隱私計算在智能營銷中的應用
近年來,基于大數據和人工智能技術的各項應用已經走進我們生活的方方面面,數據作為其中的基礎性生產要素和戰略性資源,在生產生活中扮演著越來越重要的角色。與此同時,隨著技術發展的不斷深入和應用領域的不斷拓寬,也逐漸面臨一些亟待解決的問題。一方面,單一、少量的數據逐漸不能滿足數據應用的需求,只有數據跨部門、跨業務、跨企業、跨地區的融合應用才能支撐和推動數字經濟創新發展。另一方面,數據安全和隱私保護的關注度越來越高,數據應用是否合規決定了整個產業發展的可持續性。
為解決上述問題,隱私計算技術受到了金融機構、政府部門、高校研究機構等各行業的廣泛關注。2021年以來,隱私計算技術在不同場景的預研、驗證、落地應用進程明顯加快。本文以智能營銷的場景為例,研究了隱私計算技術與銀行業務融合應用的實現方案,總結了目前遇到的問題和未來的發展方向。
傳統智能營銷建模現狀與問題
以理財推薦模型為例,在傳統的智能營銷場景下,目標是提高理財產品的點擊率,若客戶點擊了推薦的產品則為正樣本,沒有點擊則為負樣本。然后通過數據清洗和特征工程,為機器學習模型準備好訓練數據,訓練完成后即可投產上線。這其中產生的問題在于,無論如何優化算法層面,模型的預測效果很大程度上還取決于參與訓練的數據數量與質量,而目前智能營銷模型所能使用的數據是十分有限的。
在傳統場景下,參與模型訓練的數據,無論是客戶的手機銀行APP行為數據,還是客戶的資產、交易、風險數據,都是在銀行系統內產生的數據。銀行很難獲取客戶在其他金融機構產生的數據,例如客戶在其他金融機構的資產、持有產品信息、交易信息等。此外,無論是從保護客戶隱私,還是數據應用符合監管要求的角度出發,銀行將越來越不可能允許自己的數據出域,脫離自己的管控。同理,其他公司或機構在涉及數據出域的合作中,也會更加審慎。基于以上兩點原因,目前傳統智能營銷面臨的主要矛盾是,數據應用對大規模、高質量數據的需求和數據跨機構流通越來越困難之間的矛盾。隱私計算技術是目前能夠很好解決該問題的方案。
隱私計算技術概述
