Tomcat文件上傳流量層面繞waf新姿勢
無意中看到ch1ng師傅的文章覺得很有趣,不得不感嘆師傅太厲害了,但我一看那長篇的函數總覺得會有更騷的東西,所幸還真的有,借此機會就發出來一探究竟,同時也不得不感慨下RFC文檔的妙處,當然本文針對的技術也僅僅只是在流量層面上waf的繞過。
Pre
很神奇對吧,當然這不是終點,接下來我們就來一探究竟。
前置
這里簡單說一下師傅的思路
部署與處理上傳war的servlet是 org.apache.catalina.manager.HTMLManagerServlet
在文件上傳時最終會通過處理 org.apache.catalina.manager.HTMLManagerServlet#upload

調用的是其子類實現類org.apache.catalina.core.ApplicationPart#getSubmittedFileName
這里獲取filename的時候的處理很有趣

看到這段注釋,發現在RFC 6266文檔當中也提出這點
1 Avoid including the "\" character in the quoted-string form of the filename parameter, as escaping is not implemented by some user agents, and "\" can be considered an illegal path character.
那么我們的tomcat是如何處理的嘞?這里它通過函數HttpParser.unquote去進行處理。
public static String unquote(String input) {
if (input == null || input.length() < 2) {
return input;
}
int start;
int end;
// Skip surrounding quotes if there are any
if (input.charAt(0) == '"') {
start = 1;
end = input.length() - 1;
} else {
start = 0;
end = input.length();
}
StringBuilder result = new StringBuilder();
for (int i = start ; i < end; i++) {
char c = input.charAt(i);
if (input.charAt(i) == '\\') {
i++;
result.append(input.charAt(i));
} else {
result.append(c);
}
}
return result.toString();
}
簡單做個總結。
如果首位是"(前提條件是里面有\字符),那么就會去掉跳過從第二個字符開始,并且末尾也會往前移動一位,同時會忽略字符\,師傅只提到了類似test.\war這樣的例子。
但其實根據這個我們還可以進一步構造一些看著比較惡心的比如 filename=""y\4.\w\arK" 。
深入
還是在 org.apache.catalina.core.ApplicationPart#getSubmittedFileName當中,一看到這個將字符串轉換成map的操作總覺得里面會有更騷的東西(這里先是解析傳入的參數再獲取,如果解析過程有利用點那么也會影響到后面參數獲取),不扯遠繼續回到正題

首先它會獲取header參數Content-Disposition當中的值,如果以form-data或者attachment開頭就會進行我們的解析操作,跟進去一看果不其然,看到RFC2231Utility瞬間不困了
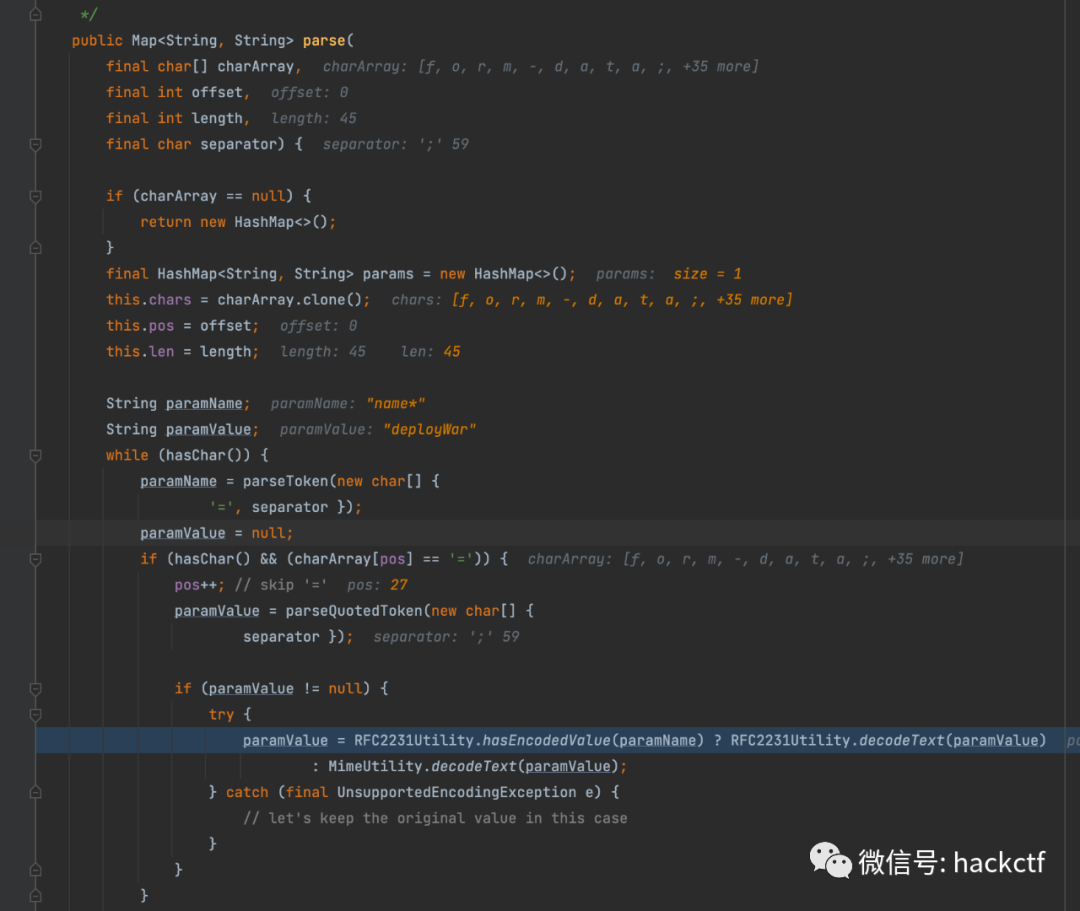
