企業哈希(Hash)數據合規指南
雖然加密技術新輩多出,但哈希算法(也稱“散列算法”)自誕生以來,已成為加密算法領域不可或缺的應用。
最簡單的散列算法也被用來加密存在數據庫中的密碼字符串,日常我們在各大APP中注冊時填寫的密碼均是以字符串方式保存在服務器中,用戶登陸時需要再次對輸入密碼實施哈希計算,而后將兩個密碼字符串進行碰撞驗證登陸。
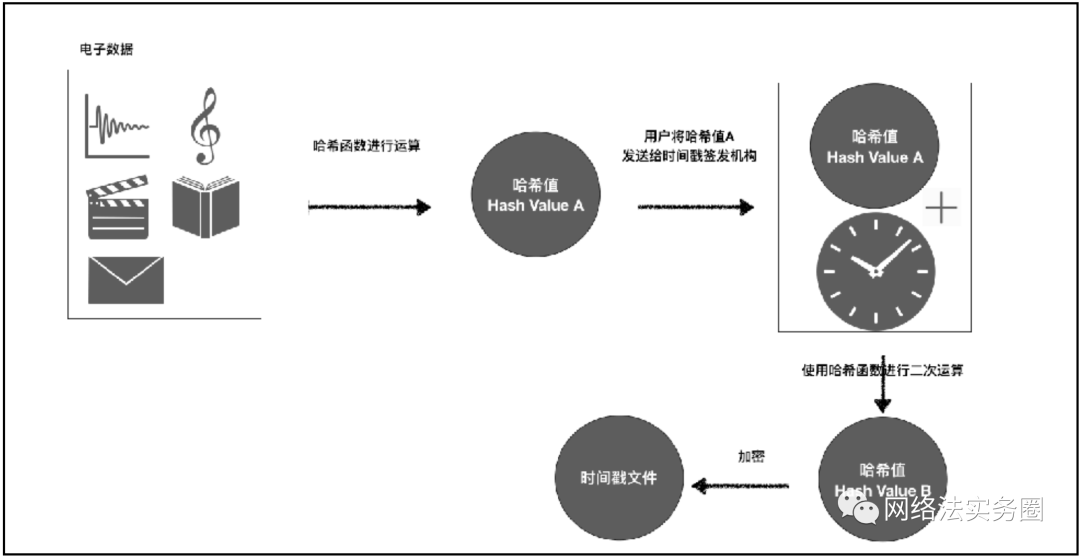
由于散列算法所計算出來的散列值(Hash Value)具有不可逆(無法逆向演算回原本的數值),以及其不可單方篡改(任一原始數據的變動,均會得出完全不同的散列值)的潔癖性質,哈希算法可以在一定程序上保護密碼等數據。
除了上述用戶密碼以哈希算法方式進行保護,哈希算法在企業的數據保護工作中充當了急先鋒的重要角色,有著廣泛的應用。例如,企業的產品或服務在營銷渠道(如各類DMP平臺)投放品牌廣告時,可能需要將其收集用戶的手機號等數據實施哈希加密,并和營銷渠道進行數據對碰,以此識別人群包中的交叉用戶,最終實施精準信息流推送。這實質上也是一種數據的聯合建模方式,雖然看似數據不出庫,但實際上在相關場景及合意下,企業仍然可以通過對撞方式為己方用戶生成和添附新的畫像標簽,這本質上仍然是一種數據收集/共享行為。也正是基于這些痛點,越來越多的企業開始尋求更復雜更安全的隱私計算路徑。
在哈希函數應用中,企業最重要的是需要評估用戶數據被“散列算法”后被重新識別的難易程度,以確定他們需要根據法律法規采取哪些進一步措施來保護用戶數據的安全性,并避免自己陷入散列算法數據屬于匿名化數據的錯覺。
Knuddels案是德國首例GDPR處罰案件,該起案件就是企業未有效評估用戶密碼哈希值安全的最佳例子。2018年夏天,黑客攻擊了Knuddels.de平臺,導致約有808,000封電子郵件地址和180多萬個用戶名和密碼被曝光。德國數據保護當局調查顯示,Knuddels.de平臺通過哈希方式加密存儲了用戶的密碼,但同時把非哈希版本的明文賬號密碼也保留在了網絡服務器上。德國數據保護當局認為,GDPR第32條要求數據控制者和處理者應當采取適當的技術和組織措施保證安全與風險一致性,包括要對個人數據進行假名化和加密處理,但顯然Knuddels沒有意識到密碼哈希的保護方式。
哈希函數一直被用作保護個人數據的工具,但用戶一直懷疑在何種情況下,散列是否可以真正將用戶數據假名化甚至完全匿名化。這個問題很重要,因為個人信息保護法不適用于真正匿名的數據。歐盟《通用數據保護條例》也承認假化名是幫助企業履行數據安全義務的一種選擇。