隱私計算是一種由兩個或多個參與方聯合計算的技術和系統,參與方在不泄露各自數據的前提下通過協作對他們的數據進行聯合機器學習和聯合分析。在隱私計算框架下,參與方的數據明文不出本地,在保護數據安全的同時實現多源數據跨域合作,可以破解數據保護與融合應用難題。常見的實現隱私計算的技術路徑包括多方安全計算、聯邦學習、可信執行環境等。
可信執行環境是指在數據計算平臺上由軟硬件方法構建的一個安全區域,可保證在安全區域內部加載的代碼和數據在機密性和完整性方面得到保護。
多方安全計算是一種在參與方不共享各自數據且沒有可信第三方的情況下,安全地計算約定函數的技術和系統。主要包括秘密分享、不經意傳輸、同態加密等安全協議,以及由此衍生出的安全求交、匿蹤查詢等技術。
聯邦學習是一種分布式機器學習技術和系統,包括兩個或多個參與方,這些參與方通過安全的算法協議進行聯合機器學習,可以在各方數據不出本地的情況下聯合多方數據源建模和提供模型推理與預測服務。根據數據在不同參與方的分布情況可分為橫向聯邦學習、縱向聯邦學習、遷移聯邦學習。
橫向聯邦學習適用于不同參與方之間數據特征重疊較多,但樣本空間重疊較少,通過橫向聯邦學習,可以擴大樣本量以提高模型精度。例如兩家面向不同客群的銀行之間,共有客戶較少,但業務類型相似,就可適用橫向聯邦學習。
縱向聯邦學習適用于不同參與方之間樣本空間重疊較多,但數據特征重疊較少,通過縱向聯邦學習,可以適用更多的特征訓練模型。例如銀行和理財公司之間,共有客戶較多,但業務類型相差較大,就更適合縱向聯邦學習。
縱向聯邦學習智能營銷建模
為解決傳統理財推薦模型遇到的數據特征不足問題,在保證數據安全的前提下,打通數據孤島,賦能數據應用,銀行與外部數據合作,搭建了隱私計算平臺。由銀行方提供客戶是否點擊推薦產品標簽信息及銀行所擁有的其他客戶信息,外部數據源提供客戶理財交易相關信息,共同進行縱向聯邦學習訓練。
圖1是完整的兩方縱向聯邦學習流程圖。從圖中可以看出,在整個訓練的過程中,雙方明文數據都沒有出域,確保了數據的安全性和數據應用的合規性。
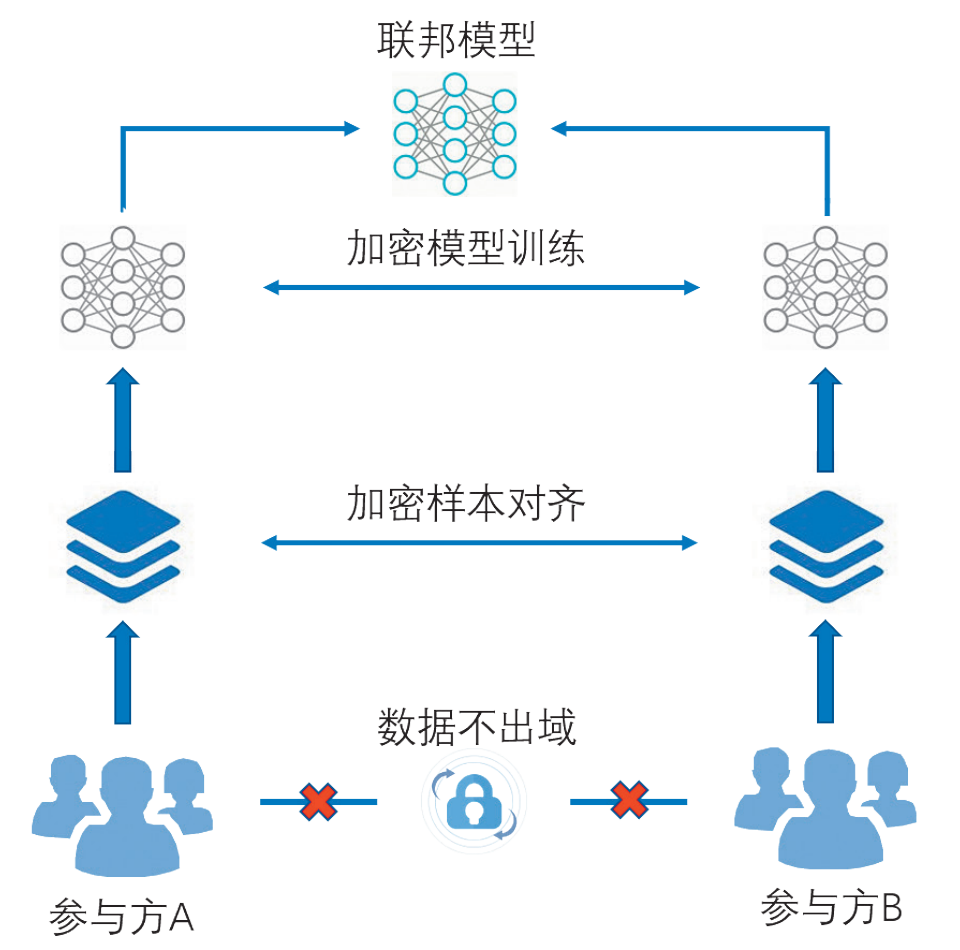
圖1 縱向聯邦建模過程