后面這一坨就不必多說了,相信大家已經很熟悉啦支持QP編碼,忘了的可以考古看看我之前寫的文章Java文件上傳大殺器-繞waf(針對commons-fileupload組件),這里就不再重復這個啦,我們重點看三元運算符前面的這段
既然如此,我們先來看看這個hasEncodedValue判斷標準是什么,字符串末尾是否帶*
1 public static boolean hasEncodedValue(final String paramName) {
2 if (paramName != null) {
3 return paramName.lastIndexOf('*') == (paramName.length() - 1);
4 }
5 return false;
6 }
在看解密函數之前我們可以先看看RFC 2231文檔當中對此的描述,英文倒是很簡單不懂的可以在線翻一下,這里就不貼中文了
Asterisks ("*") are reused to provide the indicator that language and character set 2 information is present and encoding is being used. A single quote ("'") is used to delimit the character set and language information at the beginning of the parameter value. Percent signs ("%") are used as the encoding flag, which agrees with RFC 2047.
Specifically, an asterisk at the end of a parameter name acts as an indicator that character set and language information may appear at the beginning of the parameter value. A single quote is used to separate the character set, language, and actual value information in the parameter value string, and an percent sign is used to flag octets encoded in hexadecimal. For example:
Content-Type: application/x-stuff;
title*=us-ascii'en-us'This%20is%20%2A%2A%2Afun%2A%2A%2A
接下來回到正題,我們繼續看看這個解碼做了些什么
public static String decodeText(final String encodedText) throws UnsupportedEncodingException {
final int langDelimitStart = encodedText.indexOf('\'');
if (langDelimitStart == -1) {
// missing charset
return encodedText;
}
final String mimeCharset = encodedText.substring(0, langDelimitStart);
final int langDelimitEnd = encodedText.indexOf('\'', langDelimitStart + 1);
if (langDelimitEnd == -1) {
// missing language
return encodedText;
