高效、私有且健壯的聯邦學習
Overview
聯邦學習已經在各種關鍵任務的大規模場景中顯示出巨大的成功。然而, 這種分布式學習模式仍然容易受到隱私的干擾和拜占庭攻擊。前者旨在推斷參與訓練的目標參與者的隱私, 而后者則專注于破壞所建模型的完整性。近些年來的工作通過利用通用安全計算技術和常見的旁觀者保護的聚合規則, 探索了統一的解決方案, 但有兩個主要的限制 (1)由于效率瓶頸; (2)由于模型的不全面性,它們仍然容易受到各種攻擊。
為了解決上述問題, 團隊提出了SecureFL, 一個高效的、私有的和防篡改的FL框架。SecureFL遵循最先進的拜占庭魯棒性FL方法(FLTrust), 它通過歸一化更新的幅度和測量二重相似性來實現全面的拜占庭防御, 并使其適應隱私保護的背景。團隊定制了一系列的加密組件。首先,設計了一個加密友好的有效性檢查協議 , 在功能上取代了 FLTrust中的規范化操作, 并在此基礎上進一步設計了個性化的加密協議。上述優化措施使通信和計算成本減少了一半, 而沒有犧牲穩健性和隱私保護。其次, 團隊為矩陣乘法開發了一種新的預處理技術,使得方向性相似性測量的計算開銷可以被忽略,并且能夠通過安全評估。在三個真實數據集和各種神經網絡架構上進行的廣泛評估表明, SecureFL在效率上優于現有技術兩個數量級, 具有最先進的拜占庭魯棒性。
Contributions
- 團隊提出了一個新的聯邦學習框架,
SecureFL,它實現了最先進的魯棒性,完全隱私保護和效率的同時。 - 團隊設計了一系列個性化的加密組件,在私有的魯棒性聚合評估中實現高效的數學運算。
- 大量的實驗表明,
SecureFL在效率上優于先前的技術兩個數量級,具有最先進的魯棒性。
Model
在我們的SecureFL中,有兩種類型的對手:惡意方,通過發送中毒的梯度來主動破壞全局模型;誠實但好奇的服務器(即SP和CS),遵循私有健壯聚合協議,但嘗試被動地推斷關于目標方的訓練數據 的信息。通常情況下,惡意方有以下知識:被破壞的局部訓練數據和局部梯度、訓練算法、損失函數和局部學習速率。后者服務器可以訪問各方的本地梯度、聚合算法和種子數據。這種設置是合理的,也符合現實世界的FL系統。
Crypto-friendly Byzantine-robust FL Protocol
Revising FLTrust
FLTrust的主要思想是收集一個小但干凈的種子數據集,計算數據集上的服務器更新 并將其作為基線,以檢測和排除拜占庭方。首先通過縮放使每個局部梯度具有相同的大小來歸一化,然后,服務商給每個局部梯度分配一個信任分數,如果局部模型更新的方向與服務器更新的方向更相似,則信任分數更大。在形式上,它是通過余弦相似度測量和基于relu的裁剪來實現的。除了魯棒聚合過程,FLTrust的訓練過程與大多數FL的協議一致,其中的步驟包括:梯度規范化、計算梯度的方向相似度、聚合加權梯度。
它仍然面臨兩個關鍵的效率問題:1)規范化在FLTrust中是一個高消耗的操作,因為其涉及到倒數平方根。2)所有參與方的方向相似性度量可以形式化為矩陣向量乘法,但由于模型梯度維數高、參與方數量多,耗時較長。
Crypto-friendly byzantine-robust FL protocol
用于規范化的加密友好性協議。即將規范化的實現留在一方的明文中,因為每個局部梯度的這種處理是獨立于其他梯度的。然而,該方法最大的挑戰是惡意方可能會以錯誤的形式提供局部梯度。為了解決這個問題,團隊設計了一個有效性檢查協議來捕獲偏離規范化的惡意方。其主要思想是檢驗各局部梯度的平方范數 是否在一定區間內,如下所示:
其中 為預定的常數閾值。如果正確規范化了局部梯度,則 的值為1,否則為0.
