利用威脅情報報告生成可用攻擊子圖
一、摘要
當前企業環境面臨的攻擊越來越趨于隱蔽、長期性,為了更好的針對這些攻擊進行有效的檢測、溯源和響應,企業通常會部署大量的檢測設備。安全運營人員需要根據這些檢測設備的日志和告警來對攻擊事件進行檢測與溯源。然而攻擊技術的發展通常領先于檢測設備檢測能力。當新攻擊技術或是新漏洞被發現時,通常是以報告的形式公開,針對這些新攻擊的檢測能力往往很難快速的部署到檢測設備中。
網絡威脅情報(CTI),通常是技術報告、白皮書、博客和新聞組中報告,是有關網絡攻擊的寶貴信息來源。這些報告用自然語言描述了攻擊的許多方面,包括行動的順序、對被攻擊系統的影響以及破壞指標(IOC)。威脅情報報告中包含子攻擊相關的主要知識,可以幫助安全運營人員了解攻擊過程并應用于檢測與溯源。已有一些研究工作利用NLP技術從威脅情報報告中提取攻擊行為的相關知識。但該工作現在只處理起步階段,還遠沒能應用到威脅檢測與攻擊溯源上。
主要面臨如下挑戰:
1 在威脅情報報告中,與攻擊行為相關的描述可能只占很小一部分。報告中大量的描述信息與攻擊行為沒有直接關系。
2 威脅情報報告中使用的語句結構與日常生活中使用語言具有較大的差異,其中包含了大量的簡寫,代指和被動語法等。傳統的自然語言處理工具難以對CTI報告進行處理。
3對威脅情報報告中全局的信息進行提取需要理解攻擊行為之間的關系,而理解技術報告中復雜的邏輯是NLP領域公認的難題。
本文以文獻[1]為主要參考來介紹如何基于威脅情報報告提取有效的攻擊子圖。文獻[1]提出了一個工具EXTRACTOR,該工具可以精確的自動的從威脅情報報告中抽取攻擊行為。EXTRACTOR的主要創新性在于其對文本沒有強假設,可以從非結構化文本中提取攻擊行為溯源圖。提取的這些攻擊行為溯源圖可以應用威脅狩獵。
二、相關研究內容與技術框架
攻擊技術的快速發展為安全防護出了更高的要求,如何快速的針對新攻擊技術生成有效的檢測與溯源機制是當前面臨的主要挑戰。從威脅情報中提取可用于檢測與溯源的有效信息是一種可能。但其可行性是能夠基于報告提取到可用于威脅檢查與溯源的信息,這樣可以第一時間對新攻擊進行檢測與溯源。
圖1是njRAT惡意樣本的報告中的一段關于攻擊行為的描述。圖1右側表示是根據威脅情報報告構建的溯源圖。該溯源圖的節點表示與攻擊行為相關的實體如進程、注冊表等,邊表示實體之間的操作行為。njRAT惡意樣本的攻擊子圖可以與終端日志的溯源圖相對應,可以根據該子圖在終端日志溯源圖中進行子圖匹配來進行攻擊檢測。
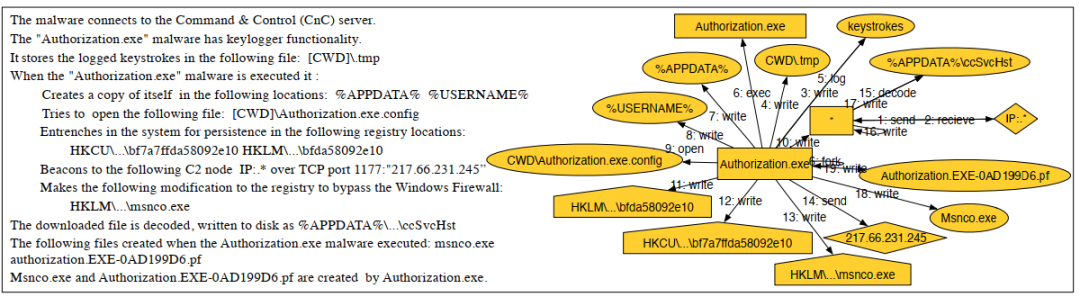
圖1 njRAT
從威脅情報的報告中抽取精確可用的攻擊子圖依然存在不少挑戰。首先,需要在報告中識別與攻擊行為相關的文本,因為威脅情報報告通常很長,其中包含了大量的與攻擊過程不相關信息。這需要了解報告中出現的與攻擊相關的實體,以及這實體之間的相關攻擊行為,據此構建可用于溯源圖威脅檢測的攻擊子圖。其次,威脅情報文本的復雜性將影響溯源的圖的構建性能,這意味著要解決自然語言寫作中存在的不同類型的模糊性和復雜性。
下面以EATRACTOR為例介紹利用NLP技術從威脅情報報告中提取有效的攻擊子圖的框架。

圖2 EXTRACTOR技術框架
