《Chrome V8 源碼》43. Turbofan 源碼分析
介紹
接上一篇文章繼續說,本文講解 Turbofan 的工作流程、梳理 PrepareJob、ExecuteJob 和 FinalizeJob 的主要功能以及重要數據結構。
Turbofan 工作流程
前文提到,Turbofan 分為 NotConcurrent 和 Concurrent 兩種工作方式,它們的區別是 NotConcurrent 立即啟動優化工作,而 Concurrent 把工作放進同步分發隊列。
Concurrent 方式由 GetOptimizedCodeLater() 函數負責,其源碼如下:
1. bool GetOptimizedCodeLater(OptimizedCompilationJob* job, Isolate* isolate) {2. OptimizedCompilationInfo* compilation_info = job->compilation_info();3. if (!isolate->optimizing_compile_dispatcher()->IsQueueAvailable()) {4. if (FLAG_trace_concurrent_recompilation) {5. //省略................6. }7. return false;8. }9. if (isolate->heap()->HighMemoryPressure()) {10. if (FLAG_trace_concurrent_recompilation) {11. //省略................12. }13. return false;14. }15. TimerEventScope timer(isolate);16. RuntimeCallTimerScope runtimeTimer(17. isolate, RuntimeCallCounterId::kOptimizeConcurrentPrepare);18. TRACE_EVENT0(TRACE_DISABLED_BY_DEFAULT("v8.compile"),19. "V8.OptimizeConcurrentPrepare");20. if (job->PrepareJob(isolate) != CompilationJob::SUCCEEDED) return false;21. isolate->optimizing_compile_dispatcher()->QueueForOptimization(job);22. if (FLAG_trace_concurrent_recompilation) {23. PrintF(" ** Queued ");24. compilation_info->closure()->ShortPrint();25. PrintF(" for concurrent optimization.");26. }27. return true;28. }
上述代碼中,第 4-14 行檢測工作隊列和內存是否滿足要求,不滿足則停止優化編譯。停止優化編譯不影響當前 JavaScript 程序的運行,因為 JavaScript 程序正在被解釋執行。
第 15-20 行統計 V8 運行信息,與優化編譯的功能無關;
第 21 行把優化編譯工作 job 添加到工作隊列中,并返回結果 true。
NotConcurrent 方式由 GetOptimizedCodeNow() 函數負責,其源碼如下:
1. bool GetOptimizedCodeNow(OptimizedCompilationJob* job, Isolate* isolate) {2. TimerEventScope timer(isolate);3. RuntimeCallTimerScope runtimeTimer(4. isolate, RuntimeCallCounterId::kOptimizeNonConcurrent);5. OptimizedCompilationInfo* compilation_info = job->compilation_info();6. TRACE_EVENT0(TRACE_DISABLED_BY_DEFAULT("v8.compile"),7. "V8.OptimizeNonConcurrent");8. if (job->PrepareJob(isolate) != CompilationJob::SUCCEEDED ||9. job->ExecuteJob(isolate->counters()->runtime_call_stats()) !=10. CompilationJob::SUCCEEDED ||11. job->FinalizeJob(isolate) != CompilationJob::SUCCEEDED) {12. if (FLAG_trace_opt) {13. CodeTracer::Scope scope(isolate->GetCodeTracer());14. PrintF(scope.file(), "[aborted optimizing ");15. compilation_info->closure()->ShortPrint(scope.file());16. PrintF(scope.file(), " because: %s]",17. GetBailoutReason(compilation_info->bailout_reason()));18. }19. return false;20. }21. // Success!22. job->RecordCompilationStats(OptimizedCompilationJob::kSynchronous, isolate);23. DCHECK(!isolate->has_pending_exception());24. InsertCodeIntoOptimizedCodeCache(compilation_info);25. job->RecordFunctionCompilation(CodeEventListener::LAZY_COMPILE_TAG, isolate);26. return true;27. }