}
final byte[] bytes = fromHex(encodedText.substring(langDelimitEnd + 1));
return new String(bytes, getJavaCharset(mimeCharset));
}
結合注釋可以看到標準格式@param encodedText - Text to be decoded has a format of {@code ''},分別是編碼,語言和待解碼的字符串,同時這里還適配了對url編碼的解碼,也就是fromHex函數,具體代碼如下,其實就是url解碼
private static byte[] fromHex(final String text) {
final int shift = 4;
final ByteArrayOutputStream out = new ByteArrayOutputStream(text.length());
for (int i = 0; i < text.length();) {
final char c = text.charAt(i++);
if (c == '%') {
if (i > text.length() - 2) {
break; // unterminated sequence
}
final byte b1 = HEX_DECODE[text.charAt(i++) & MASK];
final byte b2 = HEX_DECODE[text.charAt(i++) & MASK];
out.write((b1 << shift) | b2);
} else {
out.write((byte) c);
}
}
return out.toByteArray();
}
因此我們將值當中值得注意的點梳理一下
- 支持編碼的解碼
- 值當中可以進行url編碼
- @code'' 中間這位language可以隨便寫,代碼里沒有用到這個的處理
既然如此那么我們首先就可以排出掉utf-8,畢竟這個解碼后就直接是明文,從Java標準庫當中的charsets.jar可以看出,支持的編碼有很多
同時通過簡單的代碼也可以輸出
Locale locale = Locale.getDefault();
Map<String, Charset> maps = Charset.availableCharsets();
StringBuilder sb = new StringBuilder();
sb.append("{");
for (Map.Entry<String, Charset> entry : maps.entrySet()) {
String key = entry.getKey();
Charset value = entry.getValue();
sb.append("\"" + key + "\",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("}");
System.out.println(sb.toString());
運行輸出
//res
{"Big5","Big5-HKSCS","CESU-8","EUC-JP","EUC-KR","GB18030","GB2312","GBK","IBM-Thai","IBM00858","IBM01140","IBM01141","IBM01142","IBM01143","IBM01144","IBM01145","IBM01146","IBM01147","IBM01148","IBM01149","IBM037","IBM1026","IBM1047","IBM273","IBM277","IBM278","IBM280","IBM284","IBM285","IBM290","IBM297","IBM420","IBM424","IBM437","IBM500","IBM775","IBM850","IBM852","IBM855","IBM857","IBM860","IBM861","IBM862","IBM863","IBM864","IBM865","IBM866","IBM868","IBM869","IBM870","IBM871","IBM918","ISO-2022-CN","ISO-2022-JP","ISO-2022-JP-2","ISO-2022-KR","ISO-8859-1","ISO-8859-13","ISO-8859-15","ISO-8859-2","ISO-8859-3","ISO-8859-4","ISO-8859-5","ISO-8859-6","ISO-8859-7","ISO-8859-8","ISO-8859-9","JIS_X0201","JIS_X0212-1990","KOI8-R","KOI8-U","Shift_JIS","TIS-620","US-ASCII","UTF-16","UTF-16BE","UTF-16LE","UTF-32","UTF-32BE","UTF-32LE","UTF-8","windows-1250","windows-1251","windows-1252","windows-1253","windows-1254","windows-1255","windows-1256","windows-1257","windows-1258","windows-31j","x-Big5-HKSCS-2001","x-Big5-Solaris","x-COMPOUND_TEXT","x-euc-jp-linux","x-EUC-TW","x-eucJP-Open","x-IBM1006","x-IBM1025","x-IBM1046","x-IBM1097","x-IBM1098","x-IBM1112","x-IBM1122","x-IBM1123","x-IBM1124","x-IBM1166","x-IBM1364","x-IBM1381","x-IBM1383","x-IBM300","x-IBM33722","x-IBM737","x-IBM833","x-IBM834","x-IBM856","x-IBM874","x-IBM875","x-IBM921","x-IBM922","x-IBM930","x-IBM933","x-IBM935","x-IBM937","x-IBM939","x-IBM942","x-IBM942C","x-IBM943","x-IBM943C","x-IBM948","x-IBM949","x-IBM949C","x-IBM950","x-IBM964","x-IBM970","x-ISCII91","x-ISO-2022-CN-CNS","x-ISO-2022-CN-GB","x-iso-8859-11","x-JIS0208","x-JISAutoDetect","x-Johab","x-MacArabic","x-MacCentralEurope","x-MacCroatian","x-MacCyrillic","x-MacDingbat","x-MacGreek","x-MacHebrew","x-MacIceland","x-MacRoman","x-MacRomania","x-MacSymbol","x-MacThai","x-MacTurkish","x-MacUkraine","x-MS932_0213","x-MS950-HKSCS","x-MS950-HKSCS-XP","x-mswin-936","x-PCK","x-SJIS_0213","x-UTF-16LE-BOM","X-UTF-32BE-BOM","X-UTF-32LE-BOM","x-windows-50220","x-windows-50221","x-windows-874","x-windows-949","x-windows-950","x-windows-iso2022jp"}
