容器安全之CVE-2022-0185
最近的CVE-2022-0185還是挺有意思的,在谷歌kctf(基于 K8s 的 CTF)中被發現。這個洞是在Linux內核的文件系統上下文中功能中的legacy_parse_param函數驗證長度的代碼處有缺陷,導致了一個基于堆的緩沖區溢出(整數下溢)。
攻擊影響為越界寫入/拒絕服務/權限提升和特定場景下的容器逃逸(k8s)。
其中會涉及到一些容器安全的基礎小知識,有必要簡單學習一下這個洞。
0x01 前置知識
1.Capabilities機制
這個機制在容器逃逸中很常見
suid和capabilities
capabilities機制是一種在Linux權限控制機制中的一種,這里權限控制是指對root的權限進行劃分控制。
首先要知道suid(Set owner User ID)對于權限的控制,suid的含義是允許一個文件的owner在執行這個文件的時候,以root的權限執行,不需要密碼。比如普通用戶改密碼使用的passwd命令(euid會設置為這個程序的所有者,root的話euid會設置為0)。而suid是有安全隱患的,簡單來說就是有的情況下suid設置后去運行一個命令時,只是需要一小部分特權但是suid卻給了root的全部權限,常見滲透中的的suid提權就是因為一個程序的所有者是root或者高權用戶,并且有suid權限,才會可以被利用來提權。
suid控制權限太粗糙,所以引入的capabilities機制(Linux內核2.2后引入),和suid直接以root高權來運行程序不同的是,capabilities機制將root權限進行細分,可以對細分后的“子權限”來進行啟用或者禁用。比如進行實際操作的時候,euid不為root的話,便會檢查是否具有該特權操作所對應的capabilities,來決定是否可以執行特權操作。
常見特權操作對應的capabilities如下:
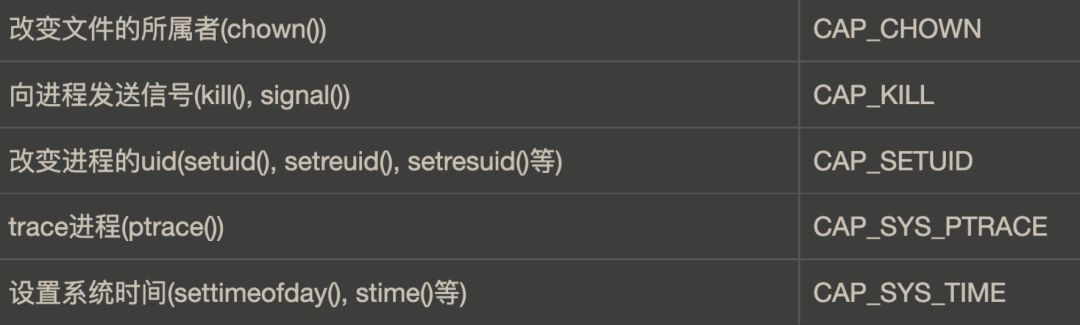
