[AI安全論文] 20.RAID19 基于Android移動設備的互聯網流量中的位置數據泄漏分析(譯文)
摘要
近年來,我們見證了移動設備向個性化、基于上下文服務的轉變。其中許多服務的關鍵組件是基于設備中嵌入的位置傳感器來推斷當前位置并預測用戶的未來位置的能力。這些知識使服務提供商能夠及時向其用戶提供相關的服務,并更好地管理流量擁堵控制,從而提高客戶滿意度和參與度。然而,此類服務存在位置數據泄漏的問題,這已成為當今智能手機用戶最關注的隱私問題之一。本文特別關注Android應用程序在用戶不知情的情況下,通過互聯網網絡流量以明文方式暴露的位置數據。
本文提出了一個涉及真實移動設備用戶網絡流量的實證評估,旨在:
- (1)測量基于Android的智能手機設備的互聯網流量中相關位置數據泄漏的程度;
- (2)了解這些數據的價值以及推斷用戶興趣點(POI)的位置;
- (3)在現實假設下,推導一個旨在推斷用戶興趣點的攻擊流程。
本文通過分析71名參與者平均37天的智能手機的互聯網流量來實現的。同時提出了一種從原始網絡流量中提取和過濾位置數據的程序,并利用地理位置聚類方法來推斷用戶的POIs。本研究的主要發現集中在這種現象的普遍性和嚴重性兩方面。實驗結果表明,超過85%的用戶設備泄漏了位置數據,而從相對稀疏的泄漏指標得出用戶POI的暴露率約為61%。
一.引言
近年來,在許多領域都出現了個性化服務的趨勢。移動設備上提供的服務尤其如此,數以百萬計的人每天都在使用大量基于上下文的應用程序(如Yelp、Uber、谷歌地圖)。這些設備擁有大量的私人信息,從用戶的個人和財務數據到他們的位置數據,使這些設備成為商業個性化廣告和情報收集的目標。
這些服務的一個關鍵特性是能夠了解用戶當前的位置、推斷興趣點以及基于設備中嵌入的位置傳感器預測用戶未來的位置。此類知識使服務提供商可以向其用戶提供相關的及時服務,例如導航建議、天氣預報、廣告和社交網絡等,從而提高客戶的滿意度和參與度。獲取移動設備位置的方法可以分為以下兩類。
基于主機的方法。 已安裝的應用程序可以通過探測內置傳感器或評估用戶在社交媒體上簽到時提供的數據來推斷設備的位置。能夠提供位置數據的本地傳感器包括熱點(Wi-Fi)信息,例如SSID和BSSID [1],已連接的基站和GPS [2]。該位置也可以通過使用各種側信道攻擊來推斷,例如電源差異分析[3]。
基于網絡的方法。 移動設備的位置可以通過使用基站信號塔三角測量[4],即通過分析設備所連接的發射塔接收到的信號來使用無線電定位,或者通過分析CDRs來使用無線電定位[5]。這需要對數據的高權限訪問,而這些數據通常是服務提供商和執法機構才可以獲得的。
為了利用位置跟蹤作為有意義的信息源,必須分析數據并將其聚集到對用戶很重要的位置集群中,例如家庭、購物或工作等場所[2]。這些位置也稱為用戶的興趣點(POIs)。推斷用戶興趣點最常見的方法是通過距離和時間閾值對位置軌跡進行聚類;最終,如果用戶在同一地方停留的時間足夠長,則會生成一個集群。POIs通過了解哪些集群對用戶很重要,并忽略不太重要的數據(如交通數據)來識別興趣點的[6,7]。
在移動設備上收集的位置數據可能由應用程序提供給第三方服務,或者被惡意應用程序泄漏[8]。最近的研究報告指出,在用戶不知情的情況下,流行的應用程序在不安全的通信通道上使用會導致很高的個人數據泄漏率。這些研究表明,位置數據是最“流行”的泄露個人身份信息(PII)之一,10%的最流行的應用程序以明文的形式泄露了位置信息[8]。事實上,據Trend Micro稱,位置權限是被濫用最嚴重的Android應用程序權限。在2018年DEFCON研討會上,這一隱私泄露也得到了承認,當時iOS和Android設備的應用程序都被檢測到以未加密的格式發送準確的位置數據。
最近的研究調查了來自合法或惡意應用程序的移動設備用戶的隱私風險,這些應用程序被授予訪問用戶位置的權限。然而,這些工作大部分都集中在分析和量化特定應用程序(或基于位置的服務提供商)的訪問,并授予位置數據訪問權限的私有數據公開[9-12]。然后在實際情況中,每個移動設備上都安裝了多個可以訪問位置數據的應用程序。因此,有必要探討多個應用程序泄漏位置數據對用戶隱私的影響。
本文在研究移動設備用戶的隱私風險時面臨一個主要的挑戰是應用程序訪問或收集位置數據,這可能需要root權限訪問。最近的研究通過在受控環境(如沙箱)中運行應用程序來收集數據[11,12],或者為研究對象提供一個不需要用作其主要設備的替代(根)設備[9]。先前的研究還分析了與能夠竊聽移動設備通信的攻擊者相關的隱私風險。這些工作主要集中在自動識別個人身份信息(PII)。
本研究通過多個應用來研究基于Android的智能手機在互聯網流量中位置數據泄露的現象。主要目的如下。
- 首先,了解設備網絡流量中明文傳輸檢測到位置泄漏的數量和質量及其相關性。
- 其次,分析位置泄漏并推斷用戶的興趣點。由于絕大多數現有的POI檢測方法都假設了一致且較高的位置采樣率(如通過GPS),該任務并非易事。因此,它們不能直接應用于有噪聲和稀疏的位置數據中,就像在本研究中關注的數據(即由于移動設備網絡流量而泄漏的位置數據)。
- 第三,從已識別POIs的數量、識別POIs所需的數據量、檢測到的POIs的準確率以及在POIs中花費的時間等方面了解用戶的隱私暴露程度。
為了實現這些目標,本文收集并分析了71名智能手機用戶平均使用時間為37天的互聯網流量,并且這些設備都是常規使用的。此外,使用安裝在設備上的專用Android代理應用程序來收集移動設備的位置,并對位置傳感器進行采樣。代理收集的數據被用作移動設備實際位置的基本事實。實驗結果顯示,超過85%的用戶設備泄露了位置數據。此外,根據相對稀疏的泄漏指標,用戶POIs的暴露率約為61%。即使位置泄漏率較低(6小時一次)并且覆蓋率只有20%(即應用程序訪問被泄漏的位置數據的時間的20%),也可以暴露約70%的加權POIs。
