[AI安全論文] (23)惡意代碼作者溯源(去匿名化)經典論文閱讀:二進制和源代碼對比
一.NDSS18:二進制代碼的作者去匿名化

1.摘要
根據代碼風格(coding style)識別計算機程序作者的能力直接威脅到程序員的隱私和匿名性。
雖然最近的工作發現,源代碼(source code)可以高精度地溯源至(attributed to)作者,但可執行二進制文件(executable binaries)作者的歸屬問題似乎要困難得多。因為源代碼中存在許多顯著的特征,例如變量名,但在編譯過程中會被刪除,并且編譯器優化可能會改變程序的結構,進一步掩蓋已知對確定作者身份(authorship)有用的特征。
本文從機器學習角度實現程序員去匿名化任務,使用一組新穎的特征,包括將可執行二進制文件反編譯為源代碼所獲得的特征。同時采用來自源代碼作者溯源領域的一組強大的技術以及嵌入在匯編中的風格表征,從而成功地對大量程序員進行去匿名化處理。
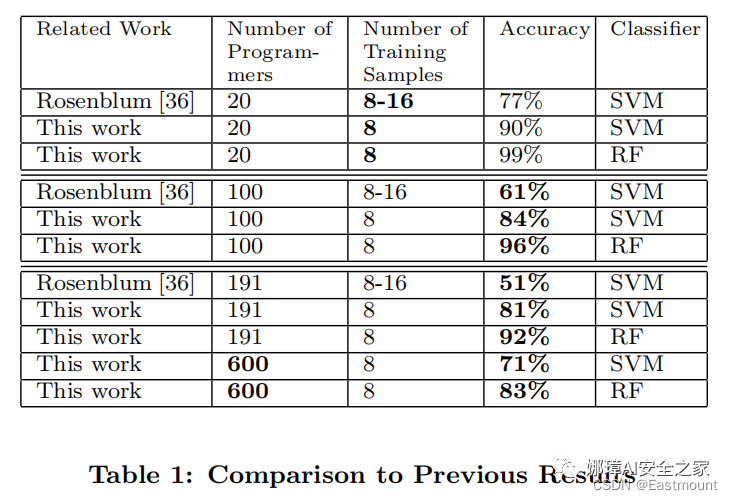
本文實驗通過谷歌GCJ(Google Code Jam)數據集評估了方法的有效性,其中,100名候選程序員的溯源準確率高達96%,600名候選程序員的溯源準確率為83%。我們首次提出了一種可執行二進制文件的作者溯源方法,該方法對基本混淆、一系列編譯器優化設置和去符號表的二進制文件具有魯棒性。此外,本文使用混淆的二進制文件和在單作者GitHub存儲倉庫以及最近泄露在 Nulled.IO 黑客論壇中的“在野”真實代碼來執行程序員去匿名化實驗。結果表明,那些想要保持匿名的程序員需要采取極端的應對措施來保護他們的隱私。

2.引言
如果遇到一個“在野”可執行的二進制樣本,我們可以從中學到什么?
在本文的工作中,我們展示了程序員的風格指紋或編程風格在編譯過程中是能被保留下來的,并且可以從可執行的二進制文件中提取。這意味著,如果我們有一組已知的潛在候選程序員,以及由這些候選程序員編寫的可執行二進制樣本(或源代碼),就可以推斷出程序員的身份。
可執行二進制文件的作者去匿名化影響了隱私和匿名性。但在軟件取證、版權、審查等領域中需要實現作者溯源,我們的工作能有效實現二進制文件的去匿名化。此外,白宮和DARPA指出“需要增強溯源能力以識別不同端設備和C2基礎設施的虛擬角色和惡意網絡運營商”。
方法對比突出本文貢獻:
- Rosenblum經典工作:可以直接從可執行二進制文件中提取控制流圖等結構,首次針對二進制代碼提出一種自動檢測代碼風格特征的方法并確定程序作者
- 本文工作:首次證明可執行二進制文件的自動反編譯(automated decompilation)提供了額外有用的特征。具體而言,我們生成反編譯源代碼的抽象語法樹(abstract syntax trees),利用隨機森林分類器能有效地組合特征,從而提升作者溯源的準確性。
具體方法為:分析人員需要將每個標記的二進制樣本轉換為一個數值特征向量,再利用機器學習技術推導出一個分類器,并預測匿名二進制文件最有可能的程序員。此外,我們發現二進制混淆、啟用編譯器優化或剝離可執行二進制文件的調試符號會降低去匿名化的準確性。
- 關鍵點:經過分解和反編譯獲得的特征向量如何來預測源代碼中的特征,如何重構二進制代碼的編程風格特征(指紋)
N. Rosenblum, X. Zhu, and B. Miller. Who wrote this code? Identifying the authors of program binaries. Computer Security–ESORICS, 2011.