事實上,根據我國個人信息安全規范等行業邏輯,哈希函數后的哈希值本質上屬于去標識化方式而不是匿名化技術。但筆者認為還是需要分場景考慮,常見的例如手機號碼或身份證號進行哈希運算就是非常容易被攻破并重識別明文數據的,畢竟黑白客世界都有一個“彩虹表”的傳奇存在。另外,不斷發展壯大的社工庫也讓人們的隱私無所遁形,這些都是在聲稱有良好哈希加密的情況下被明文復原的方式。同時,哈希值本身就是用戶新的唯一標識符,在實施數據關聯后又是一條“好漢”。
但在特殊的極特例數據場景中,外部取得哈希函數值,甚至以多次哈希加密方式情況下取得數據的一方,在無源數據庫支持下,是無法復原源數據的,則此數據仍然是有可能被認定為匿名數據的。到底是去標識化還是匿名化,雖然原則上仍應當以去標識化進行識別,但特殊場景中仍然可以個案判斷為匿名化,不宜絕對化定義。
如上所述,可重識別性是企業合規評估的重中之重,不算是企業內部,還是對外提供或委托處理等數據流轉場景中。為防止重新識別散列信息,在《INTRODUCTION TO THE HASH FUNCTION AS A PERSONAL DATA PSEUDONYMISATION TECHNIQU》(《散列函數作為個人數據假名化技術》)報告中,歐盟EDPS 和 AEPD 建議使用機密密鑰對初始消息或散列值進行加密,或者使用稱為“鹽”的常數值或隨機值進行加密,在創建哈希之前添加到所有原始消息中。
根據 上述報告,一系列因素會影響散列是否能夠充分保護個人數據。在尋求應用該措施時,企業需要考慮到的因素包括:(1)散列的計算,使用的散列技術、算法和系統;(2)消息空間:熵——數據集中有序或無序的程度——如果添加隨機元素,則消息的冗余和重復結構;(3)處理環境中散列與其他信息之間的聯系:標識符或偽標識符是否與散列信息直接相關,或者信息是否與散列信息間接相關;(3)已經引入的密碼和其他隨機元素;(4)密碼的持續管理和審計,包括物理安全和人為因素。
在常見的實踐中,我們不能被口語表述中的“匿名化”所晃倒。
在“劍橋分析公司數據泄露”事件中,Facebook上超過5000萬用戶的信息被一家名為“Cambridge Analytica”的公司不當獲取并用于未經授權的目的。然而,根據Facebook的解釋,這些個人信息,例如用戶填寫的心理測試結果,全部是在經過“匿名化”處理后才被用于對外分享的。公司表示,在獲取用戶的授權后,這些數據會“通過匿名的方式被使用和分發,并且保證即使利用這些信息也不能追溯到個人用戶”。
