基于Hadoop生態圈的數據分析平臺設計
自貴州省實施大數據戰略以來,全省社會經濟高速發展,通過支付系統貴陽城市處理中心處理的跨行資金交易呈快速增長態勢,如何從海量真實交易數據中提取和分析有效信息,對支付系統貴陽城市處理中心提升工作效率、為貴州省人民銀行系統及地方政府提供管理決策依據等方面都具有重要意義。
支付系統貴陽城市處理中心現有數據統計分析系統僅提供了跨行資金交易數據的基礎查詢和初步統計功能,對于全省全年全系統或全省半年全系統或某地區特殊固定時段全系統的數據則需要進行二次人工統計,不僅耗時且容易出錯,而對于領導關心的行業資金流入流出、企業資金流入流出、不同時段下資金流動監測預警、各地區經濟發展動向等情況則完全無法實現。在全行要求過“緊日子”的背景條件下,為有效解決當前工作存在的問題,高效快速完成對海量跨行交易數據的統計查詢,支撐更具深度的數據挖掘分析,實現直觀的數據可視化展示,建設一套低成本、高效率的央行支付系統區域數據分析平臺迫在眉睫。
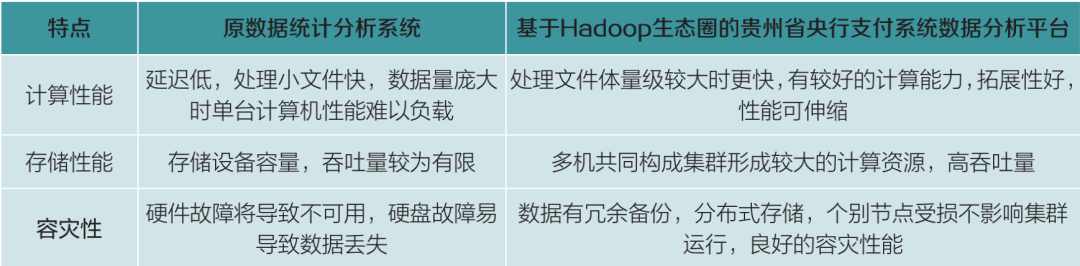
本文旨在通過利用支付系統貴陽城市處理中心已有的PC機及網絡設備作為硬件基礎,結合Hadoop、Hive、HBase、Spark等開源產品,對貴州省央行支付系統數據分析平臺進行實踐分析。該平臺設計方案與原數據統計分析系統基于單機處理的設計方案對比情況如表1所示。
表 1 原數據統計分析系統與基于Hadoop的
貴州省央行支付系統數據分析平臺對比
功能分析
貴州省央行支付系統數據分析平臺應實現對全省跨行資金交易的數據處理、查詢統計、風險預警、多維分析、報告輸出和系統管理等功能,其中,數據處理包括數據采集、數據清洗、數據加密等;查詢統計即對原數據統計分析系統的數據統計、業務量查詢、流量流向統計、精確交易查詢等功能進行完善和優化;風險預警即對交易金額、交易筆數、可疑交易等進行預警;多維分析即實現基于業務需求拖拉拽可視化組件進行自助分析,可靈活配置相關指標字段、過濾條件、結果展示等選項,實現對貴州省內各行業資金流動情況、各地區經濟發展動向等內容的動態分析;報告輸出即根據相關報告模板,結合預設指標參數、算法等,自動填充對應內容,生成圖文表并茂的分析報告;系統管理則實現用戶管理、資源管理、權限管理、日志管理等系統后臺管理功能。
平臺設計
1.平臺架構設計。平臺架構設計除數據源外,平臺按照數據采集層、存儲層、應用層、業務層、數據展示層共5個模塊進行劃分。數據采集層主要負責對原始數據的采集和清洗,經過預處理后的數據流向存儲層;存儲層負責根據業務功能需求和性能考量,提供相匹配的數據存儲方式,為業務層和應用層服務;業務層主要負責實現業務處理相關事務,封裝業務層面上的算法邏輯,供應用層引入調用;應用層負責與用戶交互,根據用戶指令對接業務層處理邏輯,調度計算任務,管理各項資源以及調整系統設定;數據展示層負責將處理完畢的數據結果以圖表、表格、導出文件等形式反饋至用戶。
2.平臺搭建。集群復用支付系統貴陽城市處理中心現有9臺運維終端,平均每個計算節點分配硬件資源為12核心CPU、28G內存、1TBSSD硬盤,集群部署于支付系統專網運維區,便于系統自動采集更新屬地數據,用戶通過其他運維終端對集群進行管理。
各計算節點基于Linux部署Hadoop-3.3.0集群,其中1個Master節點、8個Worker節點,通過Zookeeper實現高可用,在Hadoop NameNode上部署Hive數據倉庫供數據管理,集群上搭建HBase供快速響應查詢,部署Spark提供流式數據處理能力,并彌補Hadoop在執行MR任務耗時較長的短板,集成Superset作為BI工具對數據進行抽取整合,提供展示圖表等。
3.原始數據。該平臺的數據來源主要分為屬地數據和外部數據,其中,屬地數據為CSV格式,包含所有流入流出貴州省大小額支付系統、網銀支付系統和外幣支付系統的支付交易數據,平均每日約80萬行1GB的數據量,涵蓋每筆交易的交易時間、業務類型、發起行行號、接收行行號、收款人賬戶及姓名、付款人賬戶及姓名、交易金額、軋差情況、清算情況、業務處理狀態、回執信息等近38個字段。輔助數據則主要來源于公開數據及相關合作渠道,目前可使用的有銀行行名行號數據、地理區域結構數據、企業注冊數據、行業分類數據、企業信用數據、基金股票統計數據等。
