基于嵌入的知識圖譜實體對齊的基準研究
Overview
實體對齊尋求在不同的知識圖譜(KG)中找到引用同一真實世界對象的實體。KG嵌入的最新進展推動了基于嵌入的實體對齊的出現,它在一個連續的嵌入空間中對實體進行編碼,并基于學習到的嵌入來測量實體的相似性。本文對這一新興領域進行了全面的實驗研究。團隊調查了最近23種基于嵌入的實體對齊方法,并根據它們的技術和特點對它們進行了分類。此外團隊還提出了一種新的KG抽樣算法,通過該算法生成了一組具有各種異質性和分布的專用基準數據集,用于現實評估。團隊開發了一個開源庫,包括12種具有代表性的基于嵌入的實體對齊方法,并對這些方法進行了廣泛的評估,以了解它們的優勢和局限性。
Background
作為一個新興的研究課題,基于嵌入的實體對齊的分析和評估仍然存在一些問題。首先,目前還沒有對該領域的現狀進行總結的工作。基于嵌入的實體對齊的最新發展,以及它的優點和缺點仍有待探索。第二,也沒有廣泛認可的基準數據集來評估基于嵌入的實體對齊的現實性。不同的評估數據集使得很難對基于嵌入的實體對齊方法進行公平、全面的比較。此外,與現實世界的KG相比,當前的數據集包含更高的等級(即與許多其他實體相連的實體,這相對容易進行實體對齊),因此,許多方法可能在這些有偏差的數據集上表現出良好的性能。此外,這些數據集只關注異質性的一個方面,例如多語言,而忽略了其他方面,例如不同的語法和規模。這給理解基于嵌入的實體對齊的泛化性和健壯性帶來了困難。第三,該領域的研究只有一部分帶有源代碼,這使得很難在這些方法之上進行進一步的研究。由于這些問題,迫切需要對基于嵌入的實體對齊方法進行全面和現實的重新評估,并進行深入分析。
Contributions
- 全面的調查。調查了最近23種基于嵌入的實體對齊方法,并從不同方面對它們的核心技術和特點進行了分類。我們還回顧了每個技術模塊的流行選擇,簡要概述了該領域。
- 基準數據集。為了進行公平和現實的比較,團隊通過抽樣現實世界中的KGs DBpe dia、Wikidata和YAGO構建了一組五倍分割的專用基準數據集,考慮到實體度、多語言、模式和規模等方面的異質性。團隊提出了一種新的采樣算法,可以使樣本的屬性(如度分布)更接近其來源。
- 開源庫。團隊使用Python和TensorFlow開發了一個開源庫OpenEA。該庫集成了12種具有代表性的基于嵌入的實體對齊方法,屬于多種技術。iTunes采用了靈活的體系結構,可以輕松集成大量現有的KG嵌入模型(已經實現了8個代表性模型)以實現實體對齊。
- 綜合比較和分析。團隊在數據集上對12種具有代表性的基于嵌入的實體對齊方法的有效性和效率進行了全面的比較。通過使用開源庫從頭開始訓練和調整每種方法,以確保公平評估。
- 探索性實驗。團隊在文獻中已有的基礎上進行了三個實驗。團隊首先分析了實體嵌入的幾何特性,以了解它們與最終性能之間的潛在聯系。注意到許多KG嵌入模型還沒有被用于實體對齊,團隊探索了其中8個流行的模型。此外團隊還將基于嵌入的方法與幾種常規方法進行了比較,以探索它們的互補性。
- 未來的研究方向。基于調查和實驗結果,團隊對未來工作的幾個重要研究方向進行了全面的展望,包括無監督實體對齊、長尾實體對齊、大規模實體對齊和非歐幾里德嵌入空間中的實體對齊。
Literature Review
Knowledge Graph Embedding