這里作為掩飾我就隨便選一個了UTF-16BE

同樣的我們也可以進行套娃結合上面的filename=""y\4.\w\arK"改成filename="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"
接下來處理點小加強,可以看到在這里分隔符無限加,而且加了?號的字符之后也會去除一個?號
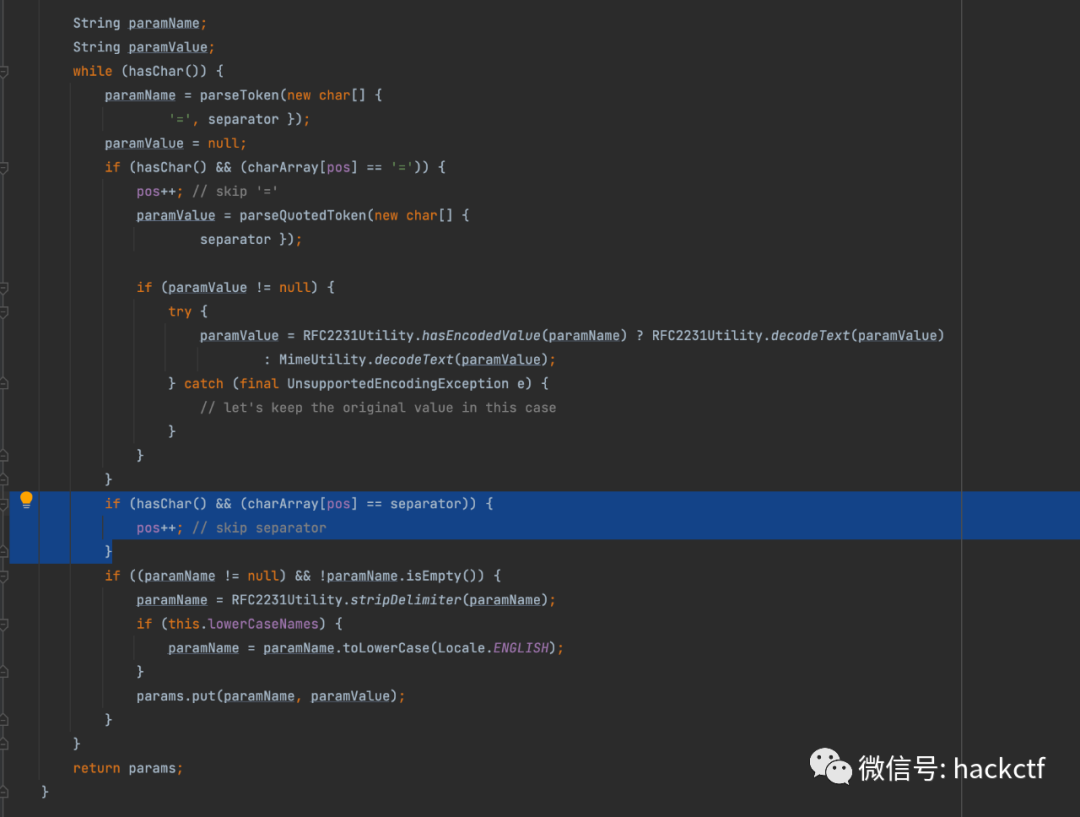
因此我們最終可以得到如下payload,此時僅僅基于正則的waf規則就很有可能會失效
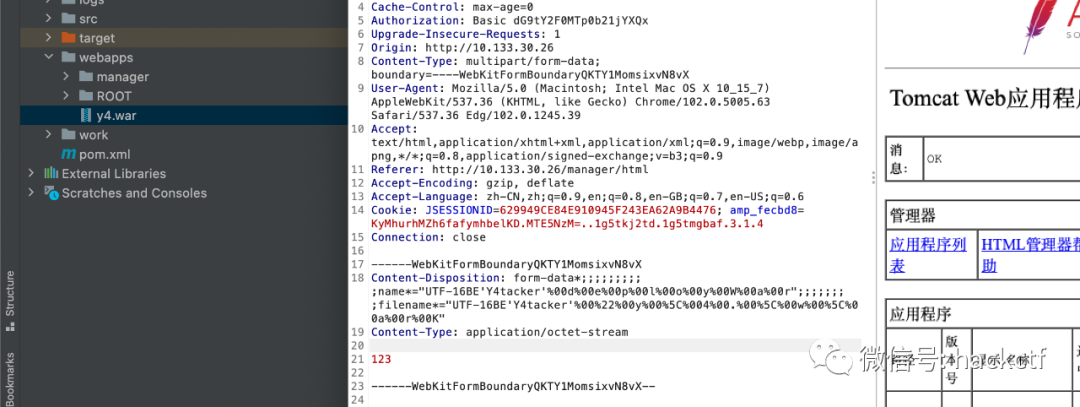
------WebKitFormBoundaryQKTY1MomsixvN8vX Content-Disposition: form-data*;;;;;;;;;;name*="UTF-16BE'Y4tacker'%00d%00e%00p%00l%00o%00y%00W%00a%00r";;;;;;;;filename*="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K" Content-Type: application/octet-stream 123 ------WebKitFormBoundaryQKTY1MomsixvN8vX--
可以看見成功上傳

變形 更新2022-06-20
這里測試版本是Tomcat8.5.72,這里也不想再測其他版本差異了只是提供一種思路
在此基礎上我發現還可以做一些新的東西,其實就是對org.apache.tomcat.util.http.fileupload.ParameterParser#parse(char[], int, int, char)函數進行深入分析
在獲取值的時候paramValue = parseQuotedToken(new char[] {separator });,其實是按照分隔符;分割,因此我們不難想到前面的東西其實可以不用"進行包裹,在parseQuotedToken最后返回調用的是return getToken(true);,這個函數也很簡單就不必多解釋
private String getToken(final boolean quoted) {
// Trim leading white spaces
while ((i1 < i2) && (Character.isWhitespace(chars[i1]))) {
i1++;
}
// Trim trailing white spaces
while ((i2 > i1) && (Character.isWhitespace(chars[i2 - 1]))) {
i2--;
}
// Strip away quotation marks if necessary
if (quoted
&& ((i2 - i1) >= 2)
&& (chars[i1] == '"')
&& (chars[i2 - 1] == '"')) {
i1++;
i2--;
}
String result = null;
if (i2 > i1) {
result = new String(chars, i1, i2 - i1);
}
return result;
}
可以看到這里也是成功識別的