EXTRACTOR通過對威脅情報報告進行多次轉換,將其從復雜的、具有歧義的形式轉換成簡單的文本。對簡化后的文本進行進一步處理,得到一個可以成功用于威脅檢測的溯源圖。如圖2所示,整個過程主要包含四個步驟:1 標準化;2 解析過程;3 文本歸納;4 溯源圖生成。標準化是一個初始的數據預處理過程,把報告中的文本內容轉換成規范的形式。文本解析過程是對數據進行消歧。文本概要是刪除文本中與攻擊行為不嚴格相關的信息。攻擊子圖構建是挖掘攻擊行為的時序與因果關系,并構建可用于威脅檢測的攻擊子圖。這些步驟需要一些包含與威脅情報語言的相關的術語字典來輔助。EXTRACTOR一共使用了兩個詞典。一是系統調用同義詞典,包含了表示系統調用(如寫,讀fork)的動詞以及其同義詞。這些同義詞表示可能在威脅情報報告中使用的表示系統調用的動詞。二是報告中的名詞詞典,該詞典包含了報告中常用的名詞詞典,以及同一概念的不同文本表示。其中系統調用詞典包含了87個動詞,名詞詞典包含了1112個名詞短語。
三、 技術細節
為了詳細說明具體細節,以圖1中關于njRAT惡意樣本的攻擊描述為例來進行說明。njRAT惡意樣本Authorization.exe連接C&C服務器,該惡意樣本具有鍵盤記錄功能,把相關的鍵盤記錄寫到本地[CWD]\.tmp文件中。當惡意樣本Authorization.exe執行時,會在本地%APPDATA% %USERNAME%目錄下創建一個副本。同時該木馬試圖打開文件[CWD]\Authorization.exe.config,同時修改下面的注冊表信息HKCU\...\bf7a7ffda58092e10HKLM\...\bfda58092e10以保證該樣本的持續運行。同時修改HKLM\...\msnco.exe以繞過防火墻,然后通過端口1177跟c2“217.66.231.245“進行通信下載相關文件并寫入磁盤%APPDATA%\...\ccSvcHst,在Authorization.exe運行過程中創建了msnco.exe和authorization.EXE-0AD199D6.pf。
針對該樣本的攻擊過程分別人標準化、語法與語義解析、文本歸納以及子圖構建四部分介紹。
3.1 標準化
為了解決威脅情報的文本復雜性挑戰,并最大限度地提高攻擊子圖構建的準確性,首先必須對報告中的句子進行規范化處理。為此,基于標準化方法對報告中進行規范化,把長的復雜句了轉換成簡單的短句。直觀來說,標準化的目標是把復雜的長句變成多個短句,每一個短句子表示攻擊主體對一個攻擊客體執行的某個行為。標準化過程也包含了三部分,分別是句子邊界切割、同質化和句式轉換。這些步驟分別執行了句子邊界檢測、詞的同質化和被動詞到主動詞的轉換。
3.1.1 句子邊界切割
當前的分詞器(如NLTK[2])主要依據句子的標點符號來識別句子的邊界。而在安全領域,包含多個動作信息的長句或是不規范分隔符的情況很多。針對該問題,除了使用典型的句子分隔符之外,還使用新行、點句、枚舉數、標題和頭信息作為句子分隔符把長句劃分為多個短句。通過長句劃分得到的多個詞語的短序列如果滿足下列條件中的一個則認為這個短序列是一個句子。1:該序列是由一個大寫的主語開始,包含了構成一個完整句子的所有組成(主語、謂語和賓語),并且該序列之前或是之后的序列也可以構成一個完整的句子;2:該序列以系統調動詞典中的動詞開始,除了主語之外包含了所有組成,同樣該序列的之前或是之后的序列可以構成一個完整的句子。

圖3 njRAT報告的句子邊界檢測
圖3給出該過程處理njRAT報告的示例。第4行到第9行是一個長句子,描述惡意樣本Authorization.exe執行時的相關行為。首先需要將其按行切分成多個短序列。然后,每個短序列通過詞性標注和依存標注進行打標簽,并檢測該序列是否滿足上面兩個條件。可以看到第4行滿足條件1,第5行到第9行滿足條件2。該過程的結果是一系列短句子,這些短句子更有可能描述一個行為。
3.1.2 同質化
