基于LSTM的二進制代碼相似性檢測
前言
近年來自然語言處理的快速發展,推出了一系列相關的算法和模型。比如用于處理序列化數據的RNN循環神經網絡、LSTM長短期記憶網絡、GRU門控循環單元網絡等,以及用于計算詞嵌入的word2vec、ELMo和BERT預訓練模型等。
近幾年也出現了一些論文研究這些模型和算法在二進制代碼相似性分析上的應用,可以實現跨平臺的二進制代碼相似性檢測。本文根據上述模型和算法實現了一個基于word2vec和LSTM的簡單模型用于判斷兩個函數或者兩個指令序列是否相似。
總體框架

函數嵌入
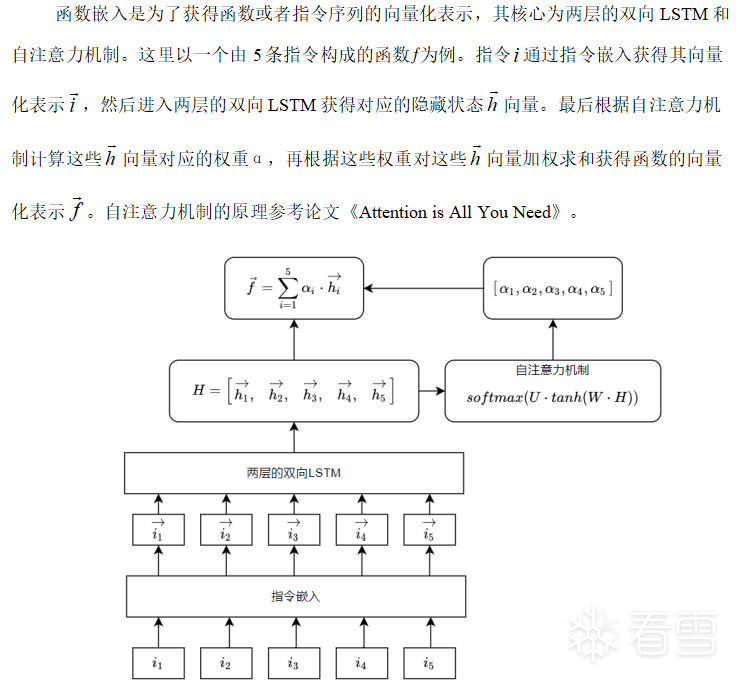
LSTM是RNN的一個變體,由于RNN容易梯度消失無法處理長期依賴的問題。LSTM在RNN的基礎上增加了門結構,分別是輸入門、輸出門和遺忘門,在一定程度上可以解決梯度消失的問題,學習長期依賴信息。LSTM的結構如下:
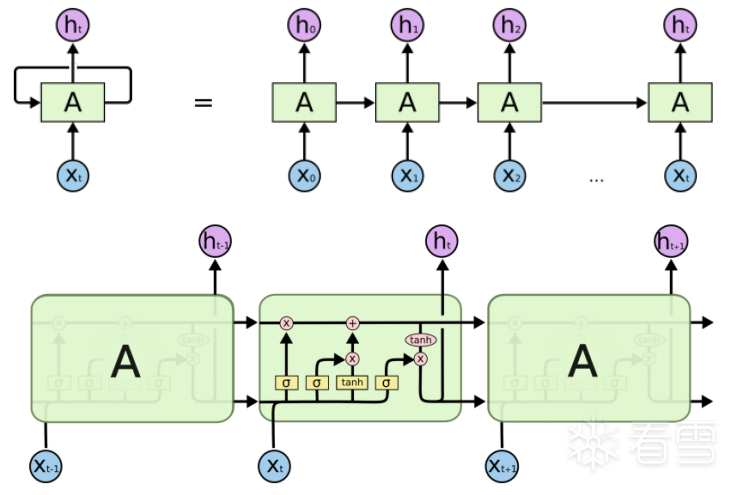
運算規則如下:
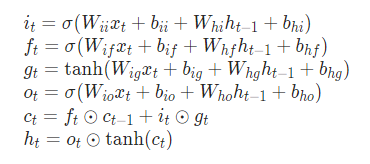
W和b都是LSTM待學習的參數,具體參數細節可以參考pytorch的官方文檔。
指令嵌入
指令嵌入的目的是也為了獲得指令的向量化表示,方便LSTM等其它模型進行計算。這里使用word2vec的skip-gram模型實現。word2vec是谷歌公司開源的一個用于計算詞嵌入的工具,包含cbow和skip-gram兩個模型。指令嵌入具體實現細節如下:
(1)操作碼、寄存器、加減乘符號以及中括號都看成一個詞。比如mov dowrd ptr [0x123456+eax*4], ebx這條指令可以得到mov,dowrd,ptr,[,0x123456,+,eax,*,4,],ebx。然后這條指令看成一個句子送入word2vec進行訓練,進而得到每一個詞的向量化表示。
(2)為了減小詞庫的大小。操作數中超過0x5000的數值用mem,disp,imm代替。
[0xXXXXXXXX] -> [mem][0xXXXXXXXX + index*scale + base] -> [disp + index*scale + base]0xXXXXXXXX -> imm
(3)指令向量由一個操作碼對應的向量和兩個操作數對應的向量三部分組成,操作數不夠的指令添加0向量補齊。對于超過兩個操作數的指令,則最后兩個操作數的向量求和取平均。操作數里面有多個詞的情況下,各個詞向量求和取平均表示當前操作數的向量。
代碼實現
模型的代碼實現用的是深度學習框架pytorch,word2vec的實現用的gensim庫。word2vec的調用參數在insn2vec.py實現如下:
model = Word2Vec(tokensList, vector_size=wordDim, negative=15, window=5, min_count=1, workers=1, epochs=10, sg=1) model.save('insn2vec.model')
tokensList的元素是一個列表,保存的是一條指令分詞(tokenization)后的各個詞序列。word2vec訓練完成后保存到insn2vec.model文件,方便后續進行進一步的微調。
指令嵌入的實現在lstm.py文件中,實現如下:
class instruction2vec(nn.Module): def __init__(self, word2vec_model_path:str): super(instruction2vec, self).__init__() word2vec = Word2Vec.load(word2vec_model_path) self.embedding = nn.Embedding.from_pretrained(torch.from_numpy(word2vec.wv.vectors)) self.token_size = word2vec.wv.vector_size#維度大小 self.key_to_index = word2vec.wv.key_to_index.copy() #dict self.index_to_key = word2vec.wv.index_to_key.copy() #list del word2vec def keylist_to_tensor(self, keyList:list): indexList = [self.key_to_index[token] for token in keyList] return self.embedding(torch.LongTensor(indexList)) def InsnStr2Tensor(self, insnStr:str) -> torch.tensor: insnStr = RefineAsmCode(insnStr) tokenList = re.findall('\w+|[\+\-\*\:\[\]\,]', insnStr) opcode_tensor = self.keylist_to_tensor(tokenList[0:1])[0] op_zero_tensor = torch.zeros(self.token_size) insn_tensor = None if(1 == len(tokenList)): #沒有操作數 insn_tensor = torch.cat((opcode_tensor, op_zero_tensor, op_zero_tensor), dim=0) else: op_token_list = tokenList[1:] if(op_token_list.count(',') == 0): #一個操作數 op1_tensor = self.keylist_to_tensor(op_token_list) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op_zero_tensor), dim=0)#tensor.mean求均值后變成一維 elif(op_token_list.count(',') == 1): #兩個操作數 dot_index = op_token_list.index(',') op1_tensor = self.keylist_to_tensor(op_token_list[0:dot_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot_index+1:]) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor.mean(dim=0)), dim=0) elif(op_token_list.count(',') == 2): #三個操作數 dot1_index = op_token_list.index(',') dot2_index = op_token_list.index(',', dot1_index+1) op1_tensor = self.keylist_to_tensor(op_token_list[0:dot1_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot1_index+1:dot2_index]) op3_tensor = self.keylist_to_tensor(op_token_list[dot2_index+1:]) op2_tensor = (op2_tensor.mean(dim=0) + op3_tensor.mean(dim=0)) / 2 insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor), dim=0) if(None == insn_tensor): print("error: None == insn_tensor") raise insn_size = insn_tensor.shape[0] if(self.token_size * 3 != insn_size): print("error: (token_size)%d != %d(insn_size)" % (self.token_size, insn_size)) raise return insn_tensor #[len(tokenList), token_size] def forward(self, insnStrList:list) -> torch.tensor: insnTensorList = [self.InsnStr2Tensor(insnStr) for insnStr in insnStrList] return torch.stack(insnTensorList) #[insn_count, token_size]
