JLink固件漏洞
JlinkV10的固件驗證缺陷我年前已發布刷機工具,但缺陷是利用就得刷機一次再刷回。
發布前在某移動設備開發群談論時候,群友說v10會檢查固件簽名,你怎么搞。我就說簽名區外面的空間我可以放代碼,能放五百字節完全塞得下。
他表示以前的很老版本固件倒是有過任意寫bug,可惜修復了,雖然沒有透露細節,但我想群友能找到我也來找個。
然后我挨個看命令處理,還真看到個棧覆蓋bug。這個bug并不是他說的那個,而且棧太小了不大好利用。
這我可就不同意了,數著字節寫代碼是我們中年程序員的基礎技能啊!
先看看出問題的函數fine_write_read反編譯代碼:
usbrxbuf(arg, 12); // 接收三個len usbrxbuf(writebuf, arg[0]); // 可覆蓋LR readed = syncM0FINEGPIO(writebuf, arg[0], replybuf, arg[1]); memcpy((char *)&arg[7] + arg[1], &readed, sizeof(int)); //任意地址清4字節 usbtxbuf(replybuf, arg[1] + 4);
此代碼有用戶控制緩沖區長度問題。首先會接收三個長度變量,我把它們取名為writelen, readlen, somelen。第一個writelen控制接下來的緩沖區接收尺寸,然后usbrxbuf函數接收對應長度的字節放入writebuf,此數組分配在棧上。這里可以超寫,覆蓋LR。
然后再看memcpy的目標,以writebuf地址+第二個長度偏移=最終地址,復制4字節readed值到此地址。構成了一個任意寫,正常情況下readed值等于readlen,但可以不正常。
這個writebuf是棧上的數組,打開棧結構窗口看看:
-0000003C readed DCD ?-00000038 arg DCD 3 dup(?)-0000002C writebuf DCB 16 dup(?)-0000001C replybuf DCB 24 dup(?)-00000004 LR DCD ?+00000000 ; end of stack variables
只要從writebuf地方寫0x2C個字節,就覆蓋到了保存的LR了。因為程序序言是一個單純的PUSH {LR},所以也沒有其他寄存器的值需要恢復。
最簡單的利用方法就是讓usbrxbuf函數對writebuf寫入0x2C字節,覆蓋保存的LR到我們寫入的緩沖區地址。首先我們需要知道執行到此處時,sp具體的值,好跳轉到我們寫入的代碼中。
我寫了一個小工具,通過usb命令觸發fine_write_read這個處理函數,接收長度writelen給了2C,這2C的內容都是AA,然后使用SWD連接jlink的芯片, 在BL usbrxbuf處下斷,然后執行命令斷下,查看此時的sp值, 100840A0。執行usbrxbuf后writebuf, replybuf, 返回地址(LR)都被填充成了AA。
因為從BL usbrxbuf直到函數返回還有三個BL, 要讓棧里LR生效, 必須執行到POP PC。我們依次執行這三個BL, 在執行第一個BL syncM0FINEGPIO后就出了問題, 我們送進來的AA被這個函數給清零了! 從replybuf開始的0x2C字節都被清了, 都超過了棧上的LR清到了父函數的棧里面。

為了直觀一些, 我畫了fine_write_read函數的棧。這個函數顧名思義, 是上位機和使用FINE接口(瑞薩的協議)的開發板通訊用的, 上位機送出writelen長度的數據, 調試探頭通過操作GPIO引腳送給開發板, 然后由引腳讀回readlen長度的數據放到replybuf, 并連同讀取長度一起發給上位機。
我們當然不想讓replybuf被覆蓋, 所以readlen寫的0, 按理說syncM0FINEGPIO也會返回0, 也不會往replybuf寫值, 只有memcpy會將replybuf開始4字節覆蓋為0(readed)啊。
跟進去syncM0FINEGPIO調了一下, 發現執行了某條寫入內存指令后, 棧里的replybuf連同后面的LR等瞬間清零了。
這指令操作就是[20000008]=1, 這個地址在數據手冊里描述為M4/M0共享內存, 經過分析這個syncM0FINEGPIO函數是給M0配參數和等待它完成的協作函數。
APP:1A016864 008 20 60 STR R0, [R4] ; 執行到這里會破壞LRAPP:1A016866 008 BF F3 4F 8F DSB.W SY