既然調用parse解析參數時可以不被包裹,結合getToken函數我們可以知道在最后一個參數其實就不必要加;了,并且解析完通過params.get("filename")獲取到參數后還會調用到org.apache.tomcat.util.http.parser.HttpParser#unquote那也可以基于此再次變形
為了直觀這里就直接明文了,是不是也很神奇
擴大利用面
現在只是war包的場景,多多少少影響性被降低,但我們這串代碼其實抽象出來就一個關鍵
Part warPart = request.getPart("deployWar");
String filename = warPart.getSubmittedFileName();
通過查詢官方文檔,可以發現從Servlet3.1開始,tomcat新增了對此的支持,也就意味著簡單通過javax.servlet.http.HttpServletRequest#getParts即可,簡化了我們文件上傳的代碼負擔(如果我是開發人員,我肯定首選也會使用,誰不想當懶狗呢)
getSubmittedFileName String getSubmittedFileName() Gets the file name specified by the client Returns: the submitted file name Since: Servlet 3.1
更新Spring 2022-06-20
早上起床想著昨晚和陳師的碰撞,起床后又看了下陳師的星球,看到這個不妨再試試Spring是否也按照了RFC的實現呢(畢竟Spring內置了Tomcat,可能會有類似的呢)
Spring為我們提供了處理文件上傳MultipartFile的接口
public interface MultipartFile extends InputStreamSource {
String getName(); //獲取參數名
@Nullable
String getOriginalFilename();//原始的文件名
@Nullable
String getContentType();//內容類型
boolean isEmpty();
long getSize(); //大小
byte[] getBytes() throws IOException;// 獲取字節數組
InputStream getInputStream() throws IOException;//以流方式進行讀取
default Resource getResource() {
return new MultipartFileResource(this);
}
// 將上傳的文件寫入文件系統
void transferTo(File var1) throws IOException, IllegalStateException;
// 寫入指定path
default void transferTo(Path dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.getInputStream(), Files.newOutputStream(dest));
}
}
而spring處理文件上傳邏輯的具體關鍵邏輯在org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest,抄個文件上傳demo來進行測試分析
Spring4
這里我測試了springboot1.5.20.RELEASE內置Spring4.3.23,具體小版本之間是否有差異這里就不再探究
其中關于org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest的調用也有些不同
private void parseRequest(HttpServletRequest request) {
try {
Collection parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
