分布式流平臺Kafka
提到Kafka很多人的第一印象就是它是一個消息系統,但Kafka發展至今,它的定位已遠不止于此,而是一個分布式流處理平臺。對于一個流處理平臺通常具有三個關鍵能力:
1.發布和訂閱消息流,在這一點上它與消息隊列或企業消息系統類似
2.以容錯的持久化方式存儲消息流
3.在消息流產生時處理它們
目前,Kafka通常應用于兩大類應用:
1.構建實時的流數據管道,可靠地在系統和應用程序之間獲取數據
2.構建實時流的應用程序,對數據流進行轉換或響應
下面我們來一起看一下,Kafka是如何實現以上所說的功能的?
首先了解Kafka幾個特性:
- Kafka作為一個集群運行在一個或多個服務器上,這些服務器可以跨越多個數據中心
- Kafka集群存儲的數據流是以topic為類別的
- 每個消息(也叫記錄record)是由一個key,一個value和一個時間戳構成
Kafka四個核心API
- Producer API,允許應用程序發布消息到1個或多個topic
- Consumer API,允許應用程序訂閱一個或多個topic,并處理它們訂閱的消息
- Streams API,允許應用程序充當一個流處理器,從1個或多個topic消費輸入流,并產生一個輸出流到1個或多個輸出topic,有效地將輸入流轉換到輸出流
- Connector API,允許構建運行可重復使用的生產者或消費者,將topic和現有的應用程序或數據系統連接起來。例如,一個關系型數據庫的連接器可以捕獲到該庫下每一個表的變化

Client和Server之間的通訊,是通過一條簡單的、高性能支持多語言的TCP協議。并且該協議保持與老版本的兼容。Kafka提供了Java客戶端。除了Java 客戶端外,客戶端還支持其他多種語言。
Topic和Log
Topic是發布的消息的類別名,可以用來區分來自不同系統的消息。Kafka中的topic可以有多個訂閱者:即一個topic可以有零個或多個消費者訂閱消費消息。
對于每一個topic,Kafka集群維護一個分區日志,如下圖:

每一個分區都是一個順序的、不可變的序列數據, 并且不斷的以結構化的提交log方式追加。分區中的每條消息都被分配了稱之為offset的序列號,在每個分區中offset是唯一的,通過它可以定位一個分區中的唯一一條記錄。
無論消息是否被消費,Kafka集群都會持久的保存所有發布的消息,直到過期。Kafka的性能和數據大小無關,所以長時間存儲數據沒有什么問題。
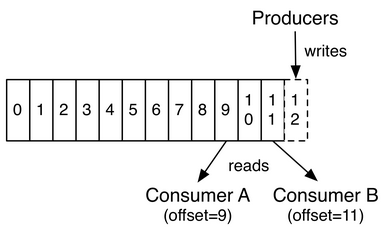
實際上,每個消費者所持有的僅有的元數據就是offset,也就是消費者消費在這個log中的位置。這個offset由消費者控制:一般情況下,當消費者消費消息的時候,offset隨之線性的增加。但是因為實際offset由消費者控制,消費者可以任意指定它的消費位置。同時,一個消費者消費消息不會影響其他的消費者。
Kafka中采用分區的設計主要有兩個目的:第一,當日志大小超過了單臺服務器的限制,允許日志進行擴展。每個單獨的分區都必須受限于主機的文件限制,不過一個主題可能有多個分區,因此可以處理大量的數據。第二,分區可以作為并行處理的單元。
分布式
log的分區被分布到集群中的多個服務器上。每個服務器處理它分到的分區,根據配置每個分區還可以有多個副本作為備份容錯。
每個分區有一個leader,零個或多個follower。leader處理此分區的所有讀寫請求,而follower被動的同步leader數據。如果leader宕機,其它的一個follower會被推舉為新的leader。一臺服務器可能同時是一個分區的leader,另一個分區的follower。這樣可以在集群中進行負載均衡,避免所有的請求都只讓一臺或者某幾臺服務器處理。
Geo-Replication
Kafka MirrorMaker為集群提供了geo-replication即異地數據同步技術的支持。借助MirrorMaker,消息可以跨多個數據中心或云區域進行復制。你可以在active/passive場景中用于備份和恢復; 或者在active/active場景中將數據置于更接近用戶的位置,或者支持數據本地化。
生產者
生產者可以采用輪詢、隨機等策略來決定將數據發布到所選擇的topic中的某個partition上。
消費者
消費者使用一個消費者組名稱來進行標識,發布到topic中的每條記錄被分配給訂閱消費組中的一個消費者實例,消費者實例可以分布在多個進程中或者多個機器上。
如果所有的消費者實例在同一個消費者組中,消息記錄會負載平衡到每一個消費者實例。
如果所有的消費者實例在不同的消費者組中,每條消息記錄會廣播到所有的消費者進程。
如圖,這個Kafka集群有兩臺server,四個分區和兩個消費者組。消費組A有兩個消費者,消費組B有四個消費者。
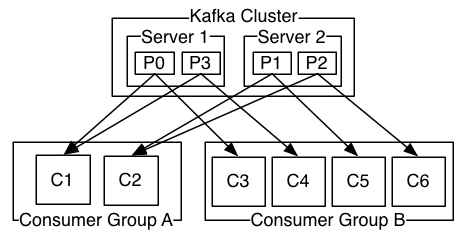