此時就要講一下這個J-Link V10的硬件特征了, 他的cpu有M4/M0兩個核心, 看來為了讓GPIO模擬協議保持時序穩定不受RTOS影響, J-Link程序員單獨用M0來完成協議模擬。20000008是M4/M0之間的狀態量, M4切換狀態到1等待0, M0等待1完成后切換為0并繼續等待1。
那為什么本應該按照readlen來跳過讀取的M0會按照writelen來覆蓋我們的replybuf呢? 為了覆蓋到位, writelen是不可以設置成0的。
我估計應該是因為我們沒有經過前置的操作, 直接發送FINE請求, M0里運行的程序并不是為了FINE協議準備的。我沒有瑞薩的開發板, 沒法實際接上FINE接口看看固件命令執行流程。
不過連翻帶猜發現了一個select_if命令, 當選擇3號interface時候, M0的app(Reset Vector地址的函數)就是匹配FINE讀寫的。
在我們工具加入select_if命令后, 經過調試, 成功走到了POP {PC}。
接下來我們就要考慮下塞下更多代碼的辦法了。目前我們能利用的空間是分開的兩段, somelen應該是fine_write_read命令中一個保留的字段, 因此函數中沒有用到他, 內容會保留。從他開始0x14字節的綠色區域可以放代碼, 然后replybuf的內容前面4字節會被memcpy覆蓋為m0程序返回的readed, 所以需要避讓開4字節。后面到LR也有0x14字節的藍色區域, 也是可以放代碼的。
那么最后的父函數棧是不是可以繼續覆蓋作為代碼呢? 實際是不行的。走完uxbrxbuf函數, 可以觀察到父函數棧確實可以被覆蓋, 但是走usbtxbuf函數發送回應時候, 設備就會崩潰重啟, 回不到POP {PC}了。
usbtxbuf函數會發送replybuf, 長度為readlen+4, 查看usbtxbuf函數, 我們會看到如果buf或者len任一項為0, 該函數就會直接返回, 不會調用其他子函數。那么如果我們把readlen設置為-4, 這個發送函數不就直接返回了嗎?
話雖如此, 但readlen同時還傳給M0作為從GPIO引腳讀取到replybuf的長度, 如果傳個負值會不會M0又開始狂寫replybuf呢?
查看M0的app后發現, 讀取部分是判斷readlen非0后至少讀一個字節再判斷已讀字節數是否小于writelen的。這里的判斷是BLT, 有符號。因此讀了1字節后循環條件1小于-4不成立不再循環。
但…節外生枝的是M4往M0傳readlen參數時候會左移3位將readlen字節數轉換為bit數, 然后在M0中右移3位轉換回byte, 因此readlen傳FFFFFFFC(-4)會丟掉高3位變1FFFFFFC(536870908)。程序員看似為了設計做的無意義轉換恰好封堵了這種繞過發送函數的辦法。
不過還不能絕望, 因為J-Link沒有讓M0從flashA執行(估計是因為放在sram中是零等待周期, 模擬出來的時序更準), 而是放在sram0中。所以我們可以實時補掉M0的app。
我們可以分兩步, 第一步不超收, 補掉M0的app后就返回, 因為我們payload執行時候, M0是位于循環等待20000008的狀態, 而M0也沒有icache, 所以補了別的地方下一輪gpio操作執行就是補丁后的代碼。我們補的就是這個右移3位的代碼LSRS R5, R5, #3, 直接補為EORS R5, R5, 這樣下一次協作函數發什么M0都以為readlen是0, 從而不會動replybuf。外面的M4看來readlen還是-4, 還能用來繞過uxbtxbuf發送函數。
測試果然可行, 收個12c大小, 已經破壞了父函數棧, 甚至穿了task的棧空間, 但usbtxbuf沒有用到棧直接返回了, 最后POP {PC}流程到我們代碼。測試中12C實際寫穿到IP棧的棧了, 但只要我payload里禁用中斷, RTOS也不會切換到IP棧線程。
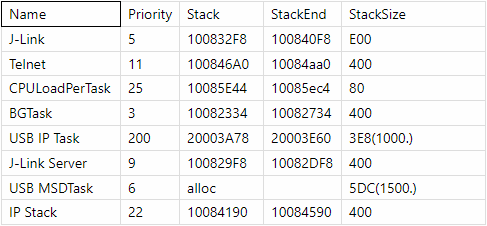
這是出廠版固件的embOS的各線程的棧分配表。
這樣我們能夠放代碼的空間就增大了很多, 因為改了readlen等于調節了隨意寫bug, readed的值相應的會復制到replybuf-4的地方, 我們可用的是0x10+0x18+超寫部分長度。最大寫多少我沒試, 應該只要能成功接收不崩潰, 就不會異常。
現在是不是可以告一段落了呢? 顯然不完美啊。這樣破壞的話我們執行完自己的payload后只能通過重啟的方式恢復環境了, 有沒有什么辦法還能繼續返回執行呢? 比如寫入其他空閑地方?