在進行縱向聯邦學習前,雙方數據需要先進行安全求交,即通過基于同態加密的多方安全計算,在不暴露非交集部分的用戶信息給其他參與方的前提下,參與計算各方獲得交集部分的客戶唯一標識,且不泄露其他特征信息。在確認雙方共有的客戶范圍后,參與雙方即可基于這部分共有客戶分別進行特征工程,準備訓練數據。
完成前期準備工作后,即可開始模型訓練,與傳統模型不同的是,在訓練過程中,雙方原始數據沒有離開雙方的控制,只有加密態的中間過程數據會進行交互,很好地保護了數據隱私。在整個模型訓練收斂之后,雙方各自保存屬于自己的部分模型。
以兩方縱向邏輯回歸為例,假設參與方A擁有數據集XAi,參與方B擁有數據集XBi和標簽yi,對傳統目標函數數進行二階泰勒展開得式(1)
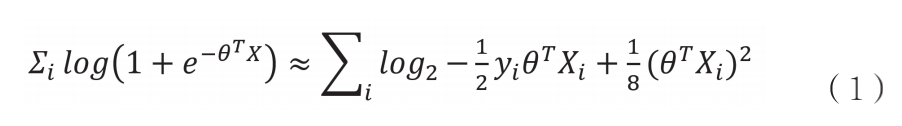
則縱向邏輯回歸的目標函數可以用式(2)表示即:
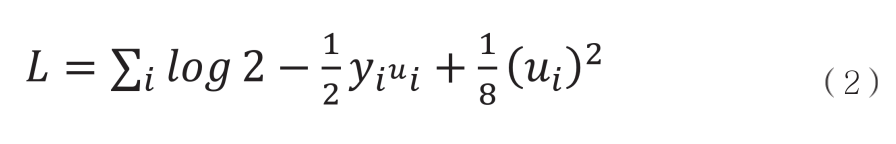
其中:
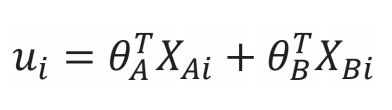
因此,對于參與方 A 和 B,其所計算的各自的子模型梯度為 :
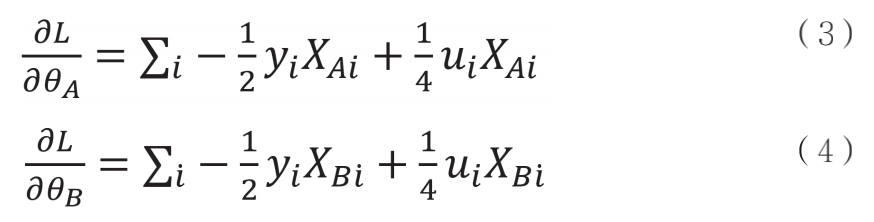
在整個訓練過程中,雙方通過同態加密技術交換密文狀態下的梯度數據,并更新模型。
在訓練理財推薦模型的過程中,我們使用到的主要數據字段如表1所示。在我們本次的案例中,計算雙方各提供50萬條數據,雙方樣本匹配率,即雙方共有的客戶占總樣本量的84%,最終參與訓練的樣本量共計42萬條。
表 1 理財推薦模型主要使用數據

由于縱向聯邦學習所用到的數據從特征存放在不同的參與方中,對于已經訓練完成的縱向聯邦學習模型,在進行模型推理前,需要對于新樣本進行一次安全求交,若新樣本是雙方的共有客戶,則可以進行模型推理,否則不能進行。對于共有客戶,各個參與方在分別完成自己的子模型推理后,利用多方安全計算進行共享,從而得到整個聯邦模型的推理結果。在整個推理過程中,原始數據與模型結果都是加密態的,不僅保護了客戶的數據安全,也保護了各個參與方模型參數的數據安全。