綜上所述,本文的貢獻如下。
- 首先,探討了智能移動設備不安全、未加密的網絡流量導致的基于位置的數據泄露的范圍、數量和質量。本文特別感興趣的是探索由多個應用程序泄露的位置數據對用戶隱私的影響,這種情況以前從未進行過調查。
- 其次,基于移動設備的真實數據進行實證評價。評估涉及一個獨特的數據集,該數據集是同時從設備本身以及從設備發送的網絡流量中收集的,從真實用戶設備中獲取這樣的數據非常困難。
- 第三,提出了一種從移動設備的網絡流量中收集、處理和過濾基于位置數據的方法,以推斷用戶的興趣點(POIs)。通過修改現有的聚類算法,在稀疏、不一致的數據流上使用POI聚類,并討論了實驗結果和應用過程的有效性。
- 最后,據我們所知,本文首次提出一個循序漸進的攻擊,其目的是在現實假設下泄漏位置數據并從設備的網絡流量中推斷用戶的POI。
二.基于位置服務的隱私
2.1 基于位置服務的隱私
根據GDPR的定義[13],個人數據或個人身份信息(PII)是可以用來識別一個人的任何數據,包括姓名、ID、社交媒體身份和位置。個人身份信息泄漏是移動設備用戶主要的隱私問題。除了設備和用戶標識符外,位置泄漏也是移動設備中最常見、最廣泛泄露的私有數據之一[8]。作為一個恰當的例子,最近的研究表明,使用位置跟蹤來消除用戶的匿名是可能的[14]。此外,大多數移動應用程序通常會請求位置許可(25%的應用程序使用精確的位置,更多的應用程序使用粗糙的位置)。如果不知道每個應用程序如何使用和處理位置數據,應用程序對位置API的訪問將對用戶的隱私構成真正的威脅。
表8(附錄)提供了該領域的相關工作總結。威脅行為者可以將研究大致歸類為威脅行為者,他們濫用網絡流量訪問權限來泄露用戶的個人信息。
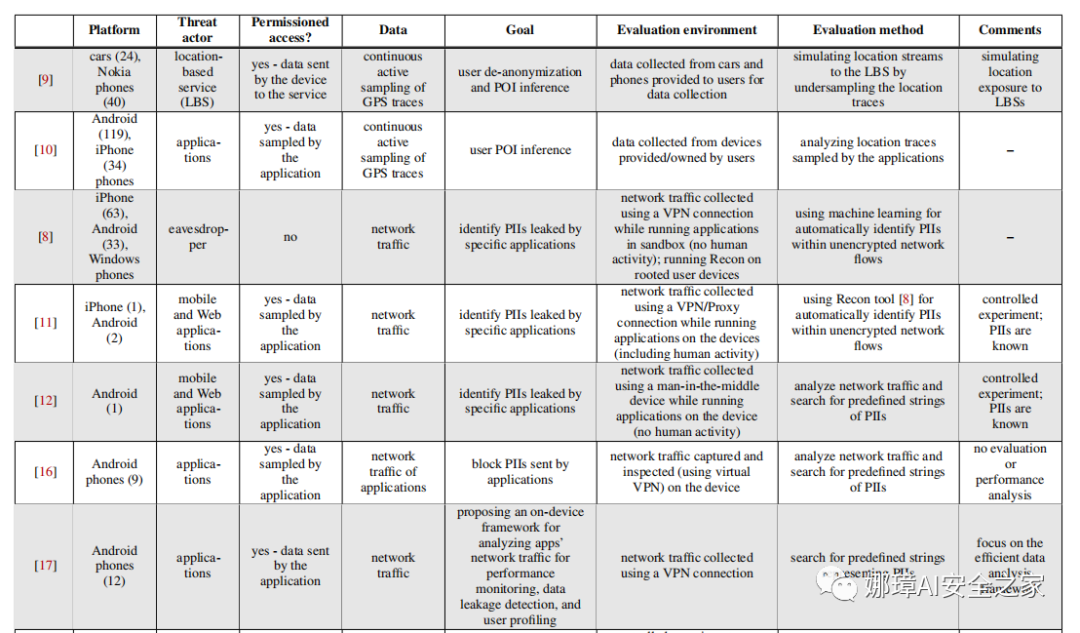
相關研究中考慮的第一類威脅參與者包括用戶安裝在移動設備上的應用程序[1,9-12,16-20]。這些研究側重于分析已安裝的應用程序,或者應用程序進行通信的基于位置服務提供商的私有數據,從而了解用戶所面臨的隱私風險。這可以嘗試通過使用位置跟蹤[9]來消除用戶的匿名化,推斷用戶的POIs[9,10,19]或識別其他PII泄漏[11,12,16-18,20]。
在大多數情況下,假定用戶已經授予訪問私有數據的權限[1, 9, 10, 16, 17, 20]。Razaghpanah等[18]和Song等[19]分析了私有數據對第三方服務(如廣告和跟蹤服務)的潛在泄露,這些服務通常以添加到應用程序中的庫的形式出現。在這些情況下,用戶在不知道應用程序中包含的第三方庫并且不知道這些第三方服務可以使用和使用數據的情況下,將許可授予安裝的應用程序。
為了進行分析,上述研究從實驗目的[9, 10]收集了提供給用戶的移動設備中的數據,或者在專用移動設備或仿真器上執行受監視的應用程序[11, 12, 19, 20] 。
先前研究中考慮的另一個威脅因素是可以分析在線社交網絡中公開可用的位置數據的攻擊者。此類數據包括Twitter中的推文元數據,Facebook中的簽到信息以及鄰近服務。在這些情況下,攻擊者通過分析數據來識別用戶的POIs[21-24]、移動模式[25-27]和位置[28]。與本文的情況一樣,在這些研究中分析的時空位置數據也是稀疏且不一致的。但在本文的研究中,我們考慮了一種不同的攻擊者模型,即可以監視和分析從移動設備發送到LBS的網絡流量的竊聽。
在本文的研究中,我們關注的是能夠攔截所有移動設備網絡通信的攻擊者(威脅參與者),例如ISP、VPN服務提供商或代理(如網絡流量的竊聽者)。假設此威脅參與者暴露于移動設備上安裝的所有應用程序和服務的所有數據泄漏中(而不是針對單個應用程序或基于位置的服務提供商的數據泄漏)。此外,與上面提到的用戶主動安裝應用程序并授予對私有數據的訪問權限的工作不同,在本文的工作中,用戶并不知道攻擊者可能正在觀察網絡流量。
先前的一些研究也關注網絡竊聽攻擊者[8, 20, 29]。例如,Taylor等[29]研究表明,通過嗅探知名且下載量很大的應用程序的網絡流量,攻擊者可以在用戶不知情的情況下獲取各種個人和設備標識信息,通過搜索預定義的PII字符串(例如,諸如IMEI和MAC地址之類的電話標識符),并在專用手機上運行應用程序,使用專用設置收集網絡流量來進行受控實驗。
然而,他們沒有分析位置數據泄漏的情況。相比之下,在這項研究中,本文的重點是分析真實用戶以及用戶手機上安裝的所有應用程序所擁有和使用的設備中位置數據泄漏的程度。Ren等[8]提出了Recon系統,這是一個基于機器學習技術的系統,用于自動識別以明文傳送網絡流量的PII;該作者使用可手動標記潛在PII泄漏(包括位置數據)的實際用戶擁有的設備,在受控實驗室環境(如在沙盒中運行應用程序)中測試了該方法。但是,該作者并沒有專注于估計設備上運行的所有應用程序泄漏的位置數據的程度和價值,這是我們研究的重點。此外,為了從原始網絡流量中獲得關于用戶的有價值的信息,本文提供了一個可由攻擊者應用的逐步過程。
用于傳輸PIIs的協議可能容易受到網絡攻擊,因此無論用戶意識如何,都會造成額外的隱私泄露。例如,Ren等[20]通過不安全的HTTP協議對移動應用程序中的數據泄漏進行了回顧,該協議可用于識別用戶。作為此過程的一部分,攻擊者可以使用作者提供的PII檢測器來提高網絡流量中位置數據的檢測。
綜上所述,在本研究中,我們專門針對一個可以監控網絡流量的攻擊者。在之前的研究中,攻擊者并沒有考慮到觀測數據中的任何噪聲,而在本研究中,我們討論了一個真實的案例,攻擊者以完全無監督的方式收集和分析原始網絡流量。
2.2 POI識別方法
