數據安全:漏洞、黑客、網絡爬蟲、數據黑產
1. 漏洞:數據泄露的重要源頭
近年來,數據泄露事件屢屢發生,數據泄露數量不斷增加,波及眾多行業,給企業和用戶帶來了不可估量的嚴重后果。據金雅拓(Gemalto)發布的數據泄露水平指數(Breach Level Index)調查報告,2018年上半年,全球共發生了945起數據泄露事件,導致共計45億條數據被泄露,過去5年有近100億條記錄被泄露,平均每天泄露的記錄超過500萬條。
系統漏洞正是造成數據泄露的罪魁禍首之一。2018年,Facebook遭遇自創立以來的至暗時刻,全年3次被曝發生數據泄露事件,其中2次都與系統漏洞直接相關,涉及約1億用戶。2018年9月,Facebook在泄露5000萬條用戶信息后再次卷入數據泄露旋渦,其系統因安全漏洞遭黑客攻擊,導致3000萬條用戶信息泄露,包括1400萬條用戶的姓名、聯系方式、搜索記錄、登錄位置等敏感信息。12月,Facebook再次被曝因軟件漏洞可能導致6800萬用戶的私人照片泄露。
2018年3月,美國運動品牌安德瑪旗下的健身應用MyFitnessPal因存在系統漏洞遭到黑客攻擊,導致1.5億條用戶數據被泄露,涉及用戶名、電子郵件地址和密碼等信息。美國票務巨頭Ticketfly、面包連鎖店Panerabread以及谷歌等企業均曾因系統漏洞導致數據泄露。
由系統漏洞引發的數據泄露事件不一而足,那什么是漏洞呢?在計算機領域,漏洞特指系統存在的弱點或缺陷,一般被定義為硬件、軟件、協議的具體實現或系統安全策略上存在的缺陷。
1947年9月9日,美國海軍對Mark II型計算機進行測試時,計算機突然發生了故障。經過幾個小時的檢查,當時的美國海軍中尉、電腦專家格蕾絲·霍波(Grace Hopper)發現,一只被夾扁的小飛蛾卡在了Mark II型計算機的繼電器觸點之間,導致電路中斷。將飛蛾取出后,計算機恢復正常。霍波在工作日志上寫道“:就是這個Bug(蟲子)害我們今天的工作無法完成。”自此,“Bug”一詞被當作計算機系統缺陷和問題的專業術語一直沿用至今。在日常生活中,人們也通常將Bug與漏洞畫上等號。
漏洞伴隨著系統的誕生而持續存在。目前,大型信息系統的代碼動輒數百、上千萬行,Windows 7操作系統有5000萬行代碼,Windows 8有上億行代碼,其中潛藏著成千上萬的漏洞。更可怕的是隨著信息系統運行、檢測、迭代升級,盡管絕大部分漏洞被發現并及時清除,但仍有部分漏洞如附骨之疽一樣難以被發現,更不會被修復,成為持續影響系統安全、造成系統持續不安全的重要源頭。例如,2018年1月發現的能影響幾乎所有Intel CPU、AMD CPU和部分ARM CPU的Meltdown(熔斷)和Spectre(幽靈)漏洞,其產生時間可追溯至1995年,當時CPU剛剛開始使用亂序執行和預測執行等硬件設計特性。微軟自動認證漏洞、BadTunnel漏洞、Windows打印機漏洞、Shellshock漏洞等在被發現并修復之前,潛藏時間均超過20年。
2. 黑客:游走在漏洞邊緣的逐利者
黑客攻擊是導致數據泄露的最主要原因。根據金雅拓統計,56%的數據泄露事件是由“惡意的外部入侵者”引發的。IBM的研究報告顯示,犯罪攻擊導致了48%的數據泄露事件,漏洞攻擊、病毒利用、“撞庫”等是主要的數據獲取方式。
