滲透測試|玩轉網絡空間搜索引擎
網絡空間搜索引擎是什么?
網絡空間搜索引擎是為了解決個人每次進行滲透測試是都要進行的信息收集過程,通過全網掃描的方式,將基礎數據進行格式化存儲,供安全人員按需搜索使用,提升了安全人員的工作效率。
常用的網絡空間搜索引擎:fofa、shodan、zoomeye、censys
常見網絡空間搜索引擎介紹
網絡空間搜索引擎有哪些
目前國內外的網絡空間搜索引擎有 shodan、zoomeye、cnesys、fofa,下面一一介紹。
shodan
Shodan 是目前最為知名的黑客搜索引擎,它是由計算機程序員約翰·馬瑟利(John Matherly)于 2009 年推出的,他在 2003 年就提出了搜索與 Internet 鏈接的設備的想法。發展至今已經變成搜索資源最全,搜索性能最強,TOP1 級別的網絡資產搜索引擎。
地址:
https://www.shodan.io/
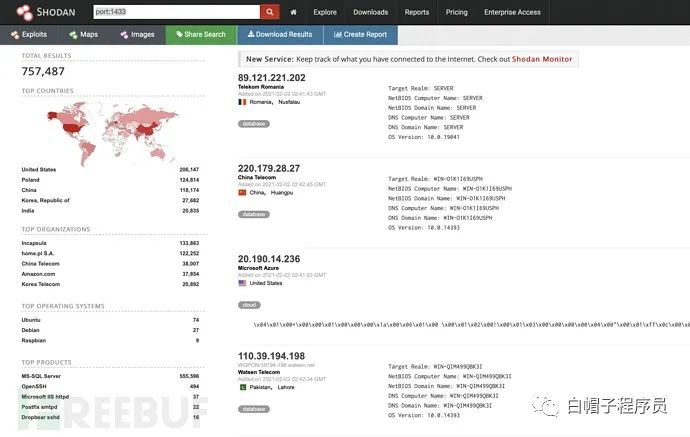
簡單語法:
hostname: # 搜索指定的主機或域名,例如 hostname:"google" port: # 搜索指定的端口或服務,例如 port:"21" country: # 搜索指定的國家,例如 country:"CN" city: # 搜索指定的城市,例如 city:"Hefei" org: # 搜索指定的組織或公司,例如 org:"google" isp: # 搜索指定的ISP供應商,例如 isp:"China Telecom" product: # 搜索指定的操作系統/軟件/平臺,例如 product:"Apache httpd" version: # 搜索指定的軟件版本,例如 version:"1.6.2" geo: # 搜索指定的地理位置,參數為經緯度,例如 geo:"31.8639, 117.2808" before/after:# 搜索指定收錄時間前后的數據,格式為dd-mm-yy,例如 before:"11-11-15" net: # 搜索指定的IP地址或子網,例如 net:"210.45.240.0/24"a
zoomeye
ZoomEye 是北京知道創宇公司發布的網絡空間偵測引擎,積累了豐富的網絡掃描與組件識別經驗。在此網絡空間偵測引擎的基礎上,結合“知道創宇”漏洞發現檢測技術和大數據情報分析能力,研制出網絡空間雷達系統,為政府、企事業及軍工單位客戶建設全球網絡空間測繪提供技術支持及產品支撐。
ZoomEye 支持公網設備指紋檢索和 Web 指紋檢索。網站指紋包括應用名、版本、前端框架、后端框架、服務端語言、服務器操作系統、網站容器、內容管理系統和數據庫等。設備指紋包括應用名、版本、開放端口、操作系統、服務名、地理位置等。
地址:
https://www.zoomeye.org
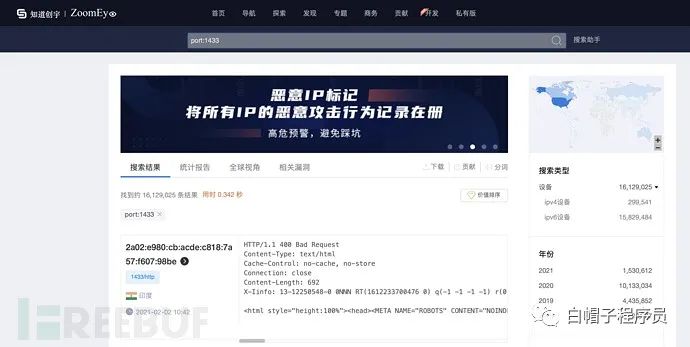
簡單語法:
app:nginx # 組件名 ver:1.0 # 版本 os:windows # 操作系統 country:"China" # 國家 city:"hangzhou" # 城市 port:80 # 端口 hostname:google # 主機名 site:google.com # 網站域名 desc:nmask # 描述 keywords:passwd # 關鍵詞 service:ftp # 服務類型 ip:8.8.8.8 # ip地址 cidr:8.8.8.8/24 # ip地址段
censys
Censys 是由密歇根大學的計算機科學家創立,幫助信息安全從業人員發現、監控和分析從互聯網訪問的設備的平臺,Censys 能夠掃描整個互聯網,每天掃描 IPv4 地址空間,以搜索所有聯網設備并收集相關的信息,并返回一份有關資源(如設備、網站和證書)配置和部署信息的總體報告。
地址:
https://censys.io/ipv4
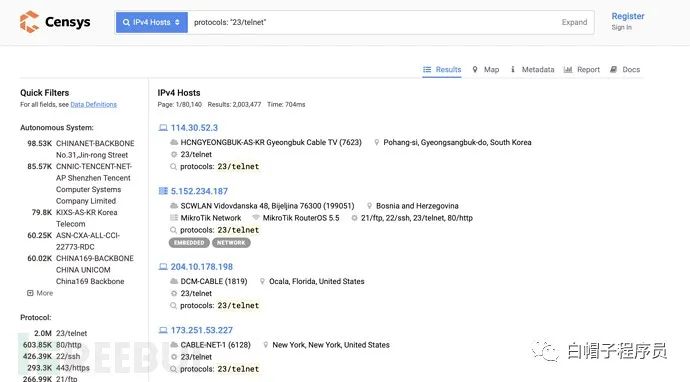
簡單語法:
23.0.0.0/8 or 8.8.8.0/24 # 可以使用and or not
80.http.get.status_code: 200 # 指定狀態
80.http.get.status_code:[200 TO 300] # 200-300之間的狀態碼
location.country_code: DE # 國家
protocols: ("23/telnet" or "21/ftp") # 協議
tags: scada # 標簽
80.http.get.headers.server:nginx # 服務器類型版本
autonomous_system.description: University # 系統描述
fofa
FOFA 是白帽匯推出的一款網絡空間搜索引擎,它通過進行網絡空間測繪,能夠幫助研究人員或者企業迅速進行網絡資產匹配,例如進行漏洞影響范圍分析、應用分布統計、應用流行度排名統計等。
地址:
https://fofa.so
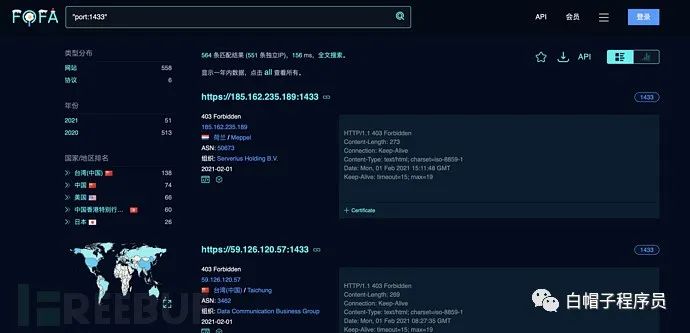
簡單語法:
title="abc" # 從標題中搜索abc。例:標題中有北京的網站。 header="abc" # 從http頭中搜索abc。例:jboss服務器。 body="abc" # 從html正文中搜索abc。例:正文包含Hacked by。 domain="qq.com" # 搜索根域名帶有qq.com的網站。例:根域名是qq.com的網站。 host=".gov.cn" # 從url中搜索.gov.cn,注意搜索要用host作為名稱。 port="443" # 查找對應443端口的資產。例:查找對應443端口的資產。 ip="1.1.1.1" # 從ip中搜索包含1.1.1.1的網站,注意搜索要用ip作為名稱。 protocol="https" # 搜索制定協議類型(在開啟端口掃描的情況下有效)。例:查詢https協議資產。 city="Beijing" # 搜索指定城市的資產。例:搜索指定城市的資產。 region="Zhejiang" # 搜索指定行政區的資產。例:搜索指定行政區的資產。 country="CN" # 搜索指定國家(編碼)的資產。例:搜索指定國家(編碼)的資產。 cert="google.com" # 搜索證書(https或者imaps等)中帶有google.com的資產。
