【技術分享】安全分析中的威脅情報(一)
背景
近兩個月實在太忙,這一篇博客拖到現在。本來計劃開一個安全分析的系列,但因為工作原因擱置了。端午去成都吃火鍋,往返飛機上寫出這篇《安全分析中的威脅情報》。作為安全分析系列文章的開篇。
何為威脅情報
我將威脅情報定義為:經過研判過的安全信息。
這里有三個實體:研判,安全信息,威脅情報。三者的關系為:
安全信息 + 研判 = 威脅情報
任何未經研判的安全信息,都不能稱之為“威脅情報”。威脅情報用于輔助支持決策或者安全分析,未知來源和真實性的安全信息將影響決策的正確性和分析結果的準確性。
威脅情報是目標現在(以及過去)一段時間的狀態描述;它受安全信息的數量、質量,以及研判過程合理性影響,使得威脅情報并不是百分百正確。
安全信息收集
安全分析依賴獲取和使用數據的能力,所以安全分析首先要克服的第一個問題就是:“如何收集安全信息”。
之前寫過一篇 《小議安全分析生命周期》 。其中表達了一個觀點:安全分析的起點應該是“確定目標”。在此也適用,在安全信息收集計劃前,應該明確目標和范圍,制定的信息收集計劃應包含“所要處理信息類別”,“信息研判可行的切入點”,“盡可能廣泛的來源渠道”,以及“何時進行信息收集”。
針對信息本身,在收集時必須注意以下幾點:
- 輸入信息高清潔度,盡量避免無用的數據
- 信息的高可用
- 保證信息的高精度
- 信息源的覆蓋面要沒有疏漏
- 信息源必須可信
- 信息必須及時
講了那么多信息收集的要求,說一下信息的來源:OSINT、封閉、機密。
- OSINT 是可公開獲取的數據,是最常見的信息獲取途徑。其中包括,媒體,機構,開放博客,社交平臺,會議論文,大廠公告等等。單反能通過互聯網訪問的信息,都屬于OSINT 數據,該數據源通常采用爬蟲,爬取網頁、api、RSS或者郵件訂閱。市面上也有很多基于 OSINT 數據的威脅情報平臺。使用該來源的信息,通常面臨信息清潔度、精度、覆蓋面…信息收集需要注意的問題。因為開放意味著公共,陳雜,不準確,冗余…使用OSINT數據,必須要解決的時信息處理相關的問題。
- 封閉數據是為了特定方向收集的信息,這方面往往對公開訪問進行限制。對應VT、riskiq、Recorded Future、微步在線……此來源的數據可能獨家,也可能是基于公開情報二次開發。這樣的信息,要比OSINT更有價值,但獲取這樣的數據需要一定的代價。
- 機密數據是通過特定的手段,隱蔽的手段收集的信息,這樣的信息非常準確,高可用,高可信,高精度且及時。但是覆蓋面很窄,僅能滿足單個需求點。此方面的數據來源,以蜜罐為代表。
安全分析人員,要基于全源分析,而不是僅局限于易于獲取的信息。不管什么方式,出發點都是獲取到想要的信息,目標都是導出決策需要的高質量情報。從成本上看,開源數據收集成本要遠遠低于部署私密的資產;開源數據獲取難度低,但是處理量極大,所以更合理的信息獲取結構是,三者互補進行。
信息研判
在信息收集階段,僅僅是構建信息獲取的途徑,針對的是來源,而不是信息本身。 對信息本身進行研判,才能將其轉變成威脅情報。
信息研判是威脅情報生命周期中極為重要的一個環節。主流的研判方式:人肉去看或者跑一些機器學習的算法。
人的主觀研判十分準確,既然是人,肯定有自己擅長的領域以及知識盲區,“人”對非擅長領域的信息是很難進行判斷的;同時,人的精力是有限的,面對海量信息顯得有些乏力。