2018年8月28日,華住酒店集團旗下酒店共計5億條用戶信息在暗網被售賣,涉及用戶姓名、身份證號、手機號、郵箱、家庭住址、生日、入住時間、離開時間、酒店ID號、房間號及消費金額等敏感信息。根據調查,該事件是由疑似華住程序員在GitHub(面向開源及私有軟件項目的托管平臺)上傳的名為CMS的項目被黑客攻擊所致。
2018年1月,印度的10億公民身份數據庫Aadhaar被曝遭網絡攻擊,姓名、電話號碼、郵箱地址、指紋、虹膜記錄等極度敏感的用戶信息被泄露。根據調查, Aadhaar數據庫的登錄和e-Aadhaar的下載存在風險,允許第三方通過白名單IP地址登錄Aadhaar數據庫,訪問相關數據。
2017年10月3日,雅虎的母公司——美國電信巨頭威瑞森表示,雅虎所有30億用戶的個人信息均于2013年被黑客竊取,涉及用戶姓名、聯系方式、密碼以及安全問答等敏感信息。
人為因素是數據泄露的重要原因。據IBM統計,25%的數據泄露事件由人為因素導致。人為因素分為兩種情況:一種是企業內部人員或承包商因設備配置不當、工作疏忽,導致數據暴露在公開的互聯網上;另一種是企業內部人員或承包商實施惡意的內部攻擊,導致數據泄露。
2018年6月,美國Exactis公司因服務器沒有防火墻保護,使2TB數據庫直接暴露在公共互聯網上,導致上億條美國成年人的個人信息和數百萬條公司的信息被泄露,這些敏感信息包括電話號碼、家庭住址、電子郵箱,以及宗教信仰、是否吸煙、興趣愛好、個人習慣等,幾乎可以構建一個人的完整“社會肖像”。
2018年6月發生的事件還有10億條圓通快遞數據在暗網被兜售。根據賣家描述,售賣數據包括寄(收)件人姓名、電話、地址等信息,是由圓通內部人士批量出售的2014年下旬的數據。經網友驗證,姓名、電話、住址等信息均屬實。考慮到泄露數量之大、準確率之高,外界普遍認為數據來源為圓通內部較高級別的工作人員。
由于用戶數據涉及大量個人隱私,其重要性對用戶不言而喻。然而,作為數據的生產者、擁有者,用戶難以掌握自身數據的流轉軌跡,數據泄露后難以第一時間獲知,甚至在泄露數據多次轉手,被用于精準營銷、詐騙時,都不清楚到底是哪里出了問題。
為什么會出現這樣的情況呢?有以下幾方面的原因。
第一,企業和用戶一樣“無知”。當前,大部分企業對數據泄露等數據安全問題的認識不到位,總以為不會得到黑客的“眷顧”,并且沒有建立相應的監測預警、應急響應機制和手段,不僅發現不了數據泄露,而且難以及時應對和補救。根據IBM統計,企業發現數據泄露的平均時間是197天,控制數據泄露造成的后果還額外需要平均69天。當然,發現數據泄露的時間越長,控制數據泄露的時間越久,企業和用戶的損失也就越大。國內外企業大規模數據泄露事件舉例如表1所示。
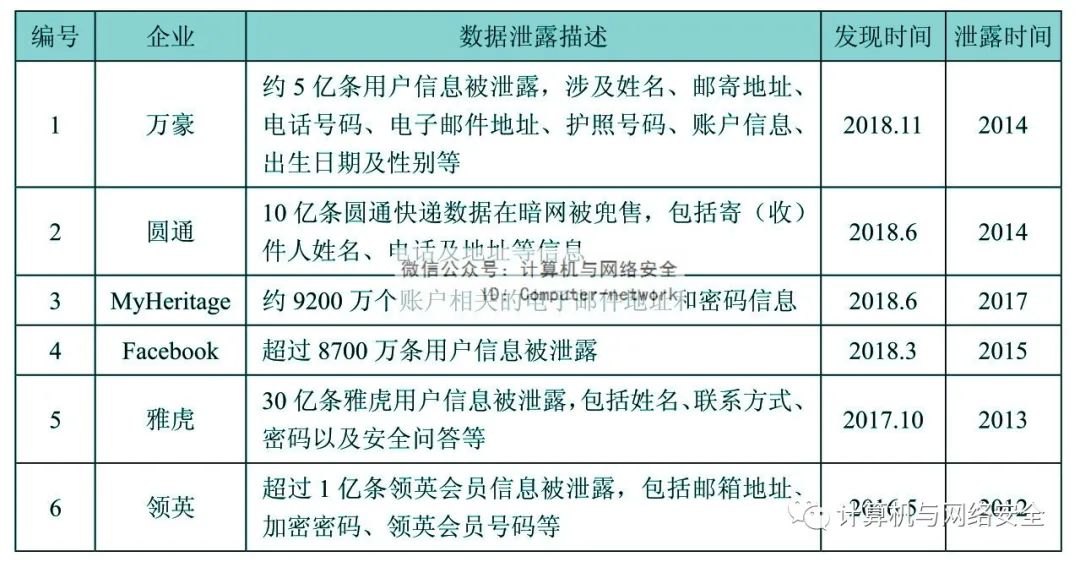
表1 國內外企業大規模數據泄露事件
從表1中可以看出,不僅酒店、快遞等行業企業,Facebook、雅虎等互聯網巨頭對數據泄露的感知能力都很差,數據泄露發生與發現的時間間隔普遍較長,對企業和用戶造成的損失自然也更大。