相似性度量的新計算范式。在現實場景中,大多數方移動設備只有很少的計算資源和有限的通信帶寬。而公有云服務提供商,擁有先進的計算設備和極高的帶寬。受上述資源不對稱的啟發,團隊認為SP可以在各方的局部梯度可用之前對繁重的加密操作進行預處理。為此,團隊提出了一種新的方向相似度度量計算模式,它包括兩個階段,即前序階段和在線階段,并根據是否存在局部梯度來區分這兩個階段。在前序階段,SP使用服務器梯度 執行矩陣乘法的預處理。受益于前序階段的工作,在線階段的余弦相似度測量的計算開銷可以忽略不計通信成本為零。
SecureFL Framework
階段一 初始化階段
這個階段在整個協議中只被調用一次,將生成Beaver乘法三元組和PLHE的密鑰對。
階段二 前序階段
該階段的執行可以獨立于局部梯度,其中進行矩陣乘法的預處理,以此提高在線階段的效率。
階段三 在線階段
當各方的本地梯度可用時,此階段運行。假設各方完成了局部訓練并獲得了歸一化的局部梯度,穩健聚合評估協議包括以下步驟:
- 梯度秘密共享
- 有效性檢查
- 余弦相似度檢查
- 信任分數計算
- 加權聚合
Evaluation
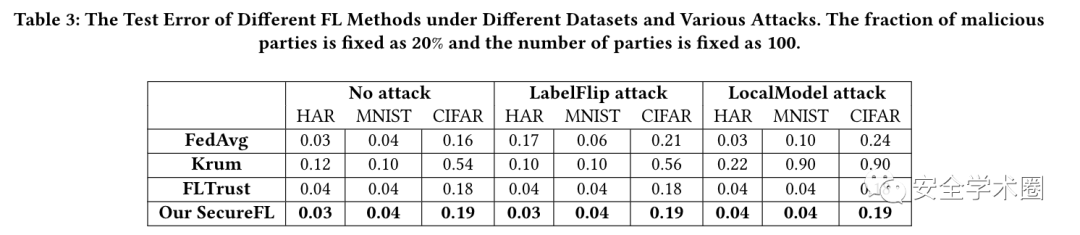
下圖顯示了SecureFL的執行時間和通信成本。從圖4(a)和圖4(c)可以看出,SP和CS的執行時間均隨參與方數量和數據項數量的增加而線性增加。這表明SecureFL具有出色的可伸縮性。
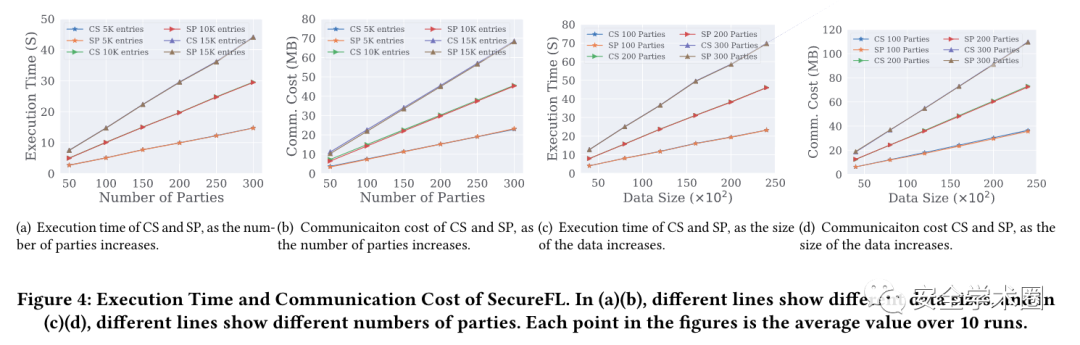
圖5(a)和5(b)比較了在三個數據集和不同的模型架構上之前的工作和SecureFL的健壯聚合所需的執行時間和通信成本。可以看出,SecureFL在效率上優于現有技術兩個數量級。
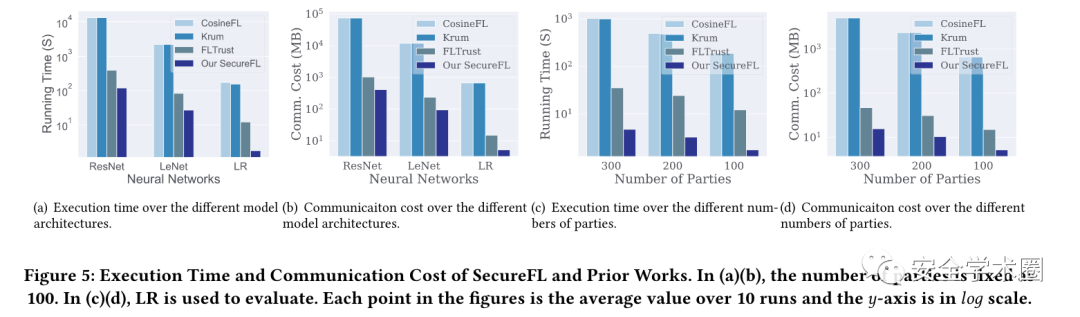
將SecureFL與之前的工作進行了比較,包括FedAvg、Krum和FLTrust,它們都是FL框架中流行的聚合規則。表3給出了三種攻擊設置和三種真實數據集下不同的測試錯誤。可以觀察到SecureFL在沒有攻擊的情況下可以達到與傳統FedAvg方法相當的準確率。此外,無論是否受到拜占庭式攻擊,SecureFL也有與最先進的FLTrust類似的測試錯誤,這表明加密友好型變體并不犧牲魯棒性和推理準確性。相比之下,現有的方法,如FedAvg和Krum仍然容易受到高級拜占庭攻擊。這是因為SecureFL考慮了局部梯度的大小和方向以抵抗現有的攻擊。