基于 Stacking 的網絡惡意加密流量識別方法
摘 要:
隨著加密流量的普遍應用,許多惡意軟件開始隱藏在傳輸層安全協議(Transport Layer Security,TLS)流量中傳輸惡意消息,對通信安全造成嚴重威脅,因此對 TLS 惡意加密流量進行識別,對打擊網絡犯罪有著重要意義。通過對惡意和正常加密流量的會話和協議進行分析,在傳統會話統計特征的基礎上,提取出握手特征和證書特征,在單一特征和多特征條件下對惡意加密流量進行識別,證明了多特征的方法能顯著提升識別效果。此外,為解決單一的機器學習方法泛化能力弱的問題,提出了一種基于 Stacking 的網絡惡意加密流量識別方法,所提模型分類 ROC 曲線下方的面積(Area Under Curve,AUC)和召回率分別達到 99.7% 和 99.1%,在公開數據集上與XGBoost 等其他 4 種算法對比證明,所提算法性能有明顯提升。
內容目錄:
1 TLS 加密流量分析
1.1 TLS 協議分析
1.2 TLS 加密流量特征分析和提取
1.2.1 TLS 握手特征分析和提取
1.2.2 服務器證書特征分析和提取
1.2.3 會話的特征分析和提取
2 基于 Stacking 集成學習的加密惡意流量檢測方法
2.1 Stacking 集成模型
2.2 Stacking 模型構建
3 實驗結果及分析
3.1 實驗環境與數據集
3.2 評價指標
3.3 特征性能對比
3.4 元分類器選擇
3.5 算法性能對比
4 結 語
在安全和隱私保護需求的驅動下,加密流量在網絡中占據了越來越重要的地位。根據谷歌在2020 年發布的透明度報告,已經有 80% 的安卓應用程序默認使用傳輸層安全協議(Transport LayerSecurity,TLS)加密所有流量。根據 CISCO 2019年的報告,使用加密來隱藏遠程控制以及數據泄露等惡意行為的惡意軟件占比超過 70%,使用加密通信的惡意軟件幾乎覆蓋了所有常見類型 。因此,高效識別 TLS 惡意加密流量有重要的現實意義。
目前,已經有國內外研究人員對網絡惡意加密流量進行了研究,并且取得了一定的成就。Canard等人 提出了對加密流量進行深度包檢測(Deep Packet Inspection,DPI) 而 無 需 解 密 的 技 術, 但在設置階段需要大量的計算和較長的檢測時間。Torroledo 等人 通過考慮 TLS 協議中的證書,利用證書內容對惡意流量進行識別,但是此方法對無證書傳遞的加密會話惡意性檢測無效。Anderson 等人提出了一種 TLS 指紋識別系統,該系統利用目標地址、端口和服務器名精心構造了指紋串。但是,Matou?ek 等人 發現以取證為目的創建唯一且穩定的 TLS 指紋并不容易,惡意用戶可以通過惡意行為改變 TLS 版本、密碼套件等信息躲避檢測,因此指紋的發展受到了限制。此外,Anderson 等人在文獻中研究利用 TLS 握手階段的可用特征來識別加密惡意流量,但缺乏對握手階段外的特征考慮,且只使用了邏輯回歸分類器進行驗證。
鑒于此,本文在 TLS 加密流量特征分析的基礎上,提出了一種基于 Stacking 的網絡惡意加密流量識別方法。該方法通過對惡意流量和正常流量進行分析,提取出能識別惡意流量的會話特征、握手特征和證書特征,并在單一特征和多特征條件下對惡意加密流量識別進行對比,發現多特征的檢測方法能有效提升識別效果。為解決單一的機器學習方法在不同環境下的分類準確率難以保持穩定且泛化能力差的問題,構建 Stacking 模型并選擇合適的基學習器和元學習器,最后在公開數據集上進行訓練,實驗證明所提算法的識別效果優于現有方法。
01
TLS 加密流量分析
1.1 TLS 協議分析
TLS 協議是加密流量傳輸中常用的協議,也是保護許多明文應用協議的主要協議。圖 1 是一個完整的 TLS 握手過程。如圖 1 所示,首先,客戶端發送一條 ClientHello 消息,該消息為服務器提供了一系列密碼套件和一組客戶端支持的 TLS 擴展;其次,服務器發送一個 ServerHello 消息,其中包含從客戶端列表中選擇的加密套件,還包含服務器支持的擴展列表以及證書鏈的 Certificate 消息,該消息可用于對服務器進行身份驗證;再次,在客戶端發送 ClientKeyExchange 消息給服務器端后,客戶端和服務器交換 ChangeCipherSpec 消息,以后的消息將使用協商好的加密參數進行加密;最后,客戶機和服務器開始交換應用程序數據 。

