使用unicorn engin還原Armariris字符串混淆
git clone git@github.com:gossip-sjtu/Armariris.git
編譯
cd Armariris mkdir build cd build cmake ../ -DCMAKE_BUILD_TYPE=Release -DLLVM_TARGETS_TO_BUILD="ARM;X86;AArch64" make -j8
測試文件內容如下:
#include
void fun(){
printf("test 3333");
}
int main(int argc, char *argv[]) {
printf("test 1111");
printf("test 2222");
fun();
return 0;
}
使用編譯好的llvm編譯這個測試的文件
clang -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk -mllvm -sobf test.c -o test
使用isysroot指定sdk,然后使用-mllvm -sobf開啟字符串混淆
Armariris是如何進行字符串混淆的
我們直接看使用ida反匯編出來的代碼
int __cdecl main(int argc, const char **argv, const char **envp)
{
printf(aRcur7777, argv, envp);
printf(&byte_100001036);
fun();
return 0;
}
可以看到有兩個printf函數打印了一些數據出來,我們點第一個打印的字符串,雙擊aRcur7777跳轉到 字符串定義位置,這個字符串在data段

這個字符串我們本來輸出的是test 1111這里顯然不是,我們查看aRcur7777的交叉引用,發現兩處, 其中一處是main函數中的printf,另一處應該就是還原這個字符串的位置了
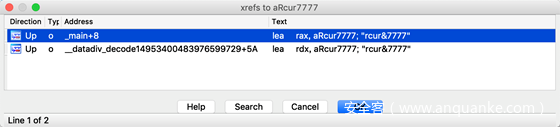
所以__datadiv_decode14953400483976599729這個函數就是還原這個字符的函數,我們看他是如何做的還原 。跳轉過去按F5反編譯,得到的結果如下:
__int64 datadiv_decode14953400483976599729()
{
bool v0; // ST23_1
bool v1; // ST17_1
__int64 result; // rax
bool v3; // ST0B_1
unsigned int v4; // [rsp+8h] [rbp-1Ch]
unsigned int v5; // [rsp+14h] [rbp-10h]
unsigned int v6; // [rsp+20h] [rbp-4h]
v6 = 0;
do
{
aLKl[v6] ^= 0x38u;
v0 = v6++ < 0xA;
}
while ( v0 );
v5 = 0;
do
{
aRcur7777[v5] ^= 6u;
v1 = v5++ < 0xA;
}
while ( v1 );
v4 = 0;
do
{
byte_100001036[v4] ^= 0x71u;
result = v4 - 10;
v3 = v4++ < 0xA;
}
while ( v3 );
return result;
}
我們可以看到aRcur7777的還原是和6做了異或操作,那我們來驗證一下是否是我們看到的這樣。
aRcur7777的原始數據是[0x72, 0x63, 0x75, 0x72, 0x26, 0x37, 0x37, 0x37, 0x37]
每一位和6異或之后的結果是[0x74, 0x65, 0x73, 0x74, 0x20, 0x31, 0x31, 0x31, 0x31]
對于的ascii字符串就是test 1111
他這里做字符串混淆用的是一個很簡單的原理,一個數字兩次異或同一個值,得到的結果是本事的值。也就是 第一次異或就給字符串混淆了,再異或一次就把數據還原了。
源碼分析
字符串混淆的源文件在lib/Transforms/Obfuscation/StringObfuscation.cpp這個位置, 實現字符串混淆的是一個ModulePass,關于ModulePass可以參考http://llvm.org/doxygen/classllvm11ModulePass.html#details 。在這個pass里面會遍歷字符串,然后把字符串和生成的key異或,并替換原始的值,關鍵代碼如下:
// Duplicate global variable
GlobalVariable *dynGV = new GlobalVariable(M,
gv->getType()->getElementType(),
!(gv->isConstant()), gv->getLinkage(),
(Constant*) 0, gv->getName(),
(GlobalVariable*) 0,
gv->getThreadLocalMode(),
gv->getType()->getAddressSpace());
// dynGV->copyAttributesFrom(gv);
dynGV->setInitializer(gv->getInitializer());
std::string tmp=gv->getName().str();
// errs()<<"GV: "<<*gv<<"";
Constant *initializer = gv->getInitializer();
ConstantDataSequential *cdata = dyn_cast(initializer);
if (cdata) {
const char *orig = cdata->getRawDataValues().data();
unsigned len = cdata->getNumElements()*cdata->getElementByteSize();
encVar *cur = new encVar();
cur->var = dynGV;
cur->key = llvm::cryptoutils->get_uint8_t();