相關工作:
- Linguistic stylometry
- Source code stylometry
- Executable binary stylometry
3.本文方法
Our ultimate goal is to automatically recognize programmers of compiled code.
數據表示對于機器學習的成功至關重要。因此,我們為可執行二進制作者溯源設計了一個特征集,目標是準確地表示與程序員風格相關的可執行二進制文件的屬性。我們通過使用額外的字符串和符號信息來增強從反匯編器中提取的低級特征,從而獲得該特征集,最重要的是,該方法結合了從反編譯器獲得的高級語法特征(syntactical features)。
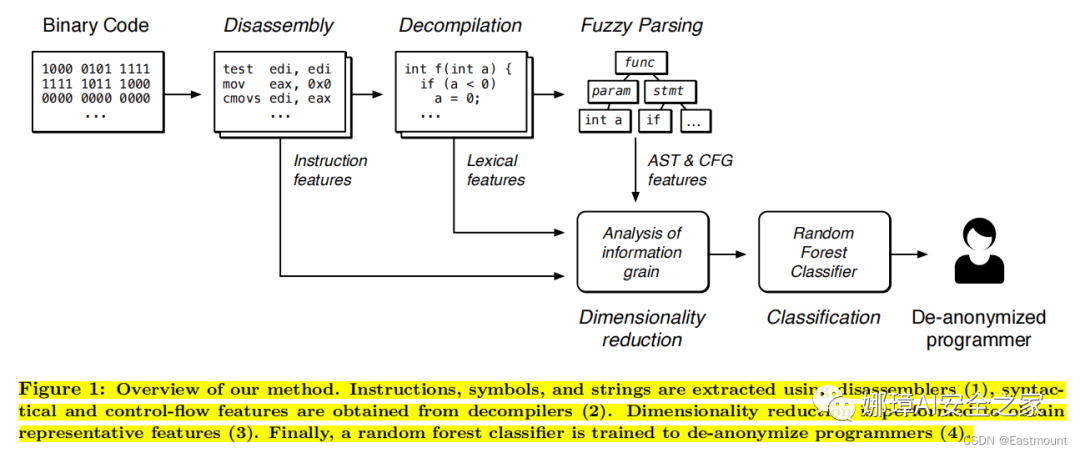
本文方法的框架圖如下所示,包括四個關鍵步驟:
- Disassembly(反匯編)。我們首先對二進制程序進行反匯編,以獲得基于機器代碼指令、引用字符串、符號信息和控制流圖(CFG)的特征(第 4.1 節)。
- Decompilation(反編譯)。我們繼續通過反編譯將程序翻譯成類似C語言的偽代碼。隨后將代碼傳遞給C語言的模糊解析器,因此,我們獲得了可以從中提取語法特征和n-gram的抽象語法樹(第 4.2 節)。如圖中函數f聲明及變量a定義。
- Dimensionality reduction(降維)。借助反匯編器和反編譯器的特征,我們利用基于信息增益和相關性的特征選擇技術,選擇其中對分類特別有用的特征(第 4.3 節)。
- Classification(分類)。最后,在相應的特征向量上訓練一個隨機森林分類器,生成一個可用于自動執行二進制作者溯源的程序(第4.4節)。
關鍵特征:
- Instruction features
- Lexical features
- AST & CFG features
(1) Feature extraction via disassembly
利用反匯編器提取低級特征。按照Rosenblum方法從可執行二進制中提取原始指令軌跡,同時反匯編程序會提供符號信息以及代碼中引用的字符串,再從反匯編器中獲得函數的控制流圖,提供基于程序基本塊的特征。
- The netwide disassembler:基本的反匯編器,能夠解碼指令。從頭到尾反匯編二進制文件,遇到無效指令時跳過該字節。
- The radare2 disassembler:從動態和靜態符號表中提取符號并獲得動態庫函數知識,生成相應的控制流圖。
(2) Feature extraction via decompilation
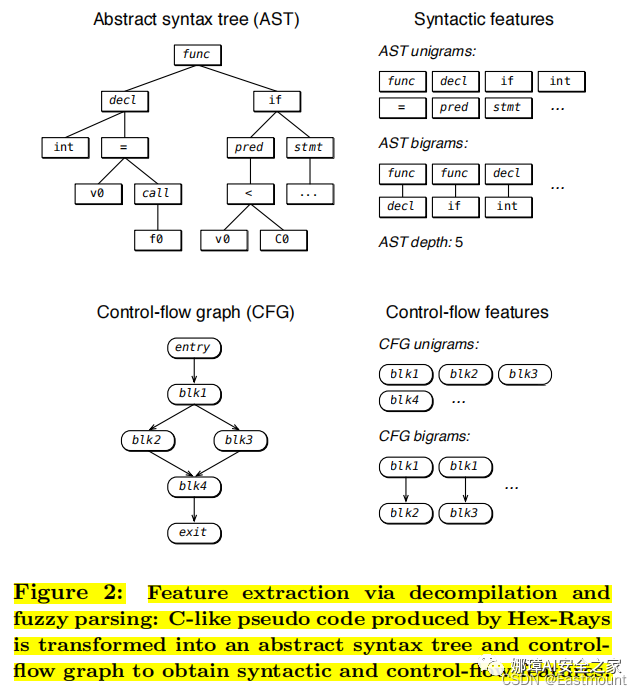