更多capabilites 列表詳細見:http://man7.org/linux/man-pages/man7/capabilities.7.html
Capabilities集合分類
Capabilities的類型可以分為線程/進程的Capabilities和文件的Capabilities兩種,并且capabilities在進程與文件中的集合分類稍有區別。分別集合的含義都簡單的標注了一下,了解即可。
文件中的Capabilities有三個集合:
- Permitted #集合的上限,權限不過超過這個集合
- Inheritable #通過execve繼承給新進程的能力
- Effective #一個標識位,是否開啟影響執行execve() 后,線程 Permitted 集合中的 capabilities 是否會自動添加到它的 Effective 集合中
進程中的Capabilities有五個集合:
- Permitted #集合的上限,權限不過超過這個集合
- Inheritable #通過execve繼承給新進程的能力
- Effective #標志位,內核正在檢查是否可以特權操作就是檢查這里。
- Bounding
- Ambient
上面的兩個集合只標注了比較重要的部分,而這倆類型的集合會確定最終程序運行起來的capabilities,是有標準的計算公式的。篇幅原因這里不展開敘述。
獲取和設置capabilities
常見使用libcap來管理Capabilities。
獲取capabilities也很簡單,比如可以通過/proc//task//status文件來查看線程的capabilities:
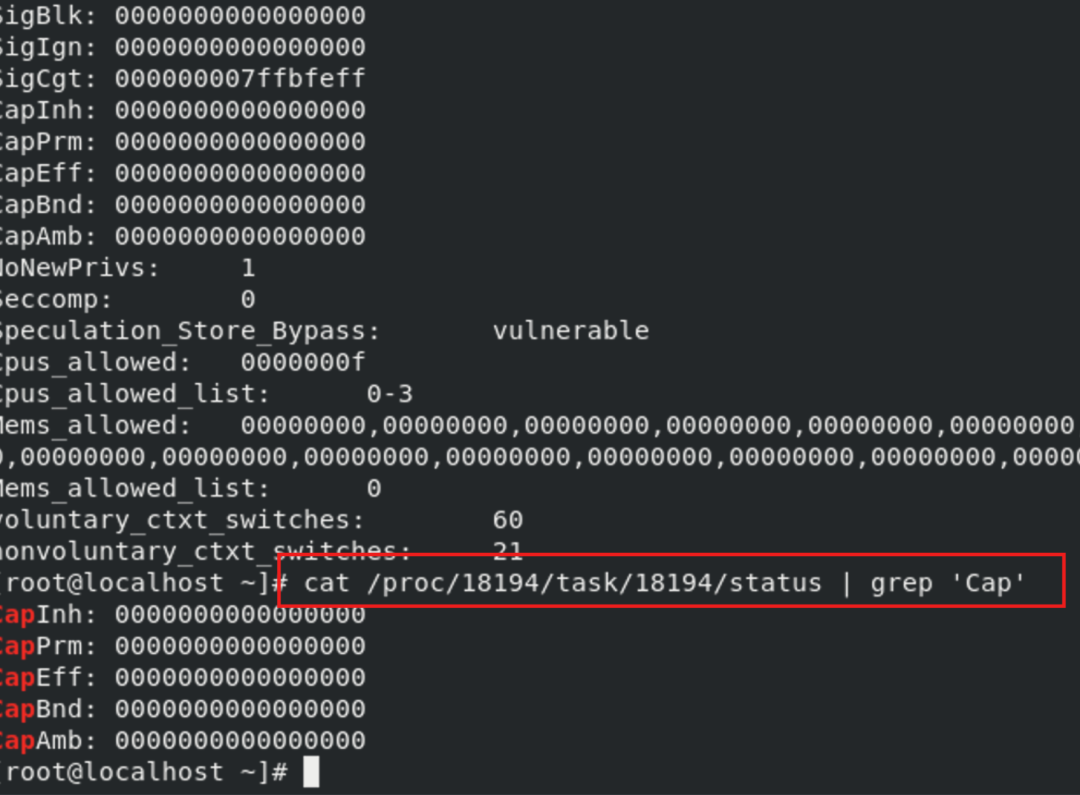
得到一堆數值沒辦法知其意,可以使用capsh進行轉換。
capsh --decode=0000003fffffffff