從聚集的位置軌跡推斷有意義的位置是一個研究領域,自從廉價的民用移動GPS設備問世以來,整個領域在迅速發展。這些設備以及智能手機(在適當的導航和采樣模式下)已經無處不在,它們具有較高且恒定的采樣率。固定數據流的可用性是大多數位置分析研究的一個常見假設。
推斷有意義的位置取決于幾個主要的系列算法:Ester等引入了DBSCAN[30],這是一種基于密度的空間數據算法,它提供了確定具有未定義形狀集群的能力,并且不受特定數量集群的約束,也不使用時間數據作為參數。Birant等將DBSCAN擴展為ST-DBSCAN[31],它不僅使用數據庫點的空間數據,還使用更適合時空數據集的時間數據。Kang等[6]提出了另一種方法,根據時間和距離閾值對地點進行聚類,以區分停留點與過境點,從而改善軌跡分析。在當前的研究中,我們將此方法稱為“增量方法”。Kang等[6]使用預定義的約束是為了防止由于跟蹤之間丟失信息而導致不正確的聚類。Montoliu等[32]通過在跟蹤的約束之間添加最大時間約束來處理不一致和丟失的數據。Alvares等[33]提出使用語義數據來更好地理解所收集數據的含義,并且可以使用它們的方法來確定一個地點對用戶是否重要。
三.威脅模型
威脅模型是本研究的重點,它是一個能夠竊聽移動設備網絡流量并暴露于以明文傳輸的個人、敏感信息的攻擊者。
先前的研究已經討論了個人信息泄露和網絡流量泄漏的推斷。然而,這些研究主要涉及推斷靜態信息,如人口統計屬性或其他個人身份信息,當用戶連接到單個惡意熱點時可以觀察到這些信息。在本文的例子中,由于正在分析一段時間內的位置數據以獲取上下文信息,因此從單個熱點捕獲網絡流量是不夠的。本文假設一個威脅參與者可以連續捕獲用戶移動設備的網絡流量,這種特殊功能被授予以下威脅參與者:
互聯網服務提供商和移動網絡運營商(MNOs)。 它們會承受大量用戶的網絡流量。ISP威脅模型是很強大的,但是我們認為位置數據泄漏本身就是一個很重要的問題,因此應該加以研究。此外,雖然ISP從cell ID中獲取位置信息,但其獲取的位置非常粗糙。另一方面,從泄露的數據中得到的位置要準確得多。
VPN和代理服務器。 將移動設備的網絡流量轉發給第三方服務器,也會濫用在網絡流量中發送的未加密數據,這些解決方案越來越多地被移動用戶用來保護他們的隱私或消費有限的娛樂內容[34]。
類似Tor的解決方案。 該方案常用來保護隱私[35]。在這種情況下,出口節點可以使用位置泄漏數據來公開真實的用戶位置(可能還包括用戶的身份)。
這項研究的主要目標是估計威脅威脅參與者(如果他們選擇濫用此數據)或攻擊者潛在的隱私風險。注意,先前的研究(例如[14, 36, 37])證明可以根據位置跟蹤信息對用戶進行匿名處理。因此,能夠監視設備的網絡流量并推斷用戶的POI的攻擊者將能夠應用類似的方法(以及電話簿和社交網絡中公開可用的信息)來破壞用戶的匿名性。
四.數據收集
為了探索基于Android的智能手機在互聯網流量中位置數據泄漏的程度,我們開發了一個專用的數據收集框架。使用此框架,共收集了71名參與者平均37天的數據。
4.1 數據收集框架
該框架由三個主要組件組成:
- 一個VPN客戶端(用于收集由設備傳輸到因特網的所有網絡流量)
- 一個專用的Android代理應用程序(可從設備的位置API獲取位置數據)
- 一個輕量型服務器
VPN客戶端。智能手機上大量的因特網流量使其無法長時間在設備上本地存儲此信息。另外,在本地緩存因特網流量并每天將其傳輸到遠程服務器會增加設備電池、CPU和網絡的開銷。出于安全方面的考慮,此類操作需要超級用戶權限,因此需要對用戶的設備進行根處理。由于這些原因,我們選擇使用VPN隧道通過專用的VPN服務器重定向流量,在該服務器中可以記錄和存儲流量。需要指出的是,VPN是Android操作系統提供的唯一用戶空間API,可以用來攔截不需要超級用戶特權的網絡流量。
Android代理(客戶端)應用程序。為了了解設備網絡流量中明文檢測到的位置泄漏的質量,并評估用戶的隱私暴露成都,本文開發了一個專用的Android應用程序來獲取用戶的實際位置。該應用程序使用網絡位置提供的程序API,該API利用三個信息源:GPS、Wi-Fi和Cell ID(從蜂窩網絡獲得)來評估位置。代理應用程序收集的數據被用作用戶實際位置的基本事實。將聚類算法應用于移動設備采集的數據是準確有效的,可以推導出用戶的POIs[33]。因此,選擇使用這種方法作為基線,而不是在提供實際/標記POIs時依賴參與者的(主觀)協作。
輕量型服務器。該服務器有兩個主要目標。首先,它作為一個應用服務器與Android代理應用程序通信,并將所有位置數據存儲在一個數據庫中。其次,它充當VPN服務器,與VPN客戶端進行通信,記錄所有的網絡流量,并將其重定向到互聯網。為了提供VPN連接并記錄流量,我們在該服務器上創建了一個專用LAN(局域網),每個VPN客戶機都被分配到LAN中的一個不同的IP地址。互聯網流量是使用“tshark”記錄的,“tshark”是一種網絡分析工具,能夠從實時網絡流量捕獲數據包數據。
我們選擇使用這種數據收集方法的原因如下。
- 首先,因為我們進行的是探索性研究,我們不知道可以期待什么樣的數據,也不知道想要提前收集和分析什么樣的數據,所以我們希望能夠收集設備傳輸的所有網絡流量。
- 其次,能夠從參與者擁有和經常使用的設備收集數據對我們來說很重要。因此,我們不能使用需要根訪問的數據收集方法。
這也給我們的研究帶來了另一個挑戰,即連接網絡流量(特別是位置數據)和發送應用程序的能力。最后,因為我們想收集數據很長一段時間,我們跟著之前的研究和選擇使用收集的數據由代理用戶POIs的作為我們的基線,而不是依賴主觀合作的參與者提供實際/標記POIs這將需要在參與者很大的開銷。如前所述,這種方法在之前的研究中被證明是準確和有效的。
4.2 實驗
