SRC信息收集思路分享
說到信息收集,網上已經有許多文章進行描述了,那么從正常的子域名、端口、旁站、C段等進行信息收集的話,對于正常項目已經夠用了,但是挖掘SRC的話,在諸多競爭對手的“幫助”下,大家收集到的信息都差不多,挖掘的漏洞也往往存在重復的情況。
那么現在我就想分享一下平時自己進行SRC挖掘過程中,主要是如何進行入手的。以下均為小弟拙見,大佬勿噴。
0x01 確定目標
無目標隨便打,有沒有自己對應的SRC應急響應平臺不說,還往往會因為一開始沒有挖掘到漏洞而隨意放棄,這樣往往不能挖掘到深層次的漏洞。挖到的大多數是大家都可以簡單挖到的漏洞,存在大概率重復可能。所以在真的想要花點時間在SRC漏洞挖掘上的話,建議先選好目標。
那么目標怎么選呢,考慮到收益回報與付出的比例來看,建議是從專屬SRC入手,特別在一些活動中,可以獲取比平時更高的收益。
微信搜一搜:
 百度搜一搜:
百度搜一搜:
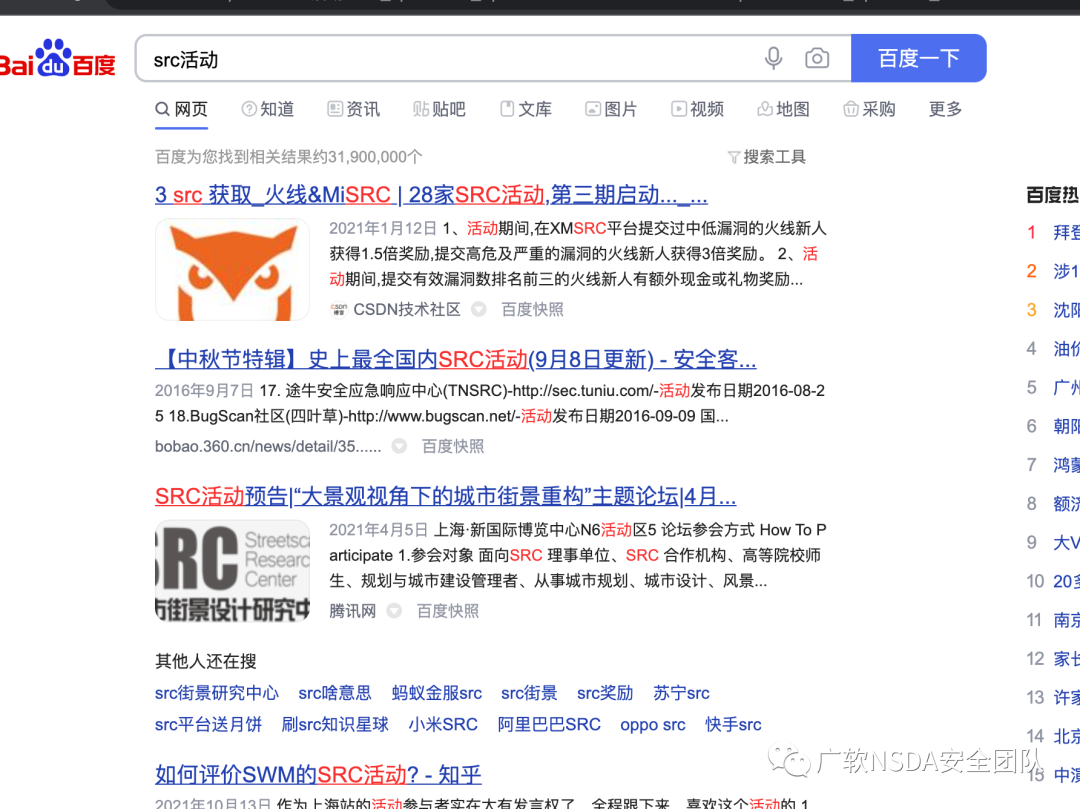
現在有活動的src已經浮現水面了,那么我們就可以從中選擇自己感興趣的SRC。
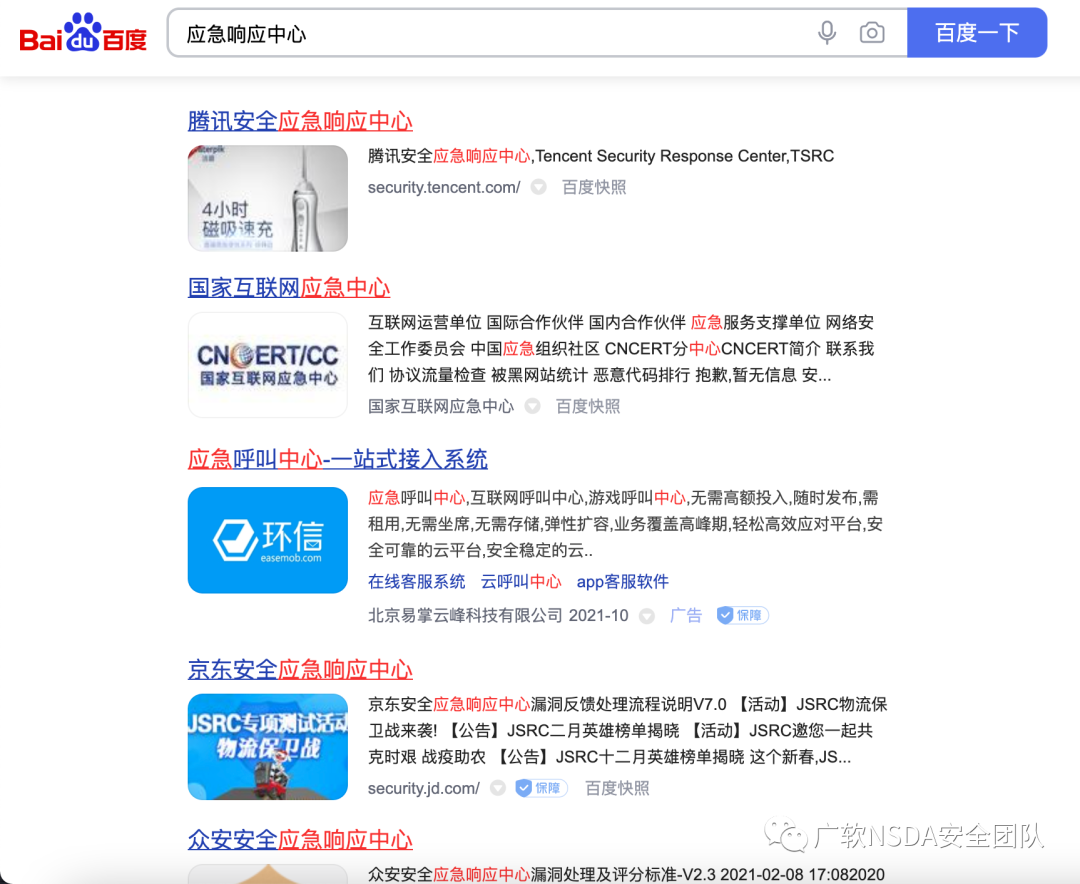
0x02 確認測試范圍
前面說到確定測什么SRC,那么下面就要通過一些方法,獲取這個SRC的測試范圍,以免測偏。
1、公眾號
從公眾號推文入手,活動頁面中可以發現測試范圍
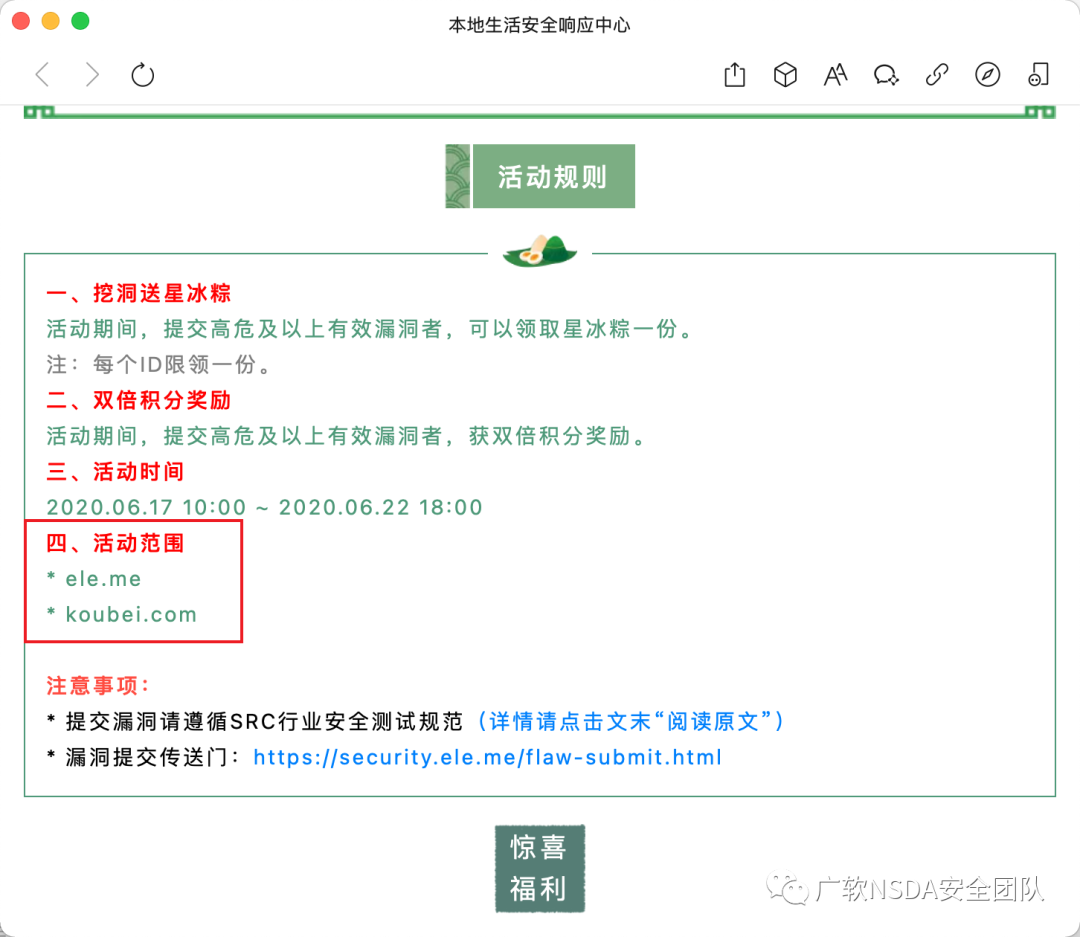
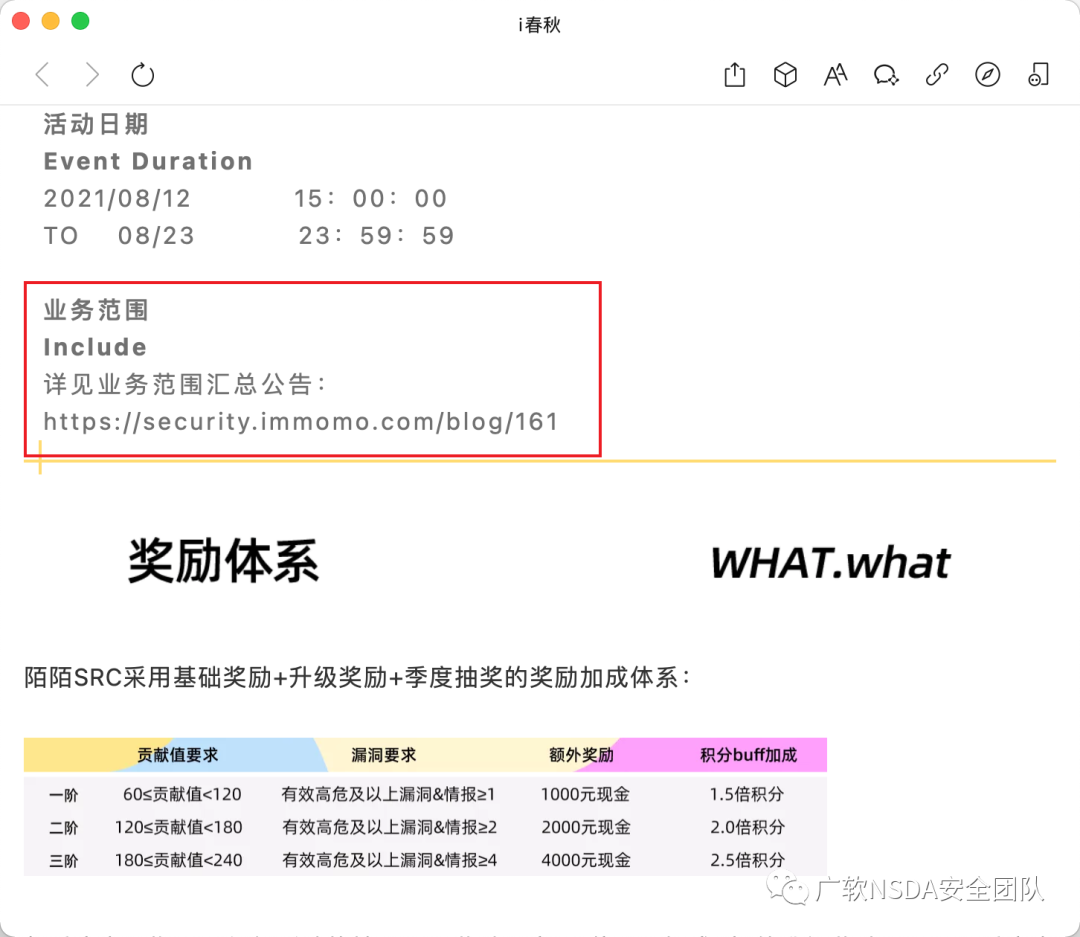
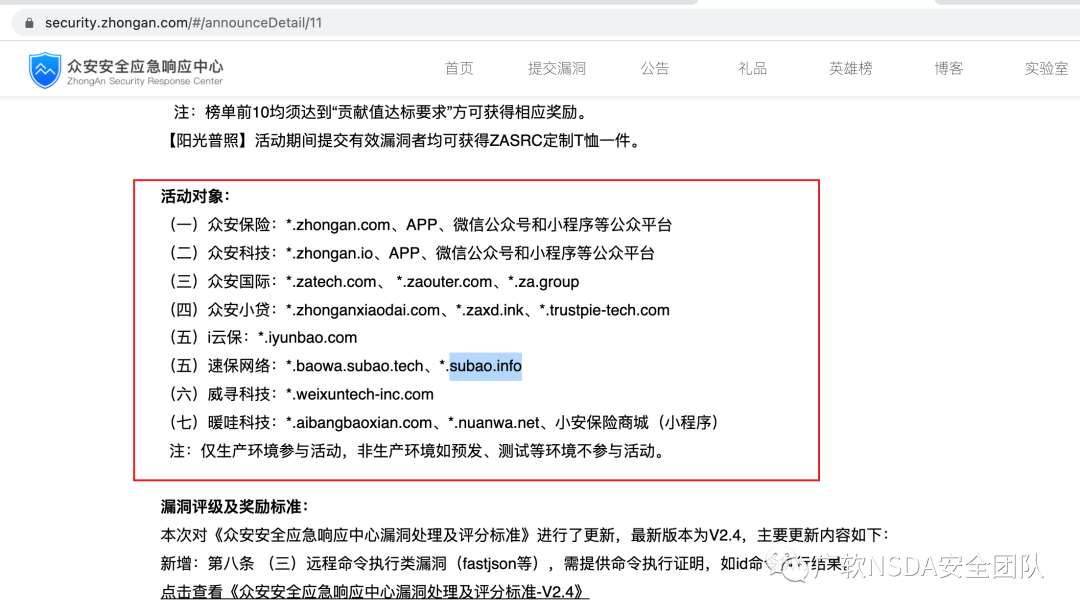
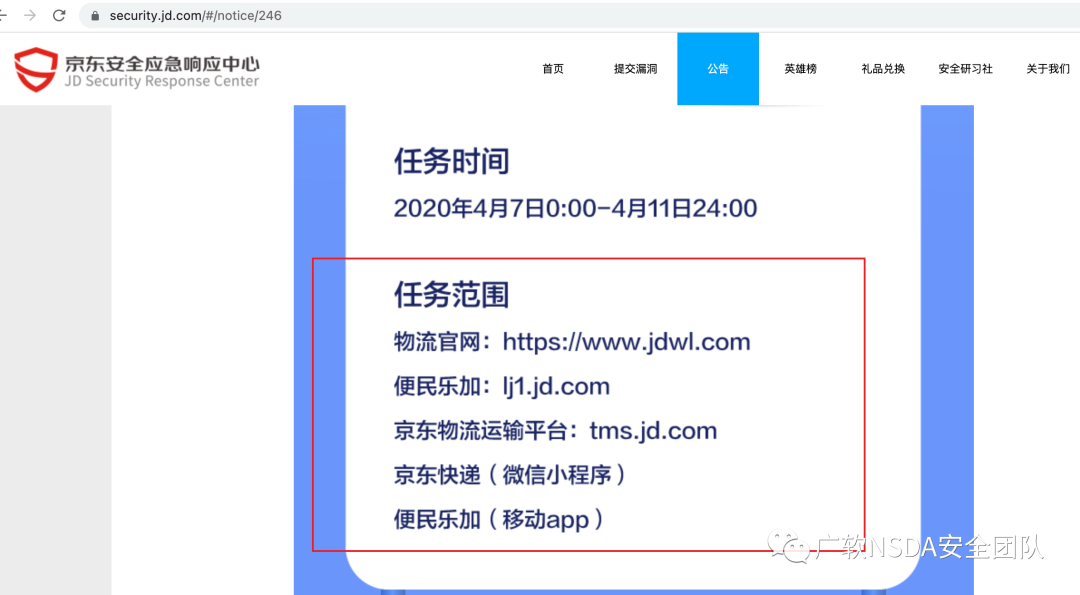