上面查看的數值后轉換也并不方便,libcap提供了getcap和setcap兩個命令來分別查看和設置文件的capabilities,方便查看對應的capabilities:
getcap /bin/ping

即該文件的capabilities中,Permitted集合中包含了CAP_NEW_RAW,從而可以發送raw packet。這也就應找了避免權限濫用,ping程序只需要網絡相關的特權即可,所以這里有cap_net_raw即可普通用戶運行。
CAP_SYS_ADMIN
CVE-2022-0185中涉及使用到了CAP_SYS_ADMIN這個capabilities,它提供眾多命令的權限,mount、unmout、swapon等等。
而在docker或其他容器化環境提供的標準創建中一般不會有加上CAP_SYS_ADMIN這個功能,也就說如果要有CAP_SYS_ADMIN能力就必須在創建的時候有加CAP_SYS_ADMIN參數或者使用特權容器--privileged標志,而CAP_SYS_ADMIN可以通過unshare進行系統調用獲得這個能力,unshare系統調用會將進程分配至新的namespace,比如unshared -U會使用戶進入新的用戶命名空間,又因為Linux capability繼承的機制,新的namespace擁有全部的capabilities,也包含了CAP_SYS_ADMIN。
2.seccomp過濾器
Seccomp 全稱Secure computing mode,意為安全計算模式,自 2.6.12 版本以來一直是 Linux 內核的功能。它可以用來對進程的特權進行沙盒處理,從而限制了它可以從用戶空間向內核進行的調用。
只有當Docker在構建時使用了Seccomp,并且內核在配置時啟用了CONFIG_SECCOMP,這個功能才可用。可以用以下命令來檢查當前環境是否支持Seccomp:

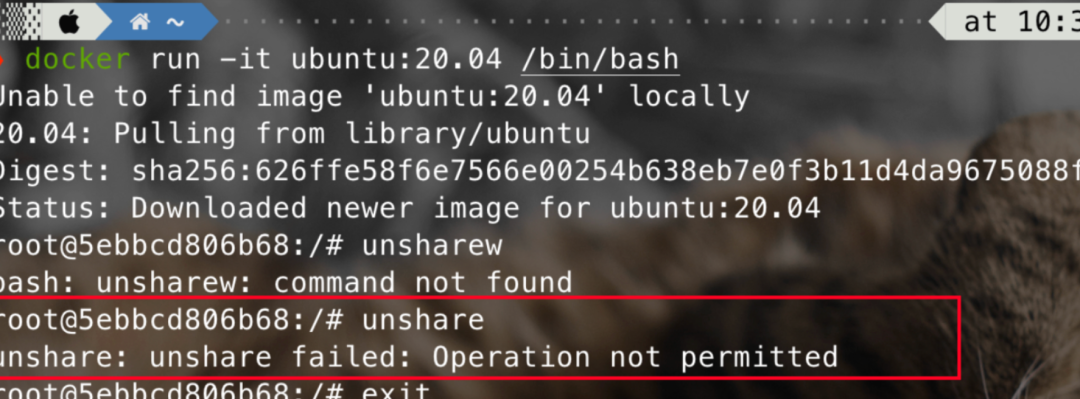