當然有, 還恰好能塞在0x28的大小里。目標地址選擇了20000048這是IP Stack才會訪問的地方, 估計是聯網功能預留的代碼。也可以選擇sram0的10000160處, 推測segger程序員將整個sram0預留給M0獨占使用, FINE的M0 APP就只用了前面0x160。
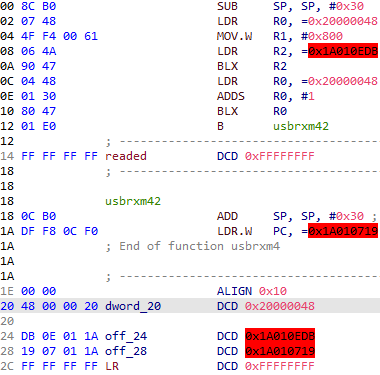
此處第一個留空的readed是memcpy的目標, 第二個留空LR是棧上返回地址。
注意這里的sub sp, #0x30是因為我們要在payload里調用usbrxbuf, 而執行到我們的payload時候, sp剛好指向的是payload結束后的地址, 第一次調用BLX R2就是usbrxbuf, 它和它調用的子函數寫入棧會往前破壞我們的payload末尾。
當然減掉28也是可以的, 因為執行了blx r2指令后才進入子函數, 此時前面幾條指令空間用不到了。
然而這并不能讓我滿足, 我又思考了, 能不能我們激活并保持住M0的重啟信號, 并把我們自制的M0 App給覆蓋到sram0, 然后App保持”后臺”執行呢?
經過精簡, 載入代碼要0x2C連續空間, 因為我們M0卡重啟會導致下次fine_write_read命令時候雙核協作函數syncM0FINEGPIO無法返回, 無法拆分為2次執行。那我們能不能把中間存readed的位置繼續往前挪呢? 答案當然是可以的!
實際上這個readed剛才已經因為我們的readlen往前挪了4字節, 如果繼續往前不就挪到當前函數棧空間外了嗎? 可是減少readlen又會造成最后usbtxbuf時候長度為負, 無限發送。因為是先memcpy再usbtxbuf, 能不能讓readlen在memcpy取參數時候是-0x18, 但執行后把-4回寫到readlen位置, 供最后usbtxbuf湊成0呢? 只要讓M0固定返回-4即可。
我改進了補M0的代碼, 多補了一個地方, 讓返回變為-4。
sram0:10000150 loc_10000150 ; CODE XREF: FINE_Reset_Handler+10A↓jsram0:10000150 000 40 1E SUBS R0, R0, #1sram0:10000152 000 FD D5 BPL loc_10000150sram0:10000154 000 20 46 MOV R0, R4
最后一句R0的值會在后面寫入20000024, 給M4同步函數讀取為返回值, 本來是從前面R4(readed)的值傳給R0, 我改為了subs R0, #4, 因為循環到這里時候R0是0。這樣等下M4取回來的就是-4了。
總結一下第一次打完補丁返回后, 第二次溢出, 上位機傳過來readlen為-0x18, 導致memcpy的目標指向readlen自身, 執行完mempy以后readlen變為了M0給的-4,調用usbtx時候這個readlen+4=0不會調用usb函數直接返回了。這樣就避開了payload破壞函數執行問題。
這樣我們的工具就有了三種方案:
(1)經典原地超收 需要補丁M0外加負偏移跳發送。完整payload從當前函數棧往后覆蓋。缺點是執行后必須重啟, 而且payload代碼里不能做usb發送。
(2)空閑內存M4執行 第一次溢出時候額外調用usbrxbuf接收完整payload到空閑內存位置, 然后跳轉執行并返回。因為沒有破壞棧, payload中可以繼續usb收發。
(3)M0專屬app后臺執行 在M4的準備階段將M0App整個替換, 我們此后再發fine_write_read指令就可以通過原本的協作函數讓M0App響應處理。
不過經過測試, 方案3用簡易刷新法(卡著M0復位并覆蓋它程序代碼的操作過后放開復位控制位), 系統會在500ms后重啟。使用固件里的完整刷新函數bootm0app不會重啟, 但我們要額外解析該函數地址。
這就結束了嗎, 還沒有, 還有最重要的一步: 兼容性。
為了發布一個成熟的利用, 我們還要兼容更可能多的版本固件。我們需要知道sp的值, usbrxbuf的值, 用來填充不同版本的固件下payload末尾的指針。一種辦法是收集所有驅動, 逐個解壓固件然后人工分析。
還有一個辦法是用程序自動尋找。雖然最早我們得到SP是通過真機調試, 但我此刻意識到SP的值可以通過主線程執行時候的初始值減去每層調用時候的SP差值得到。初始值應該就是RTOS創建時候傳入的棧空間的底部值, 因為ARM傳統的required 8兼容, 初始值還需要按8對齊一次。
IDA腳本功能是, 針對IAR特征找到main, 然后提取出棧初值, 在主線程函數中, 定位usb分發函數, 尋找usb命令處理程序數組, 定位fine_write_read函數, 將這三層跳轉處的sp偏移減去。
然后考慮到在用戶機器沒有ida還得架個服務器跑idapython, 那能不能用普通的反編譯庫來本地找呢? 以前寫insanelinker時候也寫過一些解析, 但只是個別指令。懶得完善了不如看看開源的吧!