第二,企業比用戶更“先知”。如果企業受限于自身能力難以發現數據泄露,未能及時向用戶預警,還能說是情有可原,那么發現數據泄露卻知情不報就另有意味。
2017年11月,Uber發布聲明,承認其在2016年曾遭黑客攻擊并導致數據大規模泄露。當時,黑客竊取了5700萬條用戶數據,包括用戶姓名、郵箱和手機號等敏感信息。然而,據彭博社報道,Uber在得知數據被竊取后沒有第一時間向政府機構報告,也沒有及時通知用戶采取防范措施,而是向黑客支付了10萬美元,試圖銷毀被盜數據以隱瞞泄露事件。
2017年9月,美國發生了歷史上最大規模和影響的數據安全事件。征信機構Equifax的1.45億條美國公民的信用記錄被泄露,包括姓名、社會保障號、出生日期、地址以及一些駕駛證號碼等。美國約20.9萬名消費者的信用卡詳情和涉及18.2萬人的爭議文件也可能遭到泄露,Equifax在英國和加拿大的數千萬名顧客也受到影響。根據調查,Equifax在數據泄露事件發生前忽略了國家安全部、安全專家發來的大量關于隱私數據威脅的警告;事件發生后,Equifax也是在確認數據泄露的第40天才向客戶、投資者和管理者發送通告,導致數據泄露的影響進一步擴大。
3. 網絡爬蟲:數據泄露的新渠道
大數據時代,企業收集數據的方式多種多樣。除了直接通過用戶采集之外,還包括傳感器采集、網絡爬蟲采集等方式。其中,利用網絡爬蟲采集公開信息是企業數據的重要來源。相關數據顯示,50%以上的互聯網流量其實都是爬蟲貢獻的;對于某些熱門網頁,爬蟲的訪問量甚至占據了總訪問量的90%以上。
所謂網絡爬蟲又稱網頁蜘蛛、網絡機器人,是一種按照一定規則自動從互聯網上提取網絡信息的程序或腳本。本質上,網絡爬蟲是通過代碼實現對人工訪問操作的自動化。但是,網絡爬蟲具備的代碼解析能力使其可能訪問到人工不會訪問或者無法訪問的內容。技術都具有兩面性,雖然網絡爬蟲已廣泛應用,但絕不能無限制使用。過度使用網絡爬蟲,可能引發一些問題:過于野蠻的數據爬取操作可能加大網站負荷,導致網站癱瘓,等等;用爬取技術獲取數據,可能導致數據所有者失去對數據的唯一擁有權。如果爬取數據中的企業信息和個人信息未經授權或被不正當地使用,可能引發商業糾紛,侵犯個人的合法權益。
為了規范網絡爬蟲行為,荷蘭軟件工程師馬蒂恩·科斯特(Martijn Koster)于1994年2月起草了網絡爬蟲的規范——Robots協議。Robots協議全稱網絡爬蟲排除標準(Robots Exclusion Protocol),又稱爬蟲協議、機器人協議,實質上是為了解決爬取方和被爬取方之間通過計算機程序完成關于爬取的意愿溝通而產生的一種機制。Robots協議存在于網站中,負責告訴網絡爬蟲哪些頁面可以抓取,哪些頁面不能抓取。Robots協議是行業廣泛遵守的規范,但它只是一個未經標準組織備案的非官方標準,也不屬于任何商業組織,不具有強制性,相當于一個“君子約定”。
