TRUZZ:利用路徑轉換之間的差異優化覆蓋率引導灰盒模糊測試丨技術進展

基本信息
原文名稱 Path transitions tell more: optimizing fuzzing schedules via runtime program states
原文作者 Kunpeng Zhang;Xi Xiao;Xiaogang Zhu等
原文鏈接 https://dl.acm.org/doi/10.1145/3510003.35
10063
發表期刊 ICSE '22: Proceedings of the 44th International Conference on Software Engineering

一、引言
模糊測試是如今廣泛使用的一種漏洞挖掘技術,用于探測測試目標的安全問題。其中,基于覆蓋率引導的灰盒模糊測試(Coverage-guided Greybox Fuzzing, CGF)是目前最為典型的模糊測試方法,它根據種子的覆蓋率信息決定模糊測試過程中后續的選擇和變異,引導模糊測試探索更多的代碼覆蓋。現有的提高CGF效率的解決方案主要有兩種:①通過推斷輸入字節和路徑約束的關系來減少輸入的搜索空間;②通過設定模糊過程和建立概率分布來優化種子的能量調度。兩種方法都有各自的不足:前者屬于主觀推斷,推斷結果可能包含路徑約束外的額外字節;后者只關注于種子的能量調度,而忽略了種子中的字節調度。
本文結合以上兩種方案,提出了一種輕量級的CGF優化方案——Truzz,主要思想是利用路徑轉換之間的差異,從字節分析和種子優先級兩個方面優化CGF,做出了以下研究:
01
提出輕量級的CGF優化框架Truzz,利用可以指示目標程序屬性(如驗證檢查和未發現的代碼區域)的路徑差異來提高CGF的性能。
02
通過實驗驗證Truzz中字節分析調度的有效性,并設計對比實驗,比較引入Truzz框架的模糊器與原模糊器的性能,邊覆蓋率平均增加24.75%,識別了6個沒有被原模糊器探測出來的漏洞。
二、 路徑轉換間的差異
首先簡單介紹模糊測試中路徑轉換(Path Transition)的概念:設種子 的執行路徑為 , 變異生成 ,其執行路徑為 ,于是 與 之間存在一次路徑轉換。以圖1為例,路徑轉換中包含了大量的執行狀態信息,兩個執行路徑之間的差異可能含有被測試目標的一些屬性:
(1)如果路徑轉換導致路徑明顯縮短,該轉換很可能與驗證檢查相關。其中,驗證檢查(validation check)是指保護錯誤處理代碼(error-handling code)的路徑約束。例如圖1中的驗證檢查Ⅰ和驗證檢查Ⅱ分別保護了錯誤處理代碼Ⅰ和錯誤處理代碼Ⅱ。從圖中可以發現,如果一個輸入驗證檢查Ⅰ失敗,該輸入的執行路徑僅僅只有10條邊;但如果該輸入通過了驗證檢查Ⅰ,執行路徑的長度必定不止10條邊。與此同時,通過驗證檢查Ⅱ與否也會帶來這樣的結果。這是因為錯誤處理代碼往往會導致程序進程的提前終止,使得執行錯誤處理代碼的路徑比執行函數功能代碼的路徑短很多。
(2)如果路徑轉換發現了包含新邊的執行路徑,則說明其很可能會探索到未發現的區域。換言之,路徑中覆蓋更多新邊可能會引導模糊器找到更多未發現后代,觸及更多的新代碼區域。如圖1所示,如果一個種子的執行路徑為ACFJLN,其新邊為CF、FJ、JL、LN,則該路徑未被發現的基本塊有I、K、M、O、P;而另一個種子執行路徑為ABDG,其新邊為BD、DG,則該路徑未被發現的基本塊只有H。顯然,第一個種子具有探索更多未發現代碼區域的潛力。因此,在模糊過程中,對于執行路徑包含更多未發現的新邊的種子,給予其更高的優先級可能會進一步提高代碼覆蓋率。
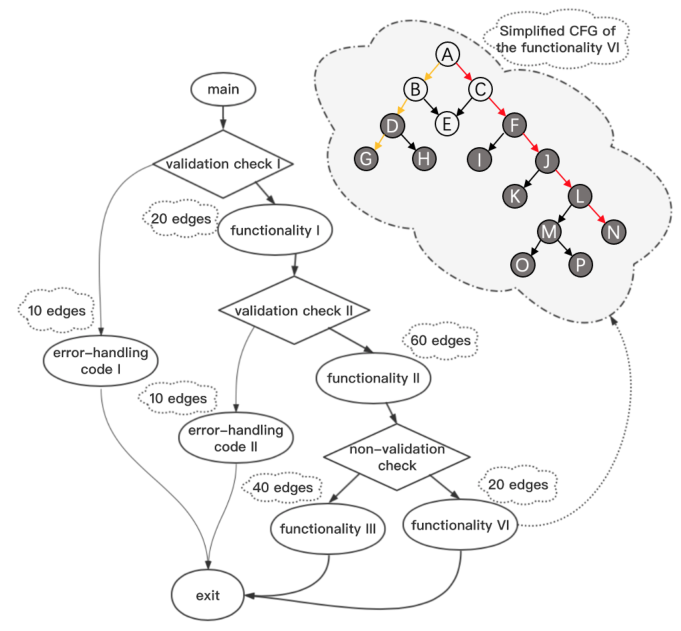
圖 1 路徑轉換間差異示例
舉一個例子以顯示模糊測試中對字節分析調度的需求。圖2為一段驗證檢查代碼,第2行是一個驗證檢查,保護了第8行的錯誤處理代碼。為了測試函數功能代碼,必須通過第二行的驗證檢查。圖2中輸入長度為5字節,如果單純使用隨機變異,可能會產生個新輸入,其中大部分都不能通過第2行的驗證檢查。如果模糊器可以推斷出第一個字節與驗證檢查相關,那么其最多只需要256次變異就可以繞過該約束。
然而,一般的基于推理的模糊器在推理約束的相關字節時,可能會由于推理依賴于執行狀態的變化,受到用于該路徑約束的額外字節的影響。例如圖2中第3行的約束條件會顯式受到變量b影響,隱式受到變量a影響,因此基于推理的模糊器的輸入與第3行的條件相關字節為input[0:4],這會導致模糊器在解析第3行約束時變異字節input[0],使得輸入可能最終流向錯誤處理代碼,導致進程提前終止。所以我們需要關注驗證檢查相關的input[0]字節變異,減少進程提前退出的概率,提高模糊測試效率。Truzz通過路徑轉換間的差異,識別與驗證檢查相關的字節,并在變異階段保護該字節以緩解上述問題。

