從Falco看如何利用eBPF檢測系統調用
一、eBPF
1.1簡介
eBPF是一項革命性的技術,可以在操作系統內核中運行沙盒程序。它用于安全有效地擴展內核的功能,而無需更改內核源代碼或加載內核模塊。通過允許在操作系統中運行沙箱程序,應用程序開發人員可以運行eBPF程序,以便在運行時向操作系統添加額外的功能。然后,操作系統保證安全性和執行效率,就像在實時(JIT)編譯器和驗證引擎的幫助下進行本機編譯一樣。這導致了一波基于eBPF的項目,涵蓋了廣泛的用例,包括下一代網絡、可觀察性和安全功能。
eBPF程序是事件驅動的,當內核或應用程序通過某個hook時運行。預定義的hook包括system calls, 函數的entry/exit, kerneltracepoints, network 事件等等。圖1展示了eBPF在hook系統調用時程序調用的實際以及如何獲取系統的數據。

圖1 eBPF在hook系統調用時的執行位置
eBPF可以對接多種類型的探針:
? Kprobes
? Kretprobes
? Tracepoints
? Uprobes
? Uretprobes
? ...
eBPF中有兩個比較重要的部分:Prog和 Map。
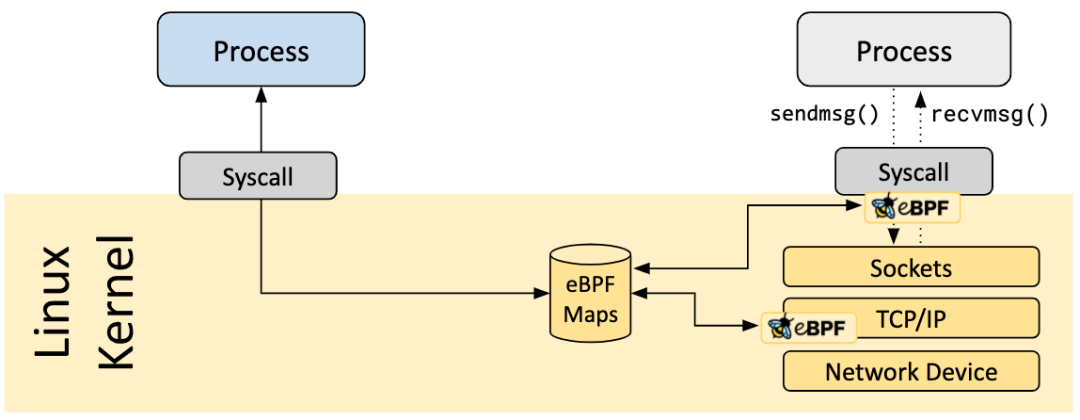
圖2 eBPF采用Map實現Prog 之前的數據通信
? eBPF Prog
為了細分不同類型的eBPF程序,截止到Kernel 5.8, eBPF劃分了30種不同的eBPF 程序類型[1]。每種eBPF只能實現的有限的功能 。內核提供了一系列可供eBPF程序調用的內核函數來實現功能的可控,保障eBPF程序的安全性。這些內核函數通常被稱為 helper輔助函數[2]。不同類型的程序可以使用不同的helper輔助函數。有關Prog的類型詳解:使用場景、函數簽名、執行位置及程序示例可以查閱產考文獻[3]。
? eBPF Map
Map是一種用來存儲不同數據的動態的數據類型,允許在內核態的程序之間共享數據,也能夠在內核態和用戶態應用之間共享數據。可以實現用戶態和內核態的雙向實時通信。
隨著版本迭代與功能的擴展細化,目前bpf_map_type已經有28不同類型的map[4]。所以在使用map時,需要根據應用場景指定一個合適的類型。關于BPF Map 類型詳解使用可以參考[5]。map大致可以分為下面幾種類型:
? Hash tables, Arrays
? LRU (Least Recently Used)
? Ring Buffer
? Stack Trace
? LPM (Longest Prefix match)
? ...