2、應急響應官網
在應急響應官網,往往會有一些活動的公告,在里面可以獲取到相應的測試范圍。
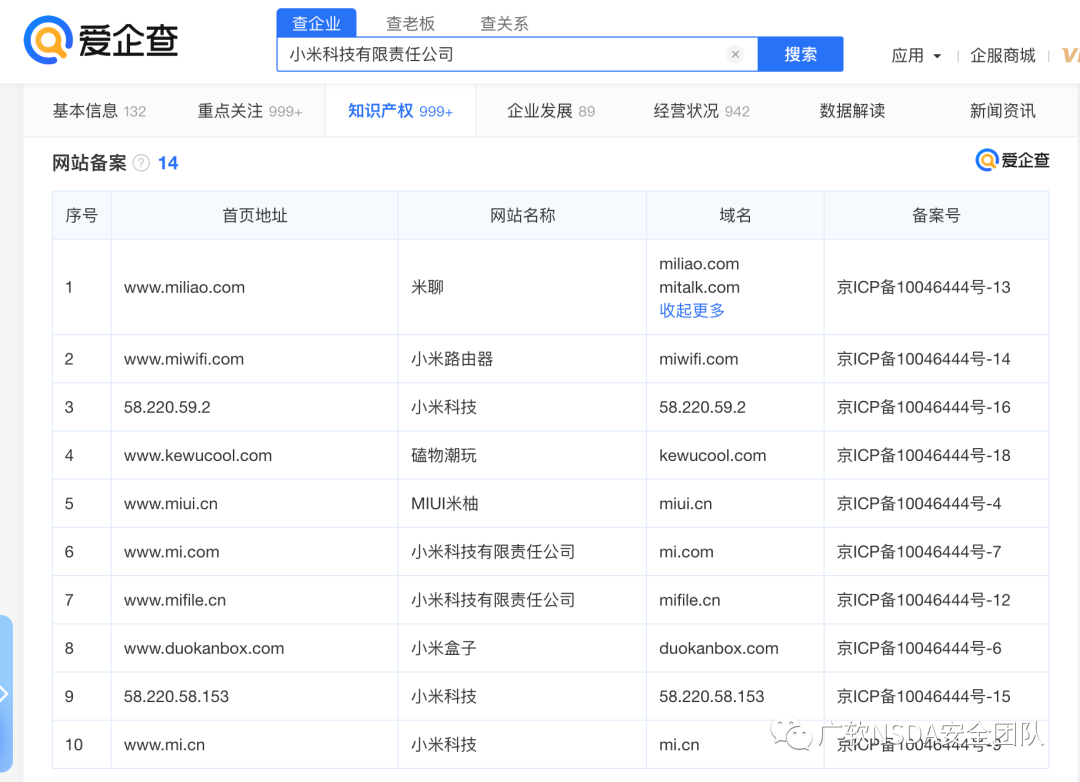
3、愛企查
從愛企查等商業查詢平臺獲取公司所屬域名
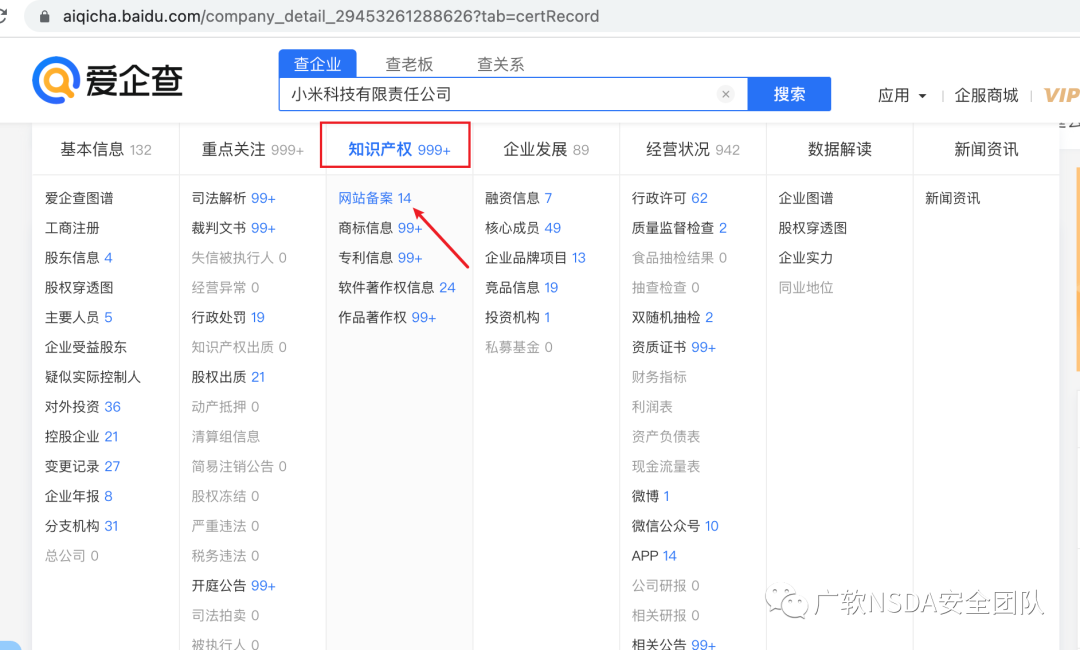
 搜索想要測試等SRC所屬公司名稱,在知識產權->網站備案中可以獲取測試范圍。
搜索想要測試等SRC所屬公司名稱,在知識產權->網站備案中可以獲取測試范圍。
0x03 子域名(oneforall)
拿到域名之后,下一步我考慮使用oneforall掃描獲取子域名,就像網上信息收集的文章一樣,主域名的站點不是靜態界面就是安全防護等級極強,不是隨便就能夠發現漏洞的,我們挖掘SRC也是要從子域名開始,從邊緣資產或一般資產中發現漏洞。
工具下載:
https://github.com/shmilylty/OneForAll
具體用法如下:
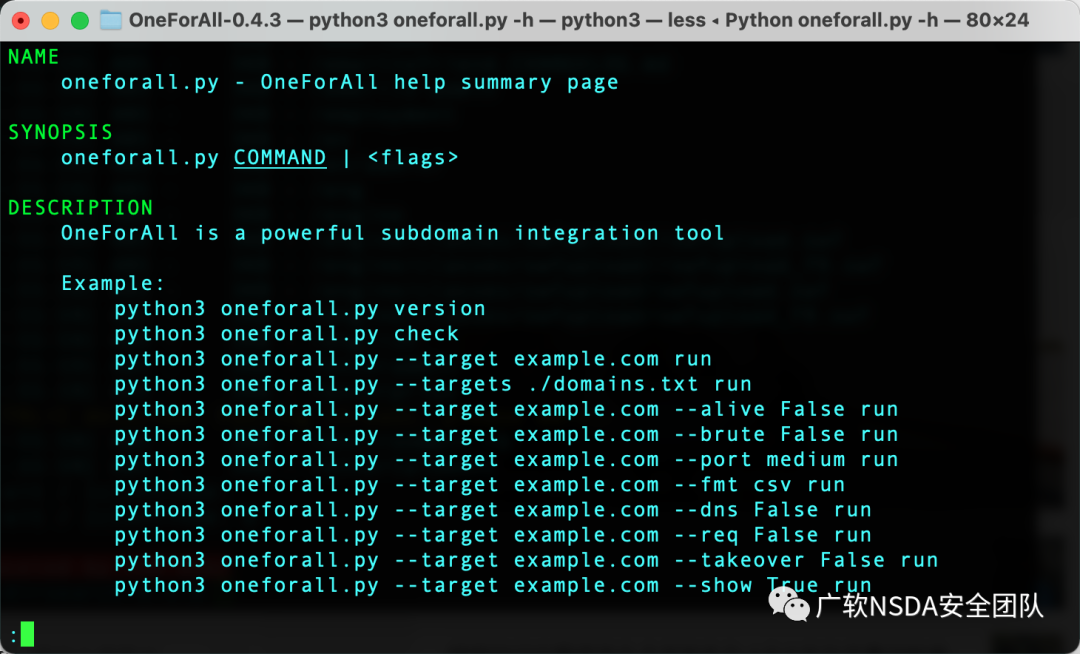 常用的獲取子域名有2種選擇,一種使用--target指定單個域名,一種使用--targets指定域名文件。
常用的獲取子域名有2種選擇,一種使用--target指定單個域名,一種使用--targets指定域名文件。
python3 oneforall.py --target example.com run python3 oneforall.py --targets ./domains.txt run
其他獲取子域名的工具還有layer子域名挖掘機、Sublist3r、證書透明度、在線工具等,這里就不一一闡述了,大體思路是一樣等,獲取子域,然后從中篩選邊緣資產,安全防護低的資產。