與反匯編器相比,反編譯器不僅揭示程序的機器代碼指令,而且還額外重構更高層次的結構,試圖將可執行二進制文件轉換為等價的源代碼。特別而言,反編譯器可以重構控制結構,如不同類型的循環和分支結構。我們利用了代碼的這些語法特性,因為它們在源代碼作者身份溯源的上下文中已經被證明是有價值的。我們從偽代碼中提取了兩種類型的特征:
- lexical features(詞法特征):單詞組合以捕獲程序中使用的整數類型、庫函數名稱,以及當符號信息可用時內部函數的名稱。
- syntactical features(語法特征):抽象語法樹。
(3) Dimensionality reduction
特征提取會產生大量特征,從而產生具有數千個元素的稀疏特征向量。然而,并不是所有的特征都具有同樣的信息來表達程序員的風格。因此,需要進行特征選擇的降維操作。我們使用信息增益準則,然后基于相關性的特征選擇來識別將每個作者表示為一個類的信息量最大的屬性。
- 方法一:information gain(WEKA編寫代碼)
- 方法二:correlation based feature selection
We use information gain criteria followed by correlation based feature selection to identify the most informative attributes that represent each author as a class.
(4) Classification
我們使用隨機森林分類器,它是由決策樹集合構成的集成學習算法,其中每棵樹都是在隨機抽樣獲得的數據的子樣本上進行訓練。(kappa編寫代碼)
4.實驗評估
(1) GCJ數據集
我們在一個基于年度編程競賽GCJ的數據集上評估了可執行二進制作者溯源方法。本文的分析重點是已編譯的C++代碼,這是比賽中使用最流行的編程語言。我們收集了2008年至2014年的解決方案,以及作者名稱和問題標識符。
- Google Code Jam Programming Competition. code.google.com/codejam.
為了創建實驗數據集,我們首先用GNU編譯器集合的gcc或g++編譯了源代碼,并且沒有對二進制文件進行任何優化。我們還編譯了具有1級、2級和3級優化的源代碼,即O1、O2和O3標志。
- To create our experimental datasets, we first compiled the source code with GNU Compiler Collection’s gcc or g++ without any optimization to Executable and Linkable Format (ELF) 32-bit, Intel 80386 Unix binaries.