1.2編寫eBPF
內核中提供了bpf系統調用:
int bpf(int cmd,union bpf_attr *attr,unsigned int size);
但在許多場景中,bpf不是直接使用,而是通過Cilium[6]、bcc[7]或bpftrace[8],goebpf[9],libbpf[10]等項目間接使用。這些項目在eBPF之上提供了一個抽象,不需要直接編寫程序,而是提供了指定基于意圖定義的能力,然后用eBPF實現這些定義。在 linux 源碼中的 samples/bpf [11] 目錄下可以找到對應的例子。關于eBPF的編寫和使用也可以參閱往期文章[12]。
1.3eBPF應用場景
得益于eBPF的強大能力,一大批基于eBPF的優秀開源項目相繼涌現,如BPFTrace,Katran[13],Cilium,Falco[14],Pixie[15],eBPF Exporter[16]等等,覆蓋觀測跟蹤,網絡,安全等各個方面。在國內,各家云廠商也開始采用eBPF技術來優化系統設計。下面我們將以Falco為例,展示下eBPF是如何實現安全監控的能力的。
二、Falco
2.1簡介
Falco最初是由Sysdig[17]創建的,后來加入CNCF孵化器,成為首個加入CNCF的運行時安全項目。可以實現對調用行為的監控,并依賴于強大的規則引擎,對異常的系統調用行為進行告警。
2.2Falco架構
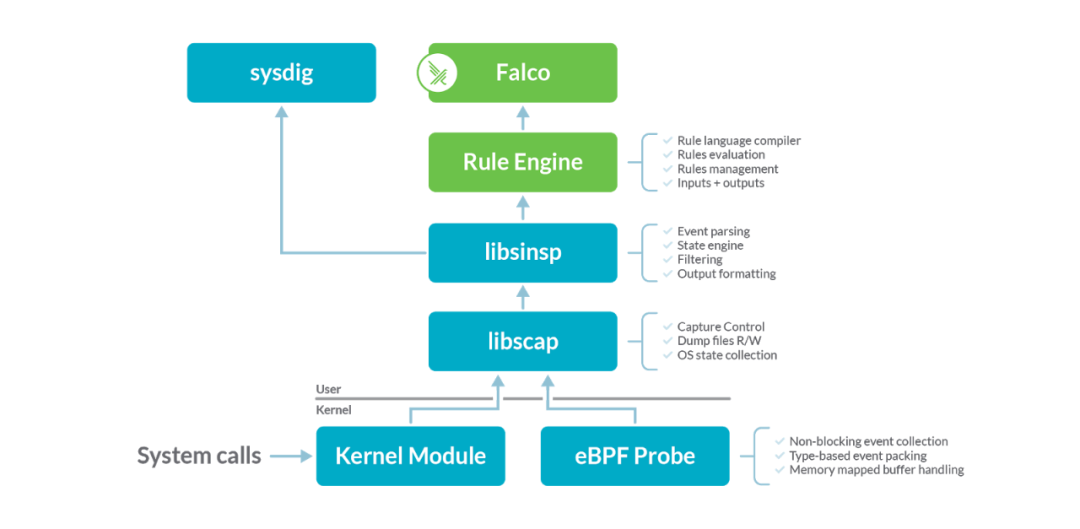
圖3 Falco架構
Falco架構圖如圖3所示。有關Falco的具體的介紹和使用可以參考往期文章【探索SysdigFalco:容器環境下的異常行為檢測工具】,本文重點關注Falco對系統調用的采集。Falco對系統調用的采集有兩種模式:
? LKM (Linux Kernel Module)內核擴展模塊
? eBPF Probe.
這兩種方法在功能上是相同的,但內核模塊的效率要高一些,而eBPF方法更安全。
Falco的eBPF模塊主要是對內核的靜態探針Tracepoints進行hook,之所以沒有采用動態探針Kprobes,是因為Kprobes并不是一種穩定的探針,可能會隨著內核的迭代更新而新增或者刪除,對內核版本的依賴性較高,因此兼容性與穩定性也就較差。
sysdig在他們的官方博客對eBPFdriver的評價[18]如下:
可能是這個星球上最雄心勃勃的、最復雜的eBPF腳本。
下面我們從Falco利用eBPF監控系統調用的代碼層面[19],了解下Falco如何利用eBPF實現系統調用的監控。
Falco主要是使用系統的raw_tracepoint或者tracepoint,這取決于不同內核所能提供的能力。
# 從linux kernel 4.17后,添加了raw_tracepoint類型。#if LINUX_VERSION_CODE >= KERNEL_VERSION(4, 17,0)#define BPF_SUPPORTS_RAW_TRACEPOINTS#endif #ifdef BPF_SUPPORTS_RAW_TRACEPOINTS#define TP_NAME "raw_tracepoint/"#else#define TP_NAME "tracepoint/"#endif #ifdef BPF_SUPPORTS_RAW_TRACEPOINTS#define BPF_PROBE(prefix,event,type)\ __bpf_section(TP_NAME #event)int bpf_##event(struct type*ctx)#else#define BPF_PROBE(prefix,event,type)\ __bpf_section(TP_NAME prefix #event)int bpf_##event(struct type*ctx)#endif
Falco的eBPF驅動提供了以下幾種類型的調用采集的能力。
BPF_PROBE("raw_syscalls/", sys_enter, sys_enter_args)BPF_PROBE("raw_syscalls/", sys_exit, sys_exit_args)BPF_PROBE("sched/", sched_process_exit, sched_process_exit_args)BPF_PROBE("sched/", sched_switch, sched_switch_args)BPF_PROBE("exceptions/", page_fault_user, page_fault_args)BPF_PROBE("exceptions/", page_fault_kernel, page_fault_args)BPF_PROBE("signal/", signal_deliver, signal_deliver_args)
下面以tracepoint:syscalls:sys_enter為例分析下,Falco是如何利用eBPF來采集系統調用的詳細信息的。