// casting away const is undef. behavior in C++
// TODO a clean implementation would retrieve the data, generate a new constant
// set the correct type, and copy the data over.
//char *encr = new char[len];
//Constant *initnew = ConstantDataArray::getString(M.getContext(), encr, true);
char *encr = const_cast(orig);
// Simple xor encoding
for (unsigned i = 0; i != len; ++i) {
encr[i] = orig[i]^cur->key;
}
// FIXME Second part of the unclean hack.
dynGV->setInitializer(initializer);
// Prepare to add decode function for this variable
encGlob.push_back(cur);
} else {
// just copying default initializer for now
dynGV->setInitializer(initializer);
}
// redirect references to new GV and remove old one
gv->replaceAllUsesWith(dynGV);
toDelConstGlob.push_back(gv);
在替換了之后為了保證程序可以正常運行,還得加一個函數輸還原字符串,還原字符串的 函數生成代碼在addDecodeFunction中。在這里添加了.datadiv_decode開始的函數 加上一串隨機字符串,里面進行了異或操作,將數據還原。然后將這個函數加入到了entry,這個在 elf文件的話,就會被加入到.init_array,在mach-o文件中就會被加入到__mod_init_func。代碼也比較簡單,可以參照源碼看一下。
還原字符串
前面講了原理其實很簡單,那么怎么還原字符串呢,其實也有很多方式,第一種是內存dump,因為他會在 初始化程序的時候就把原始字符串還原回去。但是有時候我就行靜態分析,不想執行之后去dump。如果只 靜態分析,也可以去人工還原字符串。但是如果字符串很多,人工還原工作量很大。其實我們還可以使用 unicorn之類的工具,模擬去執行他的指令,把字符串進行還原。
還原混淆字符串的思路
- 找到所有.datadiv_decode開始的函數
- unicorn分配內存,將程序的.text段和.data段映射到unicorn分配的內存中
- 模擬執行所有.datadiv_decode開始的函數
- 最后將unicorn中分配的data讀出來,patch到程序中
使用的工具
因為不同操作系統可執行文件格式不一樣。為了簡單點,我們直接寫一個ida插件。所以需要以下工具:
- ida
- python2 (因為ida里面內置的python是python2)
- python2安裝unicorn和keystone庫
找到所有的.datadiv_decode開始的函數
idautils.Functions()可以遍歷函數,遍歷匹配含有datadiv_decode的函數,保存他們 的起始地址,代碼很簡單,如下:
import idaapi import idc import idautils for func in idautils.Functions(): func_name = idc.GetFunctionName(func) if "datadiv_decode" in func_name: func_data = idaapi.get_func(func) start = func_data.start_ea end = func_data.end_ea
unicorn分配內存
我這里分配內存的想法是直接用ida的api獲取data段和text段的內容,以及起始地址,然后在 unicorn里面對于起始分配內存,將data段和text段寫進去。
unicorn分配內存還是有些坑,不能直接在任意地址分配,必須得整除1024的才可以,所以需 要稍微計算一下分配的地址。這里對基地址減去對(1024 * 1024)求余的結果作為新的基地址, 然后分配內存的長度增加(1024 * 1024),實現的代碼如下
def get_base_and_len(base, length): _base = base - (base % (1024 * 1024)) _length = (length / (1024 * 1024) + 1) * 1024 * 1024 return _base, _length
算出起始地址之后使用unicorn的mem_map方法分配內存即可
模擬執行,patch程序
模擬執行這里也比較簡單,直接調用unicorn的emu_start方法,然后傳入函數的起始地址即可開始 模擬執行,模擬執行完成之后將data段讀出來,模擬執行下一個函數的時候使用這個data加載到內存中。這樣所有的.datadiv_decode函數執行之后data段就被還原了。將還原的data段用ida的patch去 修改掉原始的data,這個時候你看到的字符串就是原始的字符串了。
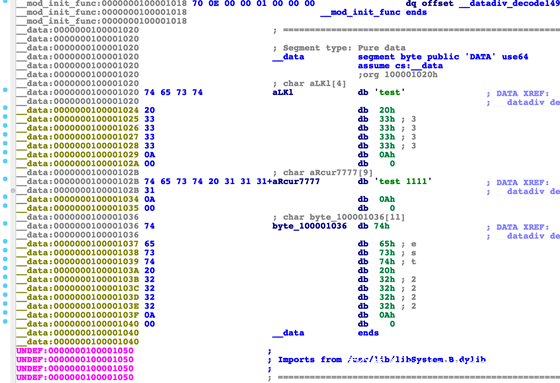
運行腳本前效果如下:

運行腳本之后效果如下:

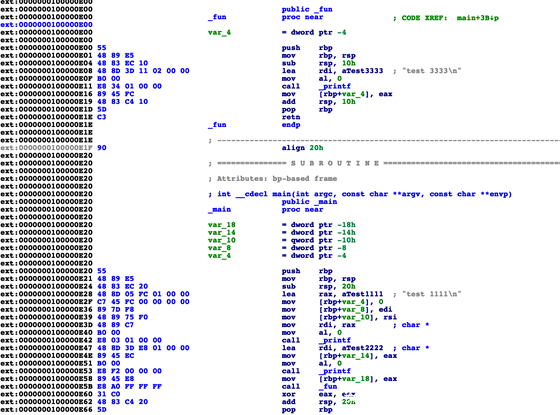
這個時候可以選中字符串,然后按a就能得到下面的效果

完整代碼以及示例二進制文件
代碼以及二進制文件存放在https://github.com/smartdone/re_scripts/tree/master/ida 其中Armaririsstringobfuscationbypass.py是ida用來還原Armariris混淆過的字符串的插件。sample里面的testlinuxx8664和testmacosx86_64是示例二進制文件。
如果本文說的有錯誤的地方,請及時指正,謝謝。