我們感興趣的是識別二進制文件中的編碼樣式特征。應用當前方法,我們提取了100名作者的750,000種代碼屬性表示,最終保留了53個高度區分的特征。實驗結果如下圖所示:
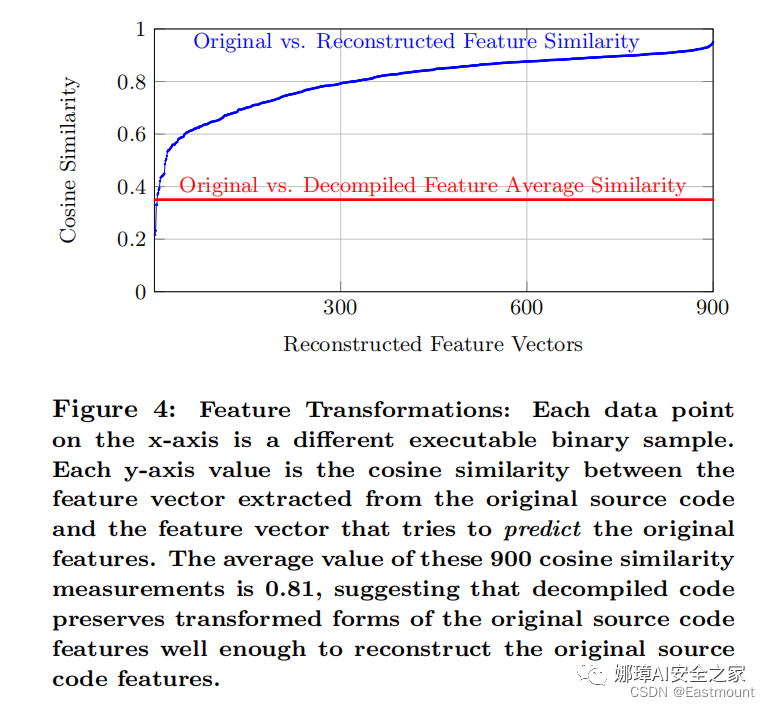
通過源代碼特征向量與預測原始特征向量的余弦相似度比較,我們得出如下圖所示的實驗結果,900個余弦相似度度量的平均值為0.81。該結果表明:
- 反編譯代碼很好地保留了原始源代碼特征的轉換形式,即重構的特征接近于源代碼的特征。因此,本文方法可以重構原始源代碼特征。
(2) 真實場景
此外,本文使用混淆的二進制文件和在單作者GitHub存儲倉庫以及最近泄露在 Nulled.IO 黑客論壇中的“在野”真實代碼來執行程序員去匿名化實驗。
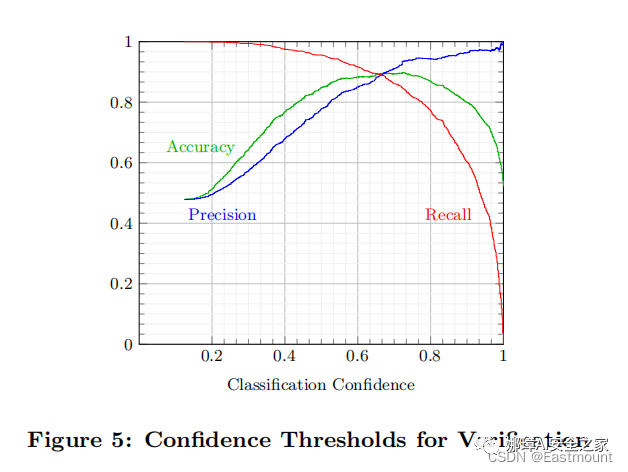
5.討論和結論
本文實現了二進制文件的作者溯源(去匿名化)研究,展現了代碼方格是能在編譯后提取的,并且在GCJ和Github真實數據集中進行了程序員去匿名化實驗。其中,100名候選程序員的二進制溯源準確率高達96%,600名候選程序員的溯源準確率為83%。
同時,本文通過兩種不同的反匯編器、控制流圖和一個反編譯器,獲得了這種編碼樣式的精確表示,有效提取53個關鍵特征。程序員風格會以令人驚訝的程度嵌入到可執行的二進制文件中,即使它被混淆、編譯器優化或符號被剝離降低了風格分析的準確性,但在仍能應用于程序員去匿名化任務中。結果表明,那些想要保持匿名的程序員需要采取極端的應對措施來保護他們的隱私。
Programmer style is embedded in executable binary to a surprising degree, even when it is obfuscated, generated with aggressive compiler optimizations, or symbols are stripped. Compilation, binary obfuscation, optimization, and stripping of symbols reduce the accuracy of stylistic analysis but are not effective in anonymizing coding style.
未來工作:
- 計劃研究代碼片段和功能級別的代碼風格信息
- 對去匿名化協作生成的二進制文件開展多作者溯源研究
- 對高度復雜的編譯和混淆方法開展研究
6.個人感受
