中原銀行融合數據湖建設實踐
隨著國內銀行業數字化轉型進程的加快,以及數據驅動戰略在銀行的落地實踐,2019年中原銀行圍繞分布式數據倉庫和大數據技術,以自主研發架構為主,構建了一套滿足一站式數據集成、存儲、整合、計算與開發的數據技術中臺,解決了海量數據存儲與分析的問題,并有效支撐了行內商業決策與各類應用規模化交付。近年來,全行數字化轉型步入深水區,業務線上化、移動化和場景化比例越來越高,相應地也帶來了數據規模爆發式增長和數據類型多樣性等問題。
數據倉庫作為中原銀行主要的基礎設施,我們圍繞數據倉庫建設的數據整合平臺承接了行內大量的貼源、明細數據。3年間其存儲的數據總量增加了2倍多,基于數據倉庫架構的應用數量增長到60多個,數據倉庫擴容已趨于常態化,數據存儲成本占全行信息科技預算的比例也越來越高。
同時,以RPA、人機交互、知識圖譜等為主的人工智能技術對半結構、非結構數據的存儲、特征提取以及數據加工提出了新的要求,單一的數據倉庫技術已無法應對上述的挑戰。
行業湖倉一體的建設方案
2020年下半年,我們開始探索解決方案,數據湖進入了我們的視線。通過對比,我們發現數據湖和數據倉庫作為大數據體系架構下兩條不同的技術演進路線,具有各自的優勢和局限性。具體表現在以下幾個方面。
一是在數據處理和存儲能力方面,數據湖支持結構化、半結構化、非結構化數據的存儲與加工,而數據倉庫基本上只支持結構化數據。
二是數據倉庫在處理數據之前要先進行數據梳理、定義數據結構后才可以進行入庫操作,而數據湖按照原樣存儲數據,無需事先對數據進行結構化處理,這也造成數據湖缺乏像數據倉庫的數據管理能力,數據質量較差。
三是數據湖在靈活性上具備天然優勢,開源大數據引擎只需遵循相對寬松的兼容協議就能夠讀寫數據湖中的數據;而數據倉庫只對特定引擎開放,并作了深度定制優化,進而換取更高的存儲與計算性能。

不難看出,數據湖與數據倉庫兩者雖然能力互補但卻很難直接合并成一套系統。有沒有一種更好地架構可以將二者的能力相互統一?Gartner在2011年提出邏輯數據倉庫的概念,推測企業數據分析將會轉向一種更加邏輯化的架構,實現邏輯統一物理分開的協同體系。
借助邏輯數據倉庫的架構理念,各大云廠商陸續推出自己的“湖倉一體”技術方案,采用湖倉協同工作的方式,將數據湖、數據倉庫與數據類服務連接成為一個整體,數據在其間按需自由移動,以邏輯統一的方式為用戶提供服務。
融合數據湖建設思路
數據顯示,2021中國數據庫市場行業分布,金融占20.2%,政府占18.4%,互聯網14.8%,運營商8.9%。毫無疑問,以銀行為代表的金融行業仍然是數據庫銷售額占比最高的市場,也是對數據庫技術依賴度最高、要求最嚴格的市場。
數據倉庫作為數據庫技術在大數據時代的一種產品形態,其安全穩定、高效易用和完善而精細的數據管理能力完美地滿足了金融行業對海量數據的分析需求。
因此在金融行業依然對數據倉庫依賴較重的前提下,如何更好地兼容企業數據技術中臺建設的歷史現狀,同時將數據湖的低成本、靈活性與數據倉庫的企業級能力有機結合,成了我們數據技術中臺下一步建設的重點。