現有的KG嵌入模型大致可分為三類:(i)平移模型,例如TransE、TransH、TransR和TransD;(ii)語義匹配模型,例如DistMult、ComplEx、HolE、SimplE、RotatE和TuckER;以及(iii)深層模型,例如ProjE、Conv、R-GCN、KB-GAN和DSKG。這些模型通常用于聯系預測。網絡嵌入是其中一個相關的領域,它學習頂點表示以捕捉它們的相似性。然而,網絡中的邊緣攜帶簡單的語義。FB15K和WN18是KGs中聯系預測的兩個基準數據集。評估中廣泛使用了三個指標:(i)頂級關系結果中正確的比例(稱為Hits@m,例如,m=1),(ii)正確聯系的平均排名(MR),以及(iii)平均倒數排名(MRR)。
Conventional Entity Alignment
傳統方法主要從兩個角度解決實體對齊問題。一個是基于OWL語義規定的一個等價推理。另一種是基于相似性計算,它比較實體的符號特征。最近的研究還使用統計機器學習和眾包來提高準確性。此外,在數據庫領域,檢測重復實體(也稱為記錄鏈接或實體解析)已被廣泛研究。這些方法主要依賴實體的文字信息。自2004年以來,OAEI2已成為本體對齊工作的主要場所。它還組織了最近幾年實體對齊的評估跟蹤。首選的評估指標是準確度、召回率和F1分數。
Embedding-based Entity Alignment
許多現有的方法使用平移模型(例如,TransE)來學習基于關系三元組的對齊實體嵌入。最近的一些方法采用了圖卷積網絡(GCN)。除此之外,一些方法還結合了屬性和值嵌入。此外,還有一些用于(異構信息)網絡對齊或跨語言知識投影的方法,這些方法也可以針對實體對齊進行修改。還值得注意的是,兩項研究設計了基于嵌入的數據庫實體解析方法。它們基于單詞嵌入表示實體的屬性值,并使用嵌入距離比較實體。然而,他們假設所有實體遵循相同的模式,或者屬性對齊必須是1對1映射。由于不同的KG通常使用不同的模式創建,因此很難滿足這些要求。就目前而言,沒有廣泛認可的基準數據集來評估基于嵌入的實體對齊方法。常用的數據集是DBP15K和WK3L。
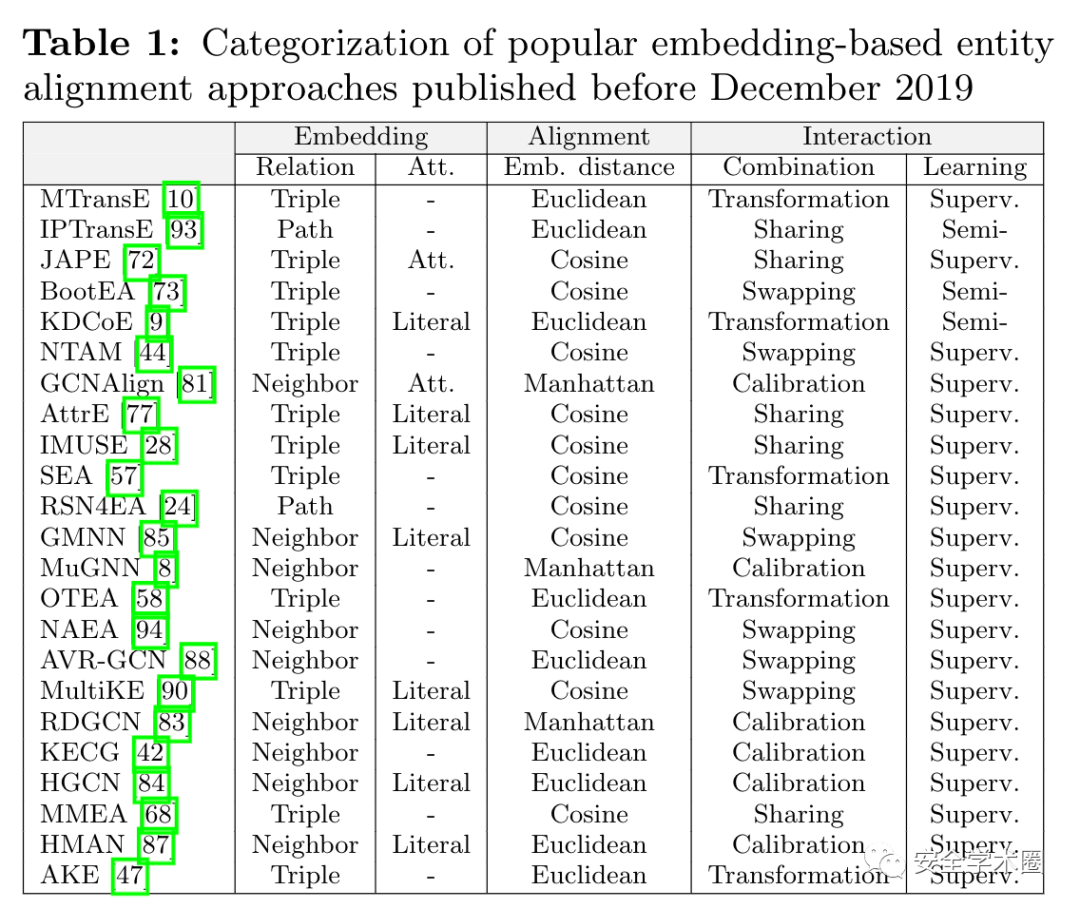
Categorization of Techniques
Embedding Module
嵌入模塊將KG編碼到低維嵌入空間中。根據使用的三元組類型,可將KG嵌入模型分為兩種類型,即關系嵌入和屬性嵌入。前者利用關系學習技術來捕獲結構,后者利用實體的屬性三元組。所有現有的方法都采用關系嵌入法。下面是三種有代表性的實現方法:
基于三元組的嵌入捕獲了關系三元組的局部語義。許多KG嵌入模型都屬于這一類,它定義了一個能量函數來衡量三元組的可擴展性。例如,TransE將關聯解釋為從頭部實體嵌入到尾部的轉化。三元關系 的能量為:
其中 表示向量的 - 或 -范數。TransE優化了邊際排名損失,以預先定義的邊際將正三元組和負三云組分開。負三元組可以使用均勻或負采樣或連續采樣生成。
基于路徑的嵌入利用了跨越關系路徑的關系的長期依賴性。關系路徑是一組三元組,例如 , 。IPTransE通過推斷直接關系和多跳路徑之間的等價性,對關系路徑進行建模。假設從 到 有直接關系 。IPTransE期望 的嵌入類似于路徑嵌入,路徑嵌入被編碼為其組成關系嵌入的組合:
其中 是一種序列合成操作,如最小化。然而,IPTransE忽略了實體。另一項工作是RSN4EA,它修改了遞歸神經網絡(RNN),以便對實體和關系的序列進行建模。
