一種基于網絡流量風險數據聚類的APT攻擊溯源方法
高級持續性威脅(Advanced Persistent Threat,APT)攻擊是指攻擊者使用多種先進手段,對特定目標展開的持續的、高威脅性的網絡攻擊活動,它有3個重要特征:(1)攻擊能力強,這體現了APT中的A(既先進性)這一方面;(2)持續時間長,這體現了APT中的P(即持續性)這一方面;(3)目標特定,危害程度大,這體現了APT中T(即威脅性)這一方面。這種攻擊活動的發起者往往具有較強的政治背景,攻擊活動具有極強的隱蔽性和針對性,而攻擊活動的受害者也往往要承受巨大的損失。
根據奇安信發布的《全球高級持續性威脅(APT)2021年度報告》披露的數據,2021年度全球APT攻擊的主要目標包括政府、醫療、科技、國防、制造、運輸、教育、航空、通信、能源等社會生活的方方面面。攻擊手段也有從傳統的魚叉攻擊向大量利用0day漏洞發展的趨勢。此外,針對基礎設施及供應鏈攻擊的事件愈發泛濫,甚至有越來越多的針對網絡安全產品的攻擊活動,APT攻擊的發生頻率和威脅程度呈持續擴大的態勢。
APT攻擊不僅危害性大,而且隱蔽性強。2022年2月23日,奇安盤古實驗室發布報告,發現隸屬于美國國安局的“方程式”組織利用頂級后門,對中國等45個國家開展了長達十幾年的名為“電幕行動”的網絡攻擊,攻擊目標所屬的行業涵蓋了電信、大學、科研、經濟、軍事等。
我國是APT攻擊的最大受害國之一。長期以來,“海蓮花”“蔓靈花”“虎木槿”“方程式”等APT組織對我國進行了持續性的網絡攻擊,使相關領域遭受了極大的損失。而且,針對政府、國防、能源、金融等重點行業的攻擊頻率在最近幾年都有100%以上的漲幅,個別行業甚至有200%以上的漲幅。
APT攻擊的溯源一直都是網絡空間攻防中極為重要的一環。做好溯源工作不僅能使相關部門掌握APT攻擊的活動規律,做好應對與防范,有效減少損失,還能使我國在面對敵對勢力在網絡安全問題上的輿論攻擊的時候,拿出確鑿的證據進行有力的反駁,有效維護國家尊嚴。
1
傳統的 APT 攻擊溯源方法
1.1 基于日志記錄的溯源
在常見的網絡攻擊活動中,典型的攻擊過程如圖1所示。攻擊者通過多個中間節點(路由器),連接到受害者的主機,或者把攻擊載荷投送到受害者的主機上。在這個過程中,攻擊者到受害者之間的每個節點都會留下日志記錄。攻擊發生后,追蹤者根據掌握到的攻擊數據包特征,與獲取到的各個路由節點的日志記錄進行匹配,如果匹配成功,則可斷定攻擊的數據流經過這一節點。如此一級一級地追蹤,直至發現真正的攻擊者。

這種溯源的方法可以看作對攻擊過程的一種逆向追蹤,但使用這種方法進行溯源具有如下困難:
(1)需要獲取并存儲大量中間路由節點的日志數據,而這往往需要使用行政手段得到網絡運營商(Internet Service Provider,ISP)的支持,對于一般的企業或單位來說具有較大的難度。
(2)中間環節易中斷。跟蹤者往往無法獲取到境外運營商的路由節點日志數據,對于來自境外的網絡攻擊,追蹤鏈就會中斷。而一旦追蹤鏈中斷,往往會導致前期的追蹤工作前功盡棄。
(3)如今的網絡攻擊大量使用僵尸網絡,即使費盡周折找到了發起攻擊的IP,最終也往往是僵尸網絡,還是難以確定攻擊者的身份。
綜合以上原因,這種溯源的方式在面對有組織的APT攻擊的時候成功率會大大降低,而成本則會大大增加。
1.2 基于包標記技術的溯源
所謂的包標記是指在網絡節點(如路由器)中以特定的概率對通過的數據包進行標記,并將路徑信息標記在IP數據包的預留字段中。在受害者接收到數據包后,通過解析其中的標記信息,即可重構數據包的路徑。包標記過程如圖2所示。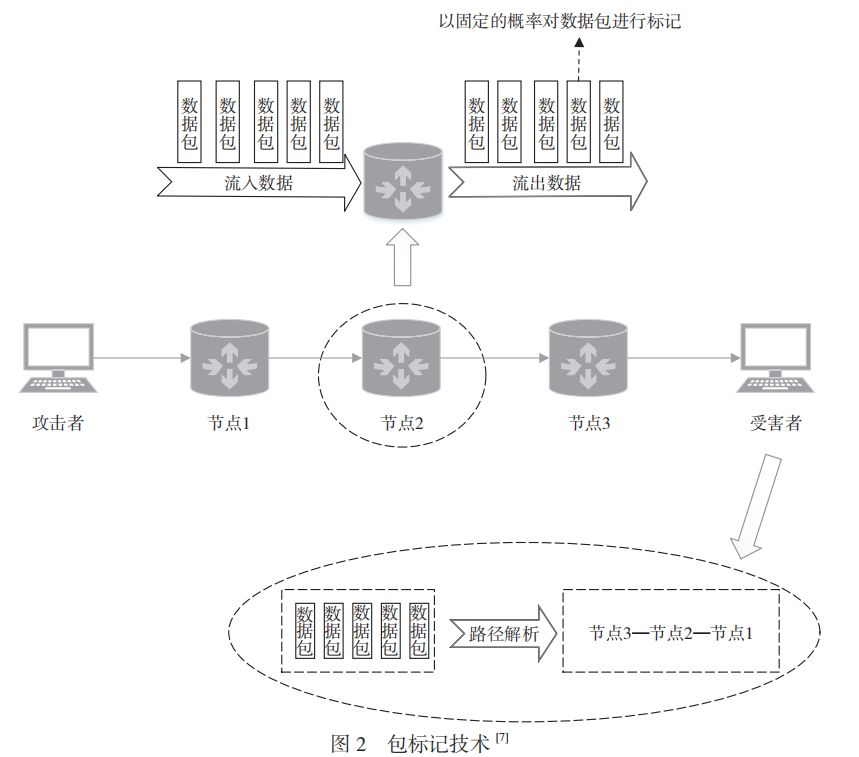
使用包標記技術進行溯源,無須再存儲海量的中間節點產生的日志數據,然而還是需要運營商對中間節點進行特殊的改造和設置。同時,上文所述的基于日志數據的溯源方法中存在的中間環節易中斷且無法對使用僵尸網絡的攻擊者進行溯源的問題依然存在。
1.3 基于主動感知數據的溯源方法
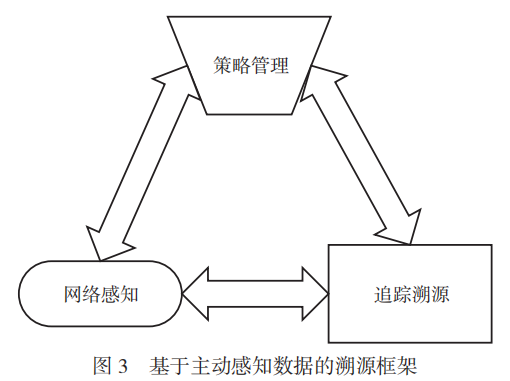
為了解決以上兩種方法的數據獲取難的問題,陳周國等人提出了一種基于主動感知數據的溯源技術框架,其架構如圖3所示。在此方法中,網絡感知是基礎,可以通過拓撲主動發現、網絡掃描和滲透等多種主動感知技術進行信息獲取。追蹤溯源模塊則對感知到的數據進行分析處理,重構數據傳輸路徑,并將結果與感知及策略管理模塊進行交互,以動態調整系統運行策略和感知內容。
2
基于網絡流量風險數據的溯源方法
2.1 溯源框架
在上述溯源方法中,溯源過程需要巨大的人力成本。在面對愈發頻繁和復雜的APT攻擊的情況下,這種溯源方式的效率日益低下。
近幾年,基于流量還原的網絡空間態勢感知技術不斷發展,相關產品也已在市場上取得了不錯的反響。通過對流量還原數據的分析和挖掘,可以發現網絡流量中的攻擊行為,并將其作為風險數據存儲到單獨的風險數據庫中。本文基于這些挖掘出的風險數據,提出了一種 APT 攻擊溯源的新思路。其整體框架和溯源流程分別如圖 4、圖 5 所示。