0x04 系統指紋探測
通過上面的方法,我們可以在/OneForAll-0.4.3/results/路徑下獲取以域名為名字的csv文件。里面放入到便是掃描到到所有子域名以及相應信息了。
下一步便是將收集到到域名全部進行一遍指紋探測,從中找出一些明顯使用CMS、OA系統、shiro、Fastjson等的站點。下面介紹平時使用的2款工具:
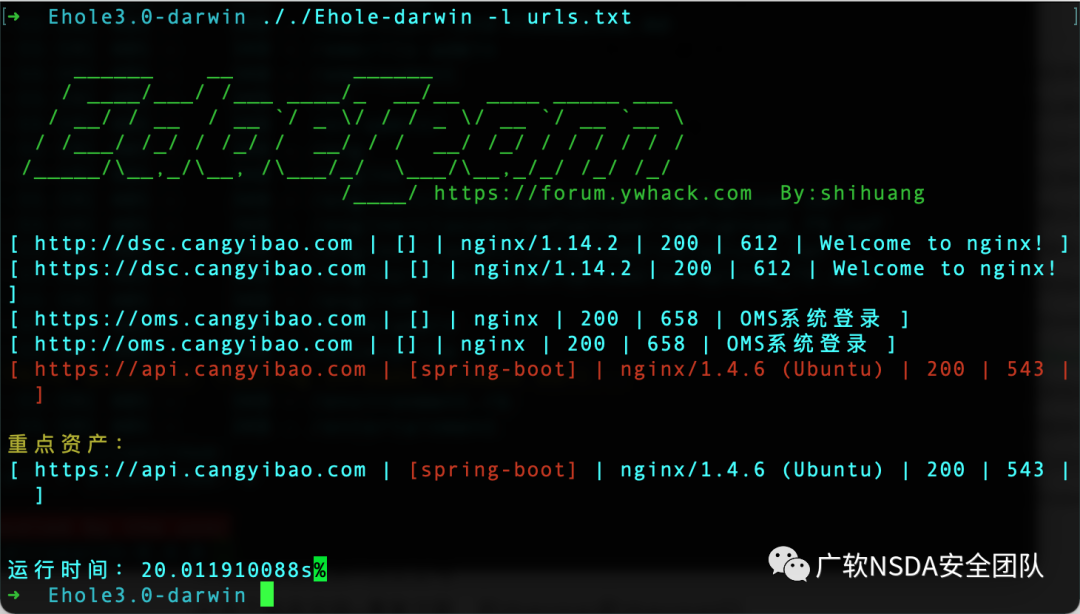
1、Ehole
下載地址:
https://github.com/EdgeSecurityTeam/EHole
使用方法:
./Ehole-darwin -l url.txt //URL地址需帶上協議,每行一個 ./Ehole-darwin -f 192.168.1.1/24 //支持單IP或IP段,fofa識別需要配置fofa密鑰和郵箱 ./Ehole-darwin -l url.txt -json export.json //結果輸出至export.json文件
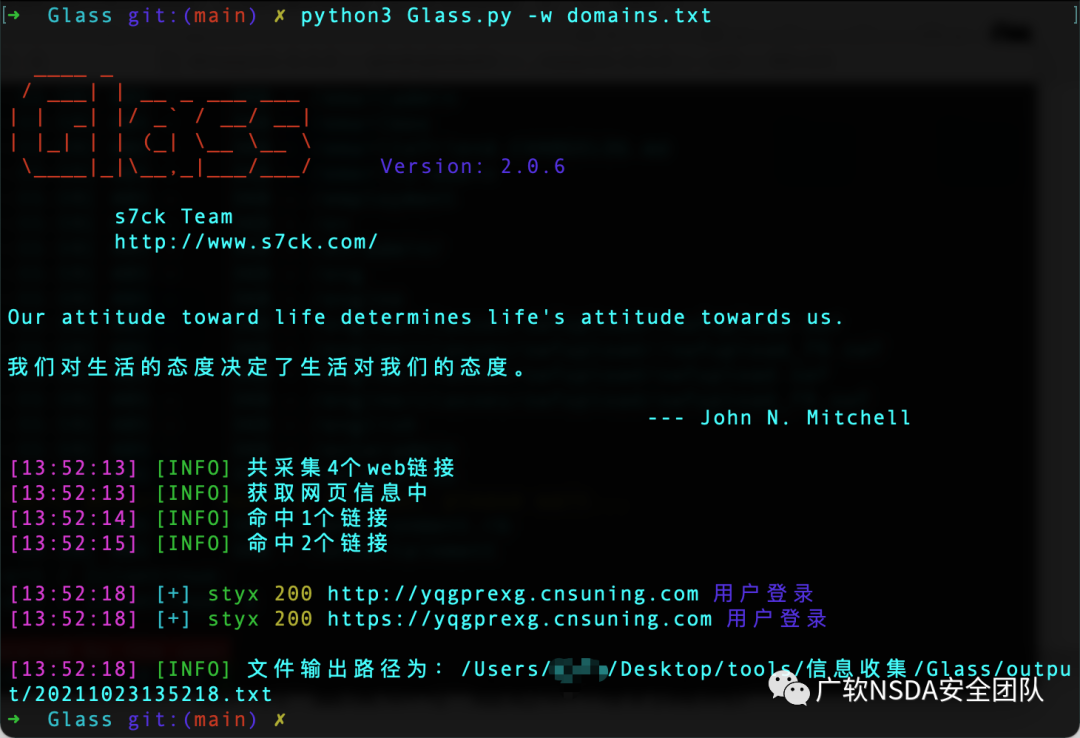
2、Glass
下載地址:
https://github.com/s7ckTeam/Glass
使用方法:
python3 Glass.py -u http://www.examples.com // 單url測試 python3 Glass.py -w domain.txt -o 1.txt // url文件內
0x05 框架型站點漏洞測試
前面經過了子域名收集以及對收集到的子域名進行了指紋信息識別之后,那么對于框架型的站點,我們可以優先進行測試。
類似用友NC、通達OA、藍凌OA等,可以通過嘗試現有的Nday漏洞進行攻擊。