上述代碼中, 第 2-7 行統計 V8 運行信息,與優化編譯的功能無關;
第 8-9 行完成優化編譯的所有工作,這些工作由 PrepareJob、ExecuteJob 以及 FinalizeJob 三個函數負責;
第 10-25 行更新編譯狀態等信息并返回 true。優化編譯同步進行,也就意味著暫停解釋執行并等待優化編譯的結果。
準備 PrepareJob
源碼如下:
1. CompilationJob::Status OptimizedCompilationJob::PrepareJob(Isolate* isolate) {2. DCHECK_EQ(ThreadId::Current(), isolate->thread_id());3. DisallowJavascriptExecution no_js(isolate);4. if (FLAG_trace_opt && compilation_info()->IsOptimizing()) {5. //省略..............6. }7. // Delegate to the underlying implementation.8. DCHECK_EQ(state(), State::kReadyToPrepare);9. ScopedTimer t(&time_taken_to_prepare_);10. return UpdateState(PrepareJobImpl(isolate), State::kReadyToExecute);11. }
上述代碼中,第 2-3 行做狀態檢測、第 4-6 行設置打印出輸信息;第 10 行 UpdateState 更新狀態信息,PrepareJobImpl 完成初始化工作,其源碼如下:
1. PipelineCompilationJob::Status PipelineCompilationJob::PrepareJobImpl(2. Isolate* isolate) {3. PipelineJobScope scope(&data_, isolate->counters()->runtime_call_stats());4. if (compilation_info()->bytecode_array()->length() >5. FLAG_max_optimized_bytecode_size) {6. return AbortOptimization(BailoutReason::kFunctionTooBig);7. }8. if (!FLAG_always_opt) {9. compilation_info()->MarkAsBailoutOnUninitialized();10. }11. if (FLAG_turbo_loop_peeling) {12. compilation_info()->MarkAsLoopPeelingEnabled();13. }14. if (FLAG_turbo_inlining) {15. compilation_info()->MarkAsInliningEnabled();16. }17. PoisoningMitigationLevel load_poisoning =18. PoisoningMitigationLevel::kDontPoison;19. if (FLAG_untrusted_code_mitigations) {20. load_poisoning = PoisoningMitigationLevel::kPoisonCriticalOnly;21. }22. compilation_info()->SetPoisoningMitigationLevel(load_poisoning);23. if (FLAG_turbo_allocation_folding) {24. compilation_info()->MarkAsAllocationFoldingEnabled();25. }26. if (compilation_info()->closure()->raw_feedback_cell().map() ==27. ReadOnlyRoots(isolate).one_closure_cell_map() &&28. !compilation_info()->is_osr()) {29. compilation_info()->MarkAsFunctionContextSpecializing();30. data_.ChooseSpecializationContext();31. }32. if (compilation_info()->is_source_positions_enabled()) {33. SharedFunctionInfo::EnsureSourcePositionsAvailable(34. isolate, compilation_info()->shared_info());35. }36. data_.set_start_source_position(37. compilation_info()->shared_info()->StartPosition());38. linkage_ = new (compilation_info()->zone()) Linkage(39. Linkage::ComputeIncoming(compilation_info()->zone(), compilation_info()));40. if (compilation_info()->is_osr()) data_.InitializeOsrHelper();41. Deoptimizer::EnsureCodeForDeoptimizationEntries(isolate);42. pipeline_.Serialize();43. if (!data_.broker()->is_concurrent_inlining()) {44. if (!pipeline_.CreateGraph()) {45. CHECK(!isolate->has_pending_exception());46. return AbortOptimization(BailoutReason::kGraphBuildingFailed);47. }48. }49. return SUCCEEDED;50. }
上述代碼中,第 4-7 行檢查 BytecodeArray 的長度是否超過最大長度限制;
第 8-10 行檢查 always_optimization 使能標記,它的作用是 always try to optimize functions;
第 11-25 行檢測 loop_peeling、inling、allocation_folding 使能標記,詳細說明參見 flag-definitions.h 文件;
第 26-37 行設置 context、OSR、源碼信息;
第 38 行創建編譯需要的 link 信息;
第 44 行創建 V8.TFGraph,這之后不再需要 T了;
編譯 ExecuteJob
ExecuteJob() 中調用 ExecuteJobImpl() 來完成優化編譯的主體工作,其源碼如下:
1. PipelineCompilationJob::Status PipelineCompilationJob::ExecuteJobImpl(2. RuntimeCallStats* stats) {3. PipelineJobScope scope(&data_, stats);4. if (data_.broker()->is_concurrent_inlining()) {5. //省略.....6. }7. bool success;8. if (FLAG_turboprop) {9. success = pipeline_.OptimizeGraphForMidTier(linkage_);10. } else {11. success = pipeline_.OptimizeGraph(linkage_);12. }13. if (!success) return FAILED;14. pipeline_.AssembleCode(linkage_);15. return SUCCEEDED;
上述代碼的核心功能就兩個,一個基于圖的優化功能(OptimizeGraphForMidTier 和 OptimizeGraph),另一個匯編生成器(AssembleCode)。優化功能的源碼如下:
bool PipelineImpl::OptimizeGraphForMidTier(Linkage* linkage) { Run(data->CreateTyper()); RunPrintAndVerify(TyperPhase::phase_name()); Run(); RunPrintAndVerify(TypedLoweringPhase::phase_name()); Run(); //省略..............}//分隔線....................bool PipelineImpl::OptimizeGraph(Linkage* linkage) { PipelineData* data = this->data_; data->BeginPhaseKind("V8.TFLowering"); Run(data->CreateTyper()); RunPrintAndVerify(TyperPhase::phase_name()); Run(); RunPrintAndVerify(TypedLoweringPhase::phase_name()); //省略..............}
上述代碼中,每一個 Run 方法代表過了一種優化技術,每種優化技術的實現都有對應的數據結構,本文不做講解。
匯編生成器(AssembleCode)的源碼如下:
1. void PipelineImpl::AssembleCode(Linkage* linkage,2. std::unique_ptr<AssemblerBuffer> buffer) {3. PipelineData* data = this->data_;4. data->BeginPhaseKind("V8.TFCodeGeneration");5. data->InitializeCodeGenerator(linkage, std::move(buffer));6. Run<AssembleCodePhase>();7. //省略.....8. }9. //分隔.................10. CodeGenerator::CodeGenResult CodeGenerator::AssembleArchInstruction(11. Instruction* instr) {12. switch (arch_opcode) {13. case kArchCallCodeObject: {14. if (HasImmediateInput(instr, 0)) {15. //省略.......................16. } else {17. Register reg = i.InputRegister(0);18. DCHECK_IMPLIES(19. HasCallDescriptorFlag(instr, CallDescriptor::kFixedTargetRegister),20. reg == kJavaScriptCallCodeStartRegister);21. __ LoadCodeObjectEntry(reg, reg);22. if (HasCallDescriptorFlag(instr, CallDescriptor::kRetpoline)) {23. __ RetpolineCall(reg);24. } else {25. __ call(reg);26. } }27. RecordCallPosition(instr);28. frame_access_state()->ClearSPDelta();29. break;30. }31. case kArchCallBuiltinPointer: {32. //省略.......................33. break;34. }}35. }
上述第 5 行代碼初始 CodeGenerator,第 6 行代碼 Run() 方法最終會調用第 10 行 AssembleArchInstruction() 方法以完成匯編碼的生成。第 12-34 行代碼采用 switch-case 為每條操作碼(OPCODE)編寫不同的匯編碼生成規則。每條操作碼對應一個 case,這個 case 描繪了把操作碼轉換為匯編碼的規則。圖 1 給出了 AssembleArchInstruction 的調用堆棧。
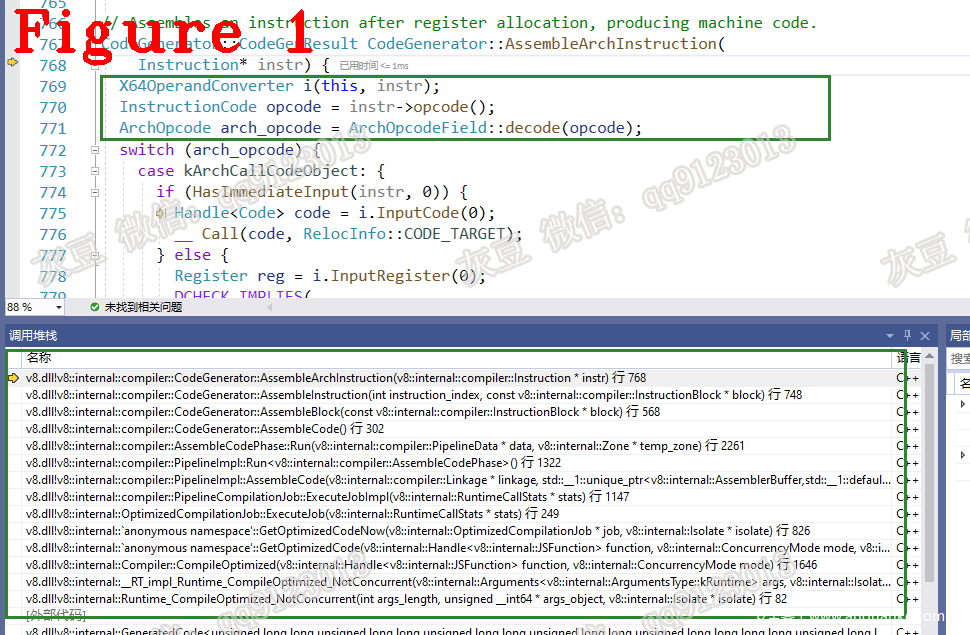
V8 中 OPCODE 分為兩類,一類是體系結構通用的操作碼(COMMON_ARCH_OPCODE_LIST),另一類是體系結構專用的操作碼(TARGET_ARCH_OPCODE_LIST),具體參見宏模板。
收尾 FinalizeJob
收尾工作由 FinalizeJobImpl() 負責,源碼如下:
1. PipelineCompilationJob::Status PipelineCompilationJob::FinalizeJobImpl(2. Isolate* isolate) {3. //省略.................4. MaybeHandle<Code> maybe_code = pipeline_.FinalizeCode();5. Handle<Code> code;6. if (!maybe_code.ToHandle(&code)) {7. //省略.................8. }9. if (!pipeline_.CommitDependencies(code)) {10. //省略.................11. }12. compilation_info()->SetCode(code);13. compilation_info()->native_context().AddOptimizedCode(*code);14. RegisterWeakObjectsInOptimizedCode(code, isolate);15. return SUCCEEDED;16. }
上述第 4 行代碼接收優化編譯的結果;第 6-8 行代碼優化編譯失敗并返回 false;第 9-11 行代碼重試優化編譯;第 12 行代碼將優化編譯結果存儲進 Cache,下次再優化該 SharedFunction 時將直接使用 Cache 結果。
技術總結
(1) —Trace-XXX 用于打印編譯狀態和結果,參見 d8 —help 或 flag-definitions.h;
(2) 優化編譯的使能標記的定義在 flag-definitions.h 中;
(3) On-Stack Replacement(OSR)是一種運行時替換函數的棧幀的方法。
新文章介紹
《Chrome V8 Bug》 系列文章即將上線。
《Chrome V8 Bug》系列文章的目的是解釋漏洞的產生原因,并向你展示這些漏洞如何影響 V8 的正確性。其他的漏洞文章大多從安全研究的角度分析,講述如何設計與使用 PoC。而本系列文章是從源碼研究的角度來寫的,分析 PoC 在 V8 中的執行細節,講解為什么 Poc 要這樣設計。當然,學習 Poc 的設計與使用,是 V8 安全研究的很好的出發點,所以,對于希望深入學習 V8 源碼和 PoC 原理的人來說,本系列文章也是很有價值的介紹性讀物。
本系列文章主要講解 https://bugs.chromium.org/p/v8/issues 的內容,每篇文章講解一個 issue。如果你有想學習的 issue 也可以告訴我,我會優先講解。