無視Robots協議抓取數據存法律風險。近兩年,因抓取數據而遭遇訴訟被處罰金,甚至鋃鐺入獄的案例逐步增多;是否遵從Robots協議,也逐步從行業規范上升為量刑的重要依據。2017年,今日頭條起訴上海晟品網絡科技有限公司采用技術手段非法抓取視頻數據。經審理,上海晟品被判定構成非法獲取計算機信息系統數據罪。根據判決書,上海晟品使用偽造device_id繞過服務器的身份校驗、使用偽造UA及IP繞過服務器的訪問頻率限制等破解防抓取措施的行為,成了獲罪的重要依據。根據《中華人民共和國刑法》第285條規定,非法獲取計算機信息系統數據、非法控制計算機信息系統罪,是指違反國家規定,侵入國家事務、國防建設、尖端科學技術領域以外的計算機信息系統或者采用其他技術手段,獲取該計算機信息系統中存儲、處理或者傳輸的數據,情節嚴重的行為。結合上述案例,企業和個人在使用爬蟲技術抓取數據時切勿突破、繞開反爬蟲策略及協議,切勿破解客戶端、加密算法。
近年來,由惡意網絡爬蟲引發的數據泄露事件也逐步增多。2017年,58同城的全國簡歷數據泄露引發軒然大波。有淘寶電商出售“58同城簡歷數據”:一次購買2萬份以上,0.3元一條;一次性購買10萬份以上,0.2元一條;同時,支付700元即可購買爬取軟件。安全專家分析,出售的數據爬取軟件本質上是一個惡意爬蟲工具,利用58同城系統的漏洞爬取相關信息。根據正常的商業模式,58同城、智聯招聘、前程無憂等招聘網站允許企業和個人訪問簡歷信息,網絡爬蟲自然也在許可范圍之內。但是,無論企業、個人還是網絡爬蟲,都只能看到部分的簡歷內容,個人聯系方式等敏感的簡歷內容需要付費才可以查看。然而,58同城系統的多個安全技術漏洞的組合使網絡爬蟲一步步獲取到了用戶的全部簡歷信息。具體地說,第一個漏洞允許爬蟲批量獲取用戶的簡歷ID,第二個漏洞會導致用戶姓名等真實信息泄露,第三個漏洞允許爬蟲通過用戶ID抓取用戶的電話號碼。在多個漏洞的疊加影響下,用戶的簡歷信息也就沒有秘密可言了。
那么,企業和個人應該如何使用網絡爬蟲這把雙刃劍呢?有專家指出,爬取數據前,首先識別數據性質,嚴格禁止侵入內部系統數據;爬取數據時,避免獲取個人信息、明確的著作權作品、商業秘密等;爬取數據后,嚴格限定數據應用場景,切忌不勞而獲、“搭便車”地利用他人數據,侵害他人的商業利益。
4. 數據黑產:分工明確的數據利益鏈條
大數據時代,信息的高速流轉和運營創造了空前的價值,隨之而來的信息數據倒賣猖獗,企業大規模數據泄露事件頻發,數據安全如臨深淵。
根據南方都市報聯合阿里巴巴發布的《2018網絡黑灰產治理研究報告》, 2017年我國網絡黑產已達近千億元規模,全年因垃圾短信、詐騙信息、個人信息泄露等造成的經濟損失估算達915億元,電信詐騙案每年以20%~30%的速度增長。據不完全統計,2015年,我國網絡黑產從業人員就已經超過40萬人;截至2017年中,我國網絡黑產從業人員已超過150萬人。據阿里安全歸零實驗室統計,2017年4月至12月共監測到電信詐騙案件數十萬起,涉及受害人員數萬人,損失資金超過億元。2018年,活躍的專業技術黑灰產平臺多達數百個。
在網絡黑產早期,數據是網絡黑產的重要基礎,貫穿網絡黑產的上中下游,支持攻擊者實施詐騙、騷擾、劫持流量等定向或非定向攻擊。近年來,隨著數據價值的提升,以數據交易、數據清洗、數據分析為核心的數據黑色產業鏈逐漸完善,網絡黑產迎來了以數據黑產為代表的新時代。
目前,龐大的數據黑產已經相當完整。根據產業鏈內各角色分工的不同,數據黑產大致可分為上游、中游、下游三部分,如圖1所示。