寫到這里,這篇論文就分享結束了,再次感謝論文作者及引文的老師們。接下來是作者的感受,由于是在線論文讀書筆記,僅代表個人觀點,寫得不好的地方,還請各位老師和博友批評指正,感恩遇見,讀博路漫漫,一起加油!
- 先前的工作多集中于源代碼作者溯源,提取具有作者編程(代碼)風格的特征是關鍵。然而,二進制代碼會因為編譯、混淆等處理導致編程風格丟失,并且惡意攻擊中常以可執行二進制文件為主。因此,針對二進制代碼的作者溯源或去匿名化研究直觀重要。
- 該論文摘要的方法論部分似乎還可以補充下,同時摘要的實驗部分沒有之前看到的頂會論文清晰。
- 論文的方法比較簡單,包括反匯編、反編譯、降維和分類四個部分,所使用的分類方法為隨機森林,提取的特征我們也能想到。從現在來看,很容易想到,但2018年能寫到這樣還是挺佩服的,也值得我們學習。個人認為,相比于模型的新舊,安全論文更看重模型如何解決實際問題以及是否貼合創新。
- 實驗部分希望自己今后能復現下,包括GCJ數據集(源碼編譯二進制)和真實數據集,同時可以深入思考如何進一步提升性能,動態特征和靜態特征如何更好地結合實現作者溯源,真正去解決惡意二進制代碼作者溯源難點。此外,一篇好論文通常會有真實的實驗支撐,實驗需要和我們的方法論互補且結合。
- Caliskan-Islam和Rosenblum兩個團隊在代碼去匿名化領域做了較多工作,推薦大家去系統學習。同時,APT溯源、作者溯源存在怎樣的區別或關聯呢?預計2023年初,我會詳細寫一篇文章總結各類溯源及檢測技術 。
二.UsenixSec15:基于代碼風格的源代碼去匿名化

1.摘要
源代碼作者溯源是對匿名代碼貢獻者的一個重大隱私威脅。然而,它還可以將成功的攻擊歸因于受感染系統上遺留的代碼,或幫助解決編程領域中的版權、著佐權和剽竊問題。
在這項工作中,我們研究了使用編碼風格對 C/C++ 的源代碼作者進行去匿名化的機器學習方法。我們的代碼風格特征集是一種在源代碼中發現的編碼風格的新穎表示,它反映了來自抽象語法樹的屬性的編碼風格。
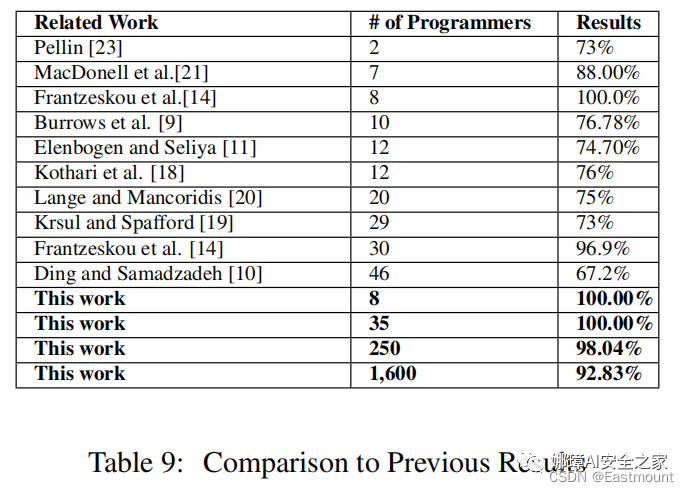
我們基于隨機森林和抽象語法樹的方法溯源了更多的作者(1600和250),并且在更大的數據集(Google Code Jam)上具有比先前工作更高的準確率(94%和98%)。此外,這些新特征是健壯的,難以混淆的,并且可以用于其它編程語言,如Python。
我們還發現:
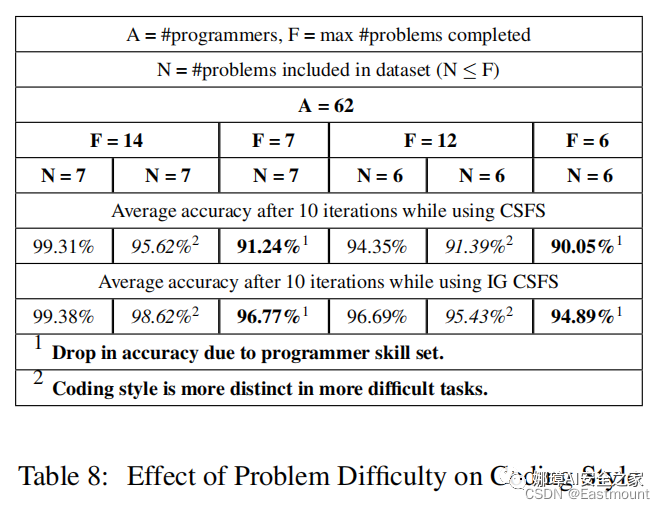
- (i)由困難的編程任務產生的代碼比容易的任務更易于溯源;
- (ii)熟練的程序員(可以完成更困難的任務)比不熟練的程序員更容易溯源。

2.引言
程序員會在源代碼中留下指紋嗎?每位程序員都有一個獨特的“編碼風格”(coding style)嗎?
