搞懂ELK并不是一件特別難的事
本篇文章主要介紹ELK的一些框架組成,原理和實踐,采用的ELK本版為7.7.0版本。
ELK介紹
ELK簡介
ELK是Elasticsearch、Logstash、Kibana三大開源框架首字母大寫簡稱(但是后期出現的Filebeat(beats中的一種)可以用來替代Logstash的數據收集功能,比較輕量級)。市面上也被成為Elastic Stack。
Filebeat是用于轉發和集中日志數據的輕量級傳送工具。Filebeat監視您指定的日志文件或位置,收集日志事件,并將它們轉發到Elasticsearch或 Logstash進行索引。Filebeat的工作方式如下:啟動Filebeat時,它將啟動一個或多個輸入,這些輸入將在為日志數據指定的位置中查找。對于Filebeat所找到的每個日志,Filebeat都會啟動收集器。每個收集器都讀取單個日志以獲取新內容,并將新日志數據發送到libbeat,libbeat將聚集事件,并將聚集的數據發送到為Filebeat配置的輸出。
Logstash是免費且開放的服務器端數據處理管道,能夠從多個來源采集數據,轉換數據,然后將數據發送到您最喜歡的“存儲庫”中。Logstash能夠動態地采集、轉換和傳輸數據,不受格式或復雜度的影響。利用Grok從非結構化數據中派生出結構,從IP地址解碼出地理坐標,匿名化或排除敏感字段,并簡化整體處理過程。
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎,是一個基于Lucene、分布式、通過Restful方式進行交互的近實時搜索平臺框架。Elasticsearch為所有類型的數據提供近乎實時的搜索和分析。無論您是結構化文本還是非結構化文本,數字數據或地理空間數據,Elasticsearch都能以支持快速搜索的方式有效地對其進行存儲和索引。
Kibana是一個針對Elasticsearch的開源分析及可視化平臺,用來搜索、查看交互存儲在Elasticsearch索引中的數據。使用Kibana,可以通過各種圖表進行高級數據分析及展示。并且可以為Logstash和ElasticSearch提供的日志分析友好的 Web 界面,可以匯總、分析和搜索重要數據日志。還可以讓海量數據更容易理解。它操作簡單,基于瀏覽器的用戶界面可以快速創建儀表板(Dashboard)實時顯示Elasticsearch查詢動態。
為什么要使用ELK
日志主要包括系統日志、應用程序日志和安全日志。系統運維和開發人員可以通過日志了解服務器軟硬件信息、檢查配置過程中的錯誤及錯誤發生的原因。經常分析日志可以了解服務器的負荷,性能安全性,從而及時采取措施糾正錯誤。
往往單臺機器的日志我們使用grep、awk等工具就能基本實現簡單分析,但是當日志被分散的儲存不同的設備上。如果你管理數十上百臺服務器,你還在使用依次登錄每臺機器的傳統方法查閱日志。這樣是不是感覺很繁瑣和效率低下。當務之急我們使用集中化的日志管理,例如:開源的Syslog,將所有服務器上的日志收集匯總。集中化管理日志后,日志的統計和檢索又成為一件比較麻煩的事情,一般我們使用grep、awk和wc等Linux命令能實現檢索和統計,但是對于要求更高的查詢、排序和統計等要求和龐大的機器數量依然使用這樣的方法難免有點力不從心。
一般大型系統是一個分布式部署的架構,不同的服務模塊部署在不同的服務器上,問題出現時,大部分情況需要根據問題暴露的關鍵信息,定位到具體的服務器和服務模塊,構建一套集中式日志系統,可以提高定位問題的效率。
完整日志系統基本特征
- 收集:能夠采集多種來源的日志數據
- 傳輸:能夠穩定的把日志數據解析過濾并傳輸到存儲系統
- 存儲:存儲日志數據
- 分析:支持UI分析
- 警告:能夠提供錯誤報告,監控機制
ELK架構分析

Beats + Elasticsearch + Kibana模式
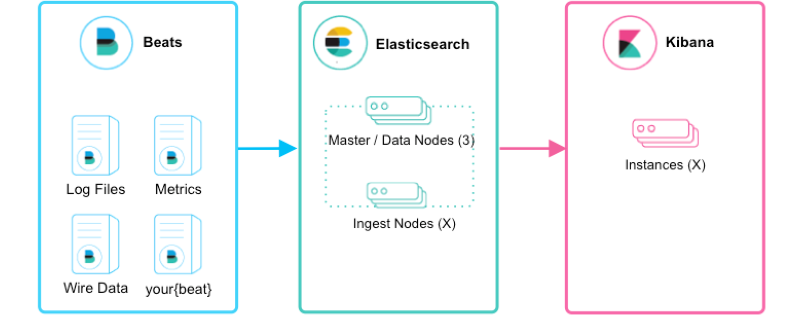
如上圖所示,該ELK框架由Beats(日志分析我們通常使用Filebeat)+ Elasticsearch + Kibana構成,這個框架比較簡單,入門級的框架。其中Filebeat也能通過module對日志進行簡單的解析和索引。并查看預建的Kibana儀表板。
該框架適合簡單的日志數據,一般可以用來玩玩,生產環境建議接入Logstash。
Beats + Logstash + Elasticsearch + Kibana模式
