數據質量監控平臺與框架
導讀
隨著業務發展和數據量的增加,大數據應用開發已成為部門應用開發常用的開發方式,由于部門業務特點的關系,spark和hive應用開發在部門內部較為常見。當處理的數據量達到一定量級和系統的復雜度上升時,數據的唯一性、完整性、一致性等等校驗就開始受到關注,而通常做法是根據業務特點,額外開發job如報表或者檢查任務,這樣會比較費時費力。
目前遇到的表大部分在幾億到幾十億的數據量之間,并且報表數量在不斷增加,在這種情況下,一個可配置、可視化、可監控的數據質量工具就顯得尤為重要了。以下介紹幾個國內外主流的技術解決方案及框架。
一.Apache Griffin(Ebay開源數據質量監控平臺)
Griffin起源于eBay中國,并于2016年12月進入Apache孵化器,Apache軟件基金會2018年12月12日正式宣布Apache Griffin畢業成為Apache頂級項目。
數據質量模塊是大數據平臺中必不可少的一個功能組件,Apache Griffin(以下簡稱Griffin)是一個開源的大數據數據質量解決方案,它支持批處理和流模式兩種數據質量檢測方式,可以從不同維度(比如離線任務執行完畢后檢查源端和目標端的數據數量是否一致、源表的數據空值數量等)度量數據資產,從而提升數據的準確度、可信度。對于batch數據,我們可以通過數據連接器從Hadoop平臺收集數據。對于streaming數據,我們可以連接到諸如Kafka之類的消息系統來做近似實時數據分析。在拿到數據之后,模型引擎將在spark集群中計算數據質量。
1.1 工作流程
在Griffin的架構中,主要分為Define、Measure和Analyze三個部分:
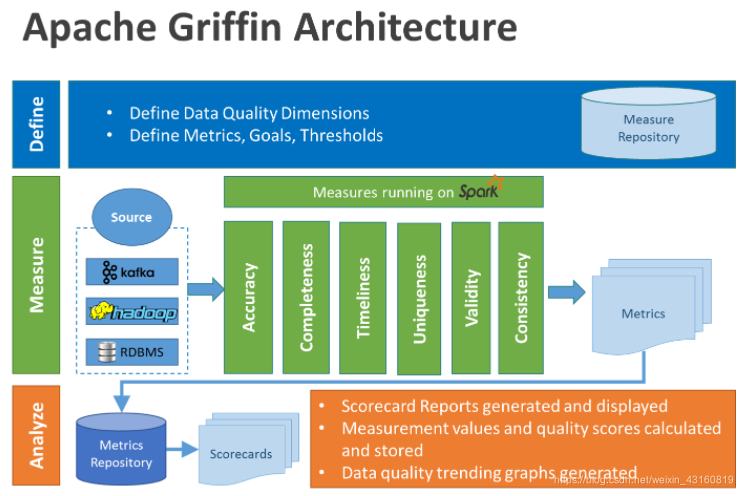
各部分的職責如下:
- Define:主要負責定義數據質量統計的維度,比如數據質量統計的時間跨度、統計的目標(源端和目標端的數據數量是否一致,數據源里某一字段的非空的數量、不重復值的數量、最大值、最小值、top5的值數量等)
- Measure:主要負責執行統計任務,生成統計結果
- Analyze:主要負責保存與展示統計結果
基于以上功能,我們大數據平臺計劃引入Griffin作為數據質量解決方案,實現數據一致性檢查、空值統計等功能。
1.2 特點