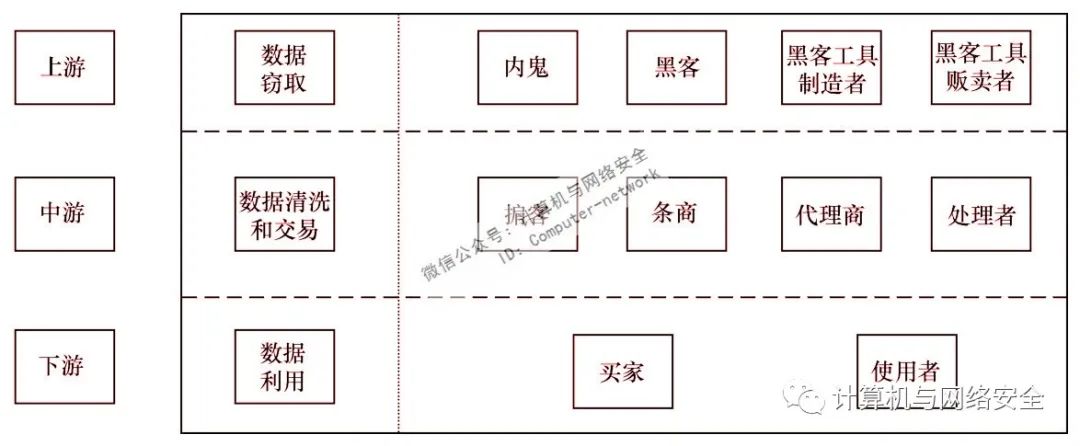
圖1 數據黑產上中下游示意圖
數據黑產的上游以內鬼、黑客為主,他們通過訪問特權或非法入侵企業信息系統獲取數據;為黑客實施攻擊提供工具支撐的工具制造者、販賣者等,也屬于數據黑產的上游。數據黑產的中游以掮客、條商、代理商及處理者為主,他們負責數據的交易和流轉。數據黑產的下游主要是各類數據買家和使用者,這些購買的數據往往用于精準營銷、身份認證及電信詐騙等。
數據泄露是數據黑產的源頭。根據360互聯網安全中心發布的《2016年網站泄露個人信息形勢分析報告》,2016年遭到泄露的個人信息約為60.5億條,平均每人就有4條相關的個人信息被泄露。這些信息最終的命運是在黑市中被反復倒手,直至被榨干價值。
我們總以為黑客、網絡攻擊及病毒等是造成數據泄露的主要原因。然而,追究數據泄露源,事實不免讓人悲哀。相關調查顯示,80%的數據泄露是企業內部人員所為,黑客和其他方式僅占20%。根據一份FBI和犯罪現場調查(CSI)等機構聯合發布的調查報告,超過85%的網絡安全威脅來自內部,危害程度遠遠超過黑客攻擊和病毒造成的損失。根據世界通信技術行業巨頭威瑞森發布的《2018年數據泄露調查報告》,超過1/4的數據泄露是由內部人員造成的。我們常常把泄露組織機密信息的人稱為“內鬼”或“細作”,而內鬼越來越成為數據泄露的罪魁禍首。
2018年9月,亞馬遜被曝其部分員工通過中間人向亞馬遜的商家出售內部數據和其他有關客戶的機密信息,使購買數據的商家在競爭中獲得優勢。2018年6月,特斯拉起訴一名前員工盜取公司的商業機密并向第三方泄露了大量公司內部數據,這些數據包括數十份有關特斯拉生產制造系統的機密照片和視頻等。2018年5月,江蘇常州警方破獲“6· 18”特大侵犯公民個人信息案,涉及內鬼多達48名,涵蓋銀行、衛生、教育、社保、快遞、保險及網購等多個行業,包括個人征信、開房住宿及收貨地址等數十種實時信息。2017年初,央視曝光了一起涉及50億條公民信息的數據泄露事件,嫌犯是京東網絡安全部的內部網絡工程師。根據調查,嫌犯利用京東網絡安全部員工的身份,為黑客提供大量在京東、QQ上的物流信息、交易信息及個人身份等數據;嫌犯還曾通過相似手段入侵多家互聯網公司的服務器,從中竊取并倒賣公民個人信息,實施盜刷銀行卡等違法犯罪活動。
隨著產業鏈上中下游分工的逐步明確和細化,第三方服務機構成為數據泄露的新主體。2018年8月,浙江警方破獲了一起上市公司非法竊取用戶數據案,堪稱“史上最大規模數據竊取案”。據悉,上市公司瑞智華勝借助為國內電信運營商提供精準廣告投放系統的開發、維護的機會,將自主編寫的惡意程序部署到運營商內部的服務器上,非法從運營商流量池中竊取搜索記錄、出行記錄、開房記錄及交易記錄等30億條用戶數據,導致百度、騰訊、阿里巴巴、今日頭條等全國96家互聯網公司的用戶數據被竊取,國內幾乎所有的大型互聯網公司均被“雁過拔毛”。