BPF_PROBE("raw_syscalls/", sys_enter, sys_enter_args){ ... // 獲取系統調用的系統調用相關信息 id =bpf_syscall_get_nr(ctx); sc_evt =get_syscall_info(id); evttype = sc_evt->enter_event_type; ... // 調用具體系統調用的信息采集方法#ifdef BPF_SUPPORTS_RAW_TRACEPOINTS call_filler(ctx, ctx, evt_type, settings, drop_flags);#else /* Duplicated here to avoid verifier madness */ structsys_enter_args stack_ctx;
memcpy(stack_ctx.args, ctx->args,sizeof(ctx->args)); if(stash_args(stack_ctx.args)) return0; call_filler(ctx,&stack_ctx, evt_type, settings, drop_flags);#endif return0;}
可以看到,這只是入口,實際的eBPF的程序是使用bpf_tail_call()尾調用機制調用的。有關bpf_tail_call的介紹可以從參考文獻[20]中獲取。
static __always_inline void call_filler(void *ctx, void *stack_ctx, enum ppm_event_typeevt_type, struct sysdig_bpf_settings *settings, enum syscall_flags drop_flags){ ... bpf_tail_call(ctx,&tail_map, filler_info->filler_id); bpf_printk("Can't tail call fillerevt=%d, filler=%d", state->tail_ctx.evt_type, filler_info->filler_id); ...}
bpf_tail_call是從tail_map獲取指定的BPF 程序執行。tail_map是type為BPF_MAP_TYPE_PROG_ARRAY的map集合。這種類型的 array 存放的是BPF 程序的文件描述符(fd),在尾調用時使用。
struct bpf_map_def __bpf_section("maps") tail_map ={ .type = BPF_MAP_TYPE_PROG_ARRAY, .key_size =sizeof(u32), .value_size =sizeof(u32), .max_entries = PPM_FILLER_MAX,};
tail_map中的BPF 程序位于driver/bpf/fillers.h中,考慮代碼復用,里面使用了大量的宏定義。
#define FILLER(x,is_syscall) \static__always_inline int__bpf_##x(struct filler_data *data); \ \__bpf_section(TP_NAME "filler/" #x) \static__always_inline int bpf_##x(void*ctx) \{ \ struct filler_data data; \ intres; \ \ res=init_filler_data(ctx,&data,is_syscall); \ if(res==PPM_SUCCESS){ \ if(!data.state->tail_ctx.len) \ write_evt_hdr(&data); \ res=__bpf_##x(&data); \ } \ \ if(res==PPM_SUCCESS) \ res=push_evt_frame(ctx,&data); \ \ if(data.state) \ data.state->tail_ctx.prev_res=res; \ \ bpf_tail_call(ctx,&tail_map,PPM_FILLER_terminate_filler);\ bpf_printk("Can't tail call terminate filler"); \ return 0; \} \ \static__always_inline int __bpf_##x(struct filler_data *data) \
FILLER(sys_open_x,true){ ... // 調用參數采集 res = bpf_val_to_ring(data, dev); return res;}FILLER(sys_empty,true)...
