基于統一結構生成的網安信息抽取研究
一、什么是信息抽取
信息抽取 (Information Extraction,IE)是將文本里的非結構信息轉化成結構化信息的過程。在網安領域,IE技術可以從紛雜的文章、博客和評論中抽取與網安相關的網絡威脅信息,該技術對實現情報交換、輿情分析、熱度預測、知識圖譜構建等任務均有重要影響。
信息抽取包含三個子任務,其中,命名實體識別(Named Entity Recognition,NER)找句子中的實體詞;關系抽取(Relation Extraction,RE)找句子中的頭實體、關系類型、尾實體;事件抽取 (Event Extraction,EE)找句子中的觸發詞以及觸發詞對應的論元。傳統的IE對3個子任務分別建模,任務之間的關聯性弱,相互協作的能力較差。為此,Lu等人提出了一種基于統一結構生成的信息抽取模型(Universal Information Extraction,UIE),該模型對不同的抽取任務統一建模,利用資源共享有效提升了信息抽取的能力。
對于網安領域而言,除了使用統一式的信息抽取模型,還有需要對部分細節進行設計。如:網安領域的實體、關系和事件的定義、適用于網安領域的prompt模板設計等。本文針對網安領域的信息抽取任務進行討論,分別介紹本體構建、UIE模型以及算法效果和應用三部分。
二、本體構建
采用自底向上的方式,構建了網安領域知識圖譜的本體模式。本體構建包含實體定義、關系定義、事件和論元定義等方面。
①實體定義:結合STIX和開源網安數據集,從各渠道提取、融合實體類型。具體而言,由于各數據集下的實體類型命名和定義有所區別,故需要對不同的實體類型進行統一,如合并不同實體命名,刪除無關實體。得到的部分網安領域實體類型如表1所示。
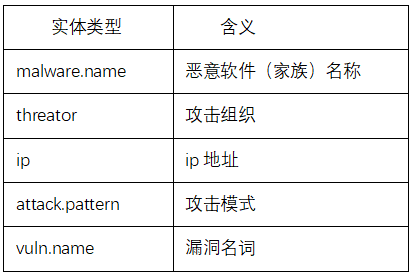
表1 實體定義
②關系定義:定義實體之間的關系,且衍生出了他們的反向關系,用于后期方便識別頭尾實體。如表2所示,subject_type和object_type分別表示頭實體和尾實體的類型。如攻擊組織對漏洞的“目標”關系,攻擊組織對惡意軟件的“使用”關系,惡意軟件對ip的“關聯”關系。
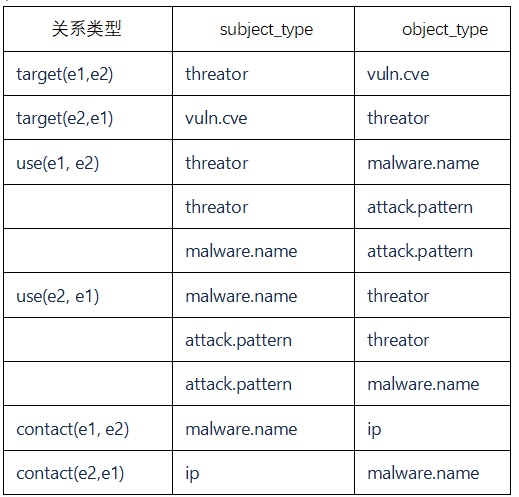
表2 關系定義
③事件和論元定義:使用CASIE數據集對事件和論元的定義。事件是指某一個網絡安全事件,包含網絡釣魚、補丁漏洞、披露漏洞、databreach、ransom等。而論元是事件的參與者,主要由實體、值、時間組成,如位置、受害者、攻擊模式、工具、支付方式等。如圖1所示為事件ransom和databreach對應的論元,可以看到兩者是一對多的關系。

圖1 事件ransom和databreach對應的論元
三、UIE模型
3.1模型背景
信息抽取是NLP技術落地中必不可少的環節,然而當前市面上的信息抽取工具大多基于傳統算法構建,偏向學術研究,對實際使用并不友好。產業級信息抽取面臨的挑戰主要包含①通用領域知識很難遷移到專業領域,②針對實體、關系、事件等不同任務需開發不同的模型,③部分領域數據稀缺,難以獲取等。
對此,中科院軟件所和百度共同提出了一個統一式的用信息抽取技術——UIE,UIE在實體、關系、事件和情感等4個信息抽取任務、13個數據集的全監督、低資源和少樣本設置下,均取得了SOTA性能。