本文進行了一項有71位參與者的實驗。參與者是位于以色列兩個不同城市的兩所大學的現任和前任學生。有關參與者的補充信息如下:60%是男性,40%是女性;44%的人年齡在18至24歲之間,56%的人年齡在25至30歲之間;本科生占51%,研究生占49%。
圖2展示了不同應用程序安裝數量的分布,只關注被授予位置權限的應用程序。可以看到,超過40%的應用程序安裝在一個設備上。此外,大多數應用程序安裝在不到20%的設備上,只有少數應用程序安裝在超過50%的設備上。
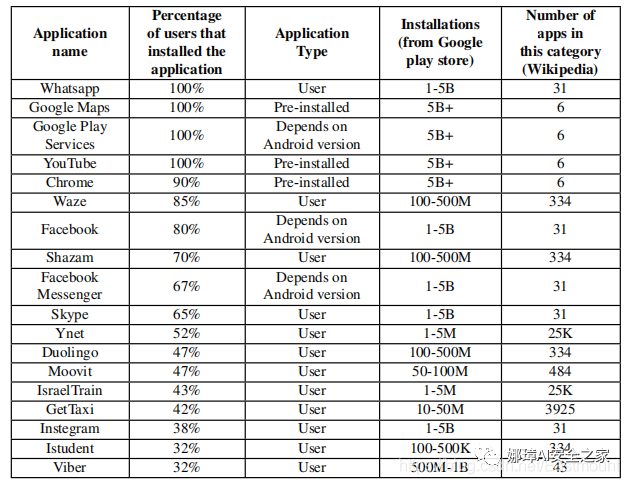
表1 探討安裝在參與者移動設備上的應用程序的受歡迎程度
本文還分析了安裝在參與者設備上的應用程序的受歡迎程度。可以看出,實驗參與者使用的大多數應用程序(如圖1a和圖1b所示)都非常受歡迎,在全球范圍內有超過十億的安裝(見表1)。這些應用程序(例如WhatsApp、Google Maps、Chrome、YouTube、Facebook、Skype和Instagram)不是特定用戶個人資料所特有的。此外,由于參與者設備上安裝的應用程序的多樣性(如圖1a、圖1b和圖2所示),我們認為從本研究中得出的見解是有效的,并且可以推廣到其他用戶配置文件。
在整個實驗過程中,要求參與者在其個人移動設備上安裝兩個客戶端應用程序(VPN和Android監視代理),該過程平均持續37天,具體取決于參與者的實際參與度。為了確保位置采樣對電池的影響最小,在大多數實驗中,Android客戶端每20分鐘對位置提供程序采樣60秒。此外,服務器已部署在AWS(亞馬遜Web服務器)EC2實例上,以確保高可用性。
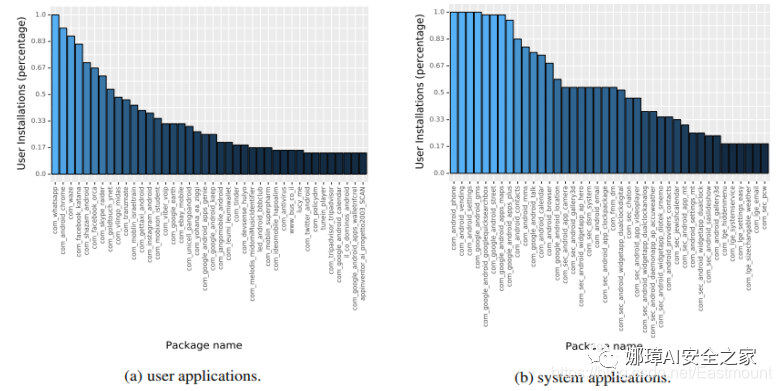
圖1 請求位置權限的參與者之間不同的應用程序安裝,對于每個應用程序組(用戶和系統)選擇前40名
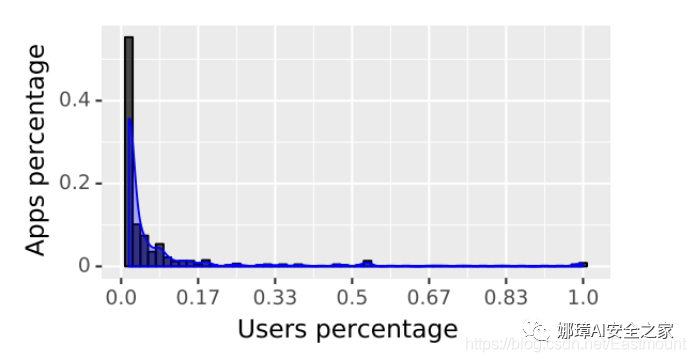
圖2 請求位置權限的應用程序之間的不同安裝
圖3展示了用戶參與實驗的時間。在實驗中觀察到代理應用程序的實際位置采樣率的分布如圖4所示。
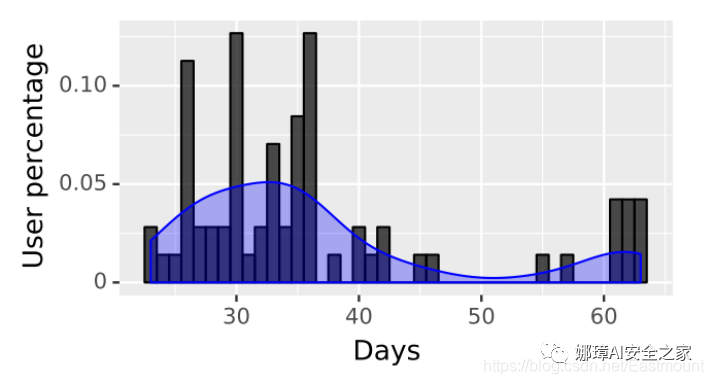
圖3 用戶參與實驗的時間(以天為單位)
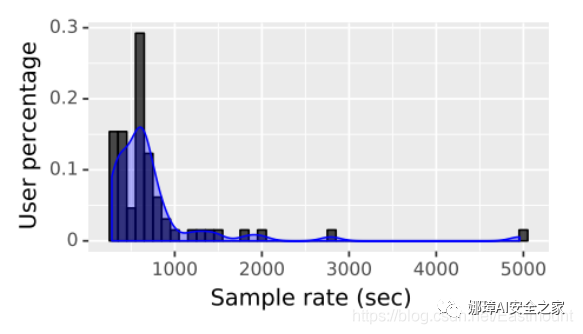
圖4 用戶設備上安裝代理的實際(平均)位置采樣率
注意,我們開發的框架,特別是安裝在參與者智能手機上的VPN和監視代理程序,僅用于數據收集、研究和驗證,并不被認為是威脅模型的一部分。
4.3 私隱及道德考慮
該實驗涉及長時間收集來自真實對象的敏感信息。為了保護受試者的隱私,采取了以下步驟。
受試者自愿參加實驗并提供正式同意參加研究。此外,他們充分了解將要收集的數據類型,并允許其隨時退出研究。受試者獲得一次性報酬作為參與補償。
對數據進行匿名化處理。在實驗開始時,為每個受試者分配了一個隨機的用戶ID,該UID用作主體的標識符,而不是其實際的標識信息。UID和主體真實身份之間的映射存儲在一個保險箱的硬拷貝文檔中,在實驗結束時銷毀了該文檔。
在實驗過程中,代理與服務器之間的通信是完全加密的。此外,收集的數據存儲在加密的數據庫中。實驗結束時,將數據轉移到一個本地服務器(機構網絡內)未連接到互聯網。僅保留受試者的匿名信息以供進一步分析。基于這些步驟,該研究獲得了機構審查委員會(IRB)的批準。
五.從原始網絡流量中提取位置跟蹤
位置數據可以通過網絡流量以多種格式傳輸,包括顯式地理位置坐標、城市或POIs名稱、Wi-Fi網絡(BSSID)和蜂窩網絡數據(Cell ID)。
在本研究中,關注的是明文傳輸的顯式地理定位數據,這樣的結構化數據可以(潛在地)提供更精確的位置,更容易提取和分析。如果泄露,會給用戶的隱私帶來更大風險。
5.1 過程描述
為了自動檢測移動設備網絡流量中的位置跟蹤,我們在IP網絡層捕獲數據。地理坐標可以用不同的格式表示[38]。執行正則表達式搜索標準Android API[39]表示的地理坐標,它是以下格式的十進制度:xXX.YYYYYYY。本文使用此正則表達式有兩個主要原因。首先,這是Android location API的標準格式,因此此類表達式很可能是位置數據。其次,對其他位置數據格式(例如城市名稱、POIs和Wi-Fi網絡)的手動研究表明,它們可能會顯著增加誤報的數量。例如,天氣預報應用程序發送的城市名稱并不表示用戶的真實位置。注意,正如Ren等提出的[8],機器學習技術可用于自動識別網絡流量內的PII(包括位置數據),然而,這仍然不能確保所識別的數據指示用戶的真實位置。
根據數據包捕獲時間為每個結果分配一個時間戳。該正則表達式可以檢索不具有地理意義的簡單浮點數的不相關結果,并且可以出現在網絡流量中(如對象在屏幕上的位置)。下一步將應用以下啟發式方法來過濾掉不相關的結果。
傳出流量過濾器。 從輸出流量中提取地理坐標(輸入的流量可能包含與用戶真實位置無關的地理數據,例如POIs建議和天氣預報)。
緯度/經度對過濾器。 僅提取分配有相同時間戳的有效地理坐標對,這是因為坐標由表示位置的緯度和經度的兩個值表示。
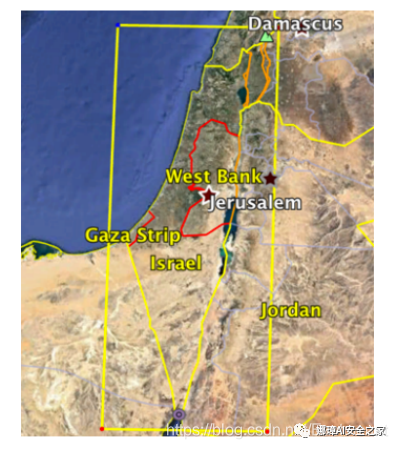
圖5 識別坐標的地理圍欄,篩選位于預定義地理區域之外的坐標
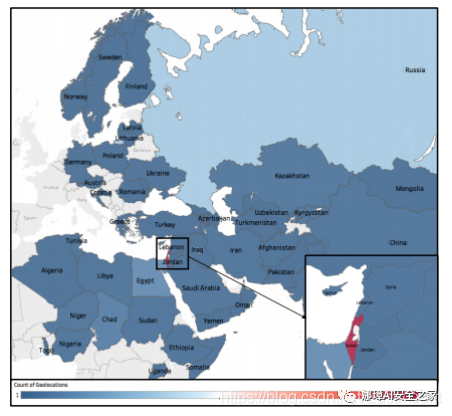
圖6 所有參與者在網絡流量中發現的隨機選擇地理位置的全球分布
地理圍欄過濾器。 過濾超出預定義地理圍欄(如給定國家或城市的地理邊界)的地理坐標。在本案例中,在數據收集期間,所有用戶都位于以色列的地理邊界內,因此過濾掉了不在該區域內的所有地理坐標(圖5中顯示了地理邊界)。注意,在一般情況下應用地理圍欄過濾器,攻擊者可以對泄漏的位置數據執行反向地理編碼,并識別最有可能與用戶或一組用戶相關的地理區域。在圖6中演示了這種方法,從泄漏的位置數據(1%)中隨機選擇的樣本執行了反向地理編碼。由圖可知,大多數樣本位于以色列國境內。