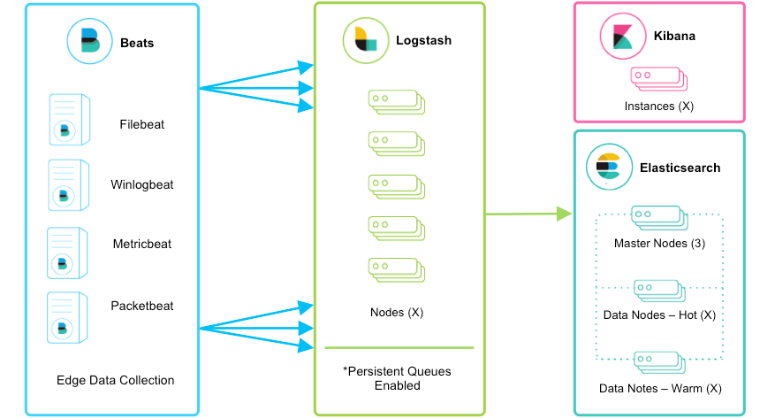
該框架是在上面的框架的基礎上引入了Logstash,引入Logstash帶來的好處如下:
- 通Logstash具有基于磁盤的自適應緩沖系統,該系統將吸收傳入的吞吐量,從而減輕背壓
- 從其他數據源(例如數據庫,S3或消息傳遞隊列)中提取
- 將數據發送到多個目的地,例如S3,HDFS或寫入文件
- 使用條件數據流邏輯組成更復雜的處理管道
Filebeat結合Logstash帶來的優勢:
- 水平可擴展性,高可用性和可變負載處理:Filebeat和Logstash可以實現節點之間的負載均衡,多個Logstash可以實現Logstash的高可用。
- 消息持久性與至少一次交付保證:使用Filebeat或Winlogbeat進行日志收集時,可以保證至少一次交付。從Filebeat或Winlogbeat到Logstash以及從Logstash到Elasticsearch的兩種通信協議都是同步的,并且支持確認。Logstash持久隊列提供跨節點故障的保護。對于Logstash中的磁盤級彈性,確保磁盤冗余非常重要。
- 具有身份驗證和有線加密的端到端安全傳輸:從Beats到Logstash以及從Logstash到Elasticsearch的傳輸都可以使用加密方式傳遞 。與Elasticsearch進行通訊時,有很多安全選項,包括基本身份驗證,TLS,PKI,LDAP,AD和其他自定義領域。
當然在該框架的基礎上還可以引入其他的輸入數據的方式:比如:TCP,UDP和HTTP協議是將數據輸入Logstash的常用方法(如下圖所示):
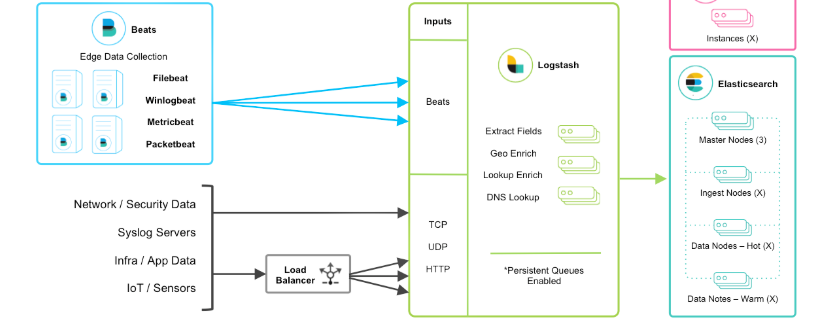
Beats+緩存/消息隊列+ Logstash + Elasticsearch + Kibana模式
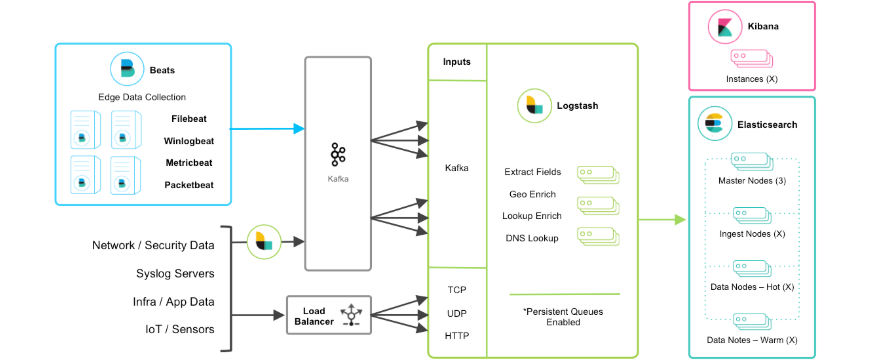
在如上的基礎上我們可以在Beats和Logstash中間添加一些組件Redis、Kafka、RabbitMQ等,添加中間件將會有如下好處:
- 降低對日志所在機器的影響,這些機器上一般都部署著反向代理或應用服務,本身負載就很重了,所以盡可能的在這些機器上少做事;
- 如果有很多臺機器需要做日志收集,那么讓每臺機器都向Elasticsearch持續寫入數據,必然會對Elasticsearch造成壓力,因此需要對數據進行緩沖,同時,這樣的緩沖也可以一定程度的保護數據不丟失;
- 將日志數據的格式化與處理放到Indexer中統一做,可以在一處修改代碼、部署,避免需要到多臺機器上去修改配置。
ELK部署
ELK各個組件的網址可以在官網下載:https://www.elastic.co/cn/
或者在中文社區下載:https://elasticsearch.cn/download/
注:本次安裝都是采用壓縮包的方式安裝。
Filebeat的安裝介紹
原理
Filebeat的工作方式如下:啟動Filebeat時,它將啟動一個或多個輸入,這些輸入將在為日志數據指定的位置中查找。對于Filebeat所找到的每個日志,Filebeat都會啟動收集器。每個收集器都讀取單個日志以獲取新內容,并將新日志數據發送到Libbeat,Libbeat將聚集事件,并將聚集的數據發送到為Filebeat配置的輸出。
Filebeat結構:由兩個組件構成,分別是inputs(輸入)和harvesters(收集器),這些組件一起工作來跟蹤文件并將事件數據發送到您指定的輸出,harvester負責讀取單個文件的內容。harvester逐行讀取每個文件,并將內容發送到輸出。為每個文件啟動一個harvester。harvester負責打開和關閉文件,這意味著文件描述符在harvester運行時保持打開狀態。如果在收集文件時刪除或重命名文件,Filebeat將繼續讀取該文件。這樣做的副作用是,磁盤上的空間一直保留到harvester關閉。默認情況下,Filebeat保持文件打開,直到達到close_inactive。
簡單安裝
本文采用壓縮包的方式安裝,Linux版本,Filebeat-7.7.0-linux-x86_64.tar.gz。
curl-L-Ohttps://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.7.0-linux-x86_64.tar.gz tar -xzvf filebeat-7.7.0-linux-x86_64.tar.gz