數據清洗是數據黑產的關鍵步驟。“撞庫”是數據清洗的第一步。在介紹“撞庫”的概念之前,我們先了解一下“撞庫”的兄弟“拖庫”。“拖庫”是指黑客入侵有價值的網站和信息系統,以TXT、XLS等格式從數據庫中導出數據的行為。2017年3月,迅雷就曾遭到“拖庫”,500萬用戶的密碼全部泄露。通常,“拖庫”竊取到的郵箱、社交軟件等賬號及密碼信息大多是單一、無效的,或者有些數據庫中存儲的密碼是經過加密的,難以直接使用。這時就需要使用“撞庫”的辦法對獲得的數據進行清洗。
“撞庫”是指黑客通過收集整理互聯網上已泄露的用戶名、密碼等信息生產對應的字典標準,嘗試對其他網站進行批量登錄,以得到可登錄的有效用戶名和密碼等信息的過程。用戶為圖省事,經常在多個網站設置同樣的用戶名和密碼,一旦其中一個網站的信息遭到泄露,就很容易被黑客通過“撞庫”攻擊的方式順藤摸瓜,獲取手機號、身份證號、家庭住址及銀行賬戶等敏感信息。2016年10月,網易遭遇“撞庫”攻擊,導致網易163、126郵箱過億條數據被泄露,包括用戶名、密碼、密碼保護信息、登錄IP以及用戶生日等。
經過“撞庫”清洗后,賬號、密碼的有效性更強,可以精準獲取用戶多平臺的相關注冊信息,數據內容更豐富。這在犯罪分子眼中極具價值,價格也水漲船高。
“拖庫”“撞庫”的流程示意如圖2所示。

圖2 “拖庫”“撞庫”的示意圖
在數據黑產中,數據交易是數據變現的重要方式之一。根據騰訊安全發布的《信息泄露:2018企業信息安全頭號威脅報告》,賬號/郵箱類數據、個人信息、網購/物流數據是黑客交易最受歡迎的產品,交易量占比分別為19.78%、12.19%、9.69%。360企業安全發布的《2018年暗網非法數據交易總結》顯示,金融行業、互聯網行業和生活服務行業涉及的交易數據最多,占比分別達23.1%、16.3%、6.1%。近年來,我國非法數據交易現象日益猖獗。2016年6月—2018年8月,我國發生十余起涉及過億條個人信息非法交易的案件,并逐步呈現出產業鏈作案特征。
數據交易在具備變現屬性的同時,也是數據清洗的關鍵一環。據地下數據產業資深人士透露,隨著數據需求的持續放大,非法數據交易等數據黑產有公開化的趨勢。部分大數據初創企業通過購買各種渠道的數據,其中不乏黑客、內鬼甚至暗網出售的數據,整合數據資源,降低數據成本,提供更全面的數據服務。在這樣的業務模式下,不同出身的各種數據實現了合法流通,無疑更刺激了數據非法交易。
經過數據交易、數據清洗等環節的復雜運作,泄露的涉及姓名、電話、身份證、銀行卡及家庭住址等真實信息的各種數據最終流入各類數據買家和使用者手中,充分展現了數據的“價值”。電信詐騙、精準營銷是數據變現的最終環節。當前,很多企業紛紛整合自有和外部數據資源,在用戶畫像的基礎上針對行業客戶提供精準廣告投放服務,推銷電話、短信騷擾、垃圾郵件和廣告彈窗等成為我們最常遇到的騷擾情況。個人信息泄露后,上門推銷、詐騙電話、垃圾郵件不請自來。調查顯示,中新網PC端與微信端均有超過70%的網友表示,詐騙電話、短信是自己信息被泄露后最困擾自己的事情。銀聯數據顯示,90%的電信詐騙案、盜竊銀行卡、非法套現、冒用他人銀行卡及網絡消費詐騙等都是由于個人數據泄露引發的。2016年8月21日,山東女大學生徐玉玉被詐騙分子以發放助學金的名義騙走全部學費9900元,在報警回家的路上猝死。究其原因,就在于徐玉玉準確的錄取信息、手機號碼等個人信息被竊取、販賣,進而引發了精準的電信詐騙。