5.2 分析和結果
為了評估位置數據泄漏量,必須確定在網絡流量中檢測到的地理坐標的準確性和正確性。在本文的實驗中,可以將網絡流量中檢測到的地理坐標與代理應用程序(安裝在參與者的手機上)采樣的位置數據進行比較。通過對agent應用程序采集的數據進行分析,發現該位置的采樣率只有70%(位置采樣率的分布如圖4所示)。可能的原因是設備關閉、代理關閉或位置服務禁用。根據上述觀察,將給定用戶的活動時間定義為代理觀察至少一個位置樣本的小時數。
驗證泄漏樣本的正確性。 使用代理觀察到的位置樣本,驗證了在網絡流量中檢測到的地理坐標。具體來說,只有在以下情況下,網絡流量中觀察到的位置才被歸類為“真實的”位置:(1)檢測到坐標的時間戳在代理應用程序采樣的位置的預定義時間閾值內,并且(2)兩個坐標之間的距離低于預定義的距離閾值。如果檢測到的坐標的時間戳與代理應用程序采樣的位置足夠接近(在時間閾值內),則將檢測到的坐標標記為“false”;否則,將其標記為“unknown”。本文將距離閾值設置為250、500和1000米,將時間閾值設置為10和30分鐘(參見表2),并測試了泄漏位置數據的標記。不出所料,當增加距離或時間閾值時,更多泄漏的位置坐標將被標記為“true”。另一方面,這樣做可能會導致標記錯誤。因此,選擇使用最嚴格的標簽規則,其中距離閾值設置為250米,時間閾值設置為10分鐘。
泄漏的位置數據量。 在所有被監視的移動設備的網絡流量中,總共識別出約474K的地理位置(符合標準API位置正則表達式)。應用地理圍欄濾鏡后,大約還有347K地理位置。
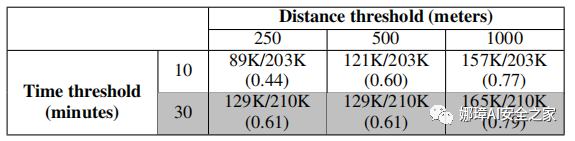
表2 距離閾值為250、500、1000米,時間閾值為10、30分鐘時標注泄漏位置數據的結果
圖7顯示了應用緯度/經度對過濾器(左列)以及應用緯度/經度對過濾器和傳出流量過濾器(右列)之后在網絡流量中檢測到地理位置的分類。每列都會根據上述標記過程顯示其余地理位置的標簽分布(“true”,“false”和“unknown”)。在使用緯度/經度對過濾器后,總共剩下257K個地理位置,其中36%被標記為“true”,47%被標記為“false”,其余則無法標記。在應用發送流量過濾器后,還保留了100K個地理位置,其中58%被標記為“true”,11%被標記為“false”,剩下的不能被標記。
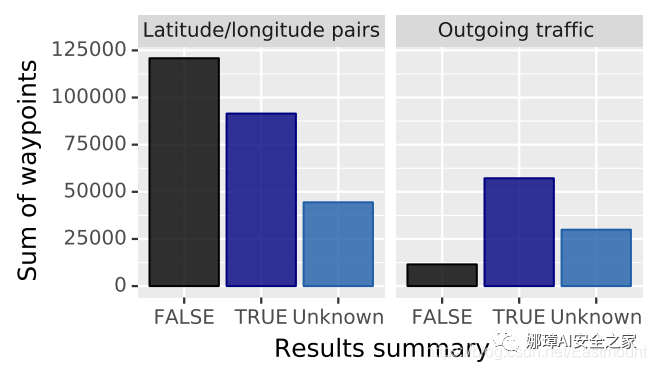
圖7使用經/緯度對過濾器以及同時應用經/緯度和傳出流量過濾器之后,在網絡流量中檢測到的地理位置分類
這些結果支持本文的假設,即傳入流量不太可能包含移動設備的相關地理位置。還可以看到,應用了所有三個過濾器后,可以標記為“ true”或“false”的地理位置中有85%表示移動設備的真實位置。我們可以假設無法標注的地理位置也存在相同的值(即“未知”)。
數據泄漏速率。 通過分析71位用戶已驗證的地理位置(即標記為“true”),我們可以看到其中大約90%的移動設備正在泄漏了位置信息。一個給定用戶設備的數據泄漏的速率由通過已驗證的泄漏位置的數量除以用戶的活動時間來計算的。本文將計算出的泄漏率分為以下幾組:“高”、“中”、“低”和“無泄漏”,如表3所示。從表3可以看出,55%的設備以中等速率(每1~6小時一次)或高速率(每1小時一次)泄漏位置數據。
5.2.1 泄漏范圍
將暴露小時定義為收集數據(網絡或代理)中至少檢測到兩個有效的位置泄漏的小時。為了分析相關已驗證的泄漏位置數據隨時間的覆蓋率,將覆蓋率度量定義為網絡流量暴露的總小時數除以代理數據的總小時數(不包括該代理未工作的時間),公式如下所示。

假設高覆蓋率會導致用戶重要位置的高曝光率和高發現率。圖8展示了收集到數據集中移動設備的覆蓋率分布。可以看出,近70%的用戶覆蓋率在0.2以下。
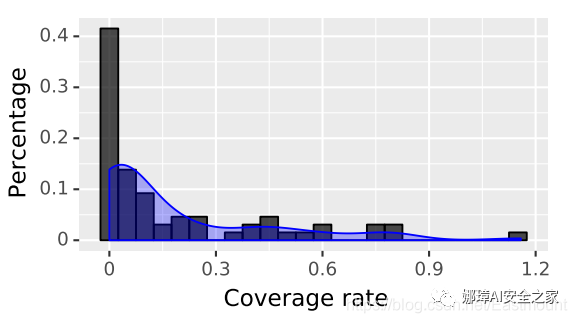
圖8 覆蓋率度量的分布。覆蓋率度量被定義為網絡流量暴露的總小時數(即觀察到位置泄漏的小時數)除以代理程序應用程序數據的小時總數
5.2.2 泄漏不一致
盡管表3和圖8給出了位置數據的總體平均泄漏率,但對數據的人工檢測表明,泄漏的數據表現出不一致、不均勻和突發的行為。例如,圖9描述了代理應用程序觀察到的單個用戶每小時的位置樣本數量(藍色線)和網絡流量內的位置樣本數量(黑色線)。可以看出,雖然代理的采樣率相對穩定(每小時大約12個采樣),但不包括微小的變化(如電話關機或代理崩潰),但網絡流量中泄漏的位置數據不穩定,從只有很少或根本沒有泄漏的概率很高。
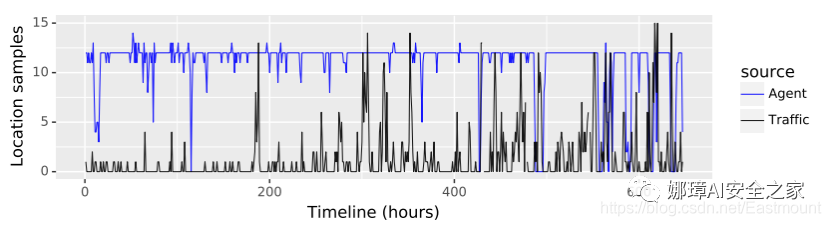
圖9 設備上安裝的代理(藍色線)和網絡流量(黑色線)中觀察到的單個用戶位置泄漏率的示例
因此,為了分析和理解泄漏的位置數據量的不一致性,通過將“每小時泄漏”的標準偏差除以“每小時泄漏”的平均次數來計算每個移動設備的相對標準偏差度量。圖10為移動設備相對標準差測度值的分布情況,其中0表示恒定的泄漏率。
我們還想了解白天位置泄漏數據的分布情況。如圖11所示,一天中不同時間段的泄漏率和參與者白天的正常活動(如晚上睡覺、上課和午休)有關。

表3 不同移動設備的泄漏率。由表可知,有55%的設備以中等速率(每1至6小時一次)或高速率(每1小時一次)泄漏位置數據
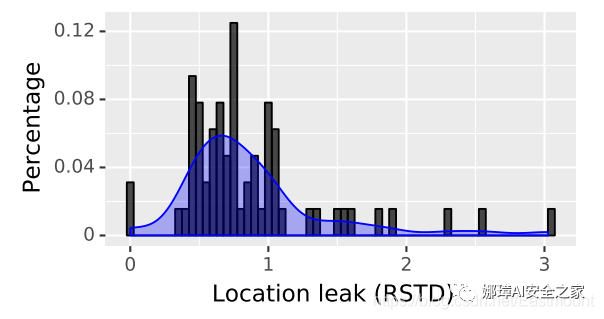
圖10 由泄漏相對標準偏差測量值指示的泄漏率變異性
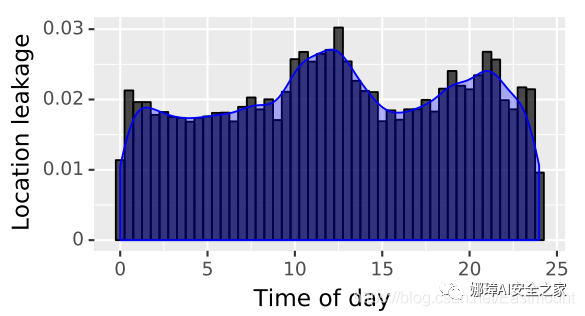
圖11 一天中不同時間(小時)內的位置泄漏率(百分比)