在CVE-2022-0185漏洞中非特權用戶可以使用unshare進入新的命名空間來利用漏洞,而unshare命令會被docker 的seccomp過濾器阻止,該過濾器會阻止該命令使用的系統調用。
這里隨便跑個docker看看,可以看到seccomp默認開啟,無法使用unshare:
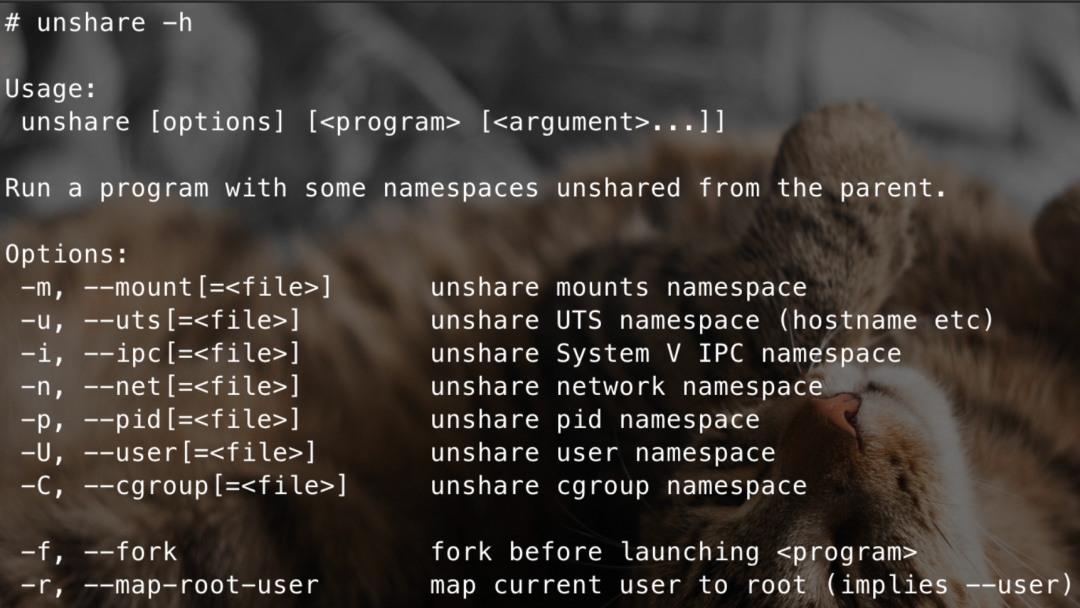
而在k8s集群中使用docker時,可以看到seccomp過濾器默認是被禁止的,可以使用unshare:
kubectl run -it yourname --image=ubuntu:20.04 /bin/bash
自1.22版本開始,Kubernetes引入了SeccompDefault特性來增強集群環境內的安全性。當該特性啟用時,kubelet將默認使用由容器運行時定義的RuntimeDefault Seccomp配置文件,限制集群環境內的系統調用。
但當處于低版本(1.22版本之前)的Kubernetes集群環境中,在默認配置情況下,非特權用戶可以在Pod內部順利執行unshare系統調用。
整理一下漏洞成因的流程就是:
低于1.22的k8s環境默認給pod非特權用戶執行unshare的系統調用-->拿到cap_sys_admin cap-->系統調用fsconfig處理文件系統上下文-->處理過程中代碼存在整數下限溢出,可以繞過檢查和越界寫入。
檢查內核是否受影響
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.kernelVersion}{""}{end}'
3.namespace
看容器逃逸的洞和手法時候總會看到namespace和cgroup兩個基礎概念,namespace實現了資源的隔離,而cgroup實現了控制。