基于鄰域的嵌入使用由實體之間的大量關系構成的子圖結構。GCN非常適合對這種結構進行建模,目前已經用于基于嵌入的實體對齊。GCN由多個圖卷積層組成。設 為KG的鄰接矩陣, 為特征矩陣,其中每一行對應一個實體。從 層到 層的典型傳播規則是:
其中 且 為單位矩陣. 是 的對角矩陣。 是可學習的權重矩陣. 是類似 的激活函數。
有幾種方法使用屬性嵌入來增強實體的相似性度量。屬性嵌入有兩種方法:
屬性相關性嵌入考慮屬性之間的相關性。如果屬性經常一起用來描述一個實體,那么它們就被認為是相關的。JAPE基于相似實體應具有相似相關屬性的假設,利用這種相關性進行實體對齊。對于兩個屬性,它們相關的概率為
其中可以通過最大化所有屬性對的概率來學習屬性嵌入。
文字嵌入將文字值引入到屬性嵌入中。AttrE提出了一種字符級編碼器,能夠在訓練階段處理看不見的值。 是帶字符的文字,其中 是第 字符。AttrE 這樣嵌入 :
這種表示將文字視為實體,而像TransE這樣的關系嵌入模型可以用于從屬性三元組中學習。然而,基于字符的文字嵌入在跨語言環境中可能會失效。
Alignment Module
對齊模塊使用種子對齊作為標記的訓練數據來捕獲實體嵌入的對應關系。兩個關鍵點是選擇距離度量和設計對齊推理策略。
- 距離度量。余弦、歐幾里得和曼哈頓是三種廣泛使用的度量標準。
- 對齊推理策略。目前使用的方法均是貪婪搜索。
Dataset Generation
團隊選擇了三個著名的KG作為來源:DBpedia(2016-10)、Wikidata(20160801)和YAGO 3。此外,團隊還考慮了DBpedia的兩個跨語言版本:英語-法語和英語-德語。團隊使用IDS算法生成具有15K和100K實體的兩種大小的數據集。
團隊評估IDS(degree-based sampling)和數據集的質量。團隊在現有圖形采樣算法的基礎上設計了兩種基線方法:
隨機對齊采樣(RAS) 首先在兩個KG之間隨機選擇一個固定大小(例如15K)的實體對齊,然后提取其頭部和尾部實體都在采樣實體中的關系三元組
基于PageRank的采樣(PRS) 首先根據PageRank分數從一個KG中采樣實體(不參與任何對齊的實體將被丟棄),然后從其他KG中提取這些實體的對應項。
Open-Source Library
團隊使用Python和TensorFlow開發了一個開放的源代碼庫,名為OpenEA,用于基于嵌入的實體對齊。軟件架構如圖所示。

設計目標和特點包括三個方面:
松耦合。嵌入和對齊模塊的實現是相互獨立的。OpeneEA提供了一個帶有預定義輸入和輸出數據結構的框架模板,使這些模塊成為一個集成且完整的管道。用戶可以在這些模塊中自由調用和組合不同的技術,以開發新的方法。
功能性和可擴展性。OpenEA實現了一組必要的函數作為其底層組件,包括嵌入模塊中的初始化函數、丟失函數和負采樣方法;互動模式下的組合與學習策略;以及對齊模塊中的距離度量和對齊推理策略。除此之外,OpenEA還提供了一組靈活的高級功能,以及調用這些組件的配置選項。通過這種方式,可以通過添加新的配置選項輕松集成新功能。
現成的方法。為了方便使用OpenEA,團隊整合或重建12種具有代表性的基于嵌入的實體對齊方法,這些方法屬于多種技術,包括MTransE、IPTransE、JAPE、KDCoE、BootEA、GCNAlign、AttrE、IMUSE、SEA、RSN4EA、MultiKE和RDGCN。