instruction2vec類的作用就是指令嵌入,token_size是詞的維度大小,指令維度的大小為token_size*3。初始過程中主要是加載word2vec訓練好的詞向量word2vec.wv.vectors,方便InsnStr2Tensor把字符串形式的指令轉換到向量。
函數嵌入的代碼實現如下:
class SiameseNet(nn.Module): def __init__(self, hidden_size=60, n_layers=2, bidirectional = False): super(SiameseNet, self).__init__() self.insn_embedding = instruction2vec("./insn2vec.model") input_size = self.insn_embedding.token_size * 3 #input_size為指令的維度, hidden_size為整個指令序列的維度 self.lstm = nn.LSTM(input_size, hidden_size, n_layers, batch_first=True, bidirectional = bidirectional) self.D = int(bidirectional)+1 self.w_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, hidden_size * self.D)) self.b_omega = nn.Parameter(torch.Tensor(hidden_size * self.D)) self.u_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, 1)) nn.init.uniform_(self.w_omega, -0.1, 0.1) nn.init.uniform_(self.u_omega, -0.1, 0.1) def attention_score(self, x): #x:[batch_size, seq_len, hidden_size*D] u = torch.tanh(torch.matmul(x, self.w_omega)) #u:[batch_size, seq_len, hidden_size*D] att = torch.matmul(u, self.u_omega) #att:[batch_size, seq_len, 1] att_score = F.softmax(att, dim=1)#得到每一個step的hidden權重 #att_score:[batch_size, seq_len, 1] scored_x = x*att_score #類似矩陣倍乘 return torch.sum(scored_x, dim=1)#加權求和 def forward_once(self, input:list) -> torch.tensor: lengths = []#記錄每個指令序列的長度 out = [] for insnStrList in input: insnVecTensor = self.insn_embedding(insnStrList)#把指令轉換到向量 out.append(insnVecTensor) lengths.append(len(insnStrList)) pad_out = pad_sequence(out, batch_first=True)#填充0使所有handler的seq_len相同 pack_padded_out = pack_padded_sequence(pad_out, lengths, batch_first=True, enforce_sorted=False) packed_out,(hn,_) = self.lstm(pack_padded_out)#input shape:[batch_size, seq_len, input_size] #hn:[D*num_layers,batch_size,hidden_size] #out:[batch_size, seq_len, hidden_size*D],此時out有一些零填充 out,lengths = pad_packed_sequence(packed_out, batch_first=True) out = self.attention_score(out) return out def forward(self, input1, input2): out1 = self.forward_once(input1)#out1:[batch_size,hidden_size] out2 = self.forward_once(input2) out = F.cosine_similarity(out1, out2, dim=1) return out