capstone有點大, 但找了其他倆輕量的更坑, 最后還是從ida腳本移植了一個capstone的版本。因為不能像IDA那樣確定函數結束, 也不能給出SP偏移, 通用性肯定不如ida腳本了。
經過調整和驗證, V10固件直到最新版都可以搜到所有特征, 順便測試了下V11, 直到7.52a里面也適用, 但在7.52b第一步就定位錯誤, 目測從這個版本起已經不是IAR編譯的了, 可能是SES(Segger Embedded Studio)編譯的, LDR基本都變成了MOVW/MOVT組合, 不好搜索了, usbrxbuf全部成為了inline調用, 靜態解析只能得到二級指針地址。
導致”M4接收器”無法擠下取接收函數地址的代碼, 但可以繞過, 比如多溢出幾次用螞蟻搬家的方式拼出一個接收器再執行, 又或者第一次溢出后取函數地址并發回給主機用來裝配接收器。
同時因為編譯器的改變, 新款fine_write_read的棧底多了R4,R5,R6, 我們覆蓋時候還要知道原來的值。比如7.60a里面R4的值在執行前是修正后的命令索引, R5和R6在主線程里面尋找MOVW/MOVT組合可以得到, 但在7.52b里面, R6才是cmd相關的。
所以想要靜態分析通用處理已經太難了(后面會說原因), 得想辦法做個能模擬外設單元的模擬器, 或者干脆用實際硬件把這些版本跑一遍下斷點加記錄, 再提供個服務遠程接收新出的測試版固件上傳刷機。
還有另一個冷門辦法, 我們看一下read_emu_mem這條命令, 它比較復雜應該也保護了這些寄存器, 果然, 入口是PUSH.W {R4-R9,LR}。那么用它來讀當前的棧里面R4-R6的值, 再在fine_write_read里裝配到LR前面可不可行呢, 完全可行。
因為主線程這里就是個無限循環, 不同的命令全是走同一個BLX指令調用的, 除非這三個寄存器有一個是存了命令索引, 但這個索引在獲取命令指針后就沒有用到了。
這個保留作為最終手段, 我們先來試試靜態分析。我改進了搜索代碼, 在遇到BLX調用usb命令前, 持續跟蹤movw/movt對, 記錄R4R5R6得到的最后一次組合值。
對比輸出結果, 目前來看, 匯編靜態解析和動態獲取的相同。我這套解析的隱患是解析代碼沒有處理跳轉, 所以如果是后面代碼初始化了R4R5R6再跳回前面代碼執行cmd的固件, 那么我的記錄方式就會失效。當然了目前版本沒有遇到。
接下來載入器也要適配SES編譯版V11固件, 但發現SES版的臨時變量readed從棧頂部跑到了尾部, 占用了replybuf結尾的4字節, 因為replybuf代碼里本來是0x14大小, 只是IAR版由于8字節棧對齊原因尾部有4字節無用空間。

當replybuf被打回原形后, 又少了4字節可用空間。不過我發現棧里r4r5r6其中總是有一個是cmd索引, 因為cmd索引的寄存器在取完命令指針后直到準備下一次接收都沒有再引用, 能不能把LDR的pool末尾動態挪到它對應位置呢?