- 度量:精確度、完整性、及時性、唯一性、有效性、一致性。
- 異常監測:利用預先設定的規則,檢測出不符合預期的數據,提供不符合規則數據的下載。
- 異常告警:通過郵件或門戶報告數據質量問題。
- 可視化監測:利用控制面板來展現數據質量的狀態。
- 實時性:可以實時進行數據質量檢測,能夠及時發現問題。
- 可擴展性:可用于多個數據系統倉庫的數據校驗。
- 可伸縮性:工作在大數據量的環境中,目前運行的數據量約1.2PB(eBay環境)。
- 自助服務:Griffin提供了一個簡潔易用的用戶界面,可以管理數據資產和數據質量規則;同時用戶可以通過控制面板查看數據質量結果和自定義顯示內容。
1.3 數據質量模型
Apache Griffin 是一個模型驅動的解決方案,用戶可以根據選定的目標數據集或源數據集(作為黃金參考數據)選擇各種數據質量維度來執行他們的數據質量驗證。它在后端有相應的庫支持,用于以下測量:
- 精確度:度量數據是否與指定的目標值匹配,如金額的校驗,校驗成功的記錄與總 記錄數的比值。
- 完整性:度量數據是否缺失,包括記錄數缺失、字段缺失,屬性缺失。
- 及時性:度量數據達到指定目標的時效性。
- 唯一性:度量數據記錄是否重復,屬性是否重復;常見度量為hive表主鍵值是否重復。
- 有效性:度量數據是否符合約定的類型、格式和數據范圍等規則。
- 一致性:度量數據是否符合業務邏輯,針對記錄間的邏輯的校驗,如:pv一定是大于uv的,訂單金額加上各種優惠之后的價格一定是大于等于0的。
1.4 官方及參考資料
- Apache Griffin的github項目鏈接 https://github.com/apache/griffin
- Apache Griffin 官方網站 https://griffin.apache.org/
二. Deequ(Amazon開源數據質量監控平臺)
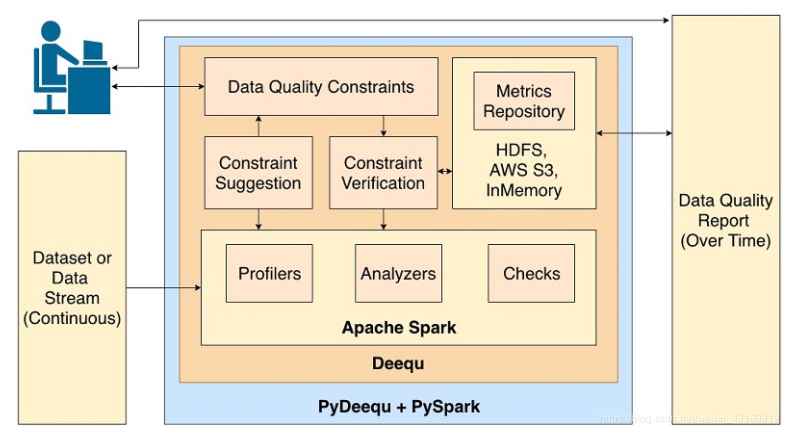
Deequ 是亞馬遜開源的一個構建在 Apache Spark 之上的庫,用于定義“數據單元測試”,用于測量大型數據集中的數據質量。同時它還提供了python接口PyDeequ, PyPi, Documents。PyDeequ,這是一個基于 Deequ(一種在亞馬遜開發和使用的開源工具)之上的開源 Python 包裝器。