或許,程序員更喜歡空格而不是標簽,或者更喜歡while循環而不是for循環,再或者更微妙地說,比起單一代碼更喜歡模塊化代碼。
這些問題有很強的隱私和安全影響。開源項目的貢獻者可能會隱藏他們的身份,無論他們是Bitcoin的創造者,還只是一個不希望她的雇主知道她的業余活動的程序員。他們可能生活在一個禁止某些類型軟件的制度中,比如審查規避工具。
另一方面,代碼溯源可能會有幫助取證,比如發現代寫、抄襲和版權糾紛調查等。它也可能給我們提供關于惡意軟件作者身份的線索。警惕的攻擊者可能只留下二進制文件,但其他的攻擊者可能會留下腳本語言編寫的代碼或下載到被破壞系統中進行編譯的源代碼。
本文在先前研究的基礎上,展示了抽象語法樹能攜帶作者相關的“指紋”,從而提升準確率。本文的貢獻如下:
- 首先,我們將語法特征(syntactic features)作用于代碼風格(code stylometry)。
- 提取這些特征需要使用模糊解析器(fuzzy parsing)解析不完整的源代碼以生成抽象語法樹。這些特征為迄今為止幾乎完全未開發的代碼樣式添加了一個組件。我們提供的證據表明,這些特征更為基礎且更難混淆。我們的完整特征集由大約12萬個基于 布局(layout)、詞法(lexical)和語法(syntactic) 的特征組成。有了這個完整的特征集,我們比先前的工作具有更高的準確率。
- 其次,本文將該方法擴展到1600名程序員并且未損失很多準確率。
- 最后,該方法不是特定于C或C++的,可以應用于任何編程語言。
本文從GCJ比賽中收集C++源代碼,利用基于詞袋的隨機森林分類器來實現源代碼的程序員溯源。最后,我們分析了程序員的各種屬性、編程任務類型,以及會影響溯源成功的特征。我們從12萬個特征中確定了最重要的928個特征,其中44%是語法性的,1%是基于布局的,其余的特征是詞匯性的。當使用詞匯、布局和句法特征時,平均有70行代碼的8個訓練文件是足夠的。我們還觀察到,具有更高技能的程序員更容易識別,而且程序員的編碼風格在困難任務的實現中比更容易的任務更獨特。
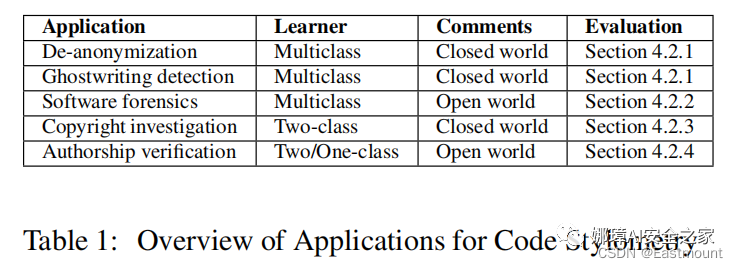
研究動機:
- Programmer De-anonymization:bitcoin作者去匿名化
- Ghostwriting Detection:剽竊行為檢測、學生作業抄襲判定(代碼風格相似性)
- Software Forensics:惡意代碼作者取證
- Copyright Investigation:版權調查和代碼版權糾紛
- Authorship Verification:授權驗證(one-class SVM)
3.本文方法
本文研究目標之一是創建一個分類器以自動確定源文件最有可能的作者。機器學習是解決該問題的一個選擇,然而,它們的成功關鍵取決于一個具有代表性編程風格特征集的選擇。為此,我們:
- 首先,解析源代碼,從而獲得廣泛的反映編程語言用法的可能特征(第3.1節)。
- 然后,定義不同特征來表示程序代碼的語法和結構(第3.2節)。
- 最后,訓練一個隨機森林分類器用于分類未知的源代碼。
(1).Fuzzy Abstract Syntax Trees