0x06 非框架型站點漏洞測試
前面測試完框架型的站點了,之后就應該往正常網站,或者經過了二開未能直接檢測出指紋的站點進行滲透了。那么對于這類站點,最經常遇到的便是登錄框,在這里,我們便可以開始測試了。
 1、用戶名枚舉
1、用戶名枚舉
抓包嘗試是否用戶名存在與不存在的情況,返回結果不同。
2、驗證碼
是否存在驗證碼,驗證碼是否可以抓包截斷繞過,驗證碼是否可以為空。
3、暴力破解
下面是我收集的集中常見的用戶名
1.弱口令用戶名如admin,test,ceshi等 2.員工姓名全拼,員工姓名簡拼 3.公司特征+員工工號/員工姓名 4.員工工號+姓名簡拼 5.員工姓名全拼+員工工號 6.員工姓名全拼+重復次數,如zhangsan和zhangsan01 7.其他
關于暴力破解我要扯一句了,就是關于密碼字典的問題。經常會聽到某人說他的字典多么多么的大,有好幾個G之類的,但是在我覺得,這很沒有必要,有些密碼是你跑幾天都跑不出來的,就算字典確實夠大,也沒有必要這樣跑,可能影響心情不說,大規模地暴力破解,很容易讓人覺得你在拒絕服務攻擊。
其實我的話一般跑一跑弱口令就差不多了。
關于弱口令字典的問題,我也想說一嘴,你最好看看,你字典里面的admin、123456、password處在什么位置。記得之前玩CTF的時候,默認密碼123456,但是那個師傅死活做不出來,后面一看,字典里面居然沒有123456這個密碼。。。
這里推薦一個字典,個人感覺還是挺好用的。當然更多的是需要自己不斷更新。
https://github.com/fuzz-security/SuperWordlist
4、工具cupp和cewl