圖 1 TLS 協議握手協商階段流程
傳統的通過 TLS 解密來查看流量密文內容的方式,不僅耗時,而且不能保護隱私。由于 TLS 協商的過程是通過明文來進行的,因此可以從未加密的消息中提取有用的信息。雖然證書是在 TLS 握手階段得到的,但由于其對分類結果的影響明顯,因此本文將證書作為單獨特征向量進行考慮。
1.2 TLS 加密流量特征分析和提取
1.2.1 TLS 握手特征分析和提取
握手特征從客戶端發送明文 Client Hello 消息和服務端反饋 Server Hello 消息中提取。圖 2 展示了惡意會話和正常會話的服務器對 TLS 加密套件的選擇對比和客戶端支持的曲線對比。為了更清晰地表示,將密碼套件用 16 進制代碼表示。
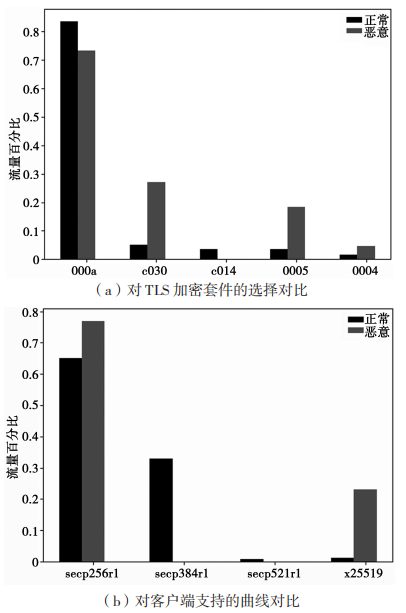
圖 2 惡意會話和正常會話密碼套件和曲線對比
服務器選擇的密碼套件針對大多數正常會話和惡意會話有嚴格劃分。大多數正常的加密會話服務器選擇的 TLS 密碼套件為 000a、c014。
其中:
“000a”:TLS_RSA_WITH_3DES_EDE_CBC_SHA
“c030”:TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
“c014”:TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
“0005”:TLS_RSA_WITH_RC4_128_SHA
“0004”:TLS_RSA_WITH_RC4_128_MD5
從圖 2(a)中可以看出,惡意軟件占比多的0004、0005 是比較弱的加密套件,安全性不足。從客戶端支持的曲線對比看出,除選用基于 256 bits的素數域 P 上的橢圓曲線(secp256r1)外,有 23%的惡意會話的客戶端依賴底層素數域特征為 的橢圓曲線(x25519),而有 33% 的正常會話選用基于 384 bits 的素數域 P 上的橢圓曲線(secp384r1)。
的橢圓曲線(x25519),而有 33% 的正常會話選用基于 384 bits 的素數域 P 上的橢圓曲線(secp384r1)。
此外,觀察到正常加密流量客戶端支持的擴展種類豐富,惡意流量客戶端擴展種類較為單一。提取出的 TLS 握手特征如表 1 所示。
表 1 TLS 握手特征