迄今為止,源代碼作者溯源的方法主要集中于代碼的順序特征表示上,如字節級和特征級的n-gram。雖然這些模型非常適合捕獲命名約定和關鍵字的偏好,但它們完全是與語言無關,因此無法對僅在語言結構組合中明顯的作者特征進行建模。例如,作者傾向于創建深度嵌套的代碼、異常長的函數或較長的賦值鏈接,這不能單獨使用n-gram來建模。
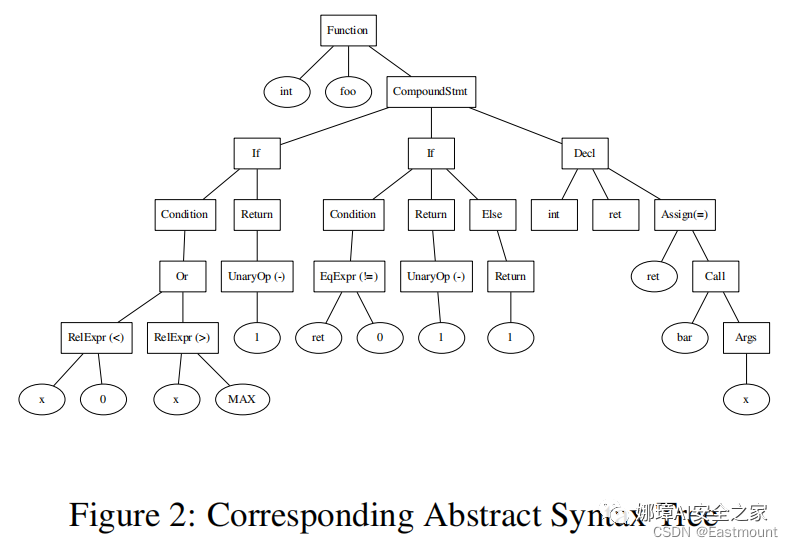
針對不完整代碼,我們使用模糊解析器解析代碼,從而生成對應的抽象語法樹。生成的語法樹構成了我們特征提取過程的基礎。雖然它們很大程度上保留了創建n-grams或bag-of-words表示所需的信息,但它們允許提取大量特征,這些特征對代碼結構中可見的程序員習慣進行編碼。
下圖是一個源代碼轉換為抽象語法樹的示例,抽象語法樹都包含一個對應的節點,樹的葉子節點使經典的語法特征如關鍵字、標識符和操作符,內部節點表示顯示的操作如何組合這些基本元素來形成表達式和語句。

(2).Feature Extraction
為了更清晰地表達源代碼的程序風格,本文提出了代碼風格特征集(Code Stylometry Feature Set,CSFS),這是一種專門為代碼風格開發的源代碼表示方法。該特征集包括詞匯特征、布局特征和語法特征。其中,詞匯特征和布局特征只能從源代碼中獲得,而語法特征只能從AST中獲得。
- Lexical Features
- Layout Features
- Syntactic Features
首先從源代碼中提取數字特征,這些數字特征表達了對某些標識符和關鍵字的偏好,以及一些關于函數使用或嵌套深度的統計數據。詞匯和布局特性可以從源代碼計算,而不訪問解析器,使用編程語言的基本知識。此外,我們對源文件進行標記化,以獲得每個標記的出現次數,即所謂的單詞單圖。表2給出了詞匯特征的概述。

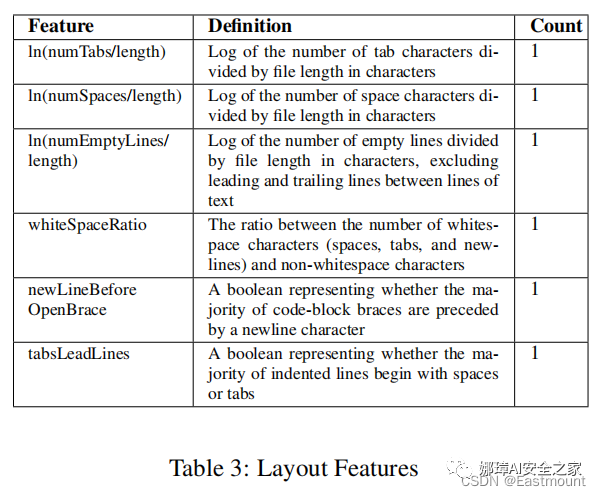
此外,我們還考慮了表示代碼縮進的布局特性。例如,我們確定大多數縮進的行是以空白還是制表符開頭,并確定空格與文件大小的比率。表3給出了對這些特征的詳細描述。
語法特征集描述了依賴于語言的抽象語法樹和關鍵字的屬性。計算這些特性需要訪問一個抽象的語法樹,所有這些特征對于源代碼布局和注釋的更改都是不變的。表4給出了語法特征的概述,我們通過對數據集中的所有C++源文件進行預處理來生成抽象語法樹并獲得這些特征(TF、IDF、TFIDF)。
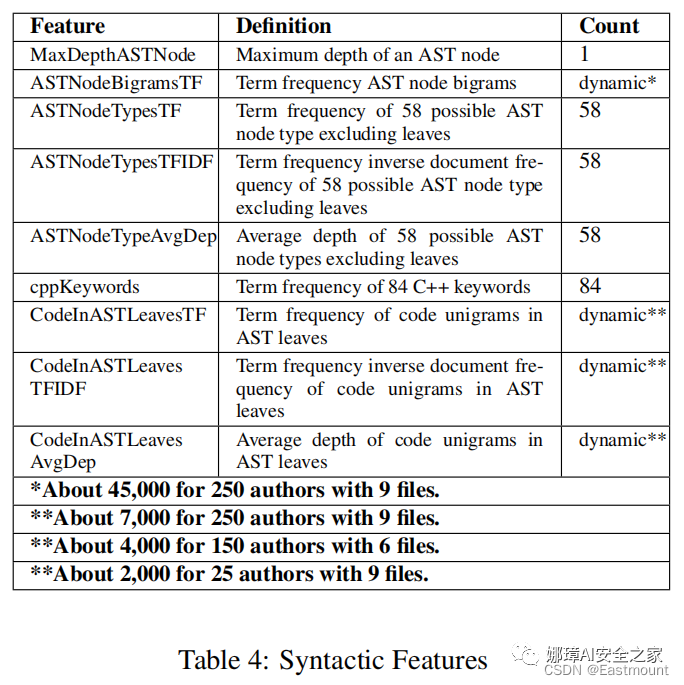
抽象語法樹得58種節點類型如下表所示。AST節點的平均深度顯示了程序員傾向于使用特定結構片段的嵌套或深度。最后計算每個C++關鍵字的項頻率,每個特征都被寫入一個特征向量,以表示特定作者的解決方案文件,這些向量隨后被用于機器學習分類器的訓練和測試。
(3).Classification
由于會產生大量特征且存在矩陣稀疏問題。因此,我們采用WEKA的信息增益準則進行特征選擇,該準則評估類的分布的熵與給定特定特征的類的條件分布的熵之間的差異:

為了減少特征向量的總大小和稀疏性,我們只保留那些信息增益非零的特征。最后構建隨機森林分類器進行源代碼作者溯源。

4.實驗評估
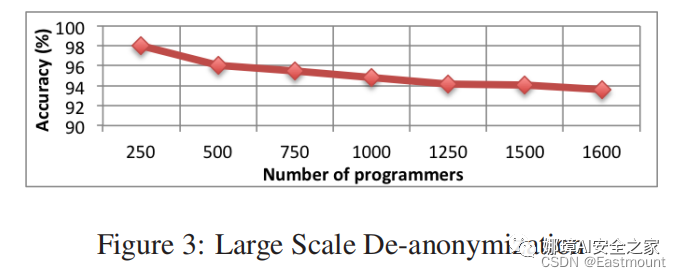