通常情況下,每個 topic 都會有一些消費組,一個消費組對應一個"邏輯訂閱者"。一個消費組由許多消費者實例組成,便于擴展和容錯。這就是發布和訂閱的概念,只不過訂閱者是一組消費者而不是單個的進程。
在Kafka中實現消費的方式是將日志中的分區劃分到每一個消費者實例上,以便在任何時間,每個實例都是分區唯一的消費者。維護消費者組中的消費關系由Kafka協議動態處理。如果新的實例加入組,他們將從組中其他成員處接管一些分區;如果一個實例消失,擁有的分區將被分發到剩余的實例。
Kafka只保證分區內的記錄是有序的,而不保證topic中不同分區的順序。如果想保證全局有序,那么只能有一個分區,但是這樣處理的性能會大幅降低。
Kafka的幾個確定性
1.生產者發送消息到特定的topic的分區上,消息將會按照它們發送的順序依次追加,也就是說,如果一個消息M1和M2使用相同的producer發送,M1先發送,那么M1將比M2的offset小,并且優先的出現在日志中
2.消費者消費的消息也是按照消息在日志中存儲的順序
3.如果一個topic配置了復制因子為N, 那么可以允許N-1臺服務器宕機而不丟失任何已經提交的消息
Kafka作為一個消息系統
傳統的消息系統有兩種模式:隊列和發布-訂閱。在隊列模式中,很多消費者從服務器讀取消息并且每個消息只被其中一個消費者讀取;在發布-訂閱模式中消息則被廣播給所有的消費者。這兩種模式都有優缺點,隊列的優點是允許多個消費者瓜分處理數據,這樣可以擴展處理。但是,隊列不支持多個訂閱者,一旦消費者讀取該消息后,該消息就沒了。而發布-訂閱允許你廣播數據到多個進程,但是無法進行擴展處理,因為每條消息都會發送給所有的訂閱者。
Kafka中消費者組有兩個概念:在隊列中消費者組允許同名的消費者組成員瓜分處理;在發布訂閱中允許你廣播消息給多個消費者組。
Kafka的優勢在于每個topic都支持擴展處理以及允許多訂閱者模式。
Kafka有比傳統的消息系統更強的順序保證
傳統的消息系統按順序保存數據,如果多個消費者從隊列消費,則服務器按存儲的順序發送消息,盡管服務器按順序發送,但消息是異步傳遞到消費者,因此消費者消費到的消息可能是無序的。這意味著在并行消費的情況下,順序就無法保證。消息系統常常通過僅設1個消費者來解決這個問題,但是這意味著無法并行處理數據,性能也就相應降低。
Kafka中的partition就是一個并行處理單元。Kafka通過將topic中的一個partition分配給消費者組中的一個消費者進行消費,保證了消費的順序保證和負載均衡。但是Kafka只能保證一個partition被順序消費,并不能保證全局有序消費,除非只有一個partition。此外,相同的消費者組中如果有比分區數更多的消費者,則多出的消費者會處于空閑狀態,不處理消息。
Kafka作為一個存儲系統
寫入到Kafka的數據會被寫到磁盤并且備份以保證容錯性,并可以通過應答機制,確保消息寫入。
Kafka使用的磁盤結構,具有很好的擴展性,使得50kb和50TB的數據在服務器上表現一致。你可以認為kafka是一種高性能、低延遲的提交日志存儲、備份和傳播功能的分布式文件系統,并且可以通過客戶端來控制讀取數據的位置。
Kafka的流處理
Kafka流處理不僅僅用來讀寫和存儲流式數據,它最終的目的是為了能夠進行實時的流處理。
在Kafka中,流處理持續獲取輸入topic的數據,進行處理加工,然后寫入輸出topic。例如,一個零售APP,接收銷售和出貨的輸入流,統計數量或調整價格后輸出一系列流數據。
可以直接使用producer和consumer API進行簡單的處理。但是對于復雜的數據轉換,Kafka提供了更強大的streams API,可用于構建聚合計算或join多個流。這一功能有助于解決此類應用面臨的硬性問題:如處理無序的數據,消費者代碼更改的再處理,執行狀態計算等。
sterams API建立在Kafka的核心之上:使用producer和consumer API作為輸入,利用Kafka做狀態存儲,使用相同的消費者組機制在流處理器實例之間進行容錯保障。
寫在最后
消息傳遞、存儲和流處理的組合是Kafka作為流式處理平臺的關鍵特性。
像HDFS這樣的分布式文件系統允許存儲靜態文件來進行批處理。這樣系統可以有效地存儲和處理歷史數據。而傳統的企業消息系統允許在你訂閱之后處理將來的數據,并在這些數據到達時處理它。Kafka結合了這兩種能力,這種組合對于Kafka作為流處理應用和流數據管道平臺是至關重要的。
通過消息存儲和低延遲訂閱,流應用程序可以以同樣的方式處理歷史和將來的數據。一個單一的應用程序可以處理歷史數據,并且可以持續不斷地處理以后到達的數據,而不是在到達最后一條記錄時就結束進程。這是一個廣泛的流處理概念,其中包含批處理以及消息驅動應用程序。
同樣,作為流數據管道,能夠訂閱實時事件使得Kafk具有非常低的延遲;同時Kafka還具有可靠存儲數據的特性,可用來存儲重要的支付數據或者與離線系統進行交互,系統可間歇性地加載數據,也可在停機維護后再次加載數據。流處理功能使得數據可以在到達時轉換數據。