APT攻擊溯源的最終目的是定位到發起攻擊的組織或個人。APT組織往往都與特定的政治實體有關聯,在一段時間內具有較為固定的攻擊目標、武器庫、漏洞庫等,這些特征就可以成為確定一個組織的不同的維度。因此,溯源的過程可以分解成確定這些特征維度的過程。確定了維度之后,再與已有的APT組織情報庫進行匹配,就可以定位到某個具體的組織。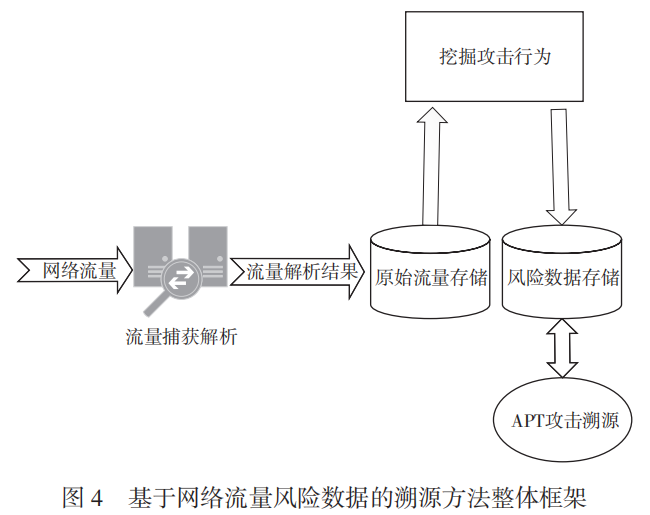
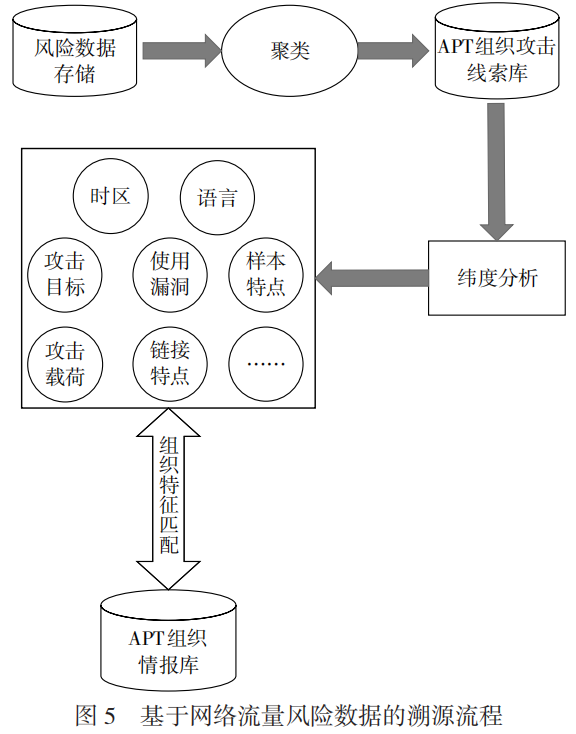
在圖5所示的溯源流程中,先基于風險數據進行聚類分析,把具有相似特征的多種類型的風險數據聚合在一起;然后再基于這些聚類的結果進行維度分析,得到APT組織的攻擊目標、時區、語言等維度的數據;最后基于分析得到的各個維度的結果,與APT組織情報庫中的組織特征進行匹配,確定該組織是否是某個已知的APT組織,或者是一個未知的組織。
本文重點研究在此方法中對風險數據進行聚類的過程。
2.2 聚類算法模型
2.2.1 定義
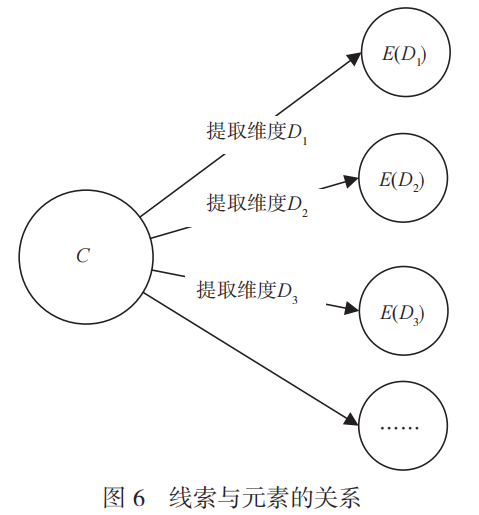
定義1:聚類(P)。把一批風險數據劃分成不同的數據集的過程。
定義2:線索(C)。一條風險數據就是一個線索,如一封釣魚郵件、一個木馬樣本等。
定義3:維度(D)。為方便對數據進行數學表示,而對數據進行拆分描述的不同的側面。
定義4:元素(E)。從風險數據中提取出來的各個維度的值。
定義5:線索集(S)。一批風險數據的集合。線索與元素的關系如圖6所示。
2.2.2 數學模型
根據以上定義,整個聚類的過程如圖7所示。

在圖7中,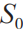 表示風險數據庫中的一批線索的集合,
表示風險數據庫中的一批線索的集合, 表示聚類的過程,
表示聚類的過程, 表示聚類得到的線索集,其中,
表示聚類得到的線索集,其中, 。
。
2.2.3 聚類算法
在本算法中,前置條件是需要有一批可以進行維度拆分的網絡流量風險數據。首先對數據的各個維度進行特征提取,然后轉換得到每個維度的元素值與線索集的映射。若用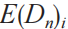 表示此映射中任意一個鍵值對的key,
表示此映射中任意一個鍵值對的key,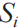 表示映射中任意一個鍵值對的value,則此鍵值對的含義就是
表示映射中任意一個鍵值對的value,則此鍵值對的含義就是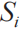 中的每一條線索都可以在維度