4.數據采集層。為實現每日獲取的屬地數據為最新數據,可通過Crontab調用Shell腳本實現,設定每間隔6小時檢測一次最新數據并完成下載,使用Python腳本對下載后數據進行安全性及完整性檢查,由于CSV格式屬于結構化數據,入庫前的數據清洗工作主要針對個人賬號姓名等敏感信息進行脫敏處理。原始屬地數據則加密壓縮后存放于HDFS中,以備特殊情況下的調取使用。由于部分數據挖掘功能需要引入外部數據,如各行業資金流動分析功能依賴于企業工商等信息數據,流量流向則依賴于行號地址映射關系數據,此類數據由于網絡隔離的原因無法實時拉取,由人工定期導入更新,在經過清洗消歧后,屬地數據與外部數據關聯聚合后流向存儲層。
5.存儲層。原始數據在經過加密壓縮后通過Hadoop的HDFS文件系統存儲,設置副本冗余策略為3個。部署Hive作為數據倉庫存放CSV格式數據,便于后續通過HQL語句轉化MR任務對數據進行抽取,創建滿足不同業務需要的數據集。部署HBase存放需要快速響應的數據,存放時考慮查詢可行性、性能等問題,分別針對不同查詢場景設計RowKey和列簇,形成多個表格,確保數據查詢簡單可行,避免查詢掃描時負載過度集中在個別RegionServer帶來性能I/O瓶頸、數據過度分散等問題,進而導致連續數據查詢效率低下等問題。
6.應用層。應用層前端Web界面采用Layui編寫,供業務操作人員使用與后端通訊,后端部分主要通過Flask框架開發,集成HDFS、PyHive、HappyBase、PySpark等Python庫以實現常用功能,搭配調用LinuxShell自動化腳本實現對宿主主機監測以及系統級管理。預留自定義功能接口,以便Shell腳本、Python腳本、Mapreduce Jar包等上傳,供系統調用實現特定功能。
7.業務層。業務層作為核心組件,需要開發人員根據特定需求對業務系統和數據有較深的理解,面對各式各樣的應用場景,采用的算法模型可能各有不同,所以業務層應集成常見算法,且對各算法的參數閾值應設置為可調整。以ID3決策樹算法為例,可應用于判斷金融機構在不同地段部署網點的合理性,通過支付系統跨行交易數據結合行號地址映射關系數據能夠提取出金額、頻率、城區中心化程度等信息,再通過本地調研選取公認分配合理的網點作為訓練樣本,發現累計交易金額大、頻度高、所在位置等屬性特征,建立模型,可以找出相對設置不夠合理的網點,供金融機構參考判斷是否需要調整策略、加以優化。
8.數據展示層。平臺對數據分析完畢后,采用基于WebUI的直觀圖形圖表將處理后的數據進行展示。該部分功能主要選用開源免費的BI工具Superset實現,該工具通過連接Hive數據庫讀取數據倉庫中的交易數據,連接Mysql數據庫讀取交易統計數據、外部導入的企業工商、行號地址映射關系數據,而Superset原生集成Echarts圖表庫,可方便靈活根據業務需求創建數據集、可視化圖表。
9.數據安全性保護。該平臺所部署的集群位于支付系統貴陽城市處理中心內部專有網段,與外部網絡物理隔絕,可有效防止外部網絡攻擊。數據采集后在進行數據清洗時,要根據相關管理制度對數據中部分字段進行脫敏屏蔽,對于敏感隱私信息進行Hash處理,實現如收付款人姓名等隱私信息僅可在得到準確信息的情況下才可以展示,普通操作人員無法直接瀏覽。而原始數據均經過加密壓縮后再進行存儲,在確保數據分析準確性的同時又能保證敏感信息不被泄露。
下一步工作方向
基于Hadoop生態圈的貴州省央行支付系統數據分析平臺設計,在有限成本預算的情況下,能夠有效提高分析速度,充分利用好屬地數據,解決當前工作中的遇到的一些難題,相較傳統單機處理分析的技術實現方法,更適應當今復雜多變的應用需求,高可用性和數據冗余存儲的設計更是提高了整個系統的可用性,但與之相對的則是需要額外增加對整個集群的維護管理,對運維工作帶來一定的負擔。
下一步工作方向:一是結合對數據關聯關系的挖掘需求,引入更多算法,探究在不同金融研究領域下的更多應用;二是使用Docker技術建立私有鏡像,提高部署效率,防止節點老化損壞后,給運維工作恢復時帶來的繁重配置工作,降低集群維護難度,提高災后重建能力。