3.2整體框架
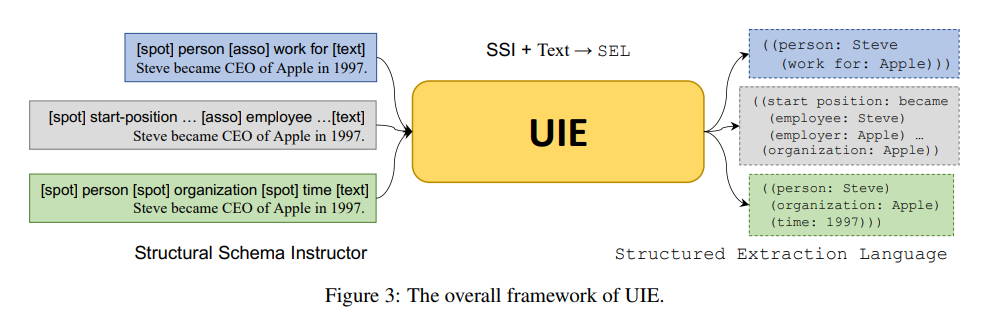
圖2 UIE整體框架
如圖2所示,UIE的整體框架包含SSI和SEL兩大模塊,其中SSI屬于編碼階段,SEL屬于解碼階段。
編碼階段,SSI將待抽取的Schema信息轉換成“線索”(Schema-based Prompt),作為待抽取文本的前綴。如對“Steve became CEO of Apple in 1997”文本進行關系抽取任務,便可以將“[spot] person [asso] work for”作為前綴,拼接到待抽取文本[text]上,作為整體輸入到UIE中。其中“person”指“人”實體類型,“work for”指“工作于”關系類型。通過這種引導,語言模型就可以明確具體的信息抽取任務要求。
解碼階段,SEL對包含任務引導(prompt)和語義信息(text)的中間向量進行解碼,得到的輸出能夠覆蓋全部的抽取任務。如{{“人”: 斯蒂芬{“工作于”: “蘋果”}}}表示關系抽取結果,{{“事件起始”: “成為”{“受雇人”: 斯蒂芬}{“雇主”: “蘋果”}{“組織名稱”: “蘋果”}}表示事件抽取結果,{{“人”: 斯蒂芬”}{“組織名稱”: “蘋果”}{“時間”: “1997”}}表示實體抽取結果。
3.3預訓練
為了讓模型能夠獲得通用的信息抽取能力,需要做預訓練,預訓練目標包括3個部分。
ext-to-Structure (文本到結構化輸出)
這是最基本的一個訓練目標,即訓練模型的encoder和decoder,讓模型獲得根據非結構化輸入x文本得到結構化輸出y的能力。
Structure generation(結構生成)
訓練模型的decoder,使得decoder能夠按照正確的抽取結構輸出抽取結果,注重的是模型生成結構化文本的能力。
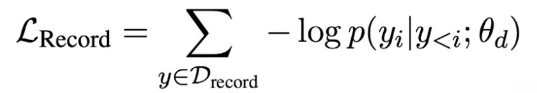
Retrofitting semantic representation(增強語義表示)
實際上是 masked language model 任務,通過打亂的原文本去預測打亂的目標問題,從而提升UIE模型的語義編碼能力。
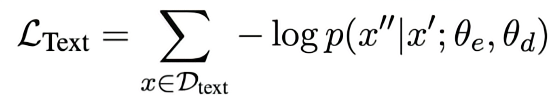
3.4模型優勢
(1)支持多種抽取任務
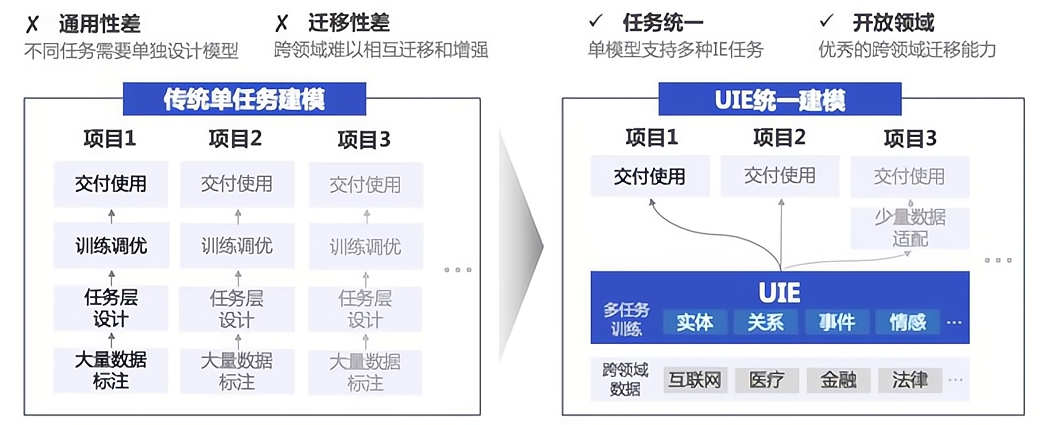
圖3 傳統建模和統一建模對比圖
如圖3所示,傳統方案對不同的抽取任務構建多個IE模型,各模型單獨訓練,數據和知識不共享。在UIE方案使用單個模型解決所有信息抽取需求,包括但不限于實體、關系、事件、評價維度、觀點詞、情感傾向等信息抽取,降低開發成本和機器成本。
(2)零樣本抽取和少樣本快速遷移能力

圖4 UIE在各場景下few-shot、zero-shot的能力
UIE開創了基于Prompt的信息抽取多任務統一建模方式,通過大規模多任務預訓練學習的通用抽取能力。如圖4 所示,UIE可以在不限定行業領域的情況下實現零樣本快速冷啟動。
(3)無需改變模型,易于添加新實體

圖5 不同抽取任務的prompt模板