配置示例文件:filebeat.reference.yml(包含所有未過時的配置項)
配置文件:filebeat.yml
啟動命令:./filebeat -e
具體的原理、使用、實例見文:https://www.cnblogs.com/zsql/p/13137833.html
Logstash的安裝介紹
基本原理
Logstash分為三個步驟:inputs(必須的)→ filters(可選的)→ outputs(必須的),inputs生成時間,filters對其事件進行過濾和處理,outputs輸出到輸出端或者決定其存儲在哪些組件里。inputs和outputs支持編碼和解碼。
Logstash管道中的每個input階段都在自己的線程中運行。將寫事件輸入到內存(默認)或磁盤上的中心隊列。每個管道工作線程從該隊列中取出一批事件,通過配置的filter處理該批事件,然后通過output輸出到指定的組件存儲。管道處理數據量的大小和管道工作線程的數量是可配置的。
簡單安裝
下載地址1:https://www.elastic.co/cn/downloads/logstash
下載地址2:https://elasticsearch.cn/download/
這里需要安裝JDK,我使用的是Elasticsearch 7.7.0自帶的JDK:

解壓即安裝:
tar -zxvf logstash-7.7.0.tar.gz
來個Logstash版本的HelloWorld:
./bin/logstash -e 'input { stdin { } } output { stdout {} }'
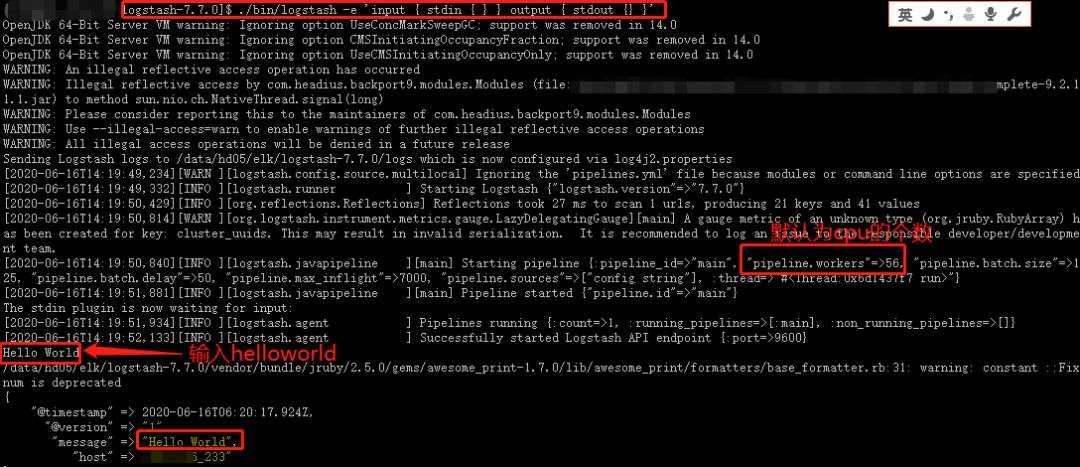
具體的原理、使用、實例見文:https://www.cnblogs.com/zsql/p/13143445.html
Elasticsearch的安裝介紹
基本介紹
Elasticsearch(ES)是一個基于Lucene構建的開源、分布式、RESTful接口的全文搜索引擎。Elasticsearch還是一個分布式文檔數據庫,其中每個字段均可被索引,而且每個字段的數據均可被搜索,ES能夠橫向擴展至數以百計的服務器存儲以及處理PB級的數據。可以在極短的時間內存儲、搜索和分析大量的數據。
基本概念有:Cluster 集群、Node節點、Index索引、Document文檔、Shards & Replicas分片與副本等。
Elasticsearch的優勢:
- 分布式:橫向擴展非常靈活;
- 全文檢索:基于Lucene的強大的全文檢索能力;
- 近實時搜索和分析:數據進入ES,可達到近實時搜索,還可進行聚合分析;
- 高可用:容錯機制,自動發現新的或失敗的節點,重組和重新平衡數據;
- 模式自由:ES的動態mapping機制可以自動檢測數據的結構和類型,創建索引并使數據可搜索;
- RESTful API:JSON + HTTP。
Linux系統參數設置
1、設置系統配置
ulimit #暫時修改,切換到該用戶es,ulimit -n 65535 /etc/security/limits.conf #永久修改 es - nofile 65535 ulimit -a #查看當前用戶的資源限制
2、禁用sawpping
方式一:
swapoff -a #臨時禁用所有的swap文件 vim /etc/fstab #注釋掉所有的swap相關的行,永久禁用
方式二:
cat /proc/sys/vm/swappiness #查看該值 sysctl vm.swappiness=1 #臨時修改該值為1 vim /etc/sysctl.conf #修改文件 永久生效 vm.swappiness = 1 #如果有該值,則修改該值,若沒有,則追加該選項,sysctl -p生效命令
方式三:
配置elasticsearch.yml文件,添加如下配置: bootstrap.memory_lock: true GET _nodes?filter_path=**.mlockall #檢查如上配置是否成功
注意:如果試圖分配比可用內存更多的內存,mlockall可能會導致JVM或shell會話退出!
3、配置文件描述符
ulimit -n 65535 #臨時修改 vim /etc/security/limits.conf #永久修改 es soft nproc 65535 es hard nproc 65535