Deequ 是用 Scala 編寫的,而 PyDeequ 可以使用 Python 和 PySpark(許多數據科學家選擇的語言)的數據質量和測試功能。PyDeequ 能與許多數據科學庫一起使用,使 Deequ 擴展其功能。此外,PyDeequ 可以與 Pandas DataFrames 進行流暢的接口,而不是在 Apache Spark DataFrames 內進行限制。
Deequ 可以計算數據質量指標,定義和驗證數據質量約束,并了解數據分布的變化。使開發人員專注于描述數據的外觀,而不是自己實施檢查和驗證算法。Deequ 通過checks提供支持。Deequ 基于 Apache Spark 之上實現,旨在擴展通常位于數據湖、分布式文件系統或數據倉庫中的大型數據集(數十億行)。PyDeequ 可以訪問以上功能,也可在 Python Jupyte notebook環境中使用它。
2.1 特點
- 指標計算——Deequ 計算數據質量指標,即完整性、最大值或相關性等統計數據。Deequ 使用 Spark 從 Amazon Simple Storage Service (Amazon S3) 等來源讀取數據,并通過一組優化的聚合查詢計算指標。可直接訪問根據數據計算的原始指標。
- 約束驗證——用戶可專注于定義一組要驗證的數據質量約束。Deequ 負責導出要對數據進行計算的所需指標集。Deequ 生成數據質量報告,其中包含約束驗證的結果。
- 約束建議 - 用戶可選擇定義自己的自定義數據質量約束,或使用自動約束建議方法來分析數據以推斷有用的約束。
- Python 包裝器——可使用 Python 語法調用每個 Deequ 函數。包裝器將命令轉換為底層 Deequ 調用并返回它們的響應。
2.2 架構
三. DataWorks(阿里巴巴數據質量監控平臺)
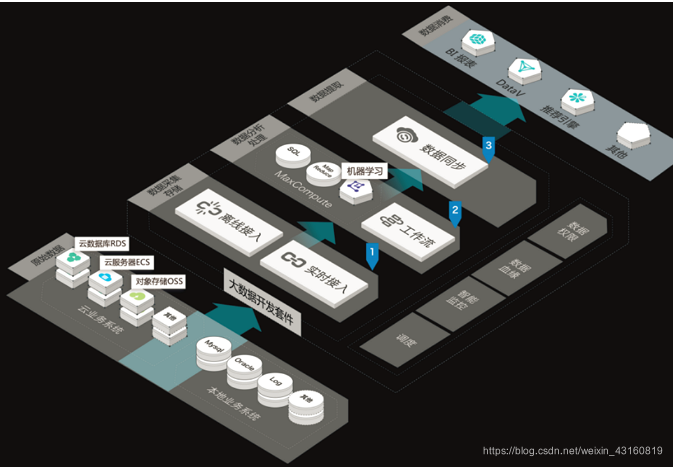
DataWorks(數據工場,原大數據開發套件)是阿里云重要的PaaS(Platform-as-a-Service)平臺產品,可提供數據集成、數據開發、數據地圖、數據質量和數據服務等全方位的產品服務,一站式開發管理的界面,幫助企業專注于數據價值的挖掘和探索。
