惡意npm包的自動化挖掘方法
0x01 Intro
Javascript流行已久,V8引擎更是讓其進化為服務端開發語言的一員。其對應的包管理工具NPM中存在著大量的可重用軟件包,體量巨大。社區的熱度促進了NPM的發展,也促進了Node.js的發展。但在NPM中發布一個新的包只需要注冊一個NPM賬戶即可,更新一個包的新版本也只需要簡單地進行注冊表上傳同步。惡意包在近幾年成為一大焦點問題,因為哪怕官方很快地發現并清除了這些惡意包,在注冊表中存活很短一段時間最終也會影響到一大片終端用戶。
要從根本上解決這個問題,無非是從兩個方面:一是阻斷這些惡意包被同步到注冊表中,即嚴格執行審查機制,在這些惡意包從上傳開始到實際被同步到注冊表中的這段時間里進行檢查并清理;二是執行訪問控制來限制包的安裝過程,縮小攻擊面。作者則是考慮在不改變現有的NPM基本過程的情況下,盡可能快地檢測出惡意包,然后清理。(題外話,讀者認為如此重要的一大社區生態,為了提高整體安全性做出一些改變是值得好好考慮的。
作者為了驗證其方法在實際情況下的有效性,提出了三個準則:
- 自動化,不使用人工審查
- 實時性,需要跟上版本更迭速度
- 準確率,避免錯誤標記正常包或是遺漏惡意包
0x02 Method
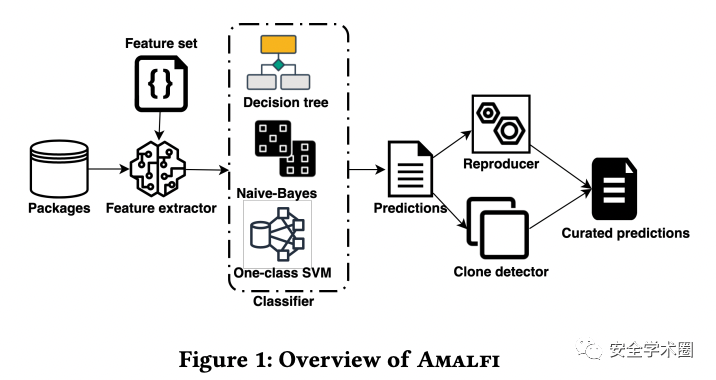
作者提出了AMALFI來滿足上述有效性準則:
- 用標記數據進行機器學習分類器的訓練,包括APIs特征和用輕量語義掃描獲得的元數據
- 使用源代碼進行包的重構,并與其在注冊表中發布的版本進行比較
- 相似度檢測器,用于對已知惡意包的檢查
0x021 Feature set
單包特征包括:
- 獲取終端用戶個人敏感信息:賬戶、密碼等
- 訪問特定的一些系統資源
- 2.1. 文件操作:讀取/寫入
- 2.2. 進程創建:創建新進程
- 2.3. 網絡請求:收發數據
- 使用特定的一些APIs
- 3.1. 加密功能
- 3.2. 數據編碼
- 3.3. 動態代碼生成
- 安裝時運行腳本
- 短代碼(避免檢測)或二進制文件(可執行文件)
多版本特征包括:
- 版本發布的間隔時間
- 版本更新說明中描述的更新類型
需要說明的是,對于第一次上傳到注冊表中的包,作者引入了一個偽更新版本,設定版本發布之間的時間為0,更新類型則是單包特征中的描述。(題外話,作者并沒有解釋為何設定為0,讀者存疑:難道不存在一個年久失修的包突然被攻擊者接管的可能性么?
0x022 Feature extraction
作者使用Tree-sitter來解析包中的Javascript和Typescript文件以獲取單包特征:對于特征1,字符串匹配;對于特征2和特征3,API匹配;對于特征4,調用eval和Function來生成代碼;對于特征5,考慮Shannon熵值。對于多版本特征則是利用npm view time獲取版本發布時間間隔;利用語義分析獲取更新類型。(作者未在文中給出相關啟發式規則,感興趣可以進一步去代碼中看。
0x023 Classifier trainning
據讀者先前的研究,NPM刪除的包是不存在緩存的,也就是說沒有任何途徑再從官方的源中下載到。作者的惡意包是找NPM索取的。在索要到的643個惡意包的基礎上,作者增加了1147個同一日期發布的正常包,構成了一個總量為1790的帶標簽語料庫(題外話,這個語料庫的量對于在當時單版本就有170w個包的總數據量是否有些小了,但在這個領域樣本差距也是無可奈何的?
也正是為了解決樣本的極度不平衡性,作者最后鎖定了三個算法:決策樹、樸素貝葉斯分類器和一分類SVM。決策樹能很好地說明特征重要性,后兩者主要是解決樣本不平衡問題。文章中值得注意的是在訓練一分類SVM時,作者設定v參的值為0.001,這個參數有點類似預期異常點(并不是verbose)。這意味1000個包的版本中存在著一個惡意版本。但實際上,作者描述到其在訓練一分類SVM時使用的都是正常版本的包。關于這一點,讀者在自己研究的時候也注意到了這一點,即預期異常概率的設定會嚴重影響到模型精確度,這里是值得好好考慮的一個點。(按作者的思路,哪怕訓練使用的是全部正常的版本,也需要設定一個本不需要的預期異常概率。讀者認為這里的做法的確不太合理,應當是按照比例投放幾個已知惡意包滿足預定比例,以此檢查模型性能。
0x024 Reproducer and clone detector
所謂reproducer就是指從源代碼重新構建生成軟件包。實際上,作者稱礙于各種現實原因(沒有源代碼倉庫、git提交記錄對不上之類),很多正常的包也沒辦法還原生成,只能算作是一個效率不高的過濾器。clone detector主要是計算包內文件的md5值,并與已知惡意包的哈希值列表進行比較。考慮到包的具體情況不同,作者忽略了包名和版本。(題外話,讀者認為首先reproducer效率有待改進,作為一個簡單過濾器放在這里沒有問題。但是這個clone detector只忽略了包名和版本,攻擊者修改文件中涉及的IOCs或是隨意調整編碼不就能夠繞過了么,這里的方法讀者認為相當不嚴謹。
0x03 Conclusion
作者提出了AMALFI,這是一個用于檢測惡意npm包的方法,包括了三個主要部件:一個在已知惡意包和正常包的樣本上訓練出的分類器;一個用于從源代碼構建包的重構器;一個用于查找已知惡意包的檢測器。
讀者小結,該文提出的方法其實沒有滿足其在文章開始提到的三個準則。放棄人工審查并不能說明該方法表現更佳,就文章中表現出的種種,很難不相信這算一種掩耳盜鈴的想法。分類器結合了各個算法的優點是很不錯的思路,但本質上還是在做一個異常檢測(一分類)問題,作者在設置一分類SVM參數時講到其訓練使用的都是正常版本的軟件包(沒有滿足比例的惡意樣本),但卻將預期異常概率設定為0.001,這里邏輯上是說不通的。同時,唯二模型輸出后的過濾器,一個not work well,一個取hash值時不嚴謹易被繞過。換句話說,過濾器沒有起到相對有效的結果,那這個最終結果是否符合現實情況是需要打一個大大的問號的。