對于一些情況,密碼不是直接使用弱口令,而是通過一些公司的特征+個人信息制作的,那么這個時候,我們的字典便不能直接使用了,需要在這之前加上一些特征,例如阿里SRC可能是a;百度SRC可能是bd等。
下面2款kali自帶等工具,可以通過收集信息,生成好用的字典,方便滲透。說真的,在滲透測試過程中,弱口令,YYDS!
具體使用說明和工具介紹,可以查看文章:
https://mp.weixin.qq.com/s/HOlPaJ4EMY7PfHh7p2d95A
5、自行注冊
如果能夠注冊那就好辦了,自己注冊一下賬戶即可。
6、小總結
對于非框架的站點,登錄接口一般是必不可少的,可能就在主頁,也可能在某個路徑下,藏著后臺的登錄接口,在嘗試了多種方法成功登錄之后,記得嘗試里面是否存在未授權漏洞、越權等漏洞。
這里借用來自WS師傅的建議:可以直接掃描出來的洞,基本都被交完了,可以更多往邏輯漏洞方面找。登錄后的漏洞重復率,比登錄前的往往會低很多。
0x07 端口掃描
前面就是正常的滲透了,那么一個域名只是在80、443端口才有web服務嗎?不可否認有些時候真的是,但是絕大多數情況下,類似8080、8443、8081、8089、7001等端口,往往會有驚喜哦~
端口掃描也算是老生常談了,市面上也有很多介紹端口掃描的工具使用方法,這里也不細說了,就放出平時使用的命令吧。
sudo nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v examples.comsudo nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v -p 1-65535 examples.com
0x08 目錄掃描dirsearch
目錄掃描在滲透測試過程中我認為是必不可少的,一個站點在不同目錄下的不同文件,往往可能有驚喜哦。