小總結
每個平臺都有自己的特點和優勢,我們可以使用多個平臺來補充自己的結果,讓搜索的信息更全。
玩轉fofa
接下來選擇一個搜索引擎進行深入學習,我毅然決然的選擇了fofa,為什么呢?因為對它最熟悉也最有感情(因為我沖了會員QAQ)
fofa中常用語法學習
邏輯運算符
●&& :表示邏輯與
●|| :表示邏輯或
用例:
#查找使用coremail并且在中國境內的網站 app="Coremail" && country=CN #查找title中含有管理后臺或者登錄后臺的網站 title="管理后臺" || title="登錄后臺"
查找使用指定應用的IP
app=”“
用例:
#查找使用Coremail的網站 app="Coremail" #查找使用Weblogic的網站 app="BEA-WebLogic-Server"
查找使用指定協議的ip
protocol=
#查找使用mssql的ip protocol=mssql #查找使用oracle的ip protocol=oracle #查找使用redis的ip protocol=redis
查找開放特定端口的ip
port=”“
#查找開放了1433,3306,3389端口的主機 ports="1433,3306,3389" #查找只開放了1433,3306,3389端口的主機 ports=="1433,3306,3389"
查找IP或網段的信息
#查找指定ip的信息 ip="220.181.38.148" #查找指定網段的信息 ip="220.181.38.0/24"
找使用指定css或js的網站
有時候,我們碰到一個使用框架的網站,現在我們想找到所有使用該框架的網站。可以查看源代碼,找到這個框架特有的css或js文件,然后將該css或js的路徑復制粘貼到 Fofa進行查找。
利用fofa挖掘漏洞的騷操作
?先可以利?FOFA進?漏洞挖掘和安全研究。對于?帽?挖掘漏洞來講,信息收集是第?步,也是很 重要的?步。?如挖SRC的時候要進??域名收集,繞過cdn查找真實IP等。
找Burpsuite代理
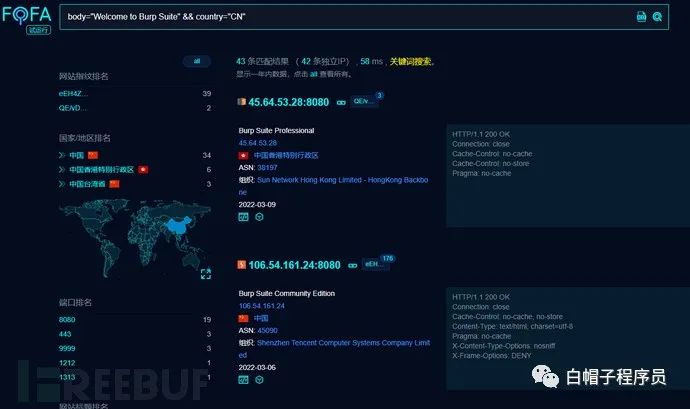
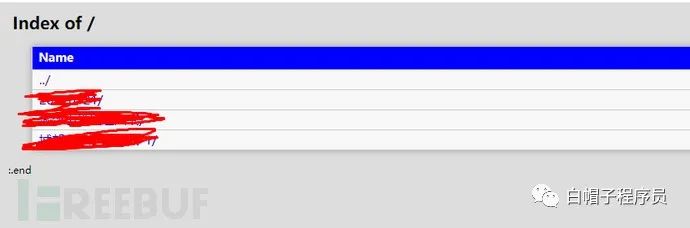
找?錄遍歷漏洞
根據?錄遍歷關鍵詞搜索,可以查到大量的結果。當然這還是在fofa經風波后被閹割的結果,全盛時期數據量更恐怖
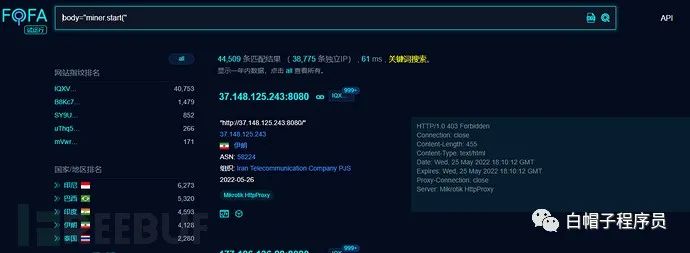
查找被黑網站
黑網站變現的有效途徑之一就是js挖礦,我們可以查找挖礦腳本的特征來搜索被黑網站
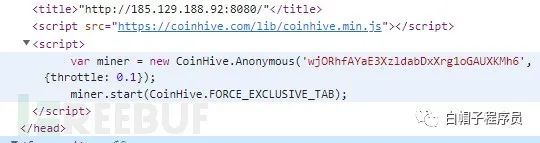