圖 2 驗證檢查
三、 Truzz框架與方法
1 Truzz概述
Truzz是一個輕量級框架,沒有利用復雜的污點分析來獲取相關字節位置。如圖3所示,主要由字節分析和種子優先級兩部分構成,分別利用上述的路徑轉換間差異,針對與驗證檢查相關的字節和能發現更多新邊的種子,對CGF進行性能優化。Truzz會對每個種子進行排名,能夠發現更多新邊的種子具有更高的優先級。每當一個種子被選擇后,Truzz會執行字節分析,識別出于驗證檢查相關的字節,在隨后的變異階段,會給這些字節較低的變異概率。

圖 3 Truzz流程概述圖
2 字節分析
在字節分析階段,Truzz根據路徑轉換過程中兩種執行路徑之間的差異為輸入字節建立概率分布,并利用概率分布選擇要變異的字節。如果一個字節更可能與驗證檢查相關,則該字節在變異階段被選中的概率更低。Truzz會為選定種子的字節與驗證檢查的可能性度量為一個適應度值,以二分法優化字節分析的過程以提高效率,最后根據適應度值為字節分配一個變異概率。字節分析只對每個種子執行一次,在AFL框架下,主要是在確定性變異階段的bitflip中實現。
(1)字節適應度
上文分析已經指出,如果路徑轉換導致路徑明顯縮短,該轉換很可能與驗證檢查相關。為衡量一個字節與驗證檢查相關的可能性,Truzz首先會對每個字節進行變異,并根據路徑轉換的長度差異計算種子適應度。計算中路徑長度以路徑中邊的數目衡量,具體公式如下:
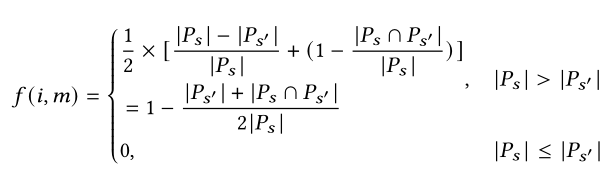
表示第 個字節到第 個字節的適應度。 和 為種子 和變異后種子 的執行路徑的長度,以該路徑的邊數衡量。 |
為執行路徑 和 的交集的邊的數量。從計算公式可以看出, 的值越大,代表兩次執行路徑的長度差異越大,即代表計算的這部分字節與驗證檢查更相關。
以圖1為例計算適應度 ,設種子 通過驗證檢查I和Ⅱ,執行函數功能代碼Ⅲ,則路徑長度 。
若變異字節 ,生成的種子通過了驗證檢查I但未通過驗證檢查Ⅱ,會執行錯誤處理代碼Ⅱ,路徑長度 。根據計算公式, 。
若變異字節 到 字節,生成的種子執行函數功能代碼Ⅵ,路徑長度 。根據計算公式, 。
對比發現 ,因此 字節相比 到 字節更可能與驗證檢查中的約束變量相關。
(2)二分法
程序中的驗證檢查比較稀疏,即只有小部分輸入字節與驗證檢查相關,大部分的輸入字節流入功能代碼中。因此,逐個字節地計算適應度相當耗時,本文使用二分法提高適應度計算的效率。具體算法如圖4所示。

