用性。
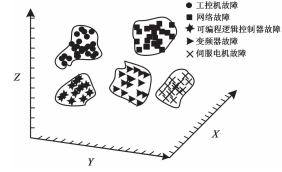
圖 6 工控設備異常運行狀態自動化檢測結果
以檢測故障類型的貼近度為衡量指標,設置其閾值小于 1,統計本文方法檢測工控設備異常運行狀態的故障類型貼近度,結果如圖 7 所示。
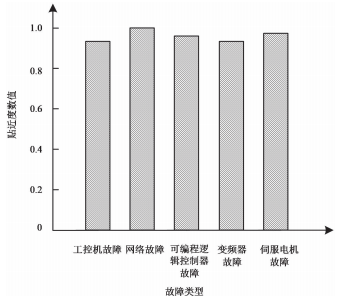
圖 7 故障類型貼近度
分析圖 7 可知,本文方法檢測工控設備異常運行狀態時的故障貼近度存在波動,但幅度較小。其中最大故障貼近度出現在由網絡故障引起的設備異常運行狀態檢測中,貼近度數值接近 1。最小故障貼近度出現在由工控機故障引起的設備異常運行狀態監測中,其數值約為 0.92。上述結果表明,本文方法在檢測工控設備異常運行狀態時的故障貼近度數值均小于 1,具有較為準確的檢測結果。
3 結 論
通過對某電廠 DCS 系統網絡全流量數據采集,并對數據采集過程中發生的機組異常跳機事件進行全面分析,通過日志挖掘與關聯分析,研究工控設備的異常運行狀態,實現工控設備異常運行狀態的自動化檢測。分析結果表明,網絡全流量數據“功在電網,利在電廠”,對電廠及電網的安全穩定運行有重要的指導意義和借鑒作用。