Linux命名空間是操作系統內核級別的資源隔離方案,每個進程只能訪問自己所處命名空間的資源,因此每個容器才被做到被隔離的效果。拿docker運行來說,每當使用docker啟動容器時,Docker在后臺為容器創建了一組獨立的命令空間,它擁有自己的主機名、進程空間、用戶和網絡,這使得一個運行在容器中的進程幾乎看不到不到另一個容器或者宿主機中的進程。
最早的chroot命令大家都知道,通過修改根目錄把用戶隔離到一個特定目錄下,chroot提供了一種簡單的隔離模式,chroot內部的文件系統無法訪問外部的內容。linux命名空間在這個基礎上提供了對UTS、IPC、mount、PID、network、User等的隔離機制(https://lwn.net/Articles/531114/):
Mount: 隔離文件系統掛載點,類似 chroot,將一個進程放到一個特定的目錄執行。
UTS: 隔離主機名和域名信息,使其在網絡上可以被視作一個獨立的節點而非 主機上的一個進程。
IPC: 隔離進程間通信,Linux 常見的進程間交互方法,包括信號量、消息隊列和共享內存等。
PID: 隔離進程的ID,不同用戶的進程就是通過 pid 命名空間隔離開的,且不同命名空間中可以有相同 pid。
Network: 隔離網絡資源。網絡隔離是通過 net 命名空間實現的,每個 net 命名空間有獨立的 網絡設備,IP 地址,路由表,/proc/net 目錄。這樣每個容器的網絡就能隔離開來。(Docker 默認采用 veth 的方式,將容器中的虛擬網卡同 host 上的一 個Docker 網橋 docker0 連接在一起)
User: 隔離用戶和用戶組的ID,每個容器可以有不同的用戶和組 id, 也就是說可以在容器內用容器內部的用戶執行程序而非主機上的用戶。
通過ls -l /proc/$pid/ns | awk '{print $1, $9, $10, $11}'可以看到對應進程所屬的命名空間
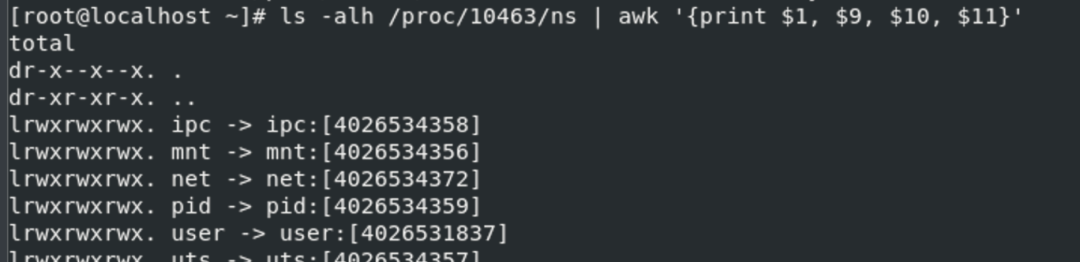