圖 4 二分法計算適應度
簡單來說,二分字節區間,分別變異并計算區間適應度值:如果屬于當前段的字節變異導致適應度低于閾值(與驗證檢查無關)或段的大小已足夠小(精確到單字節),則將該段中所有字節設置為相同的適應度;否則繼續二分,直到識別出與驗證檢查相關的字節。每輪二分法中,Truzz最多能夠在一個變異輸入中處理一半的字節,因此是一種高效的字節適應度分配計算方法。
可以用圖3上半部分為例,較為形象地說明二分法。被選擇的種子為03AC,共四個字節。在字節分析階段,首先對前兩個字節03進行變異,生成新輸入3AAC。圖中可以看到變異前后種子執行路徑沒有改變,故前兩個種子適應度為0,肯定低于閾值。而對后兩個AC變異后生成新輸入03E1,執行路徑明顯縮短,計算出較大的適應度,因此繼續對該部分字節進行二分。按照相同方法,Truzz將AC字段分為A和C兩部分,推斷出最后一個字節C與驗證檢查相關。基于二分法,Truzz只需要進行約 次變異, 為種子的長度。
(3)字節變異概率
為了保護與驗證檢查相關的字節,Truzz會根據適應度為每個字節分配變異概率,決定是否變異當前字節,以小概率對驗證檢查相關的字節進行變異,盡可能減少執行錯誤處理代碼導致進程提前終止的情況,提高模糊測試效率。概率計算公式如下:
從計算公式可以看出,字節適應度越大,變異概率越小。同時,Truzz設置了一個概率下界 ,確保仍會以小概率生成驗證檢查失敗的輸入,避免漏掉類似checksum導致的漏洞。
3 種子優先級
根據上文研究,對于執行路徑包含更多未發現的新邊的種子,給予其更高的優先級可能會進一步提高代碼覆蓋率。因此,Truzz根據新發現的執行路徑中的新邊數對每個種子進行優先級排名,新邊的數量越多,選擇對應種子的優先級越高。Truzz會在模糊測試過程中動態地對每個種子的優先級排名進行更新,例如以AFL為框架的模糊器,Truzz會在每一輪fuzz_one后更新下輪模糊測試隊列。具體算法如圖5所示。