威脅情報報告經常包含可以引入歧義并影響最終結果質量的結構和同義詞。例如,圖1描述中出現的C2和Command and Control是同一實體的不同表示。同質化是指對同一概念的不同文本表示進行統一。使用兩個專門構建的字典對名詞短語和動詞執行同質化,它們將報告中出現的不同術語和名詞和動詞的同義詞映射到審計日志中可以觀察到的實體和動作。例如,C2、C&C和Command and Control需要被映射成“IP:.*”這樣的IP地址通配符。以同樣的方式,使用系統調用動詞在系統調用字典中翻譯作為系統調用同義詞的動詞。同質化可以顯著的減少報告文本中的異構性,從報告中提取可行的情報成為可能。
3.1.3 句式轉換
威脅情報報告文本標準化的最后一步就是把被動詞轉換成主動。這種轉換可以更方便的發現系統對象與系統目標,同時能更精確的進行因果推理。
為了進行這種轉換,首先需要根據詞性標注和依存標記來進行被動句檢測。這種類型的句子主要是由依存樹中特定的已知模式表示。以如下句子為例“This kind of sentence is predominantly represented by specific andknown patterns in DP trees”,在依存樹中,is表示輔助動詞或是被動詞,deleted表示動詞或是依存樹的頭,“the downloaded file”被動句的主語,“by malware”是被動句的謂語。然而在一些情況下,一些代詞是隱含在被動句中,而沒有明顯的出現在句子中。例如,圖3中第10行,代詞malware沒出現在句子中,通過上下文可以知道其是指njRAT惡意樣本Authorization.exe。通過該模式,可以檢測出被動句式,同時能識別句子中顯示或是隱式代詞。通過該過程可以把報告中的長句轉換成短句,每個短句表示一個行為。
3.2 語法與語義解析
在規范后,需要對文本中相關的引用進行解析。尤其是文本中一些暗含的引用必須進行明確的識別。
省略號主語是一種語言結構,也就是指句子中的主語不存在。省略主語會給子圖構建帶來挑戰,從而導致一些攻擊的源節點錯誤。圖3中第5-9行描述的所有動作都是省略主體的例子。針對該挑戰,EXTRACTOR開發了一個Ellipsis Subject Resolver(ESR)模塊。該模塊利用詞性標注和依存標注以及系統調用的字典。解決這個問題的第一步是檢測缺失主語的句子。一旦檢測到這種句子,ESR就會在當前句子之前的句子中出現的實體中建立一個候選主體列表。接下來,該模塊根據候選者與缺失主語的句子的距離(以句子數計算),從列表中挑選出最可能的候選者。特別是,距離越近的候選人被選中的概率就越高。例如,在圖3中,第5-9行的句子中缺少主語。ESR模塊檢測了前面的句子中的主語和其他對象,它選擇了冒號前出現的代詞it作為主語。
代詞解析是指代詞被映射和替換到它們所指的前述實體的過程。在沒有PR的情況下處理文檔(構建出處圖)會導致一個實體出現多個節點(即代詞)。為了解決代詞問題,EXTRACTOR采用了一個流行的核心詞解析模型—NeuralCoref[3]。這個模型在解決威脅情報報告領域的代詞方面效果最好。
隱喻是指用一個詞或代詞來指代句子中以前使用過的另一個詞或短語,以避免重復。在解析步驟完成后,文本由具有明確主語、賓語和動詞的句子組成。ER模塊也在一定程度上減少了文本的數量。然而,主要的文本縮減步驟是在 "解析 "之后執行的,接下來將介紹。
3.3 文本概要
為了減少多余信息,獲得可直接用于檢測攻擊的攻擊行為的簡明描述,需要刪除大量的與攻擊行為不相關的描述。針對冗長的報告需要識別哪些句子描述了攻擊行為。另外需要簡化句子的描述。在每個句子里,通常會出現修飾性詞語如副詞和形容詞,這些詞語對構建攻擊行為子圖的幫助并不大,需要刪除。針對該需求EXTRACTOR設計了一個兩步法。其流程如圖4所示,主要包括一個BERT[4]分類器和一個BiLSTM網絡[5]。