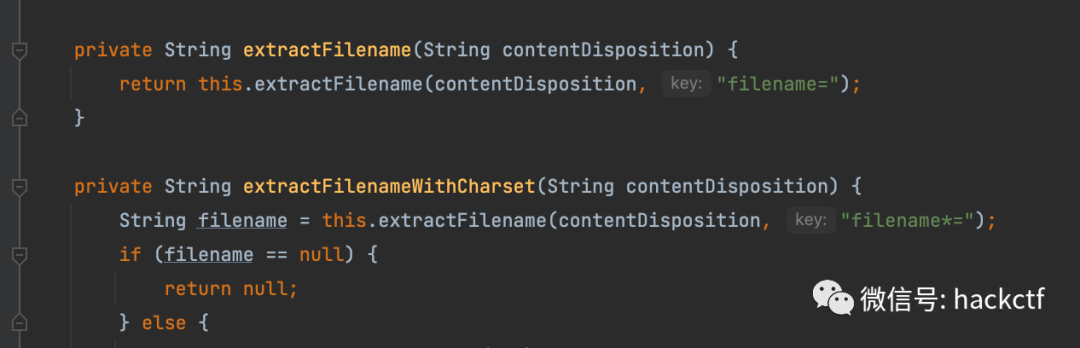
String disposition = part.getHeader("content-disposition");
String filename = this.extractFilename(disposition);
if (filename == null) {
filename = this.extractFilenameWithCharset(disposition);
}
if (filename != null) {
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var8) {
throw new MultipartException("Could not parse multipart servlet request", var8);
}
}
簡單看了下和tomcat之前的分析很像,這里Spring4當中同時也是支持filename*格式的
看看具體邏輯
private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
//截取filename=后面的內容
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
//如果后面開頭是“則截取”“之間的內容
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
//可以看到如果沒有“”包裹其實也可以,這和當時陳師分享的其中一個trick是符合的
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}
簡單測試一波,與心中結果一致
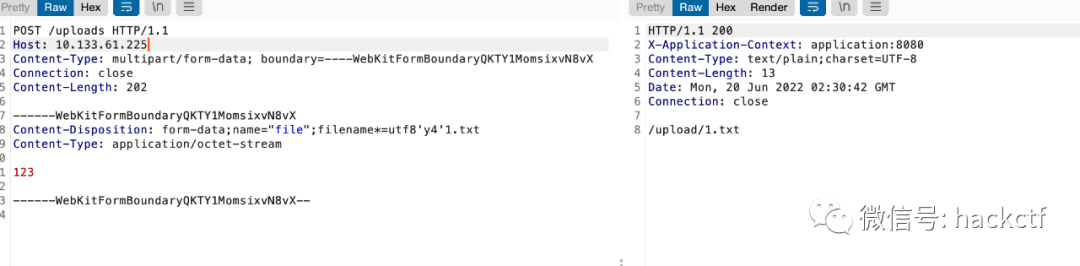
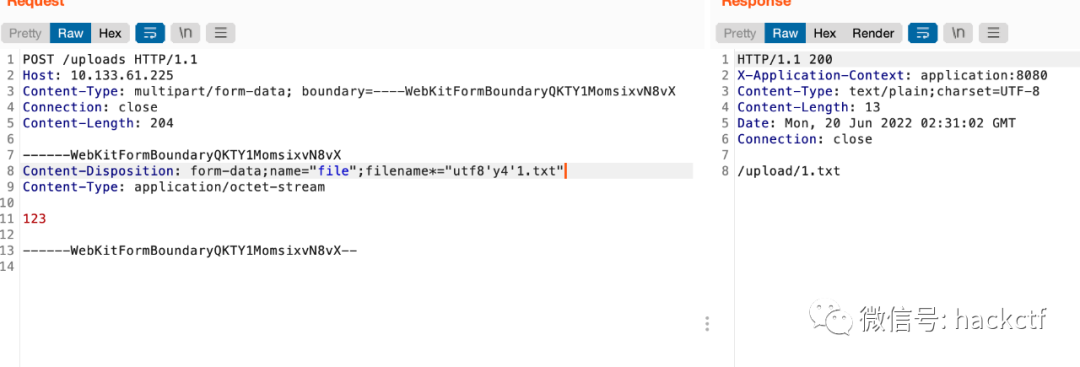
同時由于indexof默認取第一位,因此我們還可以加一些干擾字符嘗試突破waf邏輯
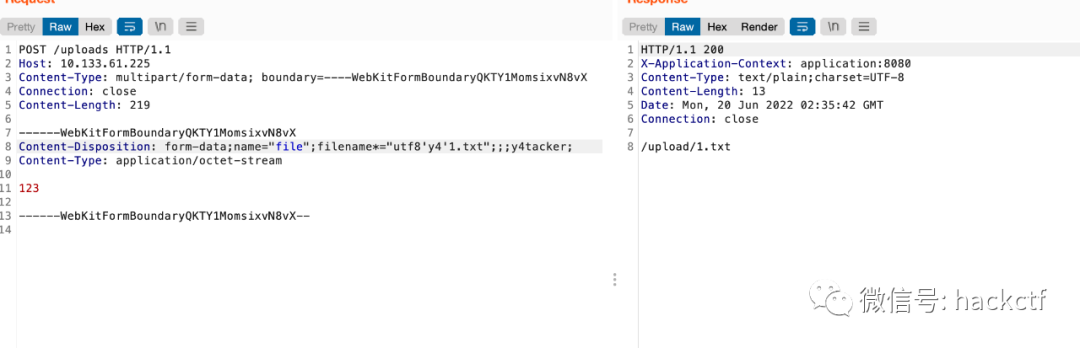
如果filename*開頭但是spring4當中沒有關于url解碼的部分
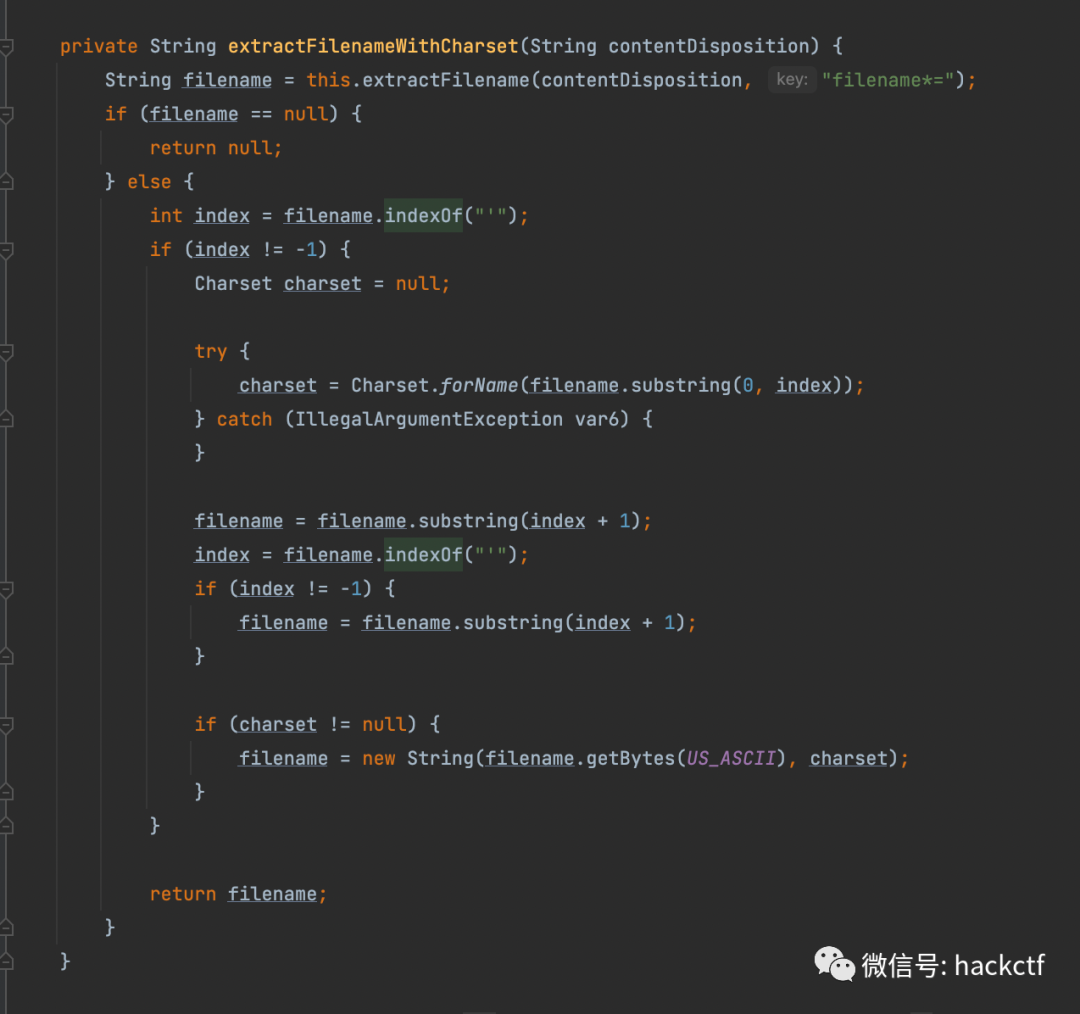
沒有這部分會出現什么呢?我們只能自己發包前解碼,這樣的話如果出現00字節就會報錯,報錯后
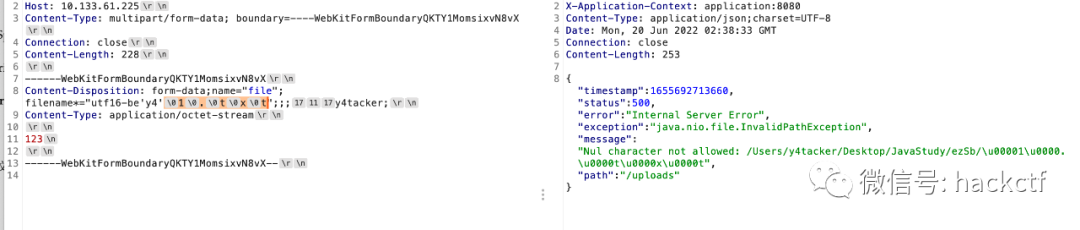
看起來是spring框架解析header的原因,但是這里報錯信息也很有趣將項目地址的絕對路徑拋出了,感覺不失為信息收集的一種方式
Spring5
也是隨便來個新的springboot2.6.4的,來看看spring5的,小版本間差異不測了,經過測試發現spring5和spring4之間也是有版本差異處理也有些不同,同樣是在parseRequest
private void parseRequest(HttpServletRequest request) {
try {
Collection parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
String headerValue = part.getHeader("Content-Disposition");
ContentDisposition disposition = ContentDisposition.parse(headerValue);
String filename = disposition.getFilename();
if (filename != null) {