可以將宏定義還原后,查看簡化的代碼結構如下:
static __always_inline int __bpf_sys_open_x(struct filler_data *data);
__bpf_section(TP_NAME "filler/" sys_open_x) static __always_inline int bpf_sys_open_x(void *ctx){ ... // 調用實際的信息獲取的方法,采集系統調用信息 res = __bpf_sys_open_x(&data); ... if(res == PPM_SUCCESS) // 將采集的數據發送給用戶態程序 res = push_evt_frame(ctx,&data); ...}
static __always_inline int __bpf_sys_open_x(struct filler_data *data){... // 調用參數采集,并將結果填充到data結構體中 if(retval <0||!bpf_get_fd_dev_ino(retval,&dev,&ino)) dev =0; res = bpf_val_to_ring(data, dev); return res;}static __always_inline int push_evt_frame(void *ctx, struct filler_data *data){ ...
#ifdef BPF_FORBIDS_ZERO_ACCESS int res = bpf_perf_event_output(ctx, &perf_map, BPF_F_CURRENT_CPU, data->buf, ((data->state->tail_ctx.len -1)& SCRATCH_SIZE_MAX)+1);#else int res = bpf_perf_event_output(ctx, &perf_map, BPF_F_CURRENT_CPU, data->buf, data->state->tail_ctx.len & SCRATCH_SIZE_MAX);#endif
可以看到, push_evt_frame中實際是bpf_perf_event_output()將獲取到的數據發送到perf_map,利用perf 緩沖區從內核向用戶空間發送數據。但是perf 緩沖區基于單個CPU的設計本身會有一定的缺陷,因此Linux 5.8開始 ,BPF提供了新的數據結構:BPF環形緩沖區(ringbuf)。有興趣的讀者可以從參考文獻中了解更為詳細的細節。關于BPF perfbuf和ringbuf的詳細資料可以參考[21]。
struct bpf_map_def __bpf_section("maps") perf_map ={ .type = BPF_MAP_TYPE_PERF_EVENT_ARRAY, .key_size =sizeof(u32), .value_size =sizeof(u32),// 只能是 sizeof(u32) ,代表的是 perf_event 的文件描述符 .max_entries =0,//是perf_event 的文件描述符數量。};
perf_map是一個type為BPF_MAP_TYPE_PERF_EVENT_ARRAY的map。與其他array、hash 類型的eBPF map不同,BPF_MAP_TYPE_PERF_EVENT_ARRAY采用bpf_perf_event_output()往map中填充數據。
在這時用戶態程序就可以從perf 緩沖區中獲取到記錄數據,傳入Falco的規則引擎中進行匹配分析。
三、總結
如今,eBPF被廣泛用于推動各種各樣的用例:在現代數據中心和云原生環境中提供高性能網絡和負載均衡,以低開銷提取細粒度的安全可觀察性數據,幫助應用程序開發人員跟蹤應用程序,為性能故障排除、預防性應用程序和容器運行時安全實施提供見解等等。
本文以Falco為例,分析了eBPF在安全監控領域的使用方式。這只是eBPF技術的一個很小的應用場景,其他諸如加速網絡訪問,遠程調試程序等等場景使用eBPF技術都能有很好的效果,有興趣的讀者也可以關注下。
參考文獻
[1]. https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md#program-types
[2]. https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
[3]. http://arthurchiao.art/blog/bpf-advanced-notes-1-zh/
[4]. https://github.com/torvalds/linux/blob/v5.8/include/uapi/linux/bpf.h#L122
[5]. http://arthurchiao.art/blog/bpf-advanced-notes-3-zh/#3-bpf_map_type_prog_array
[6]. https://github.com/cilium/cilium
[7]. https://github.com/iovisor/bcc
[8]. https://github.com/iovisor/bpftrace
[9]. https://github.com/dropbox/goebpf
[10]. https://github.com/libbpf/libbpf
[11]. https://github.com/torvalds/linux/tree/master/samples/bpf
[12]. https://mp.weixin.qq.com/s?__biz=MzIyODYzNTU2OA==&mid=2247487440&idx=1&sn=cb6379cfc4a1bba0881363840afc438a&chksm=e84fa90fdf38201990781e3c95d9857e6d4ad083ce40a575e1cbdc12aaabb4f58ba527dc58c1&scene=21#wechat_redirect。
[13]. https://github.com/facebookincubator/katran
[14]. https://github.com/falcosecurity/falco
[15]. https://github.com/pixie-io/pixie
[16]. https://github.com/cloudflare/ebpf_exporter
[17]. https://sysdig.com/
[18]. https://sysdig.com/blog/sysdig-contributes-falco-kernel-ebpf-cncf
[19]. https://github.com/falcosecurity/libs/tree/master/driver/bpf
[20]. https://lwn.net/Articles/645169/
[21]. https://www.ebpf.top/post/bpf_ring_buffer