六.從泄露的位置軌跡推斷POI
本文還希望了解攻擊者如何從檢測到的移動設備網絡流量泄漏的地理位置(坐標)中推斷出有意義的信息。具體來說,識別用戶的POIs并將其與傳輸或噪聲數據區分開[40]。
識別停留點或POIs最常用的方法是應用聚類算法,這些算法通常不會綁定到預定數量的集群(如k-means),并根據空間或時空參數對停留點進行聚類。在本研究中,選擇了三種不同的算法:
- 增量聚類
- DBSCAN
- ST-DBSCAN
這些算法通常會對數據做一些假設。具體來說,假設數據以恒定的速率到達,這在本文的情況下是不正確的。因此,我們對算法做了一些修改。
首先,對于增量算法,通過計算樣本之間的時間來添加時間概念,并定義時間間隔的界限。算法1給出了修正增量算法的偽代碼(詳見聚類過程)。可以看出,該過程接收三個輸入:距離閾值(用D表示),時間閾值(用T表示)以及按其時間戳排序的位置采樣列表(用WP表示)。距離閾值指定群集中心到給定位置樣本之間的最大距離(以米為單位)。如果該距離小于距離閾值,則將位置樣本添加到集群中(第13-17行);否則,它被認為是另一個集群的實例,或者是過渡狀態。時間閾值指定將路徑點列表視為集群的最小時間。如果該時間大于時間閾值,則將路點列表視為一個集群(第18-21行),否則不被視為集群。
算法1:具有回溯和時間約束的增量聚類

其次,對于增量算法和ST-DBSCAN算法,應用一個回溯過程對創建的群集進行迭代,并合并距離閾值內的群集(第28-36行)。回溯過程的主要好處是可以隨著時間的推移增加重復集群的置信度。
另一種方法是使用語義數據來確定用戶何時在重要位置。例如,位置跟蹤將一個著名的地標處標識為該用戶的一個重要位置[33]。這種方法與本文的情況無關,因為POIs事先是未知的。然而,本文使用來自反向地理編碼的語義數據來消除公交地理位置(例如高速公路)。
在完全無監督數據中應用聚類算法時,其主要挑戰之一是正確選擇參數(即距離和時間閾值),因為這些值直接影響算法檢測到聚類的數量和大小。為了解決這一挑戰,本文測試了幾個時間閾值(15、30和60分鐘)和距離閾值(100、250和500米)。
注意,我們沒有關于用戶的真實(已確認)POIs的任何信息,以便了解在網絡流量的泄漏位置識別出的POI的性質和有效性。因此,通過對Android代理位置數據(記作增量代理)應用增量聚類算法來確定POIs,以此作為基準和基礎事實。由于移動代理應用程序收集的位置跟蹤信息可以高精度地指示用戶的真實位置,并且POIs聚類方法在以前的工作中已證明是有效的,因此本文發現此基準足以滿足我們的目的。
在表4中,介紹了針對不同距離和時間閾值的增量算法檢測到的聚類類簇(POIs)的數量。可以看出,減小距離和時間閾值會產生大量的群集,而增加距離和時間閾值則會產生較少的群集。盡管如此,可以看出不同的參數并不影響檢出率。對于剩下的評估,將算法的閾值設置為500米和30分鐘。
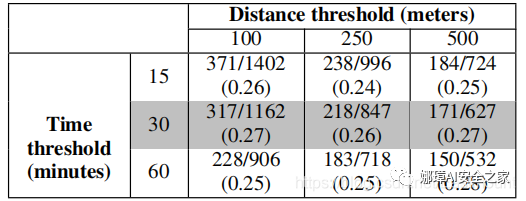
表4 當選擇不同的距離和時間閾值時,增量算法檢測到的簇數(POIs)
通過將不同的聚類算法應用于網絡流量的泄漏位置(表示為增量流量、DBSCAN流量和ST-DBSCAN流量)來識別POIs,并將其與基于代理(即增量代理)的POIs進行比較。
本文計算了在每個用戶POI上花費的總時間,并根據用戶在所有POI中所花費的總時間中所占的比例,分配了代表POI重要性的權重。
POI檢出率。 使用增量代理方法總共識別了1053個POIs(在所有用戶中)。對于每個基于流量的方法,計算:(1)已識別出的POIs總數;(2)真陽性(也采用增量代理方法檢測到的POIs數量);(3)準確率(真陽性除以已識別的POIs總數);(4)召回率(真陽值除以通過基準方法確定的POIs數量,即增量代理)。
此外,先前有關位置數據分析的工作表明,可以使用先前獲得的語義信息(如地標、購物中心、道路等)來確定位置軌跡是用戶的POI還是中轉位置[33] 。因此,為了進一步改進POI推斷過程,我們使用了先前獲得的語義信息,以便更好地確定實際POIs。具體來說,使用Google的反向地理編碼API來刪除位于高速公路上的地理位置集群(即POI)。
結果顯示如表5所示。可以看出,召回率表示所有方法POI的發現率,其值約為20%。與其他方法相比,增量流量方法產生的效果最好,召回率略低,但準確率更高。括號中的值表示使用此語義信息時檢測到的POIs的結果(真陽性、精確率和召回率)。由表可知,使用語義信息消除不相關的位置簇可以提高精確率,而不會影響召回。這可以通過以下事實來解釋:由于網絡流量中的位置泄漏較低且不一致,因此無關的位置群集(例如高速公路)在網絡流量內的反映得較差,但被代理更好地捕獲了。

表5 當將增量代理作為用戶POIs的基本事實,三種方法(增量流量、DBSCAN流量、STDBSCAN流量)的召回率和準確率。括號內的值表示使用語義信息時檢測到的POIs的結果
在真實場景中,攻擊者將無法將提取的地理位置標記為“true”、“false”或“unknown”(如第5節所述)。因此,在表5中,將聚類算法應用于所有地理位置。然而,為了評估攻擊者可能獲得的最佳結果,我們只對用戶的“true”地理位置應用POI識別過程。在這種情況下,增量流量聚類方法實現了類似的召回率,但是其精度顯著提高到95%。
識別25%的POIs的重要性。僅識別出POIs的數量并不一定能很好地估計用戶所在位置的暴露率。例如,假設一個用戶有十個不同的重要位置(POIs)。如果用戶將其50%的時間都花費在家里,35%的時間用于工作,通過確定用戶的住所和工作地點,能夠確定用戶將其85%的時間花費在這些位置(盡管我們只發現了20%用戶的POIs)。
因此,為了估計所標識位置(POI)的重要性,本文進行了如下的POI檢測率的加權度量計算。
