記錄一下從編譯的角度還原VMP的思路
一、摘要
1.1 關于代碼優化與還原
關于還原,我認為難點是工作量大,需要自動化提升效率。
還原和混淆是一對反義詞,相同點是保證代碼功能相近,不同是一個是使代碼更易讀,后者則相反。
而代碼優化非常類似,也要保證代碼功能相近,不同是減少代碼的體積或運行速度。
所以我感覺還原和代碼優化有很多共通點。然后嘗試了一下從編譯的角度去做自動化還原,這里分享一下思路,算是畫一個不太完美的句號吧。
1.2 還原流程
我的還原流程簡單來說就三步:
① 識別匯編對應的語義(翻譯虛擬機字節碼)。
② 虛擬指令轉換成C。
③ 二次編譯,利用編譯器優化。
第三步可以針對性的實現一些優化,因為vmp是一個基于棧的虛擬機,編譯器的優化效果有限。
第一步是我做的比較多的一部分,在后面的實現過程會說具體思路。
二、實現過程
2.1 Handler語義識別
這一步說的是怎么判斷Handler對應的虛擬機指令。
2.1.1 淺談VMP的CFG
Handler識別首先繞不開一個問題,怎么找到Handler?
關于VMP 3.X的架構這里簡單說一下。
在VMP2中會有一個分發器,所有Handler的地址都存在一個數組中,很容易就能把所有Handler找出來;但到了3,分發方式變成從字節碼中解碼出下一條指令的地址。
2.1.2 模擬執行輸出虛擬指令
目前分析到兩種跳轉方式:
mov regjmp reg
或
push regret
我的思路是模擬執行,遇到jmp reg或者push ; ret時就代表一條Handler已經結束,reg中的是下一條Handler的地址。
所以可以構建一個Handler 虛擬地址到虛擬指令的映射。
模擬執行還有一個好處,對于不同的虛擬指令,在Handler中下斷,讓Handler自己解密字節碼中的內容,然后提取出來。
2.1.3 Handler識別
關于Handler的語義是什么就省略了。
根據jmp reg或push ; ret把Handler提取出來后,現在就需要識別其對應的虛擬機指令。
兩種思路:
正則表達式匹配(速度塊)
DAG或者數據流圖匹配
2.1.3.1 正則匹配
這是我目前正在用的方案,對匯編代碼使用正則表達式匹配。
矛盾點是正則規則越嚴格,漏判越嚴重,規則越寬松,誤判越嚴重。
緩解方案是對匯編代碼先進行一次優化,參考編譯原理中的死代碼消除,對寄存器的使用進行分析。
以一個加法的Handler為例:
比如優化前的Handler:
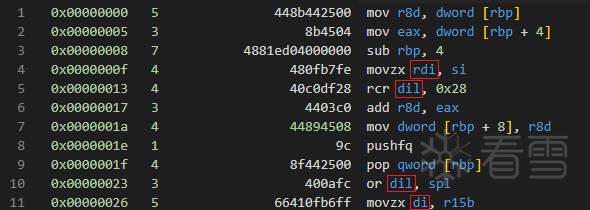
其中4、5、10、11行連續對rdi寄存器進行了寫入,顯然前三條寫入是無效的。
優化后的Handler:
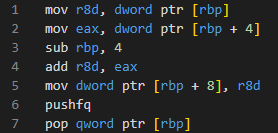
正則匹配:

2.1.3.2 DAG匹配
這部分只是做一個嘗試。
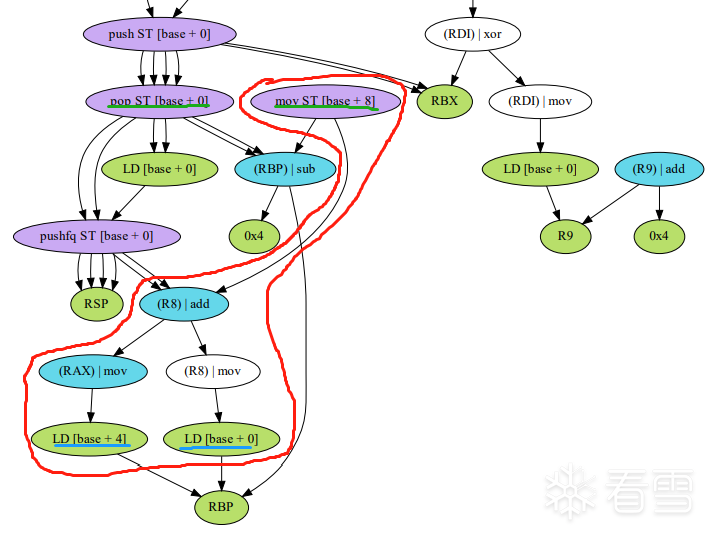
同樣是加法的例子,這是其DAG圖(不太嚴格,因為x86復雜指令集有點麻煩)。
藍色下劃線是從棧獲取的操作數。
綠色下劃線是將結果和RFLAGS放回棧。
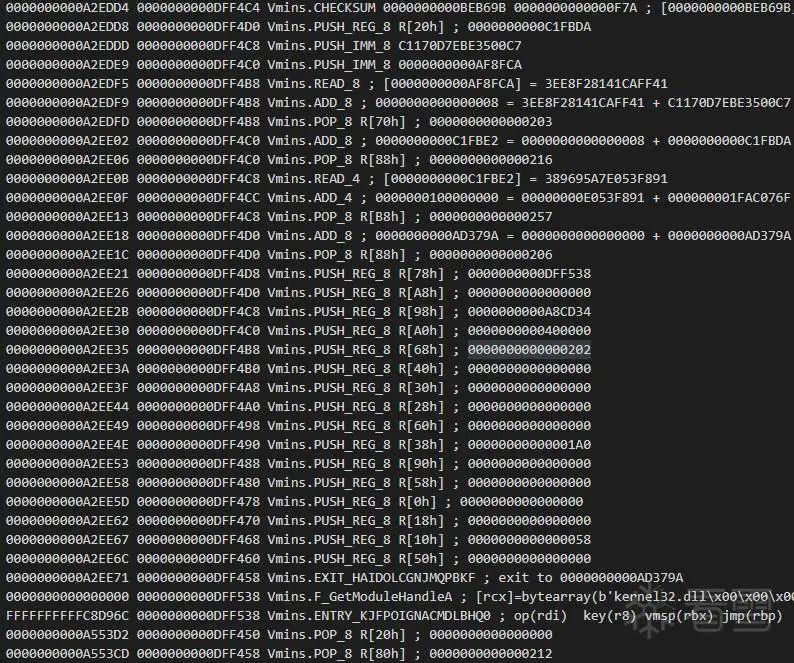
2.1.4 識別結果
模擬執行順序執行的片段:
2.2 控制流還原
2.2.1 虛擬機指令DU分析
先分析每條虛擬機指令對棧的讀寫,然后構建DU鏈。
接著利用DU鏈進行一次簡單的優化,包括常量傳播,折疊一些變量在VM棧和VM寄存器上的移動,還有簡單的MBA表達式優化(簡化接下來的判斷分支等步驟)。
2.2.2 判斷是否為分支
進行到這里就可以判斷是jmp還是jcc。
jmp的例子(左邊是每條指令起始時VM字節碼指針和VM棧指針):

jcc的例子:

區別就是RET之前的一條語句PUSH的是否為一個立即數(依賴前面的常量傳播優化)。
2.2.3 獲取分支去向
接下來就可以通過DU鏈,獲取分支的兩條去向分別是什么。
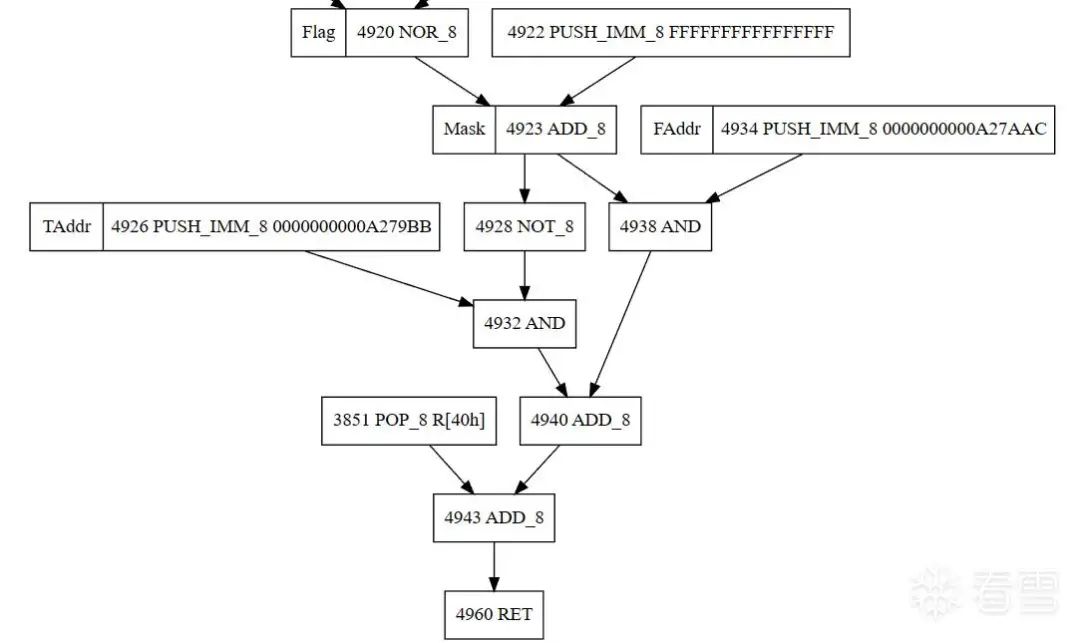
依據是VMP的分支跳轉偽代碼為:
mask = -1 + flaga1 = mask & FAddra2 = ~mask & TAddrjmp = a1 + a2
這里是識別的例子:
2.2.4 獲取分支條件(未完善)
這里我大致分成了兩步:
識別判斷的rflags標志位
識別~(~x+y)
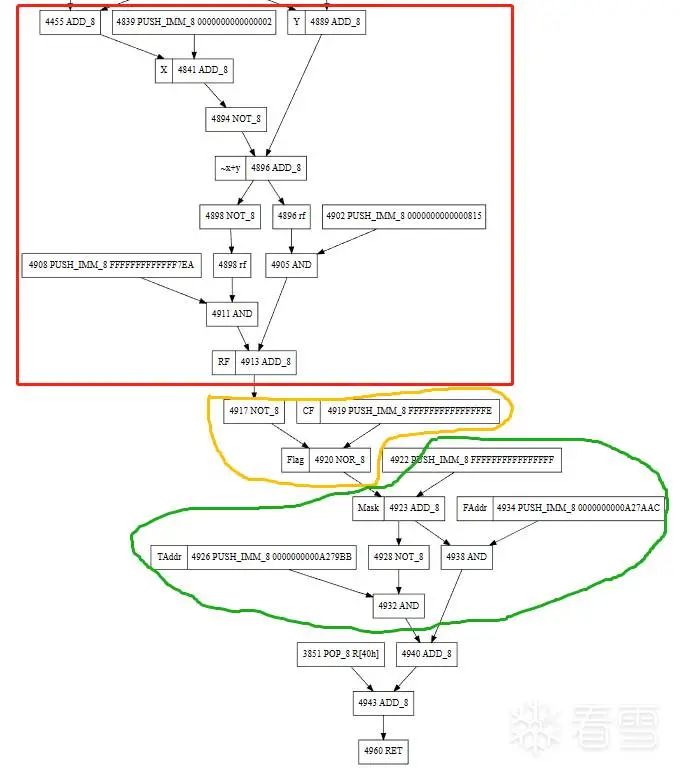
一個比較標準的test x-y,然后判斷CF的例子。
綠色框是上一步的跳轉地址計算。
黃色框是rflags標志位的判斷。
紅色框是計算x-y的rflags。
一個and x, x,判斷是否為0的例子。
綠框是上一步的跳轉地址計算。
黃框是判斷其ZF位。
紅框是讀取內存,然后獲取其and x, x的rflags,沒識別到。
2.2.5 控制流還原雜談
在前面Handler語義識別的時候,難免會有錯漏,出現識別不了的語句。
在模擬執行還原控制流時,妥協做法是停止該分支的分析。
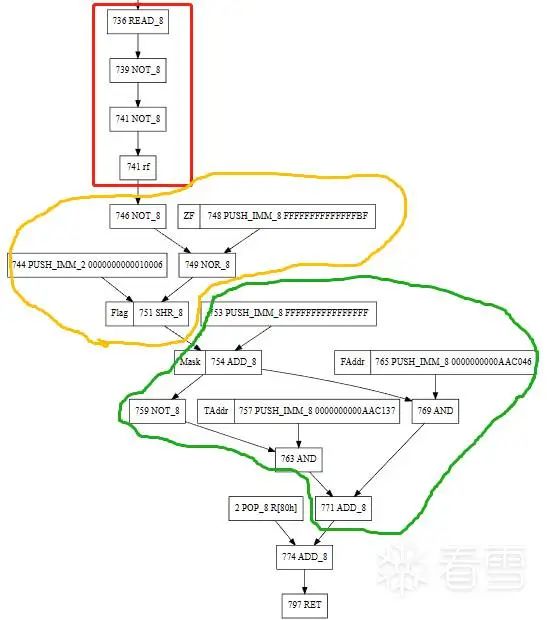
這里截取了一段控制流。
每個圈圈是一個虛擬指令基本塊。
這里綠色箭頭的是前面flag=1分支、紅色箭頭是前面flag=0的分支。
紅色圈圈的是遇到未知虛擬指令或模擬執行錯誤,停止分析的塊。

2.3 還原成C(做的不太好)
這一步隨便水水了,只做了一部分,主要工作量太大了。
將虛擬指令輸出成對應的C語言代碼,然后上編譯器編譯。
給個加法的例子吧:

三、結尾(歡迎指教)
3.1 收獲
比較喜歡寫代碼,vmp代碼還原的自動化又是個需要寫很多代碼的工程,就比較感興趣,斷斷續續大學花了不少時間在這上面。
最大的收獲是經驗,寫的時候花了很多時間在debug上,實際寫的時間根本沒多少。
我也明白,先設計好再寫代碼可以減少很多寫代碼和debug的時間,但缺乏還原經驗,設計的時候無從入手,也考慮不周全,只能邊寫邊想。算是積累了一些經驗。
然后實踐了一下編譯原理的入門知識,一個非常有意思的領域,希望以后有機會繼續深入學習下去。
3.2 關于分析深度和還原難度
在還原的過程中,我發現對虛擬機架構的分析越多,獲得更多關于殼的信息,就能寫出更容易實現、更有針對性、更有效果的優化。
有點類似窺孔優化的思路,犧牲通用性,以便實現和提高效果。