個人是喜歡使用dirserach這款工具,不僅高效、頁面也好看。市面上還有例如御劍、御劍t00ls版等,也是不錯的選擇。
dirsearch下載地址:
https://github.com/maurosoria/dirsearch
具體使用方法可以查看github介紹,這里我一般是使用如下命令(因為擔心線程太高所以通過-t參數設置為2)
python3 dirsearch.py -u www.xxx.com -e * -t 2
關鍵的地方是大家都可以下載這款工具,獲取它自帶的字典,那么路徑的話,便是大家都能夠搜得到的了,所以這里我推薦是可以適當整合一些師傅們發出來的路徑字典到/dirsearch-0.4.2/db/dicc.txt中。例如我的話,是增加了springboot未授權的一些路徑、swagger的路徑以及一些例如vmvare-vcenter的漏洞路徑。

0x09 JS信息收集
在一個站點掃描了目錄、嘗試登錄失敗并且沒有自己注冊功能的情況下,我們還可以從JS文件入手,獲取一些URL,也許某個URL便能夠未授權訪問獲取敏感信息呢。
1、JSFinder
工具下載:
https://github.com/Threezh1/JSFinder
JSFinder是一款用作快速在網站的js文件中提取URL,子域名的工具。個人覺得美中不足的地方便是不能對獲取到到URL進行一些過濾,在某些情況下,JS文件中可以爬取非常多的URL,這其中可能大部分是頁面空或者返回200但是頁面顯示404的。來自HZ師傅的建議,可以修改一下工具,基于當前的基礎上,檢測獲取的URL是否可以訪問,訪問后的頁面大小為多少,標題是什么。。。
思路放這了,找個時間改一改?