為了解決人主觀研判的弊端,有一些廠家,引入了機器學習來進行信息研判這個工作。不可否認,這是信息爆炸時代下的趨勢。受限于當前機器學習發展的瓶頸,很難有一個算法可以全自動地進行信息研判,然后把準確率四個九的處理結果拍我臉上,直接告訴我這就是準確的威脅情報。這是不可能的。
威脅情報是要用來做決策,支持我們分析的。但凡達不到準確率99.99%的威脅情報,都不能直接用于實際生產。非完全可信的情況下,必須要有人介入才行。這也間接說明了,安全分析和安全運營的必要性。安全分析領域,人機協同在未來一段時間依舊是主流。
信息研判模型
就 OSINT 信息研判,講一講信息研判的具體方法。
研判過程三個基本原則:
- 不能有主觀影響
- 必須要對信息源進行評估
- 信息要盡可能的靠近源頭
許多人做研判又是NLP,又是建立詞庫,或者甚至監督/無監督機器學習直接懟,這些都沒有到點子上。我不否認這些工作的必要性。但是思路多多少少有些歪。
所以,我認為信息研判的兩個方面:
- 信息來源
- 信息本身
許多人對信息研判只關注信息本身,而忽略來“信息來源”這個維度。補上來源可靠性判斷,對信息研判準確率會有一個較大的提升。
研判尺碼
如果基于這兩個維度上,做一些細顆粒的劃分上,是不是更容易落地?再次給出一些評判的尺碼:
信息來源:
- 完全可靠
- 真實性、完整性、可靠性、專業領域全部可信
- 歷史記錄中,該信息源無污點記錄
- 通常可靠
- 真實性、完整性、可靠性、專業領域有個別問題(其中某項)
- 歷史記錄中,該信息源有個別污點記錄
- 一般可靠
- 真實性、完整性、可靠性、專業領域有一些問題(其中兩項)
- 歷史記錄中,該信息源有一些污點記錄
- 未知
- 信息來源屬性無法判斷,且無歷史信息記錄
- 不可信
- 真實性、完整性、可靠性、專業領域方面有一定懷疑
- 歷史記錄中,該信息源有一些污點記錄
- 一定不可信
- 真實性、完整性、可靠性、專業領域方面有明確質疑
- 歷史記錄中,該信息源有大量污點記錄
信息本身:
- 質量極高
- 其他獨立來源確認該信息可靠
- 該信息在我們關注的范圍內
- 該信息符合邏輯
- 質量高
- 其他獨立來源確認該信息可靠
- 該信息與我們關注的范圍有一定偏差
- 該信息符合邏輯
- 質量一般
- 不能從其他獨立來源確定可靠性,但符合邏輯
- 該信息在我們關注的范圍內
- 未知
- 信息本身的可靠性,邏輯性和關注匹配度無法確定
- 質量低
- 不能從其他獨立來源確定可靠性,但符合邏輯
- 該信息與我們關注的范圍有一定偏差
- 沒有價值
- 不能從其他獨立來源確定可靠性,不符合邏輯
- 該信息與我們關注的范圍有一定偏差
尺碼標出來后可以以信息來源為Y軸,信息本身為X軸,未知狀態為原點建立坐標系:
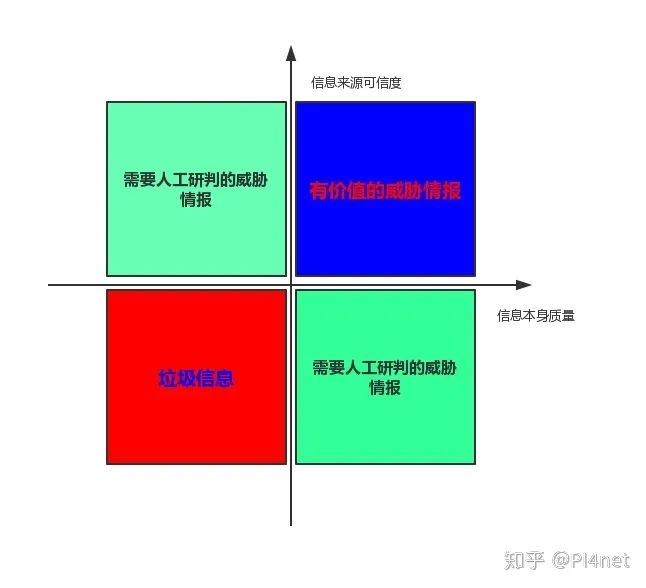
這樣就可以將機器處理的信息分為三個等級:
- 有價值的的威脅情報
- 需要人工研判的威脅情報
- 垃圾信息
用白話說出來就是:信息來源可靠且信息本身質量高的安全信息是有價值價值的威脅情報。
價值描述
當然,威脅情報有三六九等,同時需要人研判的信息也有輕重緩急。其實是有方法對“價值”進行量化的。
