Price TAG:半自動的電子商務威脅TTP提取
VSole2022-03-15 18:23:41
簡介
電子商務中的網絡安全威脅體現在欺詐行為、聲譽操縱等方面,這些攻擊行為會對用戶數據的完整性造成破壞,例如銷售量膨脹,商品排名升級,或操縱搜索引擎的結果以在短時間內獲得流量。如常見的刷銷量行為,就是通過虛假訂單偽造出高銷售量來提高人氣,從而促銷某種目標商品,也被稱作”拍A發B“。由于電子商務威脅不同于拒絕服務、入侵攻擊等傳統網絡安全威脅,之前的研究工作對于識別這類威脅行為并不適用。因此,作者設計了TAG(TTP Semi-Automatic Generator)的新方法,提取電子商務領域的TTP。
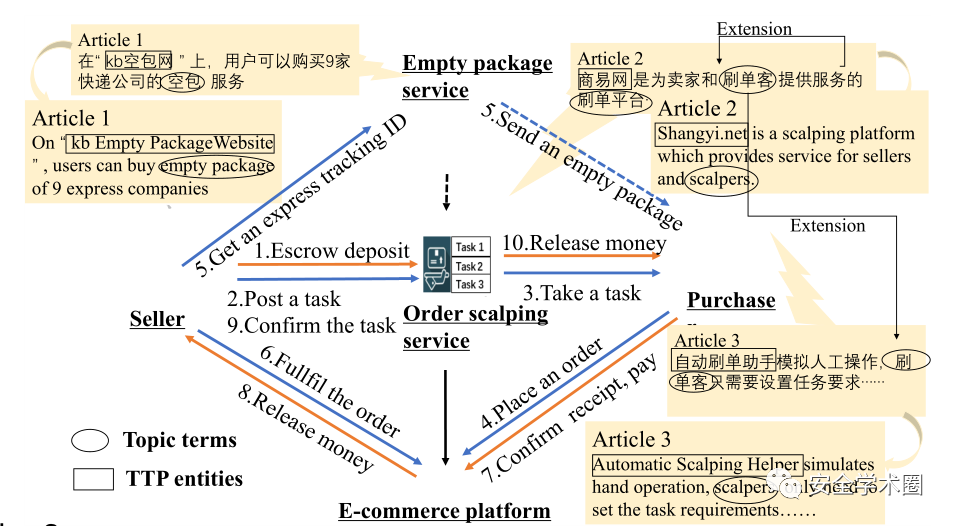 電子商務TTP的示例
電子商務TTP的示例
方法
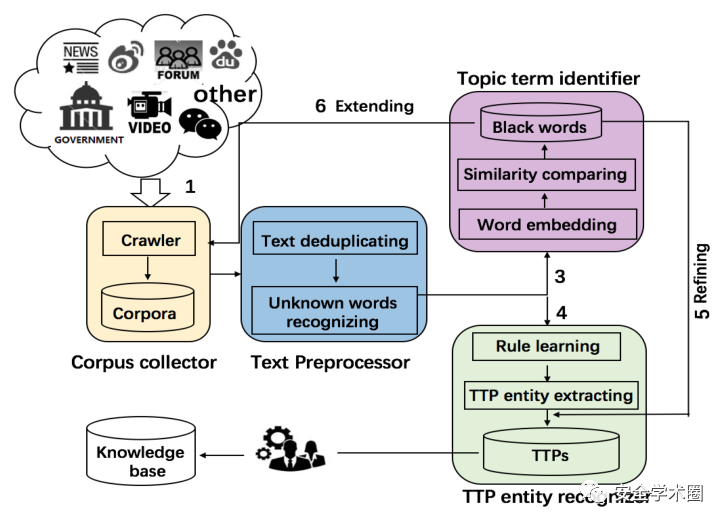 上圖是TAG的總體結構圖,主要包含四個部分:語料庫收集器、文本預處理器、主題詞標識器、TTP實體識別器。
上圖是TAG的總體結構圖,主要包含四個部分:語料庫收集器、文本預處理器、主題詞標識器、TTP實體識別器。
- 語料庫收集:利用阿里的”先知“平臺,從900多個網站中收集威脅文章,并與阿里合作,人工定義了34種電子商務TTP,如下表所示。利用這些TTP作為種子,以關鍵詞匹配的方式收集電子商務威脅相關的頁面。