實驗數據集是在Google Code Jam (GCJ)的基礎上構建的數據集,包括1600名程序員,實驗結果如下圖所示:

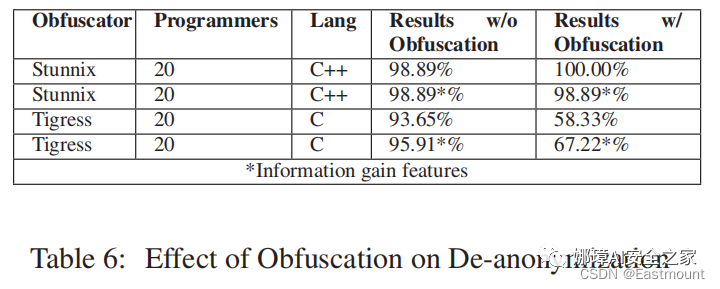
同時進行了混淆、不同編程語言的實驗。
5.結論
當前,源代碼的編程風格已經被廣泛應用于隱私、安全、軟件取證、剽竊、版權侵權糾紛和作者驗證領域。源代碼編程風格對于代碼去匿名化是一個迫在眉睫的問題。
本文首次系統性使用詞法、布局和語法特征來研究源代碼的編程風格,并對1600位作者進行分類,其準確率為94%,對250位作者進行分類,準確率為98%。本文方法提高了源代碼作者溯源的準確率和規模。此外,傳統方法僅能識別50個作者,分析的文本需要5000個單詞,本文通過訓練550行代碼和8個解決方法即可實現。特別而言,本文的研究表明:
- 基于代碼風格特征集(code Stylometry Feature Set)的源代碼作者溯源比常規風格作者溯源更有效
未來工作:
- 由于惡意代碼通常只能使用二進制格式,因此研究二進制文件如何保留語法特征是一件有趣的工作
- 進一步提高分類精度,例如,我們想探討使用具有聯合信息增益的特性是否會提高性能
- 設計捕獲抽象語法樹更大片段的特征來提升性能,這些更改(以及添加詞法和布局特征)可能會對Python的結果提供顯著的改進
- 代碼是否可以自動規范化以刪除樣式信息,同時保留功能和可讀性
6.個人感受
這篇文章針對源代碼去匿名化開展研究,完成于2015年,整個文章的亮點是:
- 源代碼編程風格特征的總結,即(Code Stylometry Feature Set,CSFS),包括詞匯、布局和語法三類特征,其中通過抽象語法樹提取語法特征,詞匯特征和布局特征從源代碼中統計獲得。
接著,通過特征提取、降維和向量表征來構建具有編程風格的源代碼向量,最后構建隨機森林分類器完成任務。方法論和前面二進制作者溯源比較相近,現在回頭看,方法和實驗略微簡單,但仍有很多值得我們學習的地方,包括:
- 如何更少地結合人工經驗(特征工程)完成該任務,是否能結合源代碼本身特性來構建深度學習模型完成分類,深度學習又將如何實現呢?
- 如何解決代碼混淆、編譯優化等溯源問題,包括二進制溯源、多作者溯源等
- 在特征工程中如何構建更好地降維方法識別更關鍵的特征,并提高作者溯源的可解釋性(tanE)
- 如何與實際安全問題結合,包括APT溯源、無文件攻擊溯源等
寫一篇好的頂會真難,值得我們學習,繼續加油!
三.總結
寫到這里,這篇文章就分享結束了,再次感謝論文作者及引文的老師們。由于是在線論文讀書筆記,僅代表個人觀點,寫得不好的地方,還請各位老師和博友批評指正。
后面作者將分享兩篇基于深度學習的作者溯源論文,分別是:
- Mohammed Abuhamad, et al. Large-Scale and Language-Oblivious Code Authorship Identification, 2018 CCS.
- Saed Alrabaee, et al. CPA: Accurate Cross-Platform Binary Authorship Characterization Using LDA, 2020 IEEE TIFS.


最后,用川大吳鵬博士的論文進行總結,非常推薦大家學習且感謝吳老師。