4、配置虛擬內存
sysctl -w vm.max_map_count=262144 #臨時修改該值 vim /etc/sysctl.conf #永久修改 vm.max_map_count=262144
5、配置線程數
ulimit -u 4096 #臨時修改 vim /etc/security/limits.conf #永久修改
Elasticsearch安裝
Elasticsearch是需要其他用戶啟動的,所以需要先創建一個新的用戶ELK:
groupadd elastic useradd elk -d /data/hd05/elk -g elastic echo '2edseoir@' | passwd elk --stdin
下載:https://elasticsearch.cn/download/
也可以去官網下載wget:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.0-linux-x86_64.tar.gz
解壓:tar -zxvf elasticsearch-7.7.0-linux-x86_64.tar.gz
建立軟鏈接:ln –s elasticsearch-7.7.0 es
目錄介紹:
$ES_HOME:/data/hd05/elk/elasticsearch-7.7.0 bin: $ES_HOME/bin #ES啟動命令和插件安裝命令 conf:$ES_HOME/conf #elasticsearch.yml配置文件目錄 data:$ES_HOME/data #對應的參數path.data,用于存放索引分片數據文件 logs:$ES_HOME/logs #對應的參數path.logs,用于存放日志 jdk:$ES_HOME/jdk #自帶支持該ES版本的JDK plugins: $ES_HOME/jplugins #插件存放目錄 lib: $ES_HOME/lib #存放依賴包,比如Java類庫 modules: $ES_HOME/modules #包含所有的ES模塊
配置自帶的Java環境:
Vim ~/.bashrc ############往后面添加如下內容###################### export JAVA_HOME=/data/hd05/elk/es/jdk export PATH=JAVAHOME/bin:PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar\:/lib/tools.jar
jvm.options文件說明:
配置Java參數 一種是通過修改/data/hd05/elk/elasticsearch-7.7.0/config/jvm.options文件修改JVM參數,一個使用過一個變量ES_JAVA_OPTS來聲明JVM參數 /data/hd05/elk/elasticsearch-7.7.0/config/jvm.options介紹: 8:-Xmx2g #表示只適合Java 8 8-:-Xmx2g #表示適合高于Java 8的版本 8-9:-Xmx2g #表示適合Java 8,和Java 9 其他配置,都是JVM的相關參數,如果要想明白,得去看Java虛擬機 通過變量ES_JAVA_OPTS來聲明JVM參數: 例如:export ES_JAVA_OPTS="$ES_JAVA_OPTS -Djava.io.tmpdir=/path/to/temp/dir" ./bin/elasticsearch
配置config/jvm.options:
[elk@lgh config]$ cat jvm.options | egrep -v '^$|#'
-Xms2g
-Xmx2g
8-13:-XX:+UseConcMarkSweepGC
8-13:-XX:CMSInitiatingOccupancyFraction=75
8-13:-XX:+UseCMSInitiatingOccupancyOnly
14-:-XX:+UseG1GC
14-:-XX:G1ReservePercent=25
14-:-XX:InitiatingHeapOccupancyPercent=30
-Djava.io.tmpdir=${ES_TMPDIR}
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=data