對于檢測到的每個POI,計算用戶在該位置花費的相對時間(即用戶在POI上的總時間除以用戶在所有POI上花費的總時間)。POIs的加權度量是根據基線增量代理方法計算得出的。然后,使用為每個識別出POI計算的權重來計算POI發現率度量。表6中顯示的結果表明,中度和高度泄漏率下的加權POI發現率較高,加權POI的暴露率總計為61%。

表6 增量流量方法的POI和加權POI發現率。POI發現率是在網絡數據中發現的位置數除以通過增量代理方法發現的位置數。加權POI發現率是在標識的POIs上花費的總用戶時間
攻擊。 綜上所述,能夠竊聽用戶網絡流量的攻擊者可以采用以下分步攻擊來推斷用戶的POIs(從而揭示其身份)。
- 首先,攻擊者使用正則表達式或預先訓練的機器學習模型識別出站網絡流量內的地理坐標。
- 接著,攻擊者在所標識的坐標上應用緯度/經度對和地理圍欄過濾器。
- 最后,攻擊者將本文提出的增量流量聚類算法應用于剩余的地理位置(在應用了過濾器之后),以識別用戶的POIs。
在真實場景中,攻擊者沒有基準可以關聯,并且僅根據捕獲的數據來推斷用戶的POI暴露率。通過推導回歸模型(表7)可以看出,用戶加權POI暴露率參數與泄漏量和覆蓋率指標具有高度相關性,而與相對標準差則相關性不顯著。因此,攻擊者可以根據分析出的流量來計算泄漏率和覆蓋率,并估算用戶POIs的潛在暴露率。
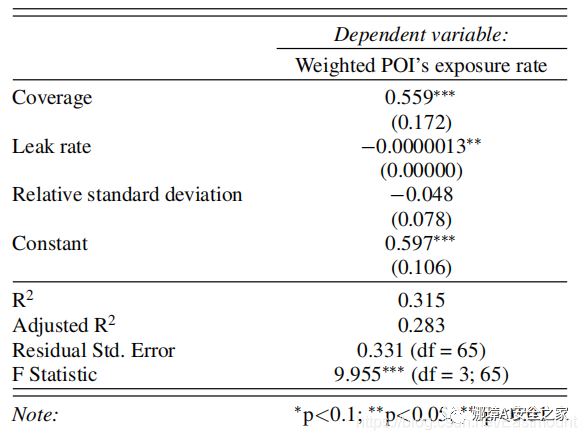
表7 從網絡流量測量中估計POIs暴露率的線性回歸模型
七.識別泄漏應用程序
本節分析的目的是確定哪些應用程序要對位置數據的泄漏負責,以及是否由于故意濫用或良性應用程序以明文形式發送泄漏而導致泄漏。
獲取此類信息的一種方法是實時監視已安裝應用程序的傳出流量[17, 41]。但是,從Android 8.0版開始,此類操作需要超級用戶權限(這需要對用戶設備成為root用戶)。在本文的實驗中,分析了用戶個人設備的網絡流量,因此這種方法是不可取的。
從捕獲的網絡流量中獲取有關泄漏的應用程序的信息也具有挑戰性,主要有以下三個原因:
- (1)捕獲的網絡流量未提供一個明確的指示發送應用程序/服務;
- (2)由于使用云服務和內容分發網絡,許多目的地ip承載服務,如AWS, Akamai或谷歌;
- (3)位置數據可以通過許多Android應用程序中嵌入的組件發送到廣告和情報服務領域。
鑒于此,本文選擇分析HTTP通信流中觀察到的目標主機名,特別關注包含位置泄漏的傳出流量。通過從包含泄漏位置數據的HTTP請求中提取主機名,確定了112種不同的服務。然后,我們使用公共安全服務(如VirusTotal)、搜索引擎(谷歌和Whois)和安全報告來分析主機名。
根據分析結果,通過報告的使用情況(如天氣預報、導航、位置分析)對每個主機名進行分類,并判斷它是合法的還是有害/可疑的服務。位置使用情況明確/合理且未報告安全問題的服務被歸類為“良性”,其余服務被歸類為“可疑”。
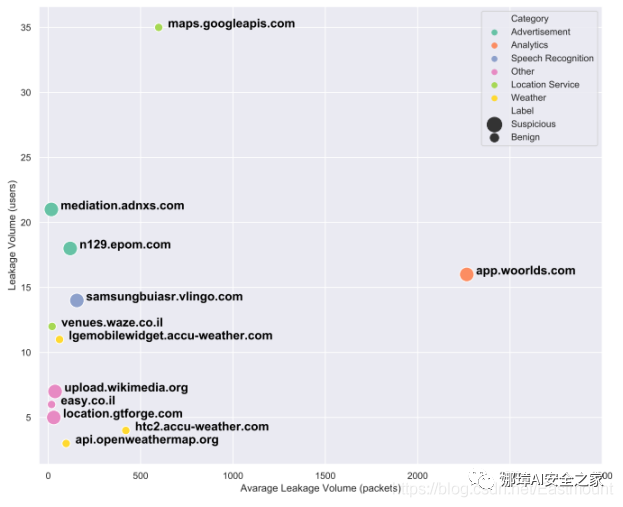
圖12 顯示按類別(顏色)和可疑程度(圓圈大小)分類的前12個主機名。x軸表示檢測到的泄漏事件的平均數量,y軸表示向該主機名發送位置數據的參與者數量。
圖12 顯示了按類別(顏色)和可疑程度(圓圈大小)分類的前12個主機名。每個主機名根據檢測到的泄漏事件的平均數量(x軸)和向該主機名發送位置數據的參與者數量(y軸)放置在圖中。
其中一些可疑域名包括samsungbuiasr.vlingo.com,該域名曾作為稱為Vlingo的三星預裝語音識別應用程序發布。此應用程序被發現正在泄漏敏感信息。其他示例包括域n129.epom.com和mediation.adnxs.com,據報道這些域可提供個性化廣告。另一個重要的可疑域是app.woorlds.com,這是一個位置分析服務。
有趣的是,我們的分析得出的結論是,Google Maps JavaScript API (Maps.googleapis.com)允許Android應用程序開發人員根據用戶位置定制地圖,它還負責以明文發送位置數據。這一點特別值得注意,因為Google建議應用程序開發人員盡可能使用安全的Maps JavaScript API(通過HTTPS操作)。盡管如此,該分析表明,開發人員在實踐中還使用了不安全的Map JavaScript API。總體而言,根據分析的數據發現,不受歡迎的服務集合造成了60%以上的位置泄漏事件。
另一個觀察結果是,盡管每個主機名的位置數據泄漏事件(圖12中的x軸)的數量并不高,但是根據第6節中的分析,仍然能夠從數據中識別出用戶的重要POIs。本文將此發現歸因于以下事實:每個智能手機上都安裝了多個應用程序,這些應用程序一起泄漏了足夠多的信息,可以對這些信息進行分析,從而推斷出POIs。
盡管泄漏的應用程序的身份未在網絡流量中明確指出,但我們進行了進一步的分析,試圖將識別出的主機名與用戶移動設備上安裝的應用程序鏈接起來。為此,首先使用Android代理提取了安裝在需要位置和網絡權限的用戶移動設備上的所有應用程序的集合。接著,為由應用程序和主機名組成的每對計算一個改進的tf-idf值。
tf-idf是文本分類領域中一個著名的度量標準,在信息檢索和文本挖掘中經常被用作一個加權因子[42]。tf-idf是一個數值統計,旨在反映特征(單詞)對集合或語料庫的重要性。tf-idf值與單詞在文檔中出現的次數成比關系,但是它被單詞在語料庫中的頻率所抵消,這有助于調整某些單詞在一般情況下出現得更頻繁的事實。在我們的示例中,文檔是主機名,單詞是應用程序。應用程序a相對于給定主機名h的詞頻TF計算如下:
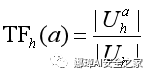