中的每一條線索都可以在維度 上提取出相同的元素值。
上提取出相同的元素值。
得到以上映射之后,把映射中所有鍵值對中的值兩兩之間取交集,得到多個新的線索集。這些新的線索集中的線索,彼此之間都有至少2個維度的元素值是相同的。然后在這些取交集得到的結果線索集中,過濾出線索數量超過閾值的線索集,作為后續聚類操作的聚類中心。
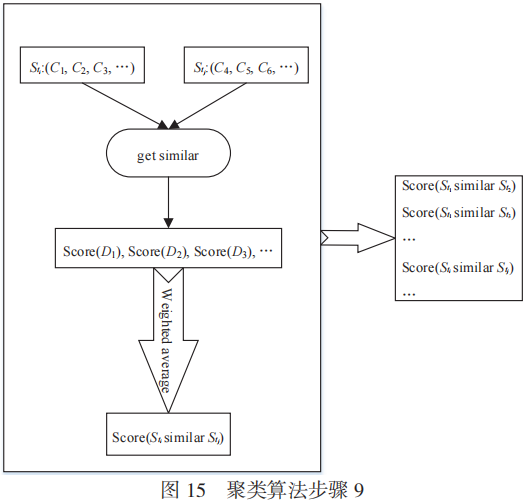
對每一個聚類中心的線索進行特征提取,然后針對原始線索集中不在任何一個聚類中心的線索,分別計算其與每一個聚類中心的歸屬度。歸屬度的具體算法:聚類中心在每個維度上的所有元素值都與線索對應維度的元素值計算相似度,如果有多個值,就對計算出來的相似度求和,即得到在此維度上的分數;然后把各個緯度的分數按照對應維度的權重計算加權平均值,得到一個線索歸屬于某個聚類中心的歸屬度。得到任意一個不在聚類中心的線索歸屬于任意一個聚類中心的歸屬度后,把線索加入到歸屬度超過閾值且分數最高的聚類中心。在此過程中,每個聚類中心又吸收到了與之歸屬度超過閾值且分數最高的線索。
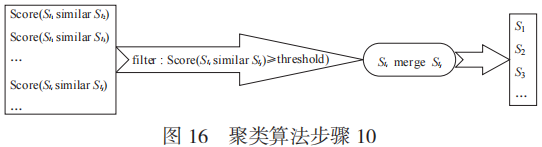
最后計算不同的聚類中心兩兩之間的相似度。相似度的具體算法:首先,對兩個聚類中心在同一維度的元素值計算彼此之間的相似度,如果有多個值,就把多個值求和,得到的結果即為在此維度上的分數;其次,把各個緯度的分數按照對應維度的權重計算加權平均值,就得到兩個聚類中心的相似度。求得所有聚類中心兩兩之間的相似度之后,把相似度分數超過閾值的兩個聚類中心進行合并,從而得到最終的聚類結果。
上述聚類算法的過程可以用如下的數學方法進行描述:
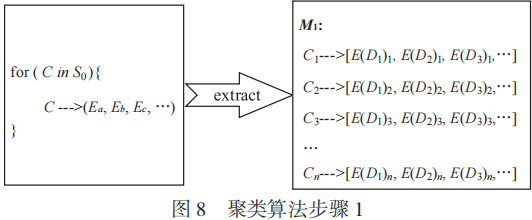
步驟1:如圖8所示,遍歷線索集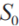 ,對于每一條線索
,對于每一條線索 ,提取維度特征
,提取維度特征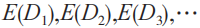 ,得到線索對應特征向量的映射
,得到線索對應特征向量的映射 。
。
步驟2:如圖9所示,轉換映射 ,得到的元素值對應線索列表的映射
,得到的元素值對應線索列表的映射 。
。

步驟3:如圖10所示,對映射中的線索列表兩兩之間取交集,得到線索集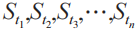 。
。
步驟4:如圖11所示,對上述結果進行過濾,選出線索數量超過閾值的線索集。