-XX:ErrorFile=logs/hs_err_pid%p.log
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
配置加密通信證書:
生成證書:
方法一:
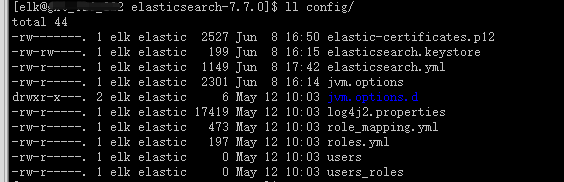
./bin/elasticsearch-certutil ca -out config/elastic-certificates.p12 -pass "password"
查看config目錄,有elastic-certificates.p12文件生成:
方法二:
./bin/elasticsearch-certutil ca #創建集群認證機構,需要交互輸入密碼 ./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 #為節點頒發證書,與上面密碼一樣 執行./bin/elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password 并輸入第一步輸入的密碼 執行./bin/elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password 并輸入第一步輸入的密碼 將生成的elastic-certificates.p12、elastic-stack-ca.p12文件移動到config目錄下
配置config/elasticsearch.yml:
[elk@lgh config]$ cat elasticsearch.yml | egrep -v '^$|#' cluster.name: my_cluster node.name: lgh01 node.data: true node.master: true path.data: /data/hd05/elk/elasticsearch-7.7.0/data path.logs: /data/hd05/elk/elasticsearch-7.7.0/logs network.host: 192.168.110.130 http.port: 9200 transport.tcp.port: 9300 discovery.seed_hosts: ["192.168.110.130","192.168.110.131","192.168.110.132","192.168.110.133"] cluster.initial_master_nodes: ["lgh01","lgh02","lgh03"] cluster.routing.allocation.cluster_concurrent_rebalance: 32 cluster.routing.allocation.node_concurrent_recoveries: 32 cluster.routing.allocation.node_initial_primaries_recoveries: 32 http.cors.enabled: true http.cors.allow-origin: '*' #下面的是配置x-pack和tsl/ssl加密通信的 xpack.security.enabled: true xpack.license.self_generated.type: basic xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.keystore.path: elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: elastic-certificates.p12 bootstrap.memory_lock: false #CentOS 6需要配置 bootstrap.system_call_filter: false #CentOS 6需要配置
然后通過scp到其他的節點,修改上面的node.name和node.master參數,然后要刪除data目標,不然會存在報錯。
然后使用./bin/elasticsearch -d 后臺啟動elasticsearch,去掉-d則是前端啟動Elasticsearch。
然后./bin/elasticsearch-setup-passwords interactive 配置默認用戶的密碼:(有如下的交互),可以使用auto自動生成。