1.2.2 服務器證書特征分析和提取
服務器證書是用于驗證服務器身份的文件,普通認證機構(Certificate Authority,CA)證書由可信的 CA 機構頒發。自簽名證書任何人都可以頒發,它的 issuer 與 subject 相同。
在提取證書特征的過程中,證書的有效期、證書鏈的長度、證書是否自簽名等重要特征指標無法直接獲取,需要通過相應的算法來獲得。圖 3 展示了正常和惡意加密流量的服務器證書有效期時長對比和服務器證書的 issuer 長度對比。可以看出,正常的加密流量證書有效期較短,有 58% 的正常會話證書有效期是 80 天左右。而惡意加密流量有效期時間相對較長,甚至有 5.6% 達到 36 500 天。從服務器證書的 issuer 長度可以看出,60% 的正常加密會話的服務器證書 issuer 長度為 1,而惡意流量證書 issuer 長度為 2 和 3 的占比 86%。此外,觀察到 TLS 服務器使用自簽名證書的頻率和使用公鑰的長度等指標在惡意和正常加密流量中也有明顯區別。提取出的服務器證書特征如表 2 所示。
1.2.3 會話的特征分析和提取
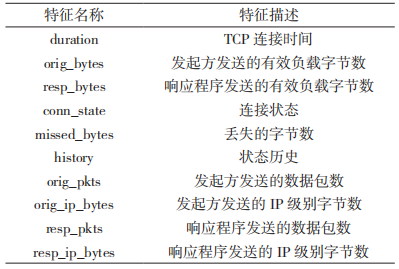
會話特征是現有文獻中的常見特征。通過觀察發現,大部分惡意軟件的接收數據包數量為 5~12個,而正常流量數據包的數量變化范圍較大。惡意加密流量的連接狀態為連接已建立,發起方中止RSTO 的最多,占比 43%,而正常加密流量的連接狀態以正常建立和終止 SF 的居多。此外,包長度、包到達時間等也是重要的會話統計特征。提取出的會話特征如表 3 所示。
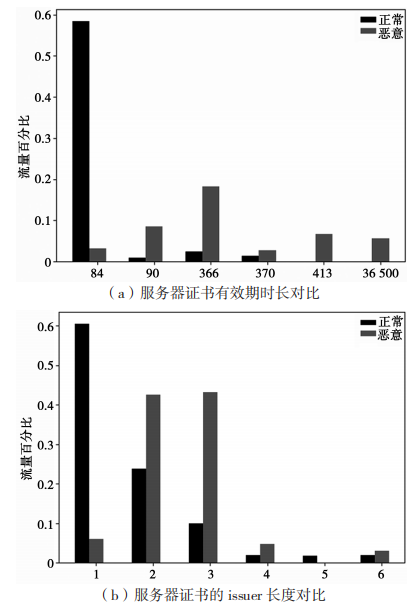
圖 3 惡意和良性流量證書有效期和 issuer 長度對比
表 2 證書特征

表 3 會話特征
02
基于 Stacking 集成學習的加密惡意流量檢測方法
2.1 Stacking 集成模型
Stacking 是組合異質分類器的集成學習方法,它融合不同的學習算法實現高精度的分類任務,能夠有效降低泛化誤差,并通過元學習器來取代Bagging 的投票法,來綜合降低偏差和方差。同時,Stacking 作為一種集成框架,往往采用兩層結構,第 1 層組合多個基學習器輸出特征,第 2 層使用元學習器組合第 1 層的輸出特征,給出最終的預測結果。研究表明,Stacking 在增加有限計算開銷的同時,有出色的性能和魯棒性。
Stacking 算法共分成 3 個步驟:
(1)根據原始數據 D 訓練第一層分類器,一共有T個分類器,其中ht是第t次循環得到的分類器;(2)根據第一層分類器的輸出,構造新的數據集,第一層的預測結果將作為數據的新特征,原始數據的標簽成為新數據的標簽;(3)根據新的數據集訓練第二層分類器得到新的分類器 h′,對于每一個數據實例 x, 分類器的預測結果為 , 其 中,
, 其 中,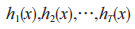 表示第一層中的分類器。
表示第一層中的分類器。
Stacking 算法偽代碼如下:


2.2 Stacking 模型構建
Stacking 集成方法通過將不同的算法結合在一起,發揮每個算法的優勢來獲得更佳的預測性能。在構建 Stacking 集成模型中,首先需要確定基學習器的種類,而基學習器的選擇需從準確性和多樣性兩個方面考慮。
從基學習器的預測性能方面考慮,本文除了選擇 隨 機 森 林(Random Forest,RF) 和 LightGBM[13]模型作為基學習器,還選擇了其他預測性能優異的模型。其中,XGBoost 針對傳統的梯度提升決策樹進行改進,在訓練時間等方面都有所提升。
為了獲得最佳的集成模型,還需要考慮基學習器之間的相關性。選擇相關性較小的算法能夠充分發揮不同算法的優勢 ,達到互補的目的。本文采用 Pearson 相關系數衡量算法之間的相關性大小,
其表達式為:

式中: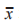 和
和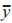 分別為各向量中元素的平均值。最后,依據基分類器追求“準而不同”的原則,初步選 擇 RF、K 近 鄰(K-Nearest Neighbor,KNN)、XGBoost、支持向量機(Support Vector Machine,SVM)和 LightGBM 作為基學習器。
分別為各向量中元素的平均值。最后,依據基分類器追求“準而不同”的原則,初步選 擇 RF、K 近 鄰(K-Nearest Neighbor,KNN)、XGBoost、支持向量機(Support Vector Machine,SVM)和 LightGBM 作為基學習器。
Wolpert 在提出 Stacking 時,就說明了元學習算法和新數據的屬性表示對 Stacking 集成的泛化性能影響很大 。對于輸出類概率的初級分類器,分類器 h 對樣例 x 的預測是,x 屬于所有可能類標簽的概率為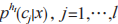 ,其中,
,其中,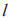 是指個分類問題,
是指個分類問題, 定義了分類器 h 估計樣例 x 屬于類別
定義了分類器 h 估計樣例 x 屬于類別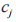 的概率值。將基分類器對所有類預測的后驗概率作為元層學習器的輸入屬性,乘以最大概率的概率分布,其表達式為:
的概率值。將基分類器對所有類預測的后驗概率作為元層學習器的輸入屬性,乘以最大概率的概率分布,其表達式為:
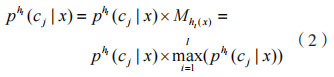
概率分布的熵為:

元模型通常很簡單,為了減輕過擬合,第二層元學習器選擇邏輯回歸模型。本文構建的基于Stacking 的加密惡意流量檢測模型如圖 4 所示。
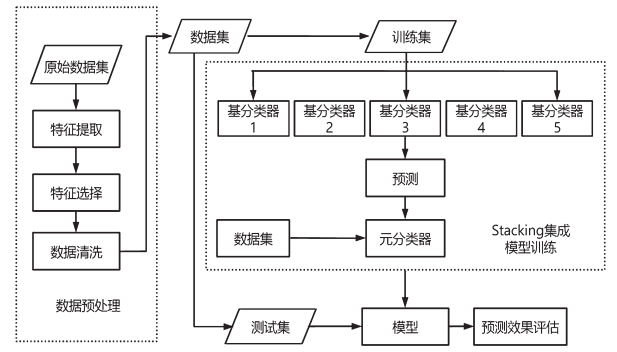
圖 4 基于 Stacking 的惡意加密流量識別算法流程
03
實驗結果及分析
3.1 實驗環境與數據集
本文采用 scikit-learn 機器學習庫構建 Stacking模型并完成實驗評估,在 Windows 10 環境下運行,處理器為 AMD Ryzen 4800H,圖形處理器(GraphicsProcessing Unit,GPU)為 RTX 2060,內存為 16 GB。
本實驗選用 DataCon 開放數據集 ,源自 2020年 2—6 月收集的惡意軟件與正常軟件,經奇安信技術研究院天穹沙箱運行并采集其產生的流量篩選生成,數據集格式為 pcap 文件。由于本文研究需要更精確的數據集,對數據進行以下處理:
(1)過濾未完成完整握手過程的會話;(2)過濾確認包、重傳包及傳輸丟失的壞包;(3)借助 Zeek[18] 將 pcap 包轉換為流量日志,進行特征提取;(4)特征提取后對非數值型的特征流量使用One-Hot 編碼,滿足模型輸入的需要;(5)對特征的缺失值和異常值進行處理,采用 Z-score 對數據進行標準化。經過數據預處理后,最終的數據集如表 4 所示。
表 4 最終數據集構成