圖 5 種子優先級算法
該算法的重點是如何確定新邊數量。Truzz會初始化一個位圖 ,用于跟蹤所有歷史邊緣覆蓋。同時,對于所有初始種子,會對每個種子執行測試并將執行路徑記錄與位圖 中。對于種子執行的路徑位圖 , 以外的部分即代表該種子新發現路徑所對應的位圖,記錄所發現的新邊數目。Truzz把種子和其對應的新發現邊數記錄于M后,將當前位圖 合并到整體歷史位圖 中。Truzz會在每輪fuzz過程中迭代這個過程,不斷根據種子所發現新邊數維護種子優先級隊列。
四、 實驗設計及結果
(一)實驗目標
實驗階段主要通過回答以下三個問題來驗證Truzz的性能:
01
RQ1:字節分析在引導更多生成的輸入進入函數功能代碼方面是否有效?
02
RQ2:該框架提高模糊測試效率的效果如何?
03
RQ3:該框架可以(唯一)發現多少bug?
(二)實驗設置
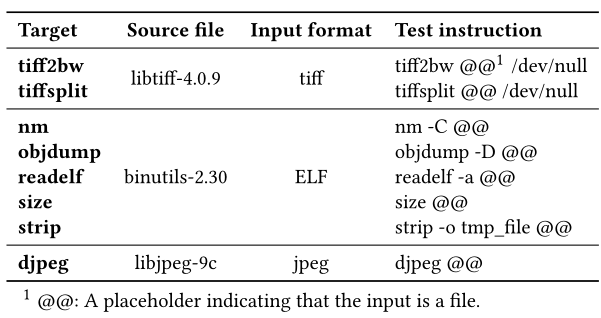
本實驗在NEUZZ、GreyOneFTI、AFL、AFLFast、MOPT、FuzzFactory六個模糊器上集成Truzz,并將其性能與相應的原模糊器進行對比。在8個目標程序運行每個模糊器24小時,重復實驗5次。需要注意的是,NEUZZ和GreyOne是基于推理的模糊器,可以推斷字節約束關系解析約束。測試目標程序如表1所示。
所有實驗的環境都是Ubuntu 18.04、Intel(R) Xeon(R) Gold 6230R CPU與4個NVIDIA GeForce RTX 2080 Ti gpu。
表 1 目標程序
(三)具體實驗
1 RQ1:字節分析的有效性
Truzz使用字節分析識別與驗證檢查相關的字節,更少地更改與驗證檢查相關的字節,因此Truzz嚴重依賴于字節分析的準確性。
本實驗將分析Truzz字節分析的準確性:手動分析實驗中使用的5個程序,標記這些程序中所有的錯誤處理路徑,程序包括nm、objdump、readelf、size、strip。分析方法上,掃描每個錯誤函數的定義,并檢查它們是否可以通過返回錯誤代碼或空指針觸發錯誤。每次生成和執行變異輸入時,需要確定輸入是否執行錯誤處理路徑,并在模糊處理期間計算這些路徑數量。如果一個輸入通過所有的驗證檢查并沒有觸發任何錯誤處理代碼,則被認為是有效的。
為避免種子優先級對結果的影響,本實驗只使用字節分析實現Truzz,以NEUZZ和TRUZZ(NEUZZ)為例說明字節分析準確性。實驗結果如表2所示,TRUZZ(NEUZZ)生成的有效樣本平均比NEUZZ多16.14%,其中nm和objdump提升效果最為明顯。
表 2 字節分析有效性實驗對比

實驗表明,在相同的實驗條件下,Truzz相比原模糊器可以產生更多有效樣本。
2 RQ2:代碼覆蓋率發現
在八個程序運行兩個版本模糊器,持續24小時(5次),利用AFL的AFL-showmap計算代碼覆蓋率,比較邊覆蓋率。如圖6所示,除tiff2bw和tiffsplit,配置Truzz的模糊器實現了更好的邊覆蓋。
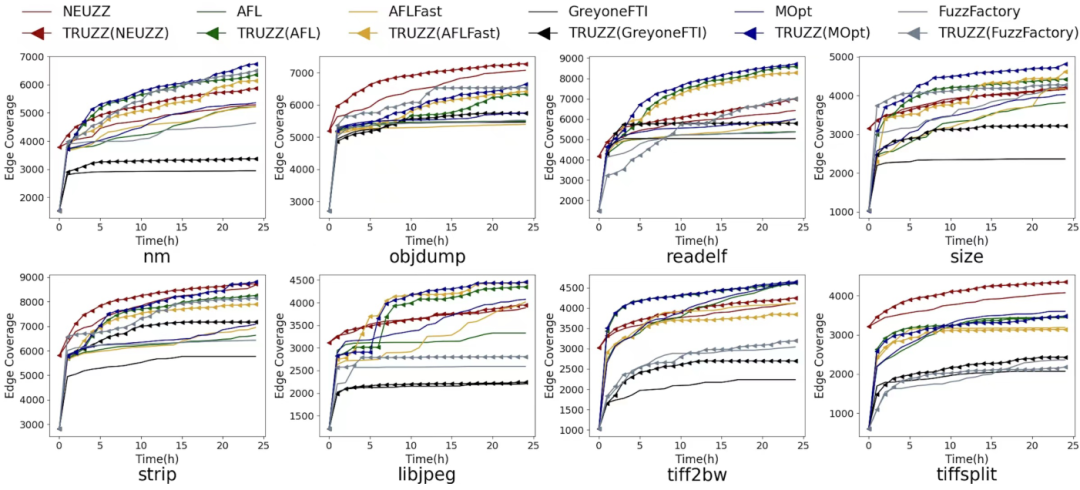
圖 6 不同模糊器針對8個程序運行24小時的邊覆蓋
其次,比較配置Truzz的模糊器和原模糊器的新邊發現數。如表2所示,配置Truzz的模糊器發現的新邊比原模糊器平均多24.75%。然而,在Truzz中分別進行字節分析和種子優先級排序實驗,發現字節分析對于性能的提高只對基于推理的模糊器較為有效,如表4所示。
表 3 不同模糊器運行24小時的發現新邊數