[elk@lgh elasticsearch-7.7.0]$ ./bin/elasticsearch-setup-passwords interactive Enter password for the elasticsearch keystore : Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user. You will be prompted to enter passwords as the process progresses. Please confirm that you would like to continue [y/N]y Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana]: Reenter password for [kibana]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]: Enter password for [remote_monitoring_user]: Reenter password for [remote_monitoring_user]: 1qaz@WSXChanged password for user [apm_system] Changed password for user [kibana] Changed password for user [logstash_system] Changed password for user [beats_system] Changed password for user [remote_monitoring_user]
然后可以登錄http://192.168.110.130:9200/需要輸入密碼,輸入elastic/passwd即可登錄。
head插件安裝
Head官網:https://github.com/mobz/elasticsearch-head
Nodejs下載:https://nodejs.org/zh-cn/download/
官方說明,Elasticsearch 7有三種方式使用head插件,這里我只試過兩種:
第一種:使用谷歌瀏覽器head插件,這個直接在谷歌瀏覽器上面安裝插件就可以使用了。
第二種:使用head服務(把head當做一個服務來使用),安裝如下:
#Running with built in server git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start open http://localhost:9100/
如果在如上的安裝過程中報錯,可以嘗試下這個命令再繼續安裝npm install phantomjs-prebuilt@2.1.16 --ignore-scripts。
Kibana的安裝介紹
下載地址:https://elasticsearch.cn/download/
也可以去官網下載。
解壓后修改kibana.yml文件:
[elk@lgh config]$ cat kibana.yml | egrep -v "^$|#"
server.port: 5601
server.host: "0.0.0.0"
server.name: "my-kibana"
elasticsearch.hosts: ["http://192.168.110.130:9200","http://192.168.110.131:9200","http://192.168.110.132:9200"]
elasticsearch.preserveHost: true
kibana.index: ".kibana"
elasticsearch.username: "elastic"
elasticsearch.password: "password" #或者使用keystore的保存的密碼"${ES_PWD}"
./bin/kibana啟動。
訪問網址:http://192.168.110.130:5601/,并使用elastic/password登錄。
實例分析
《一篇文章搞懂Filebeat(ELK)》,該文章中有Beats + Elasticsearch + Kibana的實例。