雖然上面對尺碼描述分為了6個等級,但人類語言在數字世界其實是以數字進行呈現的。標準是可以通過算法進行量化的。
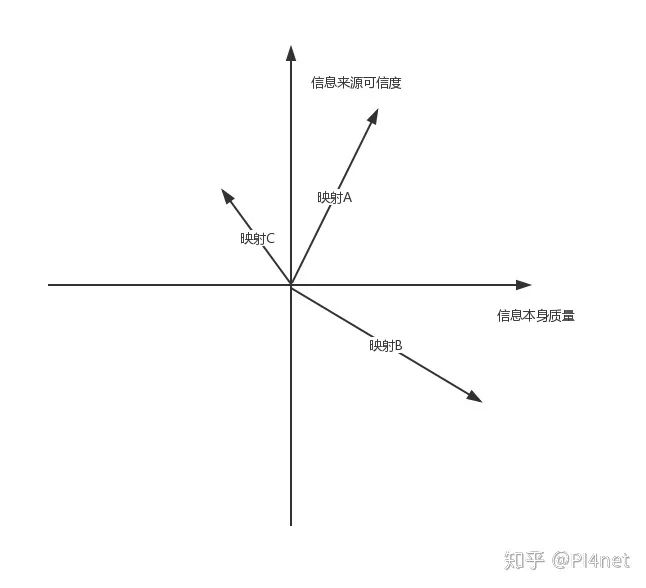
威脅情報的價值可以通過所在坐標的模進行標識的:
一條被自動判定為威脅情報的A,它的價值為:
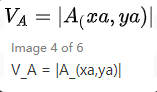
(x > 0 且 y > 0)
同理可得,映射B、C需要判定的優先級為:
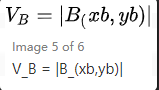
(x > 0 | y > 0)
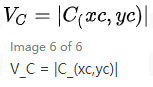
(x > 0 | y > 0)
通過這種方法,就可以把威脅情報的層次區分開了。這個只是限定在 OSINT 信息處理。不同種類的安全信息,雖然研判尺碼不同,但是大體思路是一樣的。
實踐

講了那么多方法論,為了幫助更好的理解,這里舉一個例子。
場景就設定為:企業安全建設,收集漏洞威脅情報進行安全運營。
- 第一步:確定范圍
- 首先要了解企業資產信息,明確哪些漏洞是需要關注的。
- 第二步:制訂收集計劃
- 確定信息來源,信息格式,信息研判的方式,信息收集的方式。
- 常見的漏洞信息來源有:CVE漏洞庫,NVD漏洞庫,CNVD漏洞庫,媒體網站,郵件訂閱,個人/組織博客,社交平臺(Facebook,推特,微信群,朋友圈)等。
- 明確信息格式。一般漏洞庫都有RSS訂閱服務,可以直接獲得結構化數據進行正則、字典匹配。而媒體網站,blog,社交平臺的信息往往是非結構化的,這樣的數據一般需要NLP進行處理。不同的信息種類,處理方式不同。明確信息格式是為了更好的處理數據。
- 不同信息來源的時效性,收集方式是不同。社交平臺的時效性比較高,則信息爬取的時間間隔應當盡量小。而漏洞庫則不必,一天爬一次足以。大多數情況都是通過爬蟲采取主動的方式進行信息收集,也有個例,郵件訂閱方面則需要被動的方式進行接收。
- 第三步:設置尺碼
- 尺碼的兩個維度:來源信譽、信息質量
- 來源信譽需要積累,當然也可以進行預設,官方的公告網站、推特的大V、專業的安全媒體等,這些的權值可以大一點。
- 信息質量要根據不同來源進行匹配,例如廠商公告的產品我方是否關注,推文的熱度如何,安全沒媒體披露的漏洞是否在其他來源有相同的消息……
- 第四步:機器分析研判
- 如上一節所說,可以通過一些方法把威脅情報的層次區分開。
- 第五步:人工研判
- 機器研判是不可信的,它可以在一定范圍內將高價值的信息區分出來。例如“微軟發布了安全更新,而這次更新的產品我們有所使用”,這種情況肯定是映射到第一象限中的。但是很多情況,信息是映射到二四象限。特別是非結構來源的信息,比如某個不活躍在推特發了一個0day信息,這種信息來源可疑(指不活躍用戶,而不是推特)的信息往往落到第四象限,這種情況就要接入人工研判。
- 第六步:處置
- 略
后記
先寫到這里,本片只寫了安全分析角度,威脅情報如何產出,并且提供了工程化的方案。
因為安全分析這個題太大,抽象出來的通用方法總覺著有寫干癟,希望結合“0x05 實踐”的內容讓讀者有所收獲。
ps:blog同步更新,http://pi4net.com 需要翻墻。
如果對安全分析有感興趣的點,歡迎評論。有可能作為下期博客內容。
