深入研究 Yara 掃描性能
工作來源
Botconf 2023
工作背景
Yara 是非常流行的分析工具,因為其簡單易用性深受分析人員的喜愛。簡單的例子如下所示,包含元數據、字符串與匹配條件。該規則匹配非字母數字字符分割的文本字符串或者在起始位置匹配正則表達式或者十六進制字符串。

最常見的用例就是使用 Yara 來檢測特定的惡意軟件家族,但創建此類規則非常復雜。Yara 本身存在多種方法來檢測潛在的慢速掃描,告警如下所示:

這些告警基于啟發式方法來評估規則質量,但并沒有給出提高性能的建議。更糟糕的是,存在告警的規則是不允許在 VirusTotal Hunting 中使用的。
匹配的過程一共四個步驟:字符串原子化、Aho-Corasick 自動機、字節碼引擎與條件評估。
字符串原子化
原子是長度從零到四個字節的子串,Yara 提供了多種啟發式方法選擇獨一無二的、最有效的原子。例如 Yara 會從正則表達式 /abcd[x-z]/ 中選擇字符串 abcd。
Aho-Corasick 自動機
基于所有的原子構建 Aho-Corasick 自動機前綴樹:

字節碼引擎
字節碼引擎獲取潛在匹配列表,根據字符串的完整定義(包括各種修飾符)驗證哪些是匹配命中。
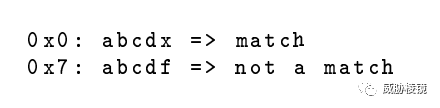
條件評估
條件評估是在字符串匹配后進行的,例如文件大小的限制仍然會在字符串匹配之后進行。值得注意的是短路評估,可以通過改變條件的順序來提高匹配性能。
工作準備
使用 4.2.3 版本的 Yara,主機運行在 CentOS 系統上且使用 AMD EPYC 7502 32 核處理器。
使用數據集:
- 一共 8.2GB,包含 31220 個良性文件與惡意樣本的數據集(https://figshare.com/authors/Eduardo_de_O_Andrade/4923649)
- 一共 14GB 的樣本文件(Avast-CTU Public CAPE
- Dataset)
- 正則性能測試(https://github.com/rust-leipzig/regex-performance)
工作評估
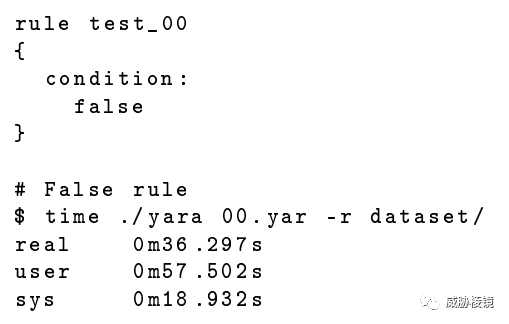
一共 22GB 左右的樣本文件,最簡單的規則掃描需要 36 秒:
字符串 vs 條件

優化后的規則如下所示,這是小端序匹配,而大端序可以使用 intXYbe() 或者 uintXYbe()。

不再掃描整個文件,而是掃描指定的位置。并且,文件大小還需要滿足條件限制。

提升性能大約 10%,在大規模數據集中差異會很明顯。
不一定存在
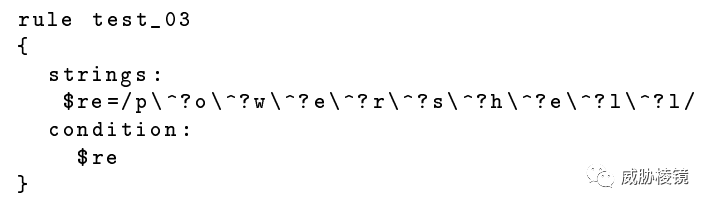
優化后的規則如下所示:

創建兩個字符串,一個是在前兩個字符之間插入符號,另一個沒有。這會讓 Yara 選擇子字符串 p^o 與 po 作為原子。這相比只使用一個字符 p,效率會更高。

性能提升大約 14%,優化后的規則使 Yara 在匹配過程中進行更多優化。
交替字符串

優化后規則如下所示。盡管連接起來的字符串更長,但 Yara 不會主動連接。所以要匹配很短的字符串,尤其是互相交叉的字符串,盡量不要合并在一起。

提供的信息越多,Yara 選擇的原子越長,掃描也就越快。

性能提升大約 19%。
范圍太大

優化后的規則如下所示。如果使用太多通配符,則會提示字符串過于籠統,建議縮小范圍。

盡量避免使用通配符,否則性能會極劇下降。

性能提升大約 40%。
IPv6 地址

優化后的規則如下所示。

只匹配了以 2001 為前綴的全球單播地址,并且限制了十六進制符號的范圍。

性能提升大約 50%,且沒有誤報。
工作思考
Yara 應該是屬于是入門容易精通難的那一類技術了,使用不當的情況下在大數據集下會為系統帶來極大的性能負擔。VirusTotal 等頭部玩家都不想純靠機器的性能硬抗,也在版本迭代中積極地優化 Yara 匹配的效率。研究人員也應該進一步學習,寫出更“好”的規則來更高效地進行威脅狩獵。