《從0到1學會Logstash的玩法(ELK)》(https://www.cnblogs.com/zsql/p/13143445.html), 該文章中有Beats + Logstash + Elasticsearch + Kibana實例。
現在我們弄一個Beats+緩存/消息隊列+ Logstash + Elasticsearch + Kibana的實例:
中間組件我們使用Kafka,我們看下Filebeat把Kafka作為output的官網:https://www.elastic.co/guide/en/beats/filebeat/7.7/kafka-output.html

這里要注意Kafka的版本,我試過兩個都是極端的版本,坑了自己一把。假如你已經有kafka集群了,我這里安裝的是一個單機版本(1.1.1):
數據集我們采用Apache的日志格式,下載地址:https://download.elastic.co/demos/logstash/gettingstarted/logstash-tutorial.log.gz
日志格式如下:
[elk@lgh ~]$ tail -3 logstash-tutorial.log 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /projects/xdotool/ HTTP/1.1" 200 12292 "http://www.haskell.org/haskellwiki/Xmonad/Frequently_asked_questions" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0" 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /reset.css HTTP/1.1" 200 1015 "http://www.semicomplete.com/projects/xdotool/" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0" 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /style2.css HTTP/1.1" 200 4877 "http://www.semicomplete.com/projects/xdotool/" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0"
首先我們配置Filebeat的配置文件filebeat.yml:
#=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /data/elk/logstash-tutorial.log #這里使用的是apache的日志格式 #- c:\programdata\elasticsearch\logs\* # Exclude lines. A list of regular expressions to match. It drops the lines that are # matching any regular expression from the list. #exclude_lines: ['^DBG'] # Include lines. A list of regular expressions to match. It exports the lines that are # matching any regular expression from the list. #include_lines: ['^ERR', '^WARN'] # Exclude files. A list of regular expressions to match. Filebeat drops the files that # are matching any regular expression from the list. By default, no files are dropped. #exclude_files: ['.gz$'] # Optional additional fields. These fields can be freely picked # to add additional information to the crawled