3.2 評價指標
本文采用精確率(Precision)、召回率(Recall)、F1 值和 ROC 曲線下方的面積(Area Under Curve,AUC)值作為評價指標來估計方法的分類效果。精確率(Precision)、召回率(Recall)和 F1 值的定義分別為:

式中:TP 為被模型預測為正類的正樣本數量;FN為被模型預測為負類的正樣本數量;FP 為被模型預測為正類的負樣本數量。
3.3 特征性能對比
本文提取出會話統計特征 86 維,握手特征 62維和證書特征 31 維,共計 179 維特征向量。為了分析不同特征組合的性能,使用隨機森林算法分別測試了 3 種特征組合下的識別效果,實驗結果如表 5 所示。
表 5 不同的特征組合五折交叉驗證結果

為了減小特征冗余和噪聲,去除相關度高及有負影響的特征,使用特征篩選算法 Correlation AttributeEval,分別選擇特征從 10 到 100 維的 10 種情況進行實驗,確定特征維數為多少時,模型分類效果最佳,實驗結果如圖 5 所示。

圖 5 特征維數確定
當特征維數為 30 時,使用隨機森林算法分類時,F1 最高,達到 97.2%。此后隨著維數的增加,F1 值逐漸降低。因此,本文將特征維數縮減到 30 來進行實驗,在提高識別效果的同時縮短了運行時間。不同特征組合下分類性能對比如圖 6 所示。
圖 6 不同特征組合對檢測結果的影響對比
可以看出多特征識別顯著提升了模型精確率和召回率,特征篩選進一步提升了模型的性能。
3.4 元分類器選擇
為 了 減 輕過 擬 合, 第 二 層 元 學 習 器 一 般 選擇簡單的模型,本文選擇邏輯回歸作為元分類器學習。表 6 比較了常用于 Stacking 模型中的 K 近鄰(K-Nearest Neighbor,KNN)、 支 持 向 量 機(Support Vector Machine,SVM)和邏輯回歸(LogisticRegression,LR)算法作為基分類器的差異。結果表明 LR 算法作為元學習器時,Stacking 模型表現最好。
表 6 元學習器對比

3.5 算法性能對比
將 本 文 構 建 的 Stacking 模 型 與 SVM、RF、XGBoost、CNN 算法對比,實驗結果如表 7 所示。
表 7 算法性能對比
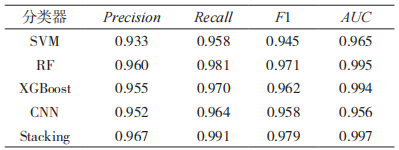
由表 7 可以看出,本文構建的 Stacking 模型的查準率、召回率、F1 值和 AUC 值均高于其他算法模型。與 SVM 相比,分別提高了 3.4%,3.3%,3.4%和 3.2%;與 XGBoost 相比,分別提高了 2.2%,2.1%,1.7% 和 0.3%;與 CNN 相比,分別提高了 1.5%,2.7%,2.1% 和 4.1%。因此,通過上述對實驗結果的分析,驗證了本文提出的基于 Stacking 的網絡惡意加密流量識別方法的可行性。
04
結 語
本文通過分析大量的正常和惡意加密流量,從中提取出具有顯著區分度的會話特征、握手特征和證書特征。對單一特征和多特征識別網絡惡意加密流量進行對比,結果表明加入了握手和證書特征后可以顯著提升模型的識別效果。構建基于 Stacking集成學習的網絡惡意加密流量檢測模型,實驗表明,在 Datacon2020 數據集下,本文 Stacking 模型效果比 XGBoost 等 4 種算法效果均有所提升,解決了單一的機器學習方法泛化能力弱的問題。此外,文章還存在一些不足之處,如在構建 Stacking 模型時可以嘗試更多基分類器和元分類器的組合,從而作出更優的選擇,這也是今后進一步研究的方向。