#檢測URL狀態碼#-----------------------#! /usr/bin/env python#coding=utf-8import sysimport requests
url='xxxx'request = requests.get(url)httpStatusCode = request.status_codeif httpStatusCode == 200: xxxxelse: xxxx
#檢測URL返回包大小#-----------------------import requests
def hum_convert(value): units = ["B", "KB", "MB", "GB", "TB", "PB"] size = 1024.0 for i in range(len(units)): if (value / size) < 1: return "%.2f%s" % (value, units[i]) value = value / size
r = requests.get('https://www.baidu.com')r.status_coder.headers
length = len(r.text)print(hum_convert(length))
#獲取網站標題#-----------------------#!/usr/bin/python#coding=utf-8
urllib.requestimport urllib.requestimport re
url = urllib.request.urlopen('http://www.xxx.com')html = url.read().decode('utf-8')
title=re.findall('(.+)',html)print (title)
2、JS文件
JS文件與HTML、CSS等文件統一作為前端文件,是可以通過瀏覽器訪問到的,相對于HTML和CSS等文件的顯示和美化作用,JS文件將會能夠將頁面的功能點進行升華。
 對于滲透測試來說,JS文件不僅僅能夠找到一些URL、內網IP地址、手機號、調用的組件版本等信息,還存在一些接口,因為前端需要,所以一些接口將會在JS文件中直接或間接呈現。下面我將介紹如何發現這些隱藏的接口。
對于滲透測試來說,JS文件不僅僅能夠找到一些URL、內網IP地址、手機號、調用的組件版本等信息,還存在一些接口,因為前端需要,所以一些接口將會在JS文件中直接或間接呈現。下面我將介紹如何發現這些隱藏的接口。