namespace 有三個系統調用可以使用:clone,unshare,setns
- clone() --- 實現線程的系統調用,用來創建一個新的進程,并可以通過設計上述參數達到隔離。
- unshare() --- 使某個進程脫離某個 namespace
- setns(int fd, int nstype) --- 把某進程加入到某個 namespace
0x02 CVE-2022-0185漏洞成因
漏洞前提條件是需要CAP_SYS_ADMIN是因為漏洞發生的系統調用是fsconfig ,其中的 FSCONFIG_SET_STRING 操作選項會對已經打開的文件系統上下文進行一些配置,配置過程中的代碼產生的漏洞。
fsconfig系統調用:
linux-5.11\fs\fsopen.c
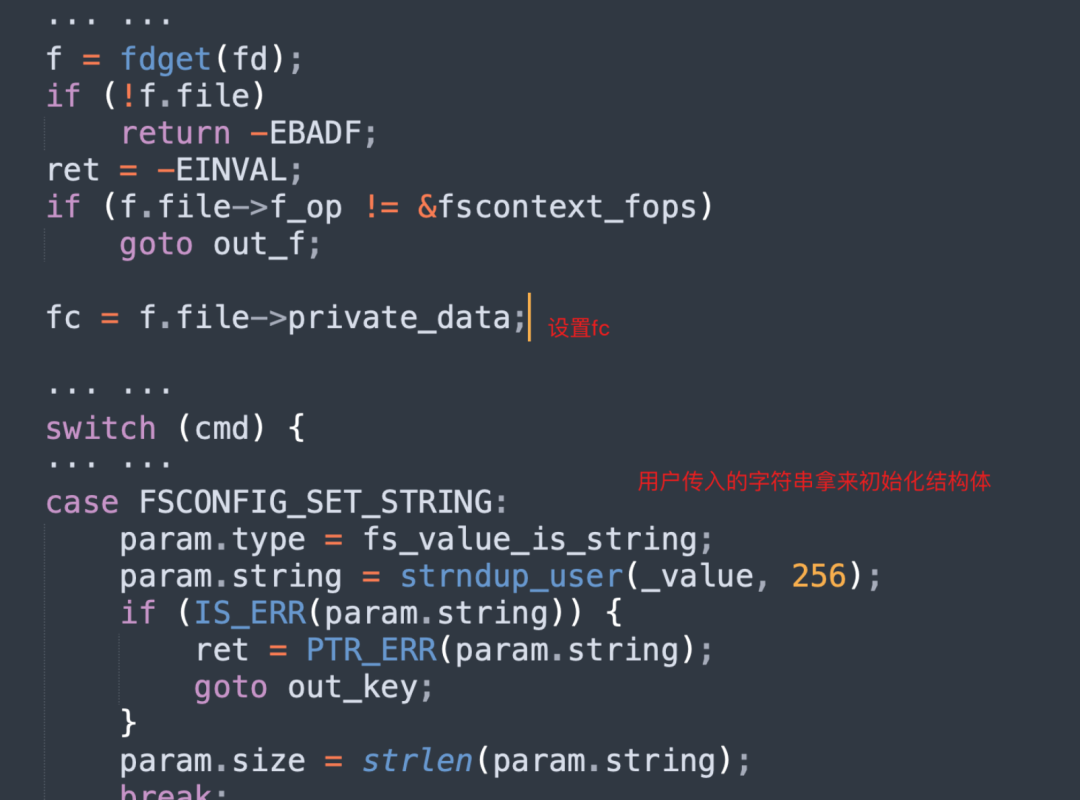
fsconfig系統調用入口中先根據文件描述符fd 初始化文件系統上下文結構體fc,然后根據用戶傳入的參數設置param結構體,進入vfs_fsconfig_locked函數:
linux-5.11\fs\fsopen.c:
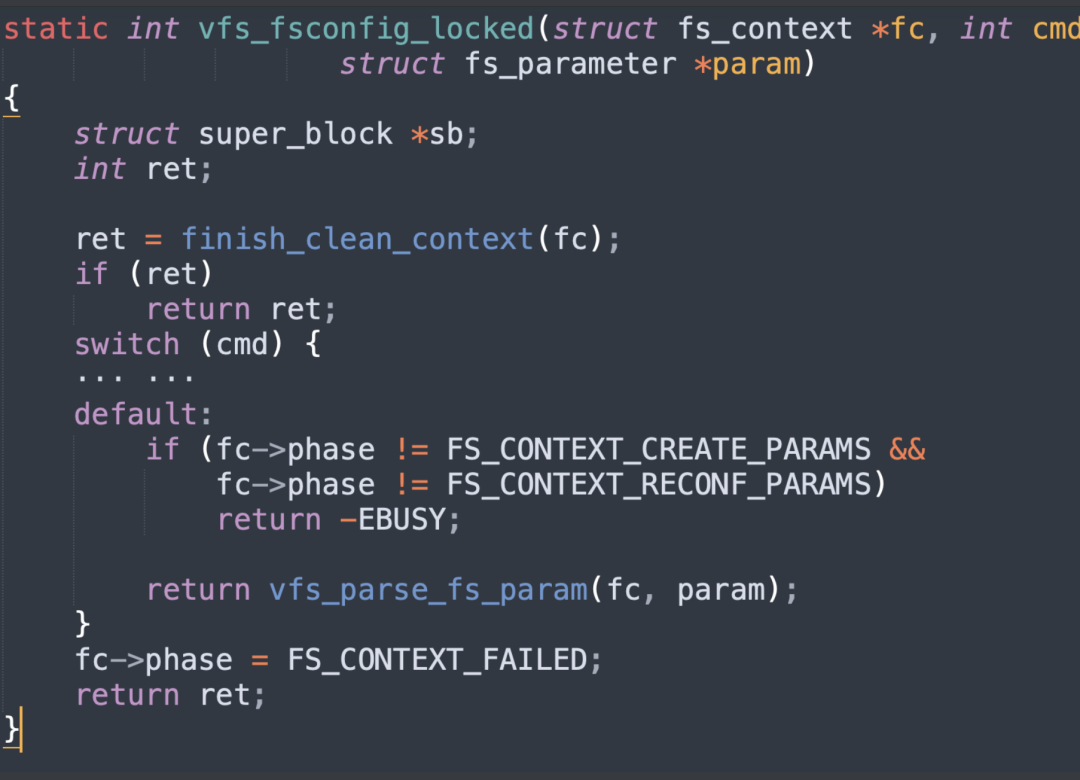
在上圖中finish_clean_context函數會調用legacy_init_fs_context 函數來注冊回調函數表,該回調函數表中就包括legacy_parse_param`函數,漏洞點就在這個函數。
legacy_parse_param函數所在的漏洞文件為處理文件系統上下文函數的fs_context.c,文件系統上下文的作用是創建superblock用于掛載和重新掛載文件系統,superblock是文件系統最基本的元數據,記錄了一個文件系統的特征,比如塊和文件大小,以及任何內存塊。
https://elixir.bootlin.com/linux/v5.14.21/source/fs/fs_context.c#L525