因為函數嵌入的輸入是一對函數,所以該模型也是一個共享參數的孿生神經網絡。hidden_size是函數的維度大小,這里設置成60維。attention_score對應的是注意力機制,w_omega是W矩陣,u_omega是U矩陣。pytorch的LSTM輸入類型為[batch_size, seq_len, input_size]的張量,相當于是一個batch_sizeseq_leninput_size的矩陣,batch_size對應是函數個數,seq_len對應的是指令的個數。
雖然LSTM可以處理任意長度的序列,但是為了加速運算,pytorch的lstm輸入需要seq_len相同,所以需要添加0向量對齊。因為添加了0向量,對整個模型可能會有一定的影響。在經過W和H的點乘后,也就是torch.tanh(torch.matmul(x, self.w_omega))運算后需要一個特殊處理,需要把這些添加的0向量弄到負無窮大,這樣在注意力機制的softmax運算中會使這部分向量對應的權重趨近于0,也就是注意力不應該放在這些0向量身上。這個處理我沒有加,大家感興趣的話自己改一改。
模型評估
指令的向量維度為30,函數的向量維度為60。數據集使用了6個二進制文件:
ntdll_7600_x64.dllntoskrnl_7600_x64.exewin32kfull_17134_x64.sysntdll_7600_x32.dllntoskrnl_7600_x32.exewin32kfull_17134_x32.sys
x86和x64各三個文件,使用angr總共提取出4437個函數,函數名相同的x86和x64函數構成一個相似的正例。x86函數中隨機選取一個不同名的x64函數構造一個負例,或者x64函數中隨機選取一個不同名的x86函數構造一個負例。數據集樣本的正負比例為1:1,總的樣本數為4437*2,再按8:1:1劃分為訓練集、驗證集和測試集。其實正負樣本里應該還要加一些x86對應x86或者x64對應x64的正負樣本,使數據分布的更均勻些。隨機梯度下降法的學習率設置為0.09,批度大小8,迭代次數為50。
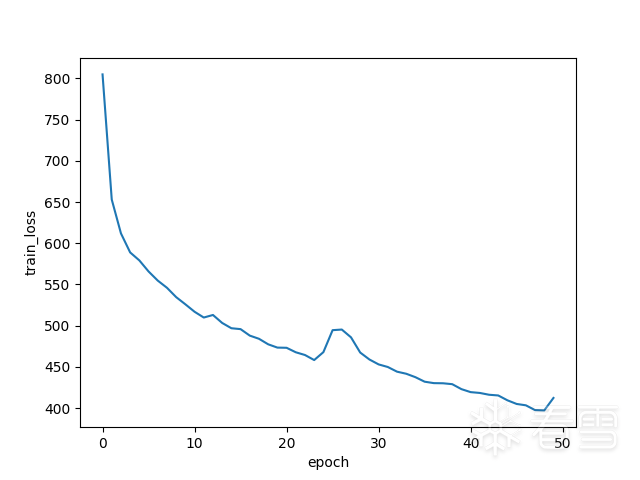


前面兩張圖片分別是訓練集和驗證集隨著迭代次數的損失loss下降情況。可以看到根據訓練集的loss還沒收斂的情況下,驗證集的loss就已經收斂不怎么下降。再訓練下去的話,大概率是會過擬合(overfitting),主要原因還是數據太少了。
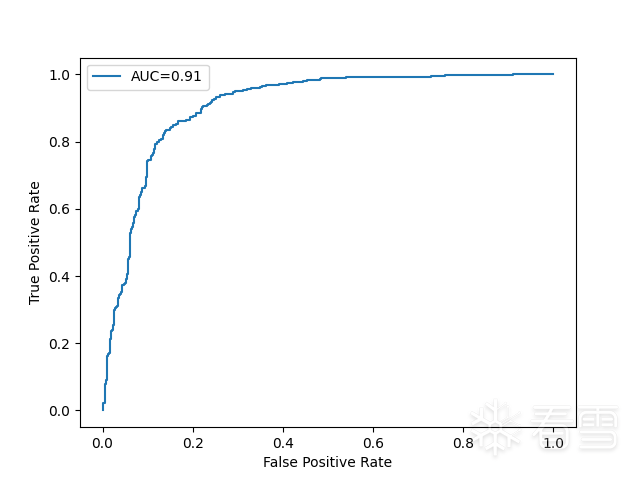
第三張圖是ROC曲線,該曲線的AUC(Area Under Curve)為0.91,AUC越接近1越好。根據ROC曲線可以得出當兩個函數的余弦相似度的閾值設置0.24時,驗證集和測試集的準確度都可以達到84%。
總結
模型準確度達不到90%以上的主要原因還是數據量不夠,深度學習的核心在于足夠多且有效的數據量。其次word2vec無法處理一詞多義的問題,基于word2vec實現的指令嵌入,同樣的指令計算出同樣的向量化表示,即使有不同的上下文。比如有以下兩個指令序列:
mov eax, [0x12345678] add eax, [0x12345678]shl eax, 2 shl eax, 2ret inc eax
上述兩條shl eax, 2指令有不同的上下文,應需要不同的向量化表示。最后,函數的處理應以基本塊為單位,函數中的指令序列受控制流的影響不完全是順序執行,控制流圖的向量化表示可以引入一個圖神經網絡獲取。
參考資料
SAFE: Self-Attentive Function Embeddings for Binary Similarity;
A simple function embedding approach for binary similarity detection;
Understanding LSTM Networks