聯邦模型與傳統模型的對比
圖2是縱向聯邦邏輯回歸和普通邏輯回歸的ROC曲線對比。從圖中可以看出,縱向邏輯回歸的AUC值比普通邏輯回歸高了近12%,說明在引入更多的數據特征后,模型訓練效果有了顯著提升。
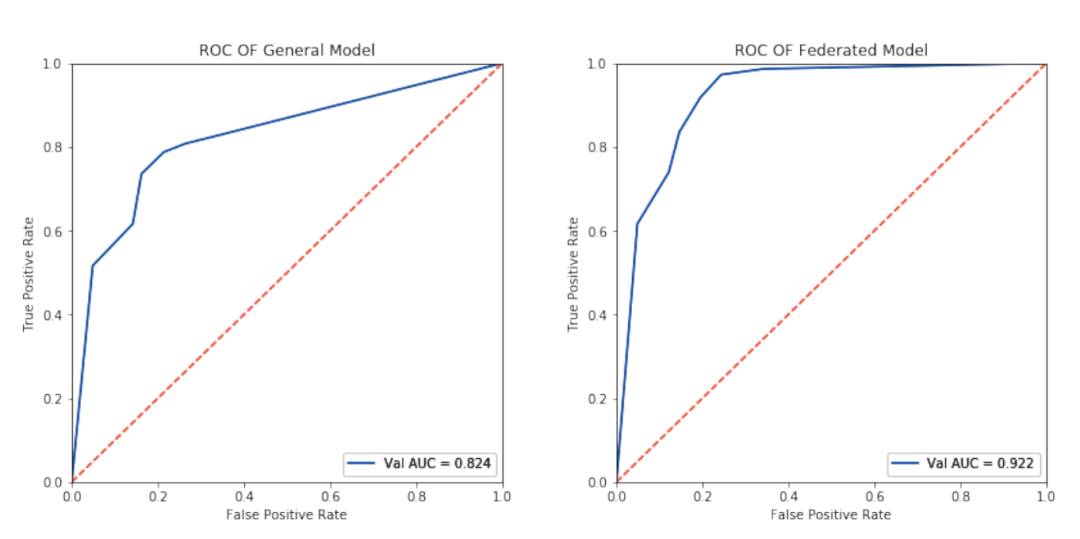
圖2 普通模型與聯邦模型ROC曲線
與傳統機器學習模型基于單方所有數據進行訓練相比,聯邦學習使得數據價值在多方協作下得到釋放,保護了數據隱私,打破了數據孤島限制,實現了數據的“可用但不可見”。
隱私計算技術是解決數據安全共享的理想方案,然而在實際應用過程中,也存在著一些難點問題,還需要進一步研究解決。
1.計算性能亟待提升。隱私計算技術在應用過程中需要對數據進行加密處理,在這個過程中會消耗大量的計算性能。以聯邦學習過程中用于交換梯度的同態加密技術為例,在相同的硬件條件下,其性能與明文計算的差距在百倍以上。對于商業化應用來說,這無疑是一大痛點。
2.網絡通信要求較高。由于隱私計算技術需要多方協作才能完成,這中間必然涉及網絡通信問題,以秘密分享協議為例,其廣泛應用于加密數據的分享過程,在計算過程中會傳輸大量密文數據,將對網絡帶寬造成很大的壓力。
3.異構平臺間的互聯互通還未完全實現。隨著近兩年隱私計算技術的快速發展,不同架構的隱私計算框架也越來越多,無論是開源框架還是商業解決方案,目前還無法完全實現不同隱私計算平臺的完全互通。這很大程度上阻礙了隱私計算技術的進一步推廣和應用,應該避免打通數據孤島之后,產生新的“平臺孤島”。
總結與展望
本文基于智能營銷場景下的理財推薦模型,介紹了隱私計算技術在銀行的應用,總結了其技術優點和目前面臨的問題。總體來說,隱私計算作為一種新興技術,目前的應用還處于探索階段,還需要進一步與具體場景緊密結合,才能擴展應用空間的同時促進技術發展。
在數字經濟的時代背景下,大力推進金融科技創新,集中攻關核心技術,積極探索應用場景,是銀行業發展的必然要求。隱私計算技術以其獨特的優勢,必將為保護數據隱私,加速數據資產價值釋放,促進銀行數字化轉型提供新的動能