步驟5:如圖12所示,對上述得到的線索集中的線索進行元素提取。


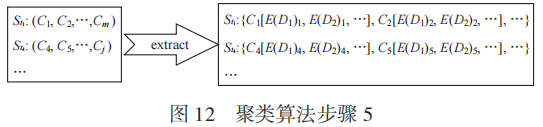
步驟6:把原始的線索集 與步驟4得到的所有線索集的并集取差集,得到線索集
與步驟4得到的所有線索集的并集取差集,得到線索集 ,即
,即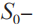
 。
。
步驟7:對于中的每一條線索 ,分別計算與線索集
,分別計算與線索集 的歸屬度。
的歸屬度。
步驟8:如圖14所示,對上述結果進行過濾,把線索加入到歸屬度超過閾值且分數最高的線索集中。
步驟9:如圖15所示,計算上述結果線索集中彼此之間的相似度。

步驟10:如圖16所示,合并上述結果中相似度超過閾值的線索集,得到最終的聚類結果。
2.3 實驗
2.3.1 場景設計
實驗場景:獲取一批郵件數據,對其進行解析,把解析的結果存儲到庫中。使用某種編程語言實現上述聚類算法,讀取存儲的郵件數據,并進行聚類,最后對聚類的結果進行分析。
數據準備:1 000條郵件數據
數據樣例:


2.3.2 結果評判標準
為了對一批數據的聚合程度進行量化,本文提出了同源度、聚合度與密集度的概念。
同源度用于衡量兩個線索是同一個組織產生的程度,其結果是一個大于0的數字。用符號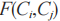 表示線索
表示線索 的同源度,
的同源度,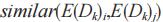 表示線索在維度
表示線索在維度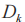 上的值的相似度分數,
上的值的相似度分數,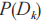 表示在維度
表示在維度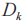 上的權重,每條線索能提取出n個維度,則有如下公式:
上的權重,每條線索能提取出n個維度,則有如下公式:
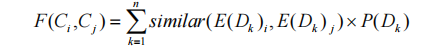
聚合度用于衡量線索集中任意一個線索與整個線索集之間的歸屬程度。用符號 表示線索集
表示線索集 中任意一條線索
中任意一條線索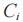 的聚合度,線索集中的線索數量為
的聚合度,線索集中的線索數量為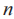 ,則有如下公式:
,則有如下公式:
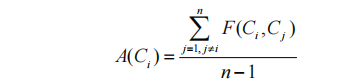
密集度用于衡量線索集中不同線索之間的平均聚合度,其值越大,表示此線索集中的線索彼此之間的同源度越高,聚類的效果就越好。用符號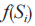 表示線索集
表示線索集 的密集度,線索集中的線索數量為,則有如下公式:
的密集度,線索集中的線索數量為,則有如下公式:
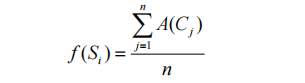
2.3.3 結果分析
本節使用Java語言實現上述聚類算法。線索的緯度劃分及權重如表1所示。

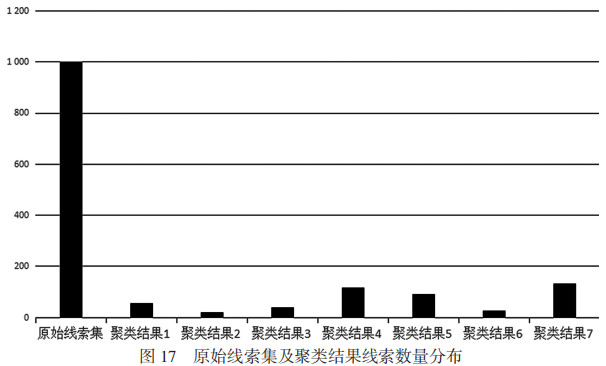
實驗共得到42個聚類結果,其中數據條數超過20的聚類結果有7個。原始線索集及聚類結果的線索數量分布如圖17所示。
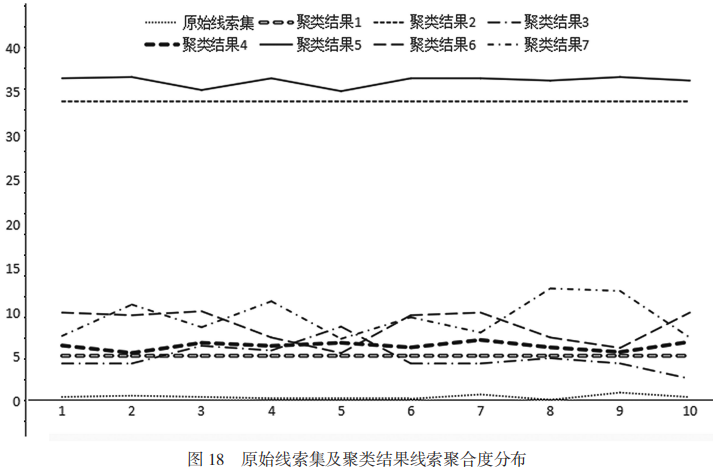
計算原始數據和聚類結果中每個線索的聚合度,從每個線索集中隨機獲取10條數據,得出其每個線索的聚合度分布如圖18所示。
從圖18可以看出,最下面的一條折線是原始數據的聚合度分布,其分數較低,說明原始線索集中的數據的聚類程度較低。在圖18的聚類結果中,所有線索的聚合度分數都要高于原始數據,說明這些聚類結果的聚類程度都要高于原始線索集。
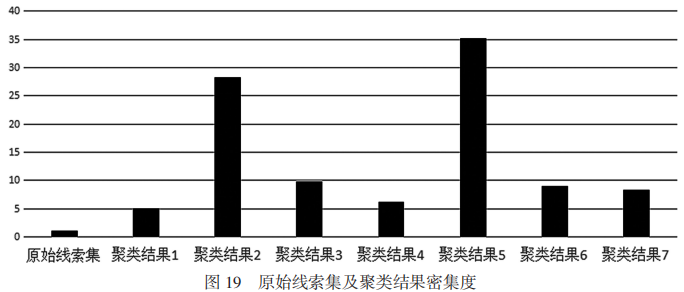
對原始線索集和聚類結果分別計算密集度,得到的結果如表2所示。把上述密集度分布用柱狀圖表示,如圖19所示。從圖19中也能很直觀地看出,所有的聚類結果較原始數據的密集度都有了數倍的提升,進一步說明了此算法的有效性。

3
結 語
本文介紹了傳統的APT攻擊溯源的方法,分析了傳統溯源方法的局限性,提出了一種基于網絡流量風險數據的溯源方法,建立了此方法的溯源框架,然后重點分析了此框架中基于風險數據產生APT組織攻擊線索庫的過程,提出了一種自動聚類的算法。該算法把風險數據自動劃分成多個不同的線索集,并使用Java語言實現了此算法,在測試數據上驗證了算法的有效性。
在上述實驗中,每條數據的維度劃分以及權重和閾值的設置對聚類的結果會有較大的影響,這些參數都需要具有一定相關經驗的人員進行測試和驗證。
后續的研究內容包括對數據拆分的維度和權重以及閾值等參數,使用機器學習的方法進行訓練,增加最終聚類結果的準確度;對聚類得到的線索集進行維度分析;根據APT組織的維度匹配到具體的APT組織的方法進行深入研究。