如圖5所示為UIE模型四個任務對應的prompt,每個prompt由schema名稱拼接生成。當任務需要增加實體、關系、事件類型時,只需要在對應的prompt中增加新的類型,不需要重新調整模型。
四、在網安領域的表現
抽取結果及應用
4.1 網安領域抽取結果
使用UIE模型對網安數據集進行信息抽取,其絕大多數抽取結果和標簽完全一致,模型的準確率很高,抽取結果具有一定可信度。以實體、事件抽取兩任務為例,本文僅對兩者不一致的樣本進行展示,其中紅色表示標簽詞、藍色表示預測詞、黃色表示正確預測的標簽詞。
實體抽取
1. Although we have only observed APT33 use DROPSHOT to deliver TURNEDUP, we have identified multiple DROPSHOT samples in the wild that delivered wiper malware we call SHAPESHIFT.
實體類型:malware.name(惡意軟件名稱)
盡管我們只觀察到APT33使用DROPSHOT來傳遞迂回,但我們已經在野外發現了多個DROPSHOT樣本,這些樣本提供了我們稱之為SHAPESHIFT的雨刮器惡意軟件
模型輸出的抽取結果優于文本標簽,模型的輸出更加全面。
2. The first attack in the US that Group IB attributes to this group was conducted in the spring of 2016 : money was stolen from the bank by gaining access to First Data' s ' 'STAR' network operator portal.
實體類型:threator(攻擊組織)
歸因于該IB集團的美國第一次攻擊發生在2016年春季:通過訪問First Data的“STAR”網絡運營商門戶,從銀行竊取了資金。
模型抽取了整個主語,增加了attributes to this group狀語,文本標簽更加準確。
3. APT33 has targeted organizations – spanning multiple industries – headquartered in the United States, Saudi Arabia and South Korea.
實體類型:location(地點)
APT33的目標組織 - 跨越多個行業 - 總部設在美國,沙特阿拉伯和韓國。
模型輸出和文本標簽均不完整,地點類型應包含美國、沙特阿拉伯和韓國三地。
事件抽取
1. And finally, Juniper said nearly 40 vulnerabilities have been resolved in the Junos Space Network Management Platform 18.3 R1 and 18.4 R1 by upgrading third party components or fixing internally discovered security vulnerabilities.