DataWorks支持多種計算和存儲引擎服務,包括離線計算MaxCompute、開源大數據引擎E-MapReduce、實時計算(基于Flink)、機器學習PAI、圖計算服務Graph Compute和交互式分析服務等,并且支持用戶自定義接入計算和存儲服務。DataWorks可提供全鏈路智能大數據及AI開發和治理服務。
DataWorks,可對數據進行傳輸、轉換和集成等操作,從不同的數據存儲引入數據,并進行轉化和開發,最后將處理好的數據同步至其它數據系統。
3.1 架構
3.2 數據質量
數據質量是支持多種異構數據源的質量校驗、通知及管理服務的一站式平臺。
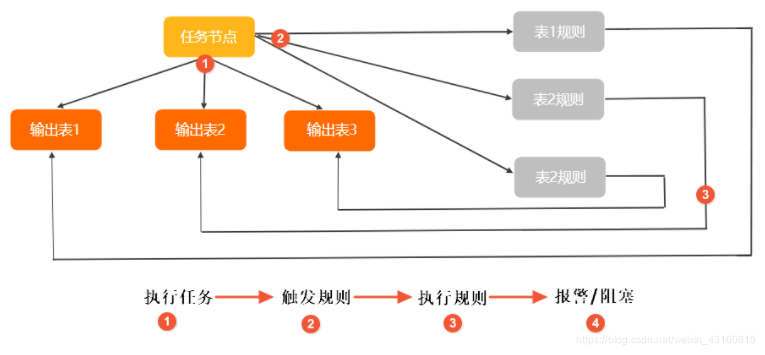
數據質量依托DataWorks平臺,提供全鏈路的數據質量方案,包括數據探查、對比、質量監控、SQL掃描和智能報警等功能。
數據質量監控可以全程監控數據加工流水線,根據質量規則及時發現問題,并通過報警通知負責人及時處理。
數據質量以數據集(DataSet)為監控對象。目前,數據質量支持EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute數據表和DataHub實時數據流的監控。當離線數據發生變化時,數據質量會對數據進行校驗,并阻塞生產鏈路,以避免問題數據污染擴散。同時,數據質量支持管理歷史校驗結果,用戶可對數據質量進行分析和定級。
在流式數據場景下,數據質量能夠基于DataHub數據通道進行監控和斷流,第一時間告警給訂閱用戶。數據質量支持設置橙色、紅色告警等級和告警頻次,最大限度地減少冗余報警。
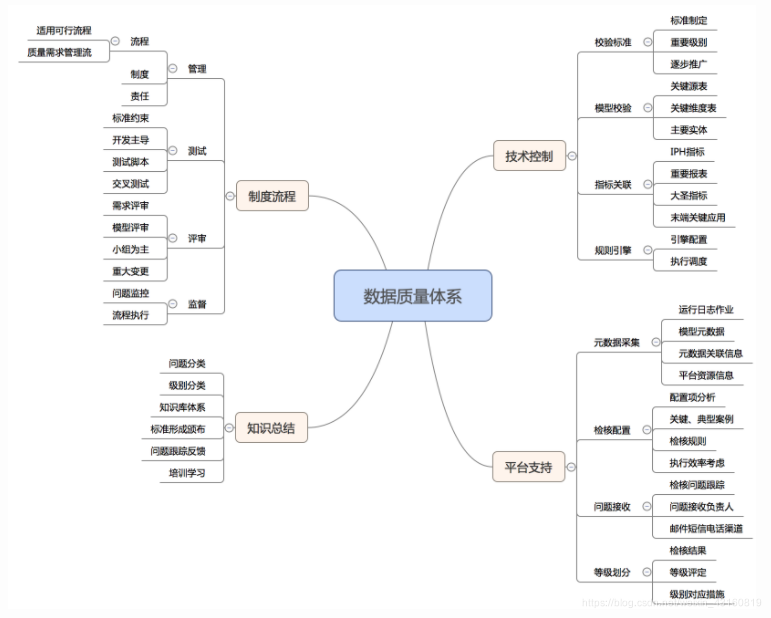
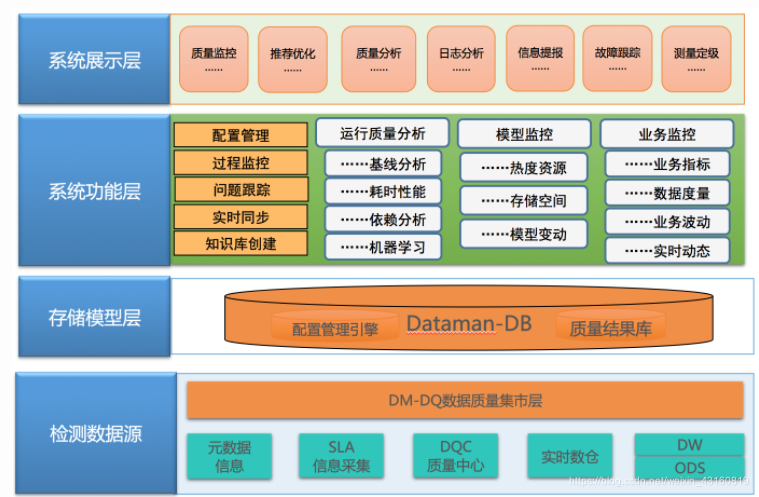
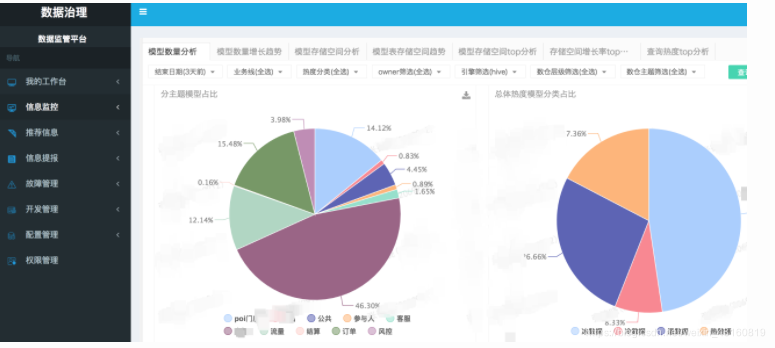
四. DataMan(美團點評數據質量監控平臺)
DataMan系統建設總體方案基于美團的大數據技術平臺。自底向上包括:檢測數據采集、質量集市處理層;質量規則引擎模型存儲層;系統功能層及系統應用展示層等。整個數據質量檢核點基于技術性、業務性檢測,形成完整的數據質量報告與問題跟蹤機制,創建質量知識庫,確保數據質量的完整性(Completeness)、正確性(Correctness)、當前性(Currency)、一致性(Consistency)。