表 4 字節分析和種子優先級排序分別對新邊發現數的影響

實驗表明,Truzz可以顯著提高覆蓋率和新邊發現數,且字節分析更適合基于推理的模糊器(如NEUZZ和Greyone)。
3 RQ3:bug發現
本實驗比較配置Truzz的模糊器和原模糊器發現真實程序的bug的能力。使用GDB和afl-collect分析模糊器發現bug的數量:
01
使用afl-collect去除無效crash樣本,實現去冗余。
02
使用gdb手動分析每個bug的程序邏輯,刪除具有相同根源的bug。
表5顯示了在真實程序中發現unique crash(在5次運行中累計)的數量,原模糊器和配置Truzz的模糊器分別在四個應用程序發現10個和13個crash,剩下四個程序中,所有模糊器在24小時內無法識別出漏洞。
表 5 不同模糊器發現bug的數量

實驗表明,配置Truzz的模糊器發現bug的能力優于原模糊器,在實驗中識別了8個目標程序的13個crash,其中6個是原模糊器無法識別的。
五、 總結
本文主要針對CGF優化這一研究目標,利用路徑轉換間的差異,識別能夠探索更多新邊的種子以及種子中與驗證檢查相關的字節,改進字節調度和種子優先級排名,實現了CGF性能的優化。然而,Truzz存在一定的局限性,這些局限性主要存在于字節分析這部分,有以下兩點:
01
字節分析在模糊器性能的提升上對基于推理的模糊器更起作用,對普通的以AFL為框架的模糊器的性能提升效果并不好。第一個原因是基于推理的模糊器能夠選出“有趣的輸入”進行變異,這在一定程度上避免了初始字節可能已經指向錯誤處理代碼的情況,而普通的模糊器可能存在初始輸入直接執行錯誤處理代碼,影響字節分析的問題。第二個原因是以AFL為框架的模糊器在字節分析上依賴于確定性階段的bitflip變異,目前研究已經表明確定性變異本身性能就不如非確定性變異,進入確定性階段會調用其他變異方式,影響模糊測試過程的效率。
02
字節分析僅僅根據路徑長度來判定與驗證檢查相關的字節。然而,如果程序在錯誤處理代碼具有復雜邏輯,這種方法可能無法正確識別與驗證檢查相關的字節。
參考文獻
1.
Zhang K, Xiao X, Zhu X, et al. Path Transitions Tell More: Optimizing Fuzzing Schedules via Runtime Program States[J]. arXiv preprint arXiv:2201.04441, 2022.
2.
Michal Zalewski. American Fuzzy Lop (2.52b). http://lcamtuf.coredump.cx/afl, 2019.
3.
She D, Pei K, Epstein D, et al. Neuzz: Efficient fuzzing with neural program smoothing[C]//2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019: 803-817.
4.
Gan S, Zhang C, Chen P, et al. {GREYONE}: Data flow sensitive fuzzing[C]//29th USENIX Security Symposium (USENIX Security 20). 2020: 2577-2594.
5.
Lyu C, Ji S, Zhang C, et al. {MOPT}: Optimized mutation scheduling for fuzzers[C]//28th USENIX Security Symposium (USENIX Security 19). 2019: 1949-1966.
6.
Padhye R, Lemieux C, Sen K, et al. Fuzzfactory: domain-specific fuzzing with waypoints[J]. Proceedings of the ACM on Programming Languages, 2019, 3(OOPSLA): 1-29.