觸發詞類型:patch vulnerability(補丁漏洞)
最后,瞻博網絡表示,Junos Space網絡管理平臺18.3 R1和18.4 R1中已經通過升級第三方組件或修復內部發現的安全漏洞解決了近40個漏洞。
模型輸出和文本標簽均不完整,與補丁漏洞相關的觸發詞應包含升級、修復和解決了三詞。
2. If a victim opens a crafted, malicious file in the Cisco Webex Player -- potentially sent over email as part of a spear phishing campaign -- the bugs are triggered, leading to exploit.
觸發詞類型:phishing(釣魚)
如果受害者在 Cisco Webex Player 中打開精心制作的惡意文件(可能作為魚叉式網絡釣魚活動的一部分通過電子郵件發送),則會觸發這些錯誤,從而導致漏洞利用 。
標簽更加準確,發送應給該事件的觸發詞。
3. Phishing and other hacking incidents have led to several recently reported large health data breaches, including one that UConn Health reports affected 326,000 individuals.角色類型:phishing(釣魚)
網絡釣魚和其他黑客事件導致最近報告的幾起大型健康數據泄露事件,其中包括UConn Health報告的一起影響了326,000人。
標簽更加準確,人過于籠統,抽取UConn Health更有意義。
4.The ransomware encrypted the files on the computers and showed a ransom note demanding payment for a decryption key.
角色類型:attack pattern(攻擊模式)
勒索軟件對計算機上的文件進行了加密,并顯示了要求支付解密密鑰的贖金記錄。
標簽和輸出均不準確,攻擊模式應為對文件加密和顯示贖金記錄。
4.2 算法應用
UIE是一種現有最優的信息抽取算法,將UIE用于網安領域可以極大的幫助研究者們分析網絡威脅,同時對維護網絡安全、促進社會信息化發展具有重要作用。具體而言,UIE在網絡安全領域的應用有以下幾部分:
構建網安知識圖譜
信息抽取是構建知識圖譜的基礎,在網安領域存在的大量非結構化文本,包含漏洞描述、惡意軟件分析報告、攻擊組織分析報告,安全熱點事件等,都依賴于IE技術對其進行結構化表示。其次,網絡安全領域存在知識、資產難以定義的問題,對此,引入強大的預訓練語言模型可以幫助研究者從自然語言的角度推進對專業知識的定義。
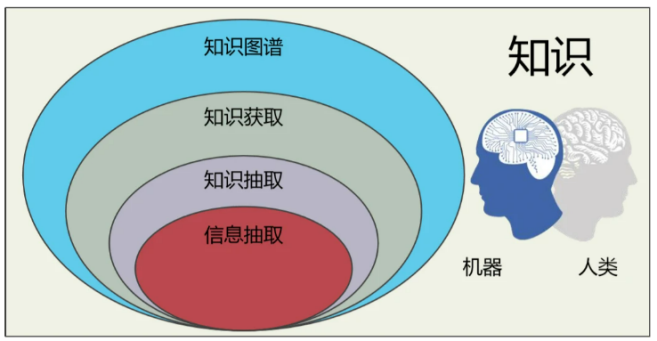
圖6 知識圖譜概念圖
APT組織畫像
由于傳統對離線數據建模的方法難以滿足大部分企業對APT攻擊實時分析的要求,所以業內均對APT組織畫像歸因開展了積極的探索工作。APT組織畫像歸因需要利用安全知識圖譜統一描述APT攻擊每個階段的TTPs,實現對APT攻擊的自動化威脅追蹤,掌握攻擊者的攻擊特征、發掘潛在的危機,甚至防堵未來的攻擊。而其中的安全知識圖譜的構建同樣使用了信息抽取技術的幫助。
豐富網安平臺功能
近些年,輿情分析、網空測繪等平臺不斷涌現,而信息抽取技術貫穿于多個功能之間。利用IE技術提取報告、情報中的信息作為關鍵詞(實體、關系、事件),可以幫助閱讀者形成對網安文章的第一認知。通過將提取的關鍵詞轉化為標簽,可用于輿情文章的分類、關聯和推送等。最后,可以在用戶瀏覽各類文章的過程中使用文章標簽反向定義用戶畫像,從而提供個性化服務。
