一種基于Graph Kernel的API使用示例選擇方法
開發人員在編寫代碼的過程中,通常會希望知道某個API的具體使用方法(也就是使用示例)。過去的研究主要是通過聚類和總結的方法從代碼庫中提取相關的代碼片段來生成示例代碼,也就是說:將源代碼轉換成方法調用序列或特征向量;這種方法只對源代碼的部分進行建模,因此容易產生不準確的示例。
在這篇文章中,作者將源代碼表示為對象使用圖,使用graph kernel進行圖嵌入以進行聚類,通過排名從每個集群中選擇一個代碼表圖來輸出代碼示例。模型相關內容詳見:https://guxd.github.io/codekernel/。
圖1是CodeKernel模型的應用場景。離線處理階段的目標是選擇代碼示例:收集每個API相關的代碼片段,使用CodeKernel模型選擇對應的API使用示例。在運行過程中,給定一個API請求,系統會給出與該API對應的代碼示例。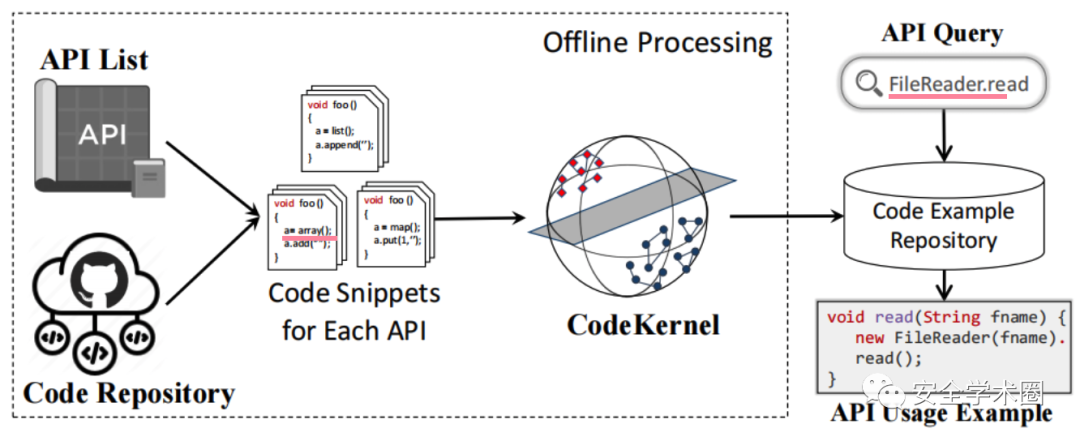
Fig. 1 CodeKernel模型使用場景