if (filename.startsWith("=?") && filename.endsWith("?=")) {
filename = StandardMultipartHttpServletRequest.MimeDelegate.decode(filename);
}
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var9) {
this.handleParseFailure(var9);
}
}
很明顯可以看到這一行filename.startsWith("=?") && filename.endsWith("?="),可以看出Spring對文件名也是支持QP編碼
在上面能看到還調用了一個解析的方法org.springframework.http.ContentDisposition#parse
,多半就是這里了,那么繼續深入下
可以看到一方面是QP編碼,另一方面也是支持filename*,同樣獲取值是截取"之間的或者沒找到就直接截取=后面的部分
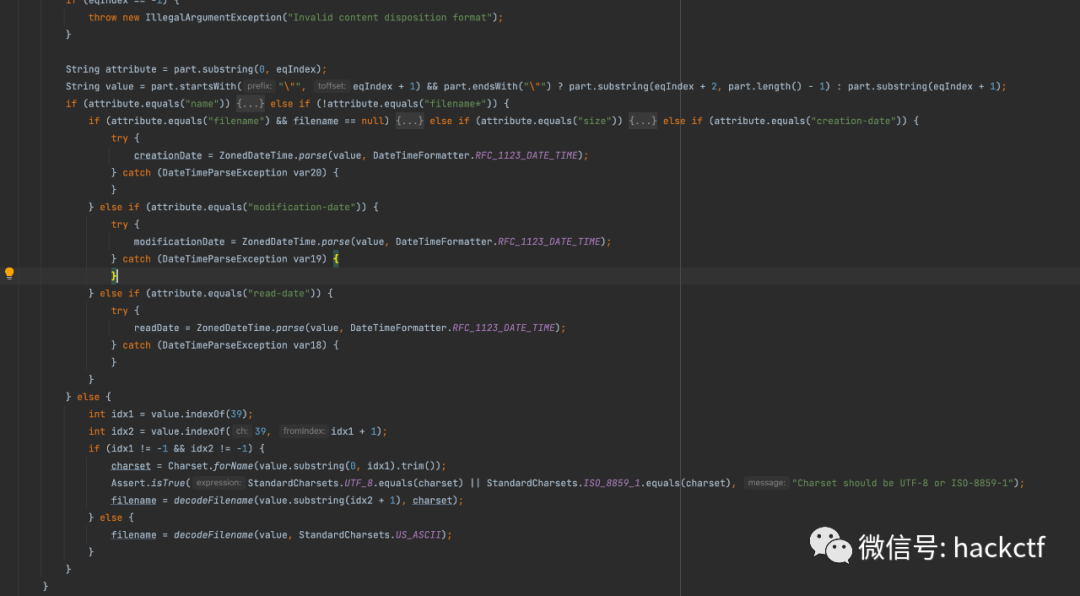
如果是filename*后面的處理邏輯就是else分之,可以看出和我們上面分析spring4還是有點區別就是這里只支持UTF-8/ISO-8859-1/US_ASCII,編碼受限制
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}
但其實仔細想這個結果是符合RFC文檔要求的

接著我們繼續后面會繼續執行decodeFilename
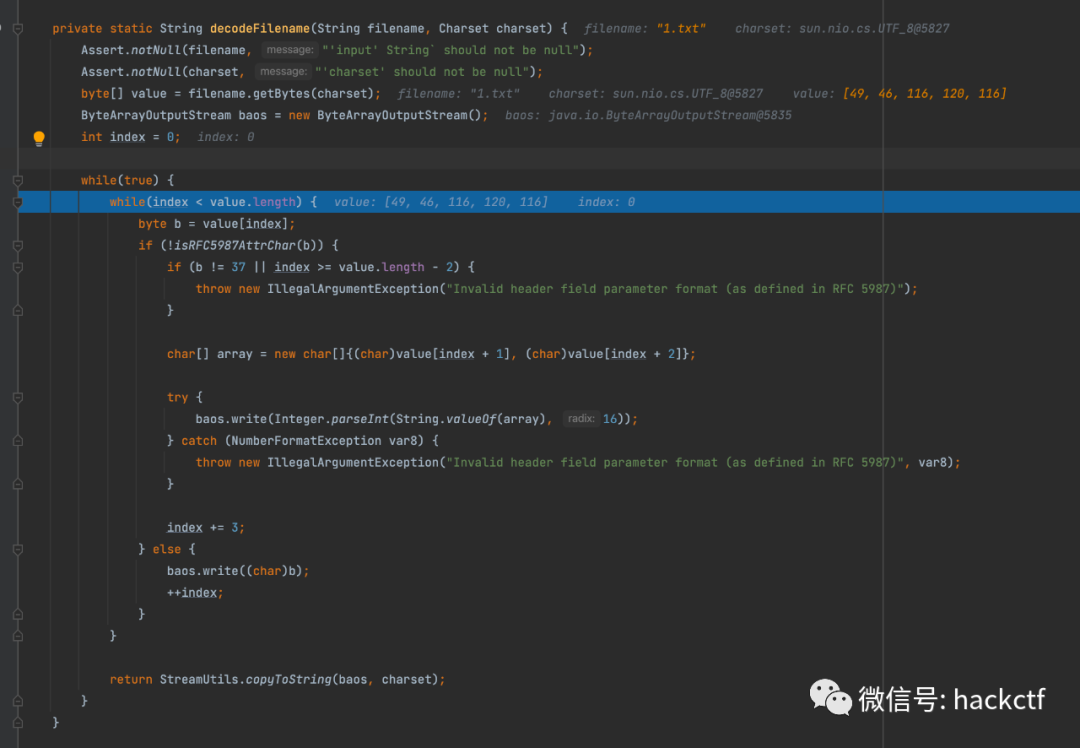
代碼邏輯很清晰字符串的解碼,如果字符串是否在RFC 5987文檔規定的Header字符就直接調用baos.write寫入
attr-char = ALPHA / DIGIT
/ "!" / "#" / "$" / "&" / "+" / "-" / "."
/ "^" / "_" / "`" / "|" / "~"
; token except ( "*" / "'" / "%" )
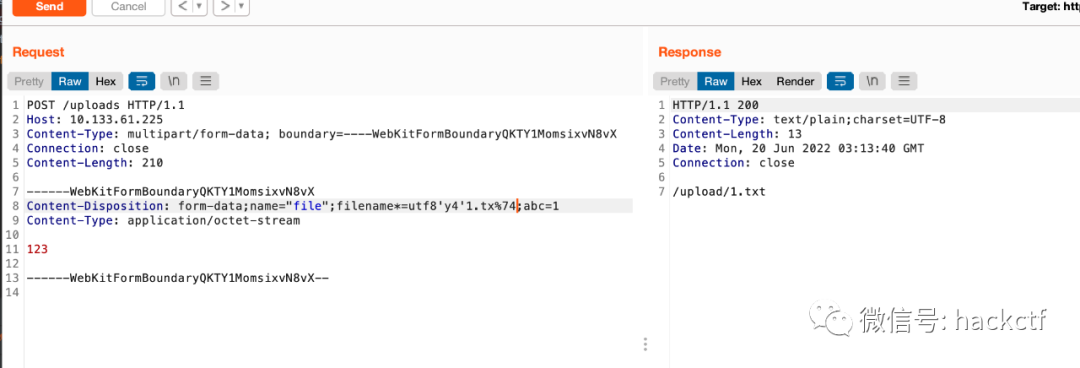
如果不在要求這一位必須是%然后16進制解碼后兩位,其實就是url解碼,簡單測試即可
參考文章
https://www.ch1ng.com/blog/264.htmlhttps://datatracker.ietf.org/doc/html/rfc6266#section-4.3https://datatracker.ietf.org/doc/html/rfc2231https://datatracker.ietf.org/doc/html/rfc5987#section-3.2.1https://y4tacker.github.io/2022/02/25/year/2022/2/Java%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E5%A4%A7%E6%9D%80%E5%99%A8-%E7%BB%95waf(%E9%92%88%E5%AF%B9commons-fileupload%E7%BB%84%E4%BB%B6)/https://docs.oracle.com/javaee/7/api/javax/servlet/http/Part.html#getSubmittedFileName--http://t.zoukankan.com/summerday152-p-13969452.html#%E4%BA%8C%E3%80%81%E5%A4%84%E7%90%86%E4%B8%8A%E4%BC%A0%E6%96%87%E4%BB%B6multipartfile%E6%8E%A5%E5%8F%A3