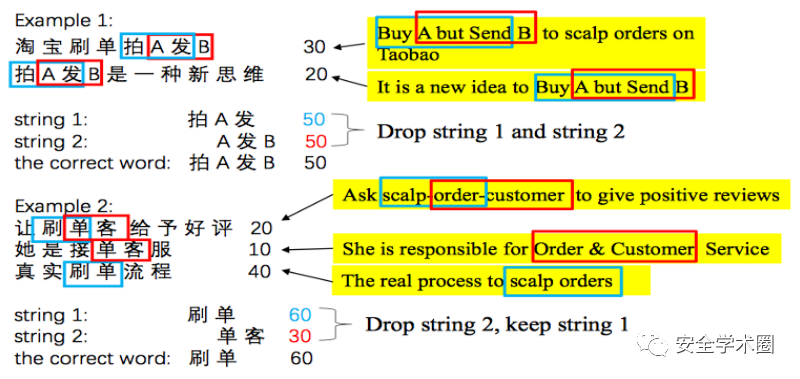
- 文本預處理:首先,關鍵詞匹配后的文章有可能存在重復,通過計算兩篇文章的SimHash值的漢明距離比較它們的相似性,如果漢明距離大于2bits,則刪除其中一篇。對于電子商務威脅的中文分詞,jieba和LTP等工具都不能正確分詞,因此作者設計了一種基于n-gram的鄰居詞頻率統計方法來輔助分詞。若相鄰詞的頻率相等,則兩個都丟棄,采用更長的n-gram繼續統計;否則保留頻率較高的那一個,如下圖所示。
- 主題詞標識:在這一場景中,文章的主題詞一般與上述定義的34種TTP有相似的語義和結構,因此分別計算詞匯的語義相似度和結構相似度,加權后取其中的最大值;其中語義相似度由詞向量的余弦相似度得到,結構相似度由編輯距離得到。
- TTP實體識別:由于語料庫中收集到的文章還包含了廣告等其他內容,TTP在其中的分布比較稀疏,因此首先刪除了文章中的不相關信息。預處理后,剩余的內容從語法結構入手,定義了6種規則來提取TTP實體。


實驗
作者分兩個時期共收集了22380篇文章作為實驗數據集,使用分層抽樣從每個時期中抽取500篇文章人工標記,再進行五折交叉驗證來評估模型,各個部分的實驗結果如下:
- 預處理在識別:53.55%的準確率和83.12%的召回率;
- 過濾不相關TTP句子:正確與錯誤的數量分別為483條和203條;
- 主題詞識別:49.33%的準確率和95.41%的召回率;
- TTP識別:45.56%的準確率和88.47%的召回率;
從結果上看,這一算法可以達到較高的召回率,但代價則是準確率相對較低。
作者在自己收集的語料庫中對比了幾種方法的實驗結果,如下圖所示,作者的方法要優于其他一些主流的方法。
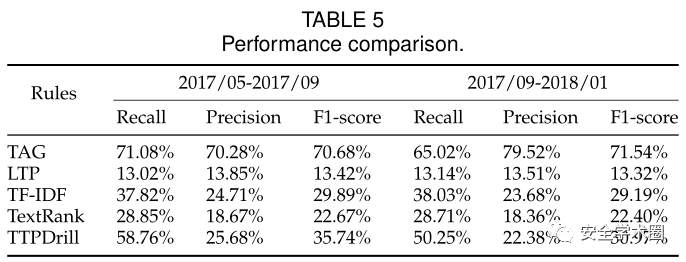
雖然作者的這一方法要比其他NLP方法有著更高的準確性和覆蓋面,但攻擊者也有可能通過省略某些詞匯、調換黑話的順序等方式來繞過模型的檢測,同時對于人類理解而言不會有很大的影響,即模型的抗干擾能力還存在一定的改進空間。

VSole
網絡安全專家