也可以利用黑頁的特征查被黑網站,例如查找“HackedBy”,能出一大坨大黑闊入侵完畢后掛的黑頁。
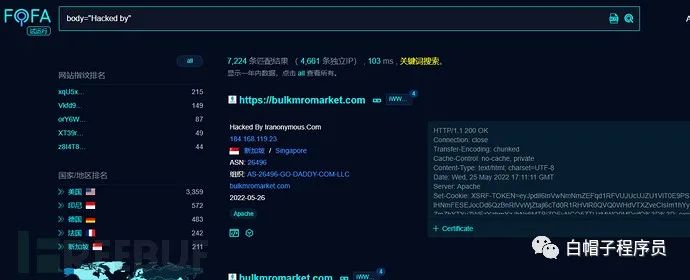
當然 還有一些很騷的操作,但都涉及違法違規,這里不再學習,一定要保持自身的潔身自好~
從fofa到shodan|網絡空間引擎是如何獲取數據的
shodan的工作原理
shodan通過爬蟲從世界各地收集數據,n采集的基本數據單位是b a n n e r。b a n n e r是描述設備所運行服務的標志性文
本信息。對于W e b服務器來說,其將返回標題或者是t e l n e t登陸界面。B a n n e r的內
容因服務類型的不同而相異。
以下這是一個典型的H T T P B a n n e r:
H T T P / 1 . 1 2 0 0 O K S e r v e r : n g i n x / 1 . 1 . 1 9 D a t e : S a t , 0 3 O c t 2 0 1 5 0 6 : 0 9 : 2 4 G M T C o n t e n t ?T y p e : t e x t / h t m l ; c h a r s e t = u t f ?8 C o n t e n t ?L e n g t h : 6 4 6 6 C o n n e c t i o n : k e e p ?a l i v e #上面的b a n n e r顯示該設備正在運行一個1.1.19版本的n g i n x W e b服務器軟件
除了獲取b a n n e r,S h o d a n還可以獲取相關設備的元數據,例如地理位置、主機
名、操作系統等信息。大部分元數據可以通過S h o d a n的官網獲取,小部分的可以通
過使用A P I編程獲取。
如下是shodan獲取數據的流程圖:

fofa的工作原理
fofa的收錄是基于端口掃描的收錄,底層原理就類似一個掃全網的zmap加上各種指紋識別的腳本和規則來維護的,基于:IP、端口、指紋、部分域名子域名的關系數據庫。
什么樣的東西可以被fofa收錄
例子
是否會被收錄
解釋
111.111.111.111:80 是 IP、端口兩要素 111.111.111.111:80/test/test.html 否 僅會收錄根目錄返回結果,二級目錄不會收錄,fofa不會進行目錄掃描 http://baidu.com:80 可能 某些特定情況下,可能會掃到baidu.com對應的IP,并且該IP未作針對性防護 http://baidu.com:80/test/test.html 可能(概率很小) 唯一一種可能的情況就是/test/目錄單獨解析到某個IP,或服務由某個IP節點提供 |
上面列舉了一些可能被收錄的和不會被收錄的資產,fofa搜索開始之前就應該了解,自己搜索什么可以搜到東西,而搜索什么不可能找到東西。
原理應用:Title & Header & Body 與 Html search