漏洞函數為legacy_parse_param:
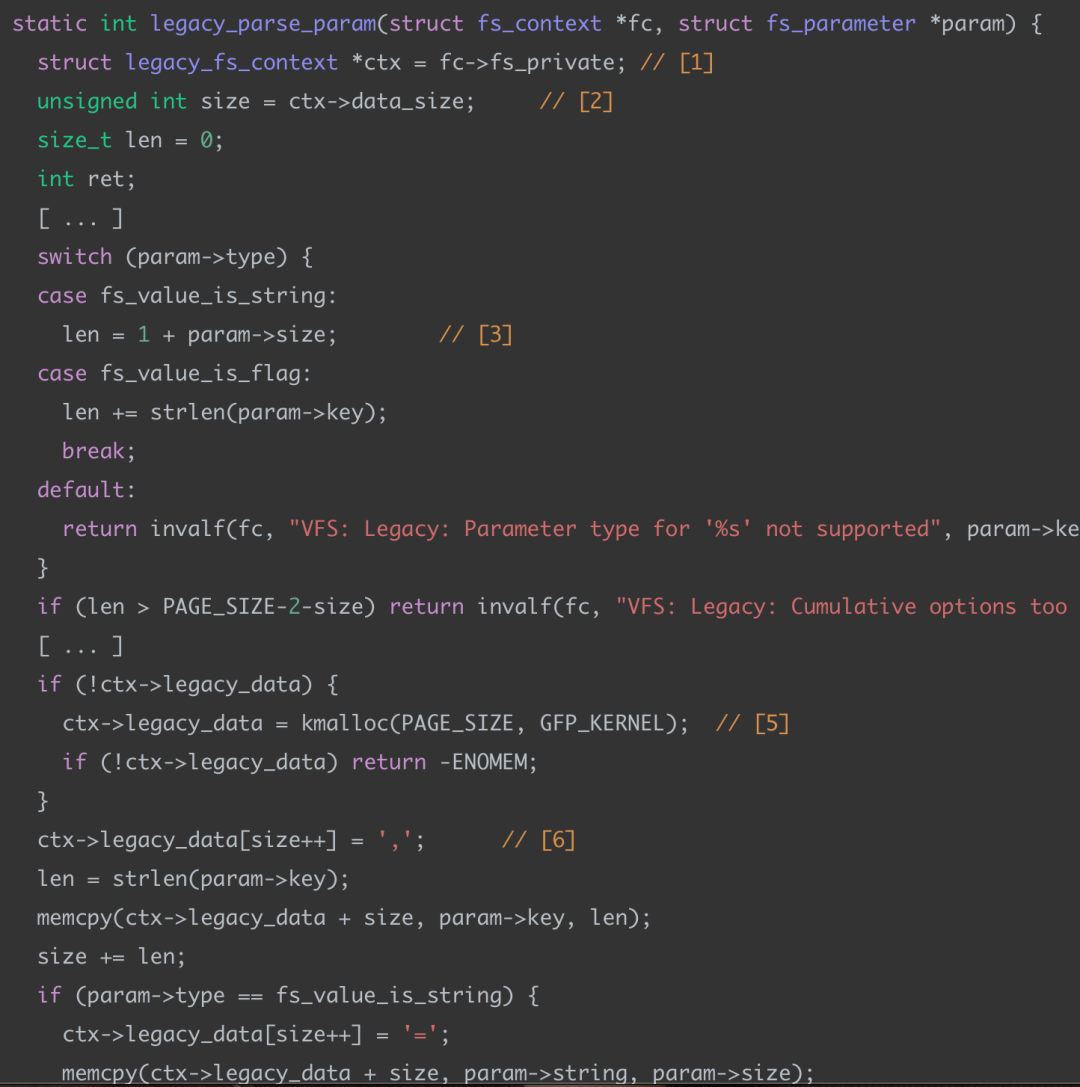
如上代碼不需要看懂作用,只需關注漏洞的代碼處:

如上這里存在一個長度檢查,如果len大于PAGE_SIZE – 2 – size的值,會直接return。
明顯這里有問題,判斷的類型是size_t,也就是unsigned int,PAGE_SIZE是4096,當size大小為4095或更大時, 無符號減法PAGE_SIZE – 2 – size的計算結果將是一個巨大的正值,發生整數溢出反轉,也就是該正值大于len,所以檢查將不會觸發。
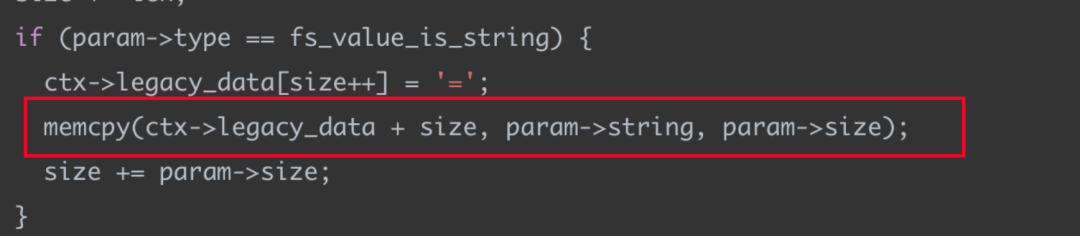
判斷輸入長度通過后,這里memcpy會將param->string拷貝到ctx->legacy_data的相關操作,如上,而這里拷貝的size是大于PAGE_SIZE - 2的,所以造成拷貝的越界。
調用過程:
fsconfig系統調用入口-->vfs_fsconfig_locked-->finish_clean_context-->legacy_init_fs_context注冊回調-->vfs_parse_fs_param-->legacy_parse_param
links
https://www.willsroot.io/2021/08/corctf-2021-fire-of-salvation-writeup.html
http://blog.nsfocus.net/linux-cve-2022-0185/
https://syst3mfailure.io/wall-of-perdition
https://jfrog.com/blog/the-impact-of-cve-2022-0185-linux-kernel-vulnerability-on-popular-kubernetes-engines/