經過調節, 加了重定位處理, 成功把M4載入器的代碼塞進最新V11的棧里, 還富余倆字節。寫了個紅燈閃爍的payload執行后, 正常繼續執行也沒崩。
那么如果cmd索引它不是r4r5r6咋辦? 因為我們方案2里面返回的是調用cmd的函數, 所以可以在payload返回前恢復對應寄存器的值, 不過這樣需要payload配合了。
如果不想在payload里配合, 那么這個流程也必須做一次M0App的補丁, 將+14處的四字節省出來。
我還在琢磨只給正版用戶利用, 不想給做盜版的商家用, 用usb協議的驗證簽名命令是不靠譜的, 我懷疑盜版的不能升級的那種也改掉了簽名驗證。我想的是把bootloader讀出來檢查代碼區和部分參數, 首先確保bootloader沒被改, CRP調試保護也存在, 再查序號和OTS簽名不為空。
我在自己的V10上測試, 可以識別對bootloader的修改。
因為我沒有V11真機, 目前還沒測試。無意間聽說一位群友有正版V11, 特地向他求助, 在他幫助下, 增加了V11的正版驗證。
至此我就可以支持v10/v11所有版本了, 讓我們想想能寫點兒啥好玩的呢?
(1)Blinky 最經典的閃燈
//LPC_SCU->SFSP2_4 = 0x54; // P2_4 -> Fun4, No Pullup //LPC_GPIO_PORT->DIR[5] |= 1 << 4; // GPIO5[4] Output for (int loop = 12; loop; loop--) { LPC_GPIO_PORT->CLR[5] = 1 << 4; // ON FeedWWDT(); delay200ms(); LPC_GPIO_PORT->SET[5] = 1 << 4; // OFF FeedWWDT(); delay200ms(); } return;
GPIO5[4]是紅燈, 主程序已經幫我們初始化好了, 頭兩條初始化可以不要。效果就是紅燈閃爍12次后, 機器仍正常運行。因為此芯片WWDT看門狗起來就關不掉的, 時間超過了500ms就要喂狗, 所以加上了喂狗調用。
(2)SWDUnlock 解除調試限制
V10的電路板預留了jtag/swd調試接口, 但因為它出場時候設置了CRP代碼讀出保護, 導致此接口不能用來調試(當然就不能用來dump), 但我們可以代碼方式改寫CRP標志所在的頁, 將其關閉。
因為LPC4322自帶的ROM里面有flash操作函數, 我們經過init, prepare, erase, prepare, write五步操作, 可以完成修補。因為返回時候棧在上層函數, 因此大概有Dxx大小的棧可以在payload里用。
(3)去除bootloader固件校驗, 或者刷自制bootloader
Segger為了保證固件是官方固件, 增加了RSA簽名驗證. 之前的帖子雖然也講了這個RSA檢查沒有覆蓋整個固件, 能夠讓我們插入自己的代碼, 但如果bootloader補掉, 我們就可以完全自制固件了。Segger的信任策略是bootloader相信自己不會被修改, 然后不信任固件去檢查固件。
(4)讓JLink自動補用戶開發的固件
這個就比較特殊了, 假設知道對方是開發者, 或者偏執的斷網編譯固件燒寫的錢包用戶。可以接觸到他的調試器的usb連接的話, 通過以上方式給調試器刷固件加入匹配代碼, 燒寫的產品固件里植入后門, 例如特定的保密設備, 只有flash代碼能夠訪問的安全存儲, 但很遺憾的是, 這個估計沒法做通用, 因為無法把固件全部緩沖下來分析, 只能流式修補。
此bug在JLinkV9, JLink Pro, JLink Wifi最新固件中都存在, 估計Segger家只要支持FINE協議的產品都有同樣的漏洞。其中Wifi版可能不需要usb連接也可溢出。而Pro版沒有M0協處理器, 因此不能使用負偏移技巧。
此bug我已在1/5日報給Segger, 不過不知道由于啥原因, 廠家沒有重視。后來催了下, 說我給的密碼打不開壓縮包。再后來又催了下, 說產品經理病了。那好吧, 那我發布時候為止, 通用JLinkV10/V11所有固件。
最后總結一下, 嵌入式環境有其固有特點, 缺點是內存資源極其有限, VFT用的少, 一些基于函數指針的利用沒法在這里用。優點呢, 就是執行的環境比較潔凈, 沒有其他進程/OS干擾, 只要不搞出bug, 走同樣路徑觸發的函數, 不管是多少次, 現場都一樣, 甚至可以在電腦上靜態計算出來。
特別感謝: thxlp, XX, Status:Headcrabed。
工具已上傳, 加了一些限制防止taobao. 目前具有閃燈, 去除features, V10/V11互轉等功能。代碼已發github。