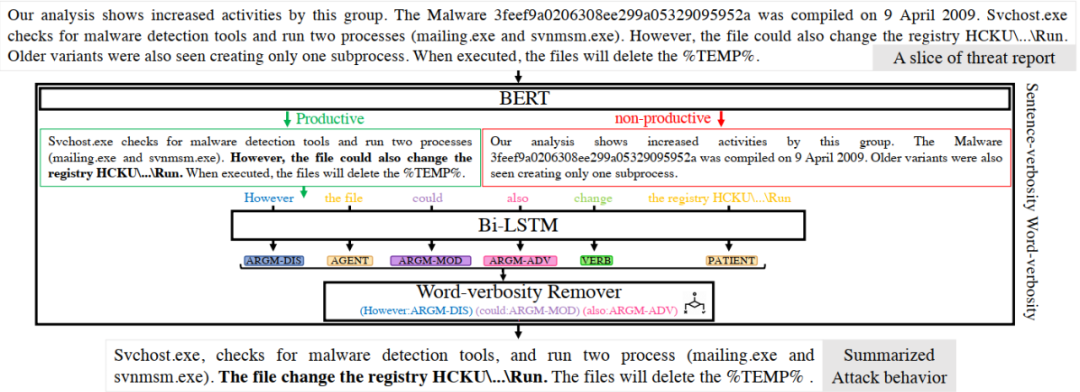
圖4 文本概要模塊示例
為了區分實際威脅行為的句子和普通行為的句子,需要超越主題分類,對文本有更深入的理解。因此,為了對這些聯系進行分類,模型必須建立一個關于單詞上下文的細粒度表示。目前,建立這種細粒度表示法的最佳模型之一是BERT。
文本概要的第二步是從BERT得到的句子中刪除修飾性詞語。它由兩個階段組成,一個是得出句子成分語義的BiLSTM網絡,另一個是去詞階段。
在一個句子被BiLSTM網絡處理后,其成分被標記為Agent、Patient和Action,以及其他類型的參數。在下一個階段,不必要的句子成分被刪除。從理論上講,這只能通過保留句子中的Agent、Action和Patient成分來實現。然而,在某些情況下,這種方法會刪除重要的信息。
3.4 攻擊子圖構建
經過前面的步驟,得到的文本是這樣一種形式:系統主語(如進程)、對象(如文件、套接字)和動作(如執行)是明確的、有序的,而且大部分多余的信息均被刪除。
這一階段的目標是根據處理好的文本生成一個有效的攻擊子圖。該步主要是基于文本識別語義實體與關系。實體的語義識別依據語義角色標簽(SRL),關系與信息流方法通過因果關系挖掘方法實現。
SRL是一種發現句子中的語義角色的技術。圖5中的兩句子是上文中報告的惡意樣本的兩個攻擊行為描述。一個是主動形式的,一個是被動形式的。SRL能夠從每個句子中提取兩個角色(用Raw SRL表示),并理解哪個名詞是目標者(也就是動作落在上面的人,用ARG1表示),哪個是代理人(攜帶動作的名詞,用ARG0表示)。一個SRL角色可以被認為是一個動作。因此,SRL能夠正確地將句子中的每個成分與語義標簽聯系起來。
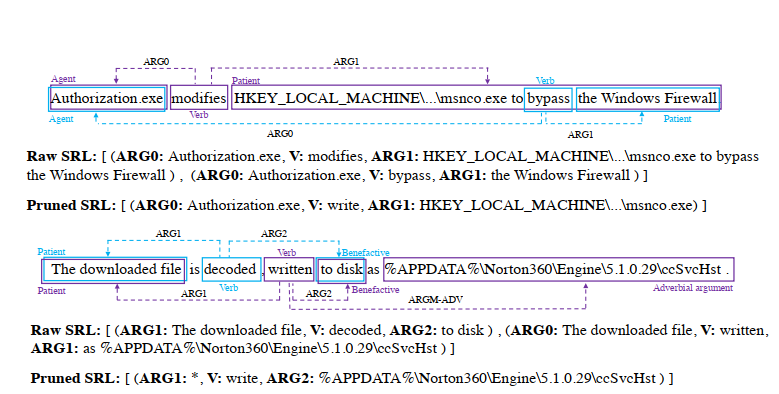
圖5 SRL標注示例
然后要根據SRL的輸出構建攻擊子圖。首先,將具有相同文本的SRL合并到同一個節點中,并剔除不屬于系統實體的詞。接下來,使用以下方法構建圖。1)源節點-邊-目標節點三元組。對于每個句子,如果它至少有三個角色,包括一個動詞角色(作為連接器的系統調用表示)和兩個實體,據此生成一個三元組。2)邊的方向依據系統調用與系統數據流動方向來確定。
四、總結
針對檢測設備檢測能力的滯后性,如果能夠從威脅情報中自動的提取相關攻擊子圖可以直接應用到終端日志溯源圖中,可以大大提高檢測的時效性。EXTRACTOR方法提供了一套有效可行的技術框架。但是由于NLP技術的局限,在實際應用過程中依然存在不少的挑戰,其次在實驗驗證過程中該方法針對惡意樣本效果較好,針對其他復雜多步攻擊的效果依然有待于提高。
參考文獻
1 Satvat K, Gjomemo R , Venkatakrishnan V N . EXTRACTOR: ExtractingAttack Behavior from Threat Reports[J]. 2021.
2 https://www.nltk.org/
3 https://github.com/huggingface/neuralcoref.
4Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of DeepBidirectional Transformers for Language Understanding[J]. 2018.
5 Huang Z , Wei X , Kai Y . BidirectionalLSTM-CRF Models for Sequence Tagging[J]. Computer Science, 2015..