2006年,Netflix為改善其電影推薦服務,公布了包含部分用戶評分的數據庫,其中包括用戶對電影的評分和評分日期。該數據庫是匿名的,采用隨機更改數據庫中包含的大約480,000個用戶的部分評級和評級日期等方法對數據庫進行匿名化處理。但研究表明,只需非常少的輔助信息,就可以對Netflix數據庫中的大部分的用戶記錄進行去匿名化。通過8部電影的評分,和允許誤差14天的評分日期,就可以唯一標識數據庫中99%的用戶。
在基于哈希函數所提供服務產品的案例中,當年的Facebook(即現在的Meta元宇宙)自定義客戶廣告模式案例是值得研究的。自定義廣告受眾是一種較為直接主動的Facebook廣告方式,通過這種方式,賣家不需要被未知的受眾信息所局限,可以根據已有客戶的Facebook 賬號、郵箱地址或者電話建立特定目標受眾,制定多元的廣告格式,向更加精準的目標用戶投放廣告,提高廣告投放效果。
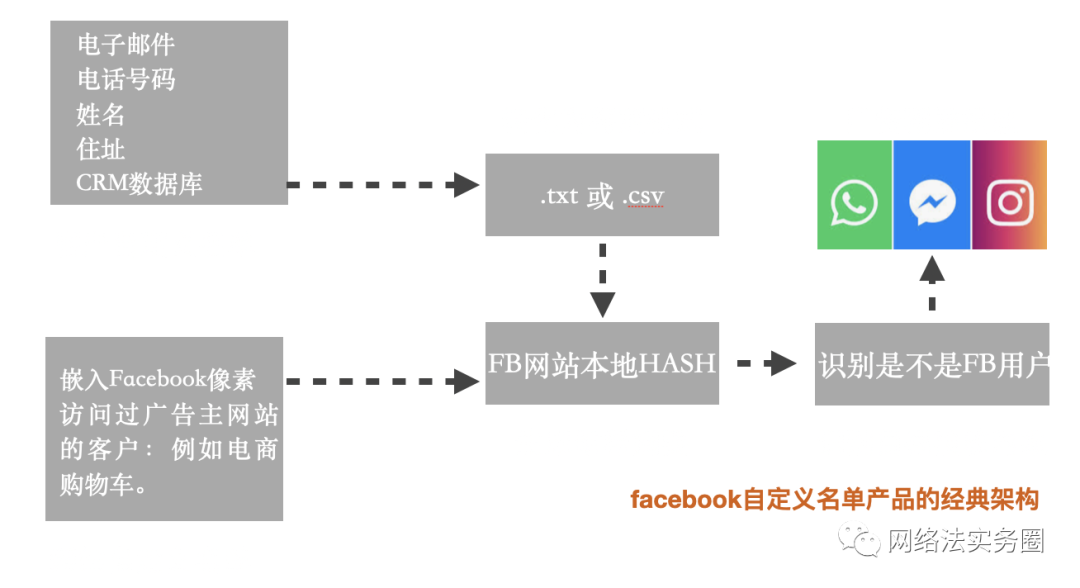 但是,德國巴伐利亞數據保護監督局BayLDA認為Facebook的自定義客戶廣告模式并不合法,要求在德國境內的網站所有者(一家網上商店的運營商)刪除從他的Facebook帳戶創建的用戶列表。慕尼黑高級行政法院VGH 也指出,數據的哈希不能完全消除個人引用和可識別性。
但是,德國巴伐利亞數據保護監督局BayLDA認為Facebook的自定義客戶廣告模式并不合法,要求在德國境內的網站所有者(一家網上商店的運營商)刪除從他的Facebook帳戶創建的用戶列表。慕尼黑高級行政法院VGH 也指出,數據的哈希不能完全消除個人引用和可識別性。
從上述案件可知,盡管使用了散列過程,但傳輸的數據至少對Facebook來說是個人的,理論上講,Facebook可以將上傳的CRM數據與其自身系統中的數據進行比較,從而明確地將提供的數據分配給特定的Facebook用戶,哈希值僅阻止第三方重新識別。
當然,我們也需要考慮一個問題,雖然個人信息保護法不適用于匿名化數據,但對個人信息進行匿名化這一處理行為是否仍應當適用類如知情同意的規則,也是處于模糊地帶。英國ICO(信息專員辦公室)也曾就這個問題在其《anonymisation code》指引中明確表明了立場:匿名化過程通常不需要征得同意,獲得同意可能非常麻煩,甚至是不可能的。但是問題也在于,如果采取的措施不能被視為是匿名化方式或技術,例如僅僅只是去標識化,則仍應當取得用戶的同意為前提,這就為匿名化提出了實質性要求,避免將非匿名化技術認定為匿名化方法,不然會很尷尬。