其中Uh表示確定其位置泄漏(從他們的設備到h)的用戶集合,Uha表示Uh在其設備上安裝了應用程序a的用戶子集。
應用程序的逆文檔頻率(用IDF表示)計算如下:
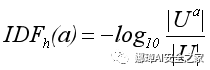
其中Ua表示在設備上安裝了應用程序a的用戶集,U表示所有用戶的集合。綜上所述,應用程序對給定主機名的tf-idf計算如下:
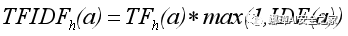
將逆文檔頻率(IDF)限制為1的原因是為了防止罕見的應用程序獲得很高的tf-idf分數,從而錯誤地鏈接到主機名。此外,將min-max歸一化應用于應用程序的tf-idf分數,以使它們保持在0到1的范圍內。應用程序A相對于主機h的高tf值表明,在以明文向h傳輸位置數據的設備中經常觀察到A。
另一方面,如果a的idf值很高,則表示通常不會在設備上頻繁觀察到a。因此,針對主機h的應用程序a較高的tf-idf分數可能表明a與h的位置泄漏有關。
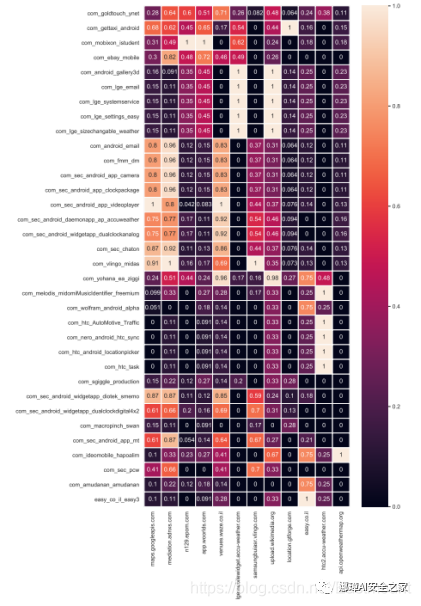
圖13 每個主機名和應用程序的tf-idf值
該分析的原始結果顯示在圖13中,顯示了每個主機名(x軸)和應用程序(y軸)的tf-idf值。基于這些結果,將應用程序分為兩類。
第一類包括將位置數據發送到其自己的托管服務的應用程序。
- 在此類別中,可以找到多個HTC、LG和Samsung預安裝的應用程序,它們與自己的托管服務有關(htc2.accu-weather.com,lgemobilewidget.accu-weather.com和samsungbuiasr.vlingo.com),也與它們的托管服務相關的GetTaxi(com.gettaxi.android)和Easy(easy.co.il.easy3)應用程序(分別為location.gtforge.com和easy.co.il)。
第二類包括將位置數據發送(通過集成的“軟件插件”)到第三方服務的應用程序。
- 例如廣告API(n129.epom.com)或分析服務(app.woorlds)。在這一類別中,我們確定了一個受歡迎的學生應用程序,名為com.mobixon.istudent。
本文還確定了將位置數據發送到Google Maps服務的應用程序,其中一些可能以不安全的方式(HTTP協議而不是HTTPS協議)使用Google Maps JavaScript API。
八.緩解策略
為了降低本文中所提出的位置泄漏和POI推斷的隱私風險,本文提出了以下對策,并在今后的工作中進一步研究和發展。
- 意識。最基本的方法是提高移動設備用戶對此類風險的認識,并為他們提供降低風險的工具和手段[43]。例如,通過只安裝受信任的應用程序(來自受信任源),監視和限制敏感權限(如位置和互聯網訪問)以及在設備不使用時禁用位置服務并只在需要時打開它來降低風險。還可以使用Recon[8]和LP-Doctor[10]之類的工具,通過顯示警報并提供覆蓋敏感傳輸信息的能力來提高用戶對隱私風險的意識。
- 操作系統策略和工具。Android操作系統提供了內置的標準安全解決方案特性,如隔離、加密、內存管理以及用戶授予的手機資源和傳感器的權限。一旦用戶授予了權限,PII處理就完全由最佳實踐建議完成[44]。這可能包括對發送敏感信息(如通過互聯網的位置)的應用程序進行加密,或應用諸如PrivacyGuard[19]之類的工具,該工具是基于VPN的解決方案,可以檢測網絡流量上的數據泄漏,修改泄漏的信息以及將其替換為旨在保護隱私的數據。MockDroid[45]和LP-Guardian[46]等其他工具可用于阻止應用程序在運行時訪問位置傳感器。此外,未來的Android操作系統可以考慮通過允許用戶決定涉及敏感數據的后臺操作來改善隱私。
- 監控。文獻[8]提出了監視第三方安全提供商的網絡流量以檢測PII泄漏的方法,這對于識別濫用用戶私人信息的應用程序是一種有用的方法。所提出的Recon應用程序[8]還允許用戶用用戶選擇的另一個值替換傳輸的數據。
- 匿名化和PII混淆。文獻[47-53]提出了各種技術和算法來保證LBSs中的K匿名性。大多數方法都依賴于代理,它在將用戶的位置數據發送到LBS之前對其進行篩選、操作或泛化。當LBS需要精確或頻繁的定位樣本來提供服務時,這種方法很難應用。此外,這些技術沒有考慮到敵手訪問多個LBSs位置數據的唯一威脅模型。Puttaswamy等為了保護客戶端設備的隱私,提出LBSs應該將應用程序功能轉移到客戶端設備上。然而,這是不切實際的,因為在大多數情況下(特別是對于免費應用程序或第三方SDK),收集個人數據(如位置)是LBS的主要業務模型。
一種替代方法可以是安裝在移動設備上的應用程序形式,該應用程序監視網絡流量上的位置采樣或位置泄漏,并智能地注入欺騙性位置,這可能使威脅參與者難以推斷用戶的真實POI 。
由于一方面要向基于位置的應用程序或服務提供所需的位置數據,另一方面要保護用戶隱私,因此存在固有的權衡取舍,因此本文認為應采用以下一種隱私保護解決方案:
- (1)實施在操作系統級別,可以查看所有正在運行的應用程序,并且可以應用訪問控制策略以及混淆技術;
- (2)自動化程度低,用戶參與度低,決策過程簡單;
- (3)根據本文的研究建議,它不僅應該通過單個應用程序來分析隱私暴露級別,而且還應該從整體上看待網絡流量,以降低網絡竊聽者攻擊者的風險;
- (4)應用智能機器學習技術來自動識別位置數據和其他PII泄漏,從而對應用程序進行性能分析,以了解每個應用程序所需的位置數據的粒度級別,并智能地混淆從傳輸的數據推斷出的POIs。
由于本研究的實驗設置很復雜且耗費資源和時間,因此我們選擇保留防御方法的設計、開發和評估,尤其是將PII模糊處理作為對抗性學習方法應用于聚類算法[55],以備將來研究。