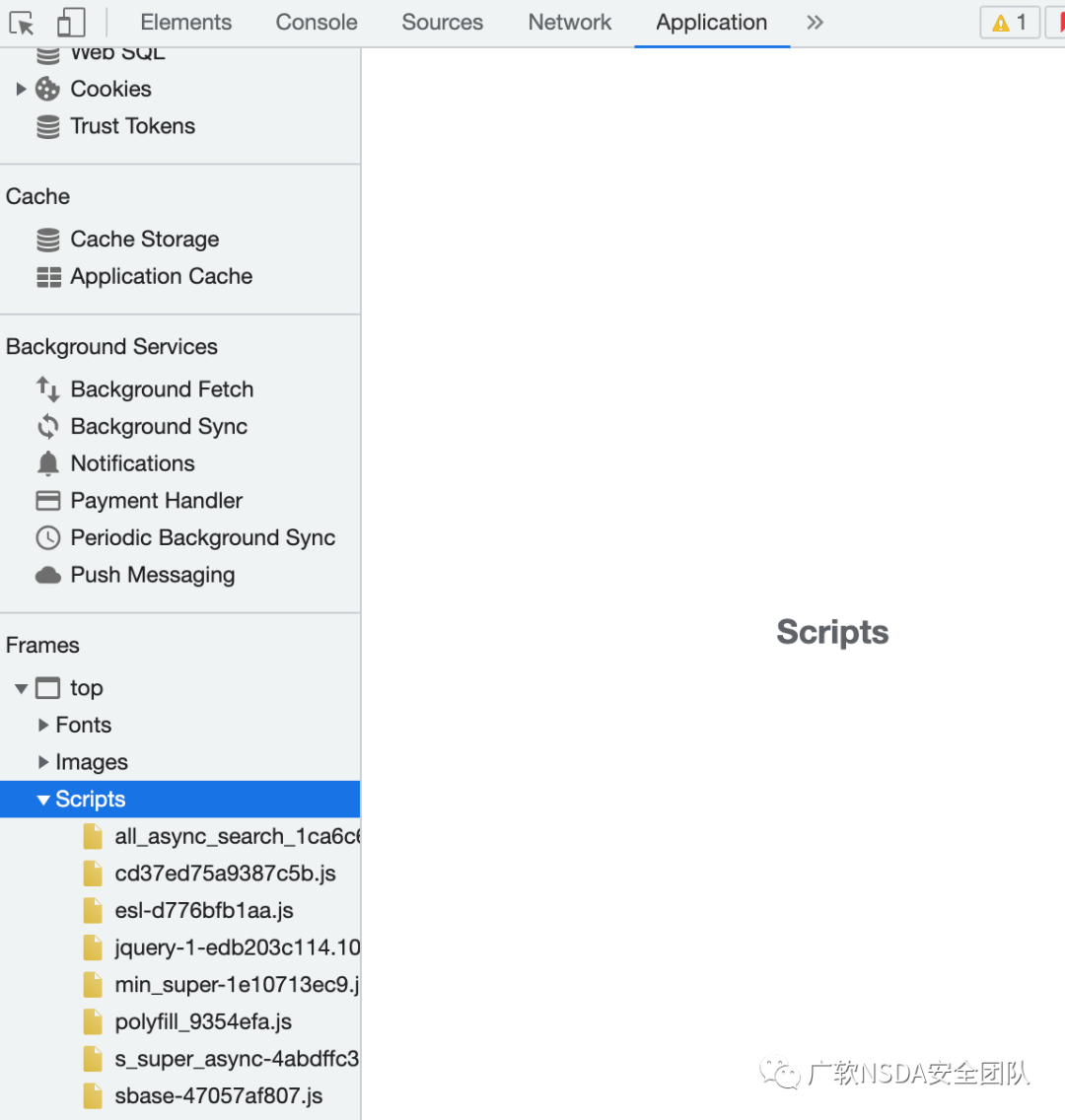
1、首先在某個頁面中,鼠標右鍵,選擇檢查

2、點擊Application
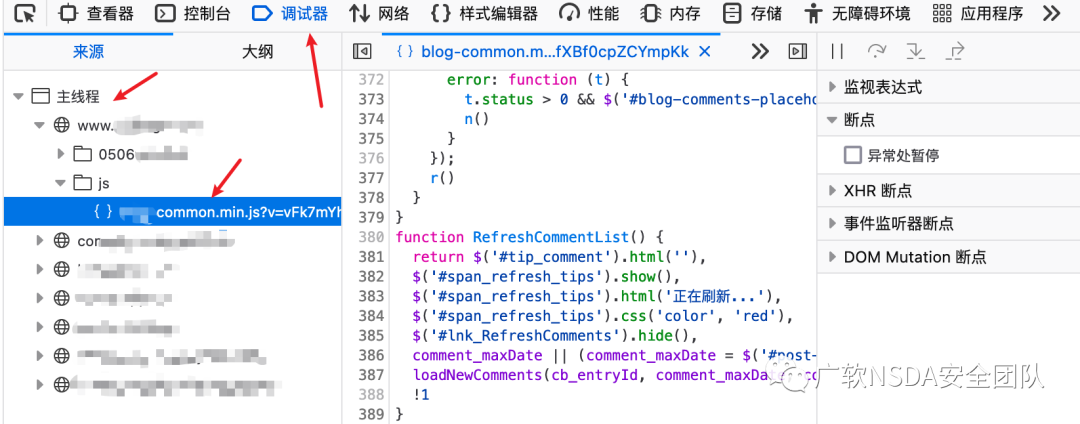
 3、在Frames->top->Scripts中能夠獲取當前頁面請求到的所有JS
3、在Frames->top->Scripts中能夠獲取當前頁面請求到的所有JS
 4、火狐瀏覽器的話,則是在調試中
4、火狐瀏覽器的話,則是在調試中
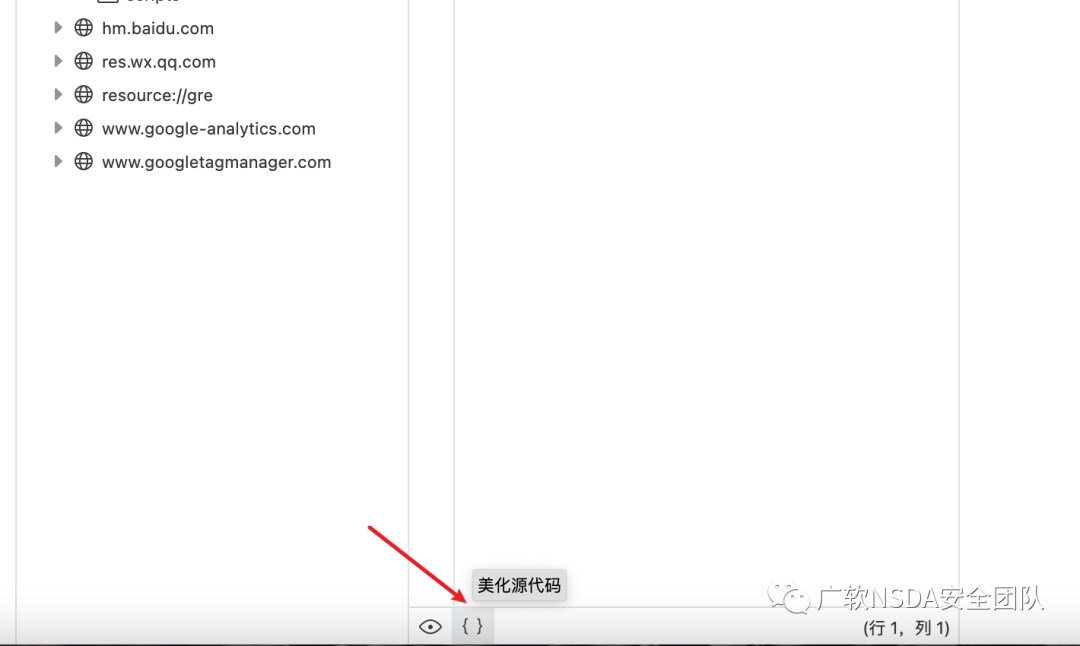
 5、如果你請求的JS文件內容都疊在了前幾行的話,下面這個鍵可以幫你美化輸出
5、如果你請求的JS文件內容都疊在了前幾行的話,下面這個鍵可以幫你美化輸出
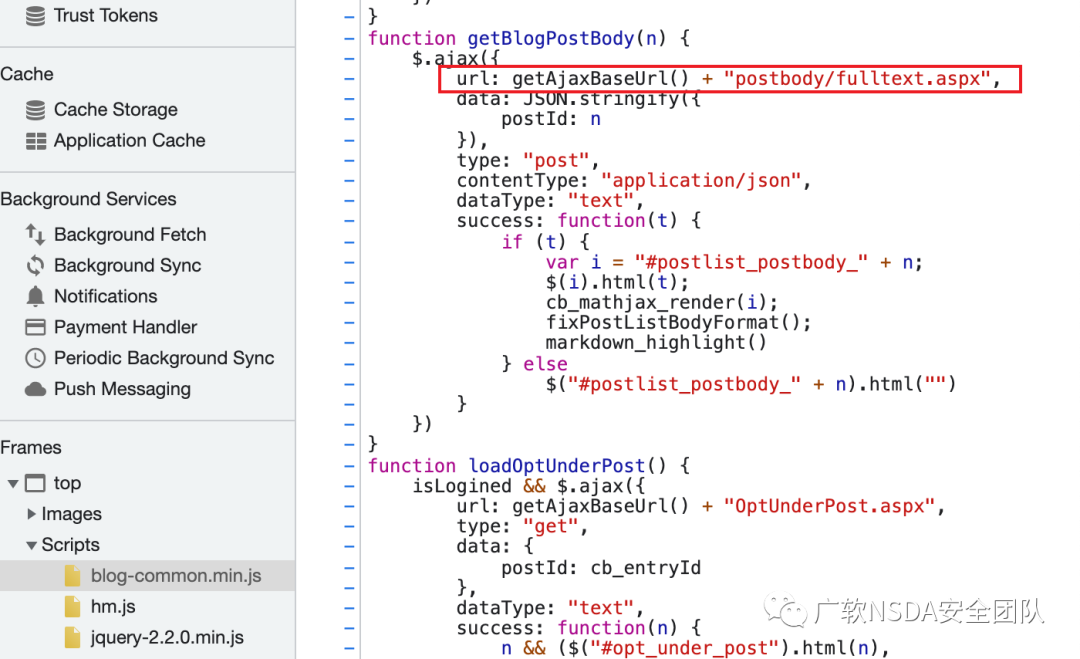
 6、在JS文件中,可以尤為注意帶有api字眼的文件或內容,例如下面這里我發現了一個接口。
6、在JS文件中,可以尤為注意帶有api字眼的文件或內容,例如下面這里我發現了一個接口。
0x10 小程序、APP
web端沒有思路的時候,可以結合小程序、APP來進行滲透。小程序或APP的服務端其實可以在一定程度上與web應用的服務端相聯系。也就是說,我們在小程序或者APP上,一樣能夠挖掘web端的漏洞如SQL注入、XSS等,并且相對來說,這類等服務端安全措施會相對沒有那么完備,所以在web端確實沒有思路的時候,可以迂回滲透,從小程序、APP中進行。
#小程序抓包、APP抓包參考鏈接: https://mp.weixin.qq.com/s/xuoVxBsN-t5KcwuyGpR56g https://mp.weixin.qq.com/s/45YF4tBaR-TUsHyF5RvEsw https://mp.weixin.qq.com/s/M5xu_-_6fgp8q0KjpzvjLg https://mp.weixin.qq.com/s/Mfkbxtrxv5AvY-n_bMU7ig
0x11 總結
以上就是我個人挖掘SRC的一些信息收集思路,挖掘SRC有的時候真的很看運氣,也許別人對一個接口簡單Fuzz,便出了一個注入,而我們花了幾天,還是一直看到返回內容為404。所以有的時候真的可以換個站試試,也許就挖到高危甚至嚴重了~
作為一名SRC小白,以上內容均為小弟拙見,希望能夠通過這篇文章,幫到更多的網絡安全小白,沒能幫上大佬們真的很抱歉~后續也會持續提高自己,將學到的更多的東西分享給大家。
文章來源:先知社區
原創作者:ajie