Title顧名思義就是網站的標題,相應的,header,body對應網站的頭部,主體。
假如在滲透測試時我們想搜集某一主體相關的資產,我們可能匹配的是Title & Header & Body 存在主體的名稱,如:
title="XX市XX醫院"
這一條可以匹配的是標題中含有“XX市XX醫”的資產,標題為"XX醫院"的某些資產也可能是XX市XX醫院的資產,我們就無法獲取這部分資產信息。這時我們如何才能最大化的匹配到相關資產呢
title="XX市" && title="XX醫院"
這條規則比上面 的規則可以匹配到更多的資產,但是會搜索到目標之外的結果,例如”XX市XX醫院與AA醫院合作系統“。所以搜索的時候拆分title來搜索可以獲得更多的搜索結果和更大的搜索范圍,但是可能會帶來臟數據。body,header同理。
當我們分別查找title、header、body的關鍵字的時候總覺得太麻煩,能不能直接搜索一次就包含所有的搜索結果呢?答案是肯定的。
這就需要我們認識html參數。我們來看一下html包含什么
首頁 - XX管理系統 body welcome to my web user: pass: 版權信息:XX市XX醫院
上面的代碼可以看到,footer里面包含我們的目標關鍵字,但是fofa中并沒有專門搜索footer的語法,那么我們怎么把這個結果搜索到呢?如下代碼就可以了:
"XX市XX醫院"
看一眼這個語法,應該不用解釋了,過濾掉容易出現辣雞網站的地區==只要中國的結果==,其中==容易出現辣雞數據的HK==也進行過濾,會清爽很多。
原理應用:通過api接口的特殊姿勢進行資產搜集
有時同一主體的全部資產,會調用有些API接口,直接訪問這些api接口會報錯:
MiniGo API MINIGO 微信小程序 歡迎使用XX WebAPI中間服務,當前版本為V2.0.1.5
以上這種情況,我反手就是一個:
"歡迎使用XX WebAPI中間服務,當前版本為V2.0.1.5" "歡迎使用XX WebAPI中間服務"
通過這種方式,我們能夠獲取相關主體的:
1. IP資產 2. 關聯相關IP段 3. 端口掃描
原理應用:通過證書獲取資產
我們肯定都見過這樣的頁面
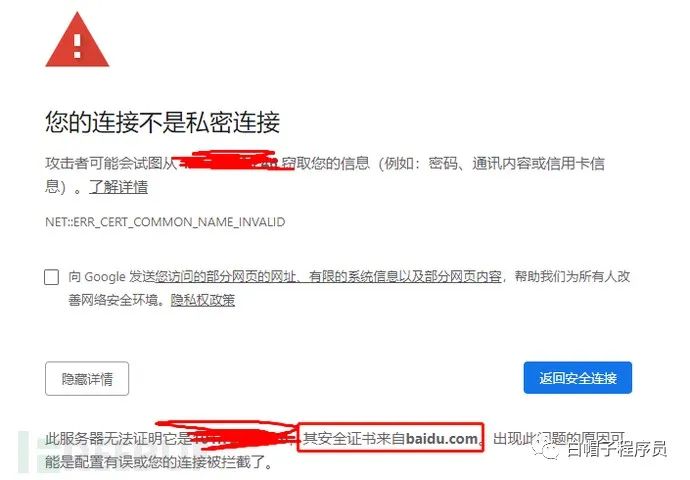
可以看到證書來自baidu.com了吧,百度的資產是不是要使用百度證書?我們就可以這樣搜索
cert="baidu.com"
通過以上結果可以得出不光【baidu.com】,屬于百度的好多域名都知道了
原理應用:資產搜集CDN繞過
1.通過證書查詢方式
cert="baidu.com"
這個可以繞過一部分SSL網站的CDN直接看到真實IP
1.通過某些主頁特殊關鍵字
"百度一下 你就知道"
某些網站沒有對IP直接訪問做限制,可以直接訪問
1.某些特殊接口
比如你訪問某個接口給你返回一個
"baidu OK!"
后記
今天我們由淺入深的了解一下關于網絡空間搜索引擎的使用方法,搜索原理,收獲頗豐,學會了使用網絡空間搜索引擎來進行信息搜集服務于我們的滲透測試工作