log files for filtering #fields: # level: debug # review: 1 ### Multiline options # Multiline can be used for log messages spanning multiple lines. This is common # for Java Stack Traces or C-Line Continuation # The regexp Pattern that has to be matched. The example pattern matches all lines starting with [ #multiline.pattern: ^\[ # Defines if the pattern set under pattern should be negated or not. Default is false. #multiline.negate: false # Match can be set to "after" or "before". It is used to define if lines should be append to a pattern # that was (not) matched before or after or as long as a pattern is not matched based on negate. # Note: After is the equivalent to previous and before is the equivalent to to next in Logstash #multiline.match: after #================================ Outputs ===================================== output.kafka: hosts: ["192.168.110.130:9092"] #配置kafka的broker topic: 'filebeat_test' #配置topic 名字 partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000
然后使用命令后臺啟動:
cd filebeat-7.7.0-linux-x86_64 && nohup ./filebeat -e &
接下來我們配置Logstash的配置文件:
cd logstash-7.7.0/ && mkidr conf.d
cd conf.d
vim apache.conf
################apache.conf文件中填入如下內容##############################
input {
kafka{
bootstrap_servers => "192.168.110.130:9092"
topics => ["filebeat_test"]
group_id => "test123"
auto_offset_reset => "earliest"
}
}
filter {
json
{
source => "message"
}
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
remove_field => "message"
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.110.130:9200","192.168.110.131:9200","10.18.126.224:9200","192.168.110.132:9200"]
index => "test_kakfa"
user => "elastic"
password => "${ES_PWD}"
}
}
然后后臺啟動Logstash命令:
cd logstash-7.7.0/ && nohup ./bin/logstash -f conf.d/apache.conf &
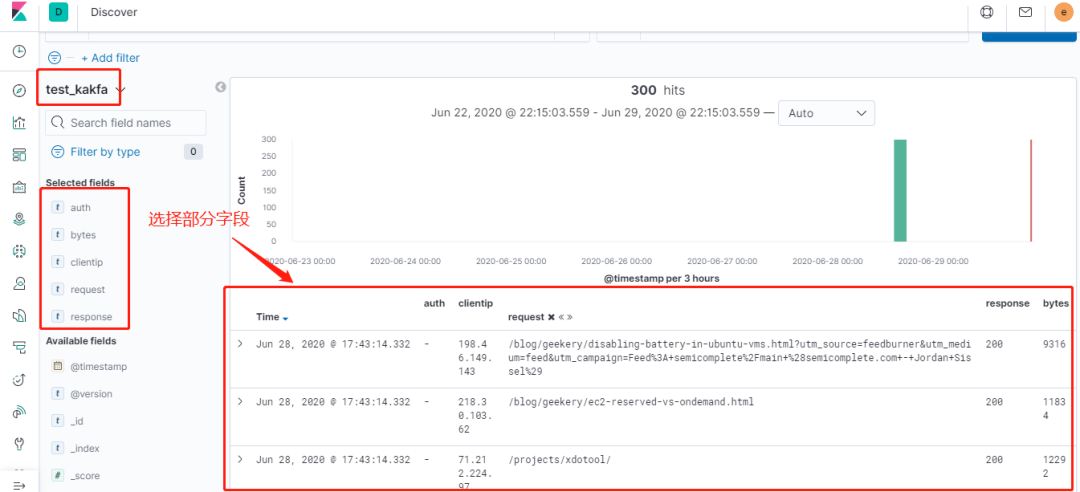
然后我們查看Elasticsearch集群查看該索引。

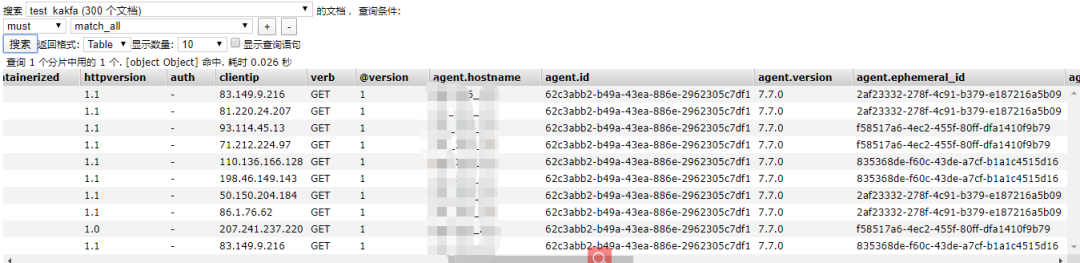
接下來我們登錄到Kibana查看該索引的分析。