圖2是模型的Workflow。模型的輸入是一系列來自開源項目和代碼搜索結果的原始代碼片段。原始代碼片段首先會被轉換成對象圖(如圖3所示);然后使用graph kernel將其嵌入到連續空間中,得到內積矩陣;在內積矩陣上使用聚類算法進行圖聚類(使用譜聚類算法);最后基于排序的方法從每個集群中選擇代碼圖,將其還原為代碼示例。
 Fig. 2 模型Workflow
Fig. 2 模型Workflow
本文中,使用GrouMiner[1]構建函數級對象圖。對象圖包含文本、序列、結構和數據依賴的信息,忽略了語法細節,能夠較為完整地表示源代碼,是局部上下文不敏感的。
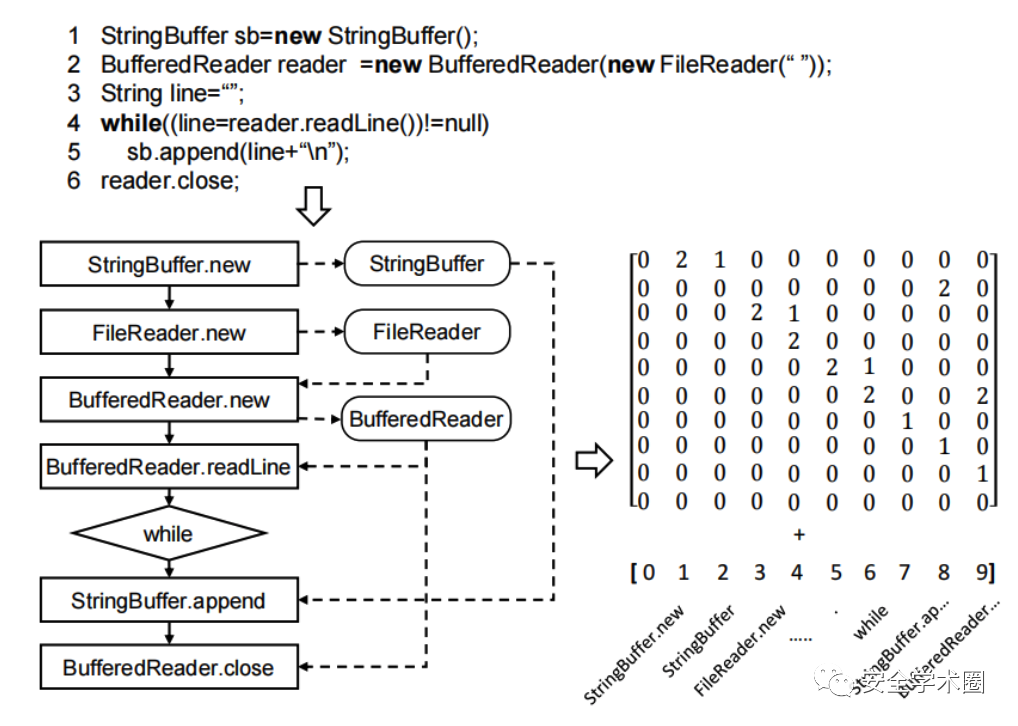 Fig. 3 對象圖示例
Fig. 3 對象圖示例
 Fig. 4 CodeKernel偽代碼
Fig. 4 CodeKernel偽代碼
聚類后的結果通過兩種排序度量指標進行排序。
- Centrality:從集群中選擇的圖與集群中的其他圖要有很高的相似性,也就是高代表性。
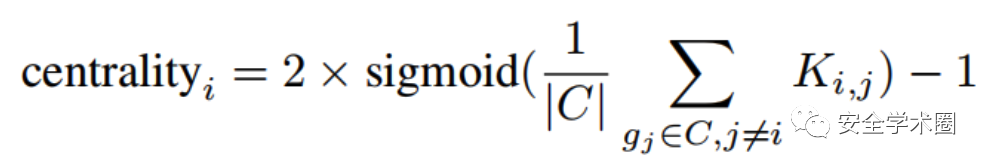
- Specificity:具有高代表性的圖可能傾向于更大的圖,因為它們更可能與其他圖相似。但是,較大的圖往往有更多的特定元素(即,在集群中很少出現的邊),這使得代碼示例難以理解。Specificity指標的目的是為了懲罰有太多特定邊的圖。
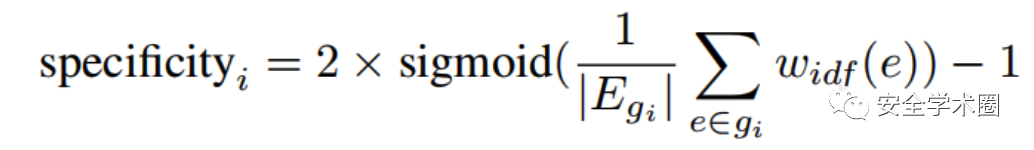
最終,排序分數通過如下公式計算得出。
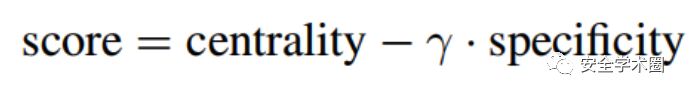
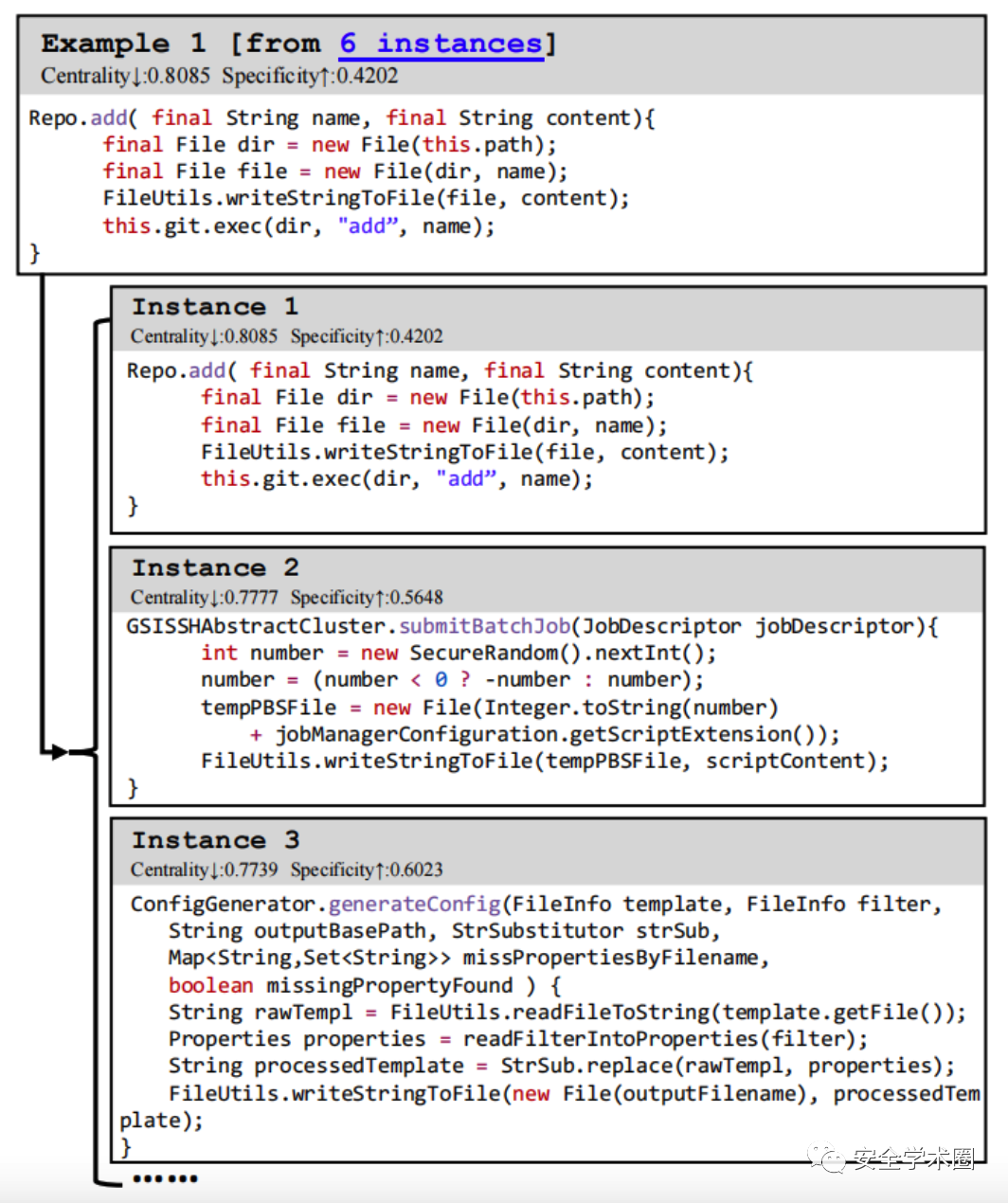 Fig. 5 CodeKernel模型產生的代碼示例
Fig. 5 CodeKernel模型產生的代碼示例
參考文獻
[1] Nguyen T T, Nguyen H A, Pham N H, et al. Graph-based mining of multiple object usage patterns[C]//Proceedings of the 7th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT symposium on the Foundations of Software Engineering. 2009: 383-392.