通過對各主流云廠商有關“湖倉一體”架構方案的深入研究與學習,我們逐步明確了自己的融合數據湖的建設思路:
一是在數據倉庫已經建設完善的前提下,數據湖可以作為數據倉庫的補充,位于數據倉庫的后端,主要用于卸載數據倉庫的部分重載,如歷史數據的存儲與查詢;
二是數據湖擴展其他場景下的數據探索與AI分析能力,原有數據倉庫對外服務保持不變,依然以整合層、集市層、應用層批處理任務加工和報表查詢等應用場景為主;
三是在邏輯層面,采用湖倉任務一體化開發、元數據統一管理以及聯邦查詢等技術將數據湖、數據倉庫與數據類服務連接成為一個整體,滿足用戶的一體化使用需求。
融合數據湖方案總體架構
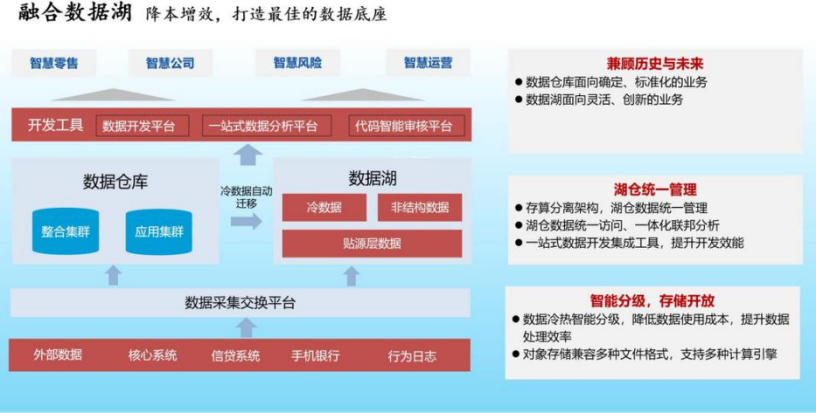
中原銀行融合數據湖方案:涵蓋了分布式存儲、大數據、數據倉庫等主流技術方案,通過構建湖倉與數據類服務的一體化方案,實現數據在其間按需高效流轉與統一管理,滿足全行不同業務條線的個性化多維度的數據統計分析需求。
融合數據湖方案具體技術架構
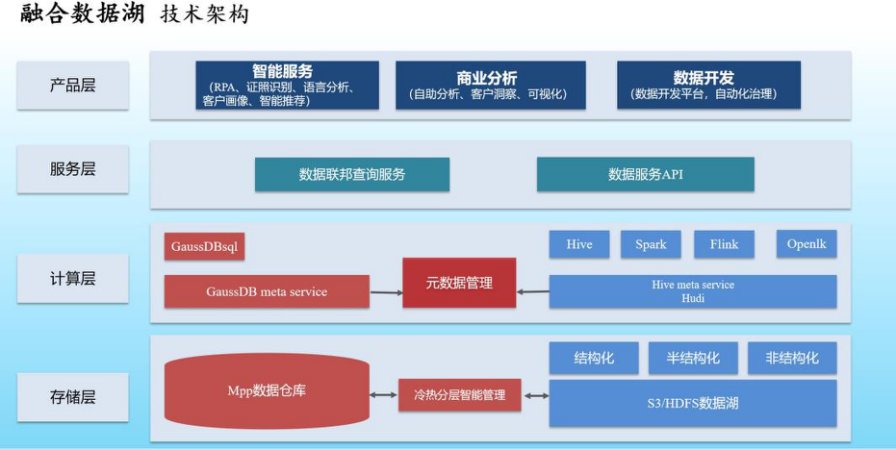
1.冷熱分層智能管理
(1)冷熱數據的定義
針對不同場景,用戶對數據的需求程度是存在差異的,高頻引用的數據,用戶對數據的加工時長以及高性能訪問往往要求嚴格;而低頻引用的數據,則沒有那么高的標準。
根據用戶對數據的使用頻次可以將存儲周期內的數據分為熱數據與冷數據。顧名思義,熱數據為用戶高頻引用的數據,包括跑批和頻繁使用的數據分析。冷數據則為低頻引用的數據,一般是歷史沉淀的業務數據,這類數據體量大,訪問頻度低,可以采用成本更低的存儲方式,而不是全都存放在數據倉庫中。
(2)冷熱數據存儲方案
具體而言,主流廠商的數據倉庫產品為追求高性能的查詢響應,一般采用存算一體的架構設計,通過控制與調度本地存儲,達到快速訪問的目標,雖然無法對存儲和計算資源進行單獨擴容,但有效保證了本地熱數據的計算與查詢性能。
數據湖在高擴展、低成本的基礎上,實現了計算和存儲分離,雖然犧牲了查詢效率,但能夠支持海量數據的存儲,因此非常適合分擔數據倉庫中冷數據的存儲壓力。
通過采用基于湖倉一體的冷熱數據分層存儲方案,可以有效降低數據的單位存儲成本。
(3)冷熱分層的挑戰
在基于湖倉一體的冷熱數據分層存儲方案實施過程中,我們遇到了一些問題與挑戰。
用戶對冷熱數據是有比較明確的業務定義,但數據倉庫在建表時并不能指定有關冷熱數據分層的參數,如何定義冷熱數據分層參數以及冷熱數據如何關聯冷熱存儲集群,是需要解決的首要問題。
(4)冷熱分層的解決方案

一站式數據開發平臺是中原銀行為數據開發人員提供的標準化、自動化、敏捷化的全流程數據開發工作坊。在數據建模板塊,我們為用戶提供了標準建表功能,可以根據用戶輸入的中文信息,自動匹配詞根并生成英文字段。同時支持用戶按照表的分類,配置不同的數據存儲策略。
平臺可以根據用戶建表時指定的數據存儲周期策略精確關聯業務上的冷熱數據和分層存儲中的冷熱數據存儲集群,采用智能化的調度策略,將冷數據自動從數據倉庫遷移至數據湖內,并在數據資產平臺端詳細展示數據分布情況,方便用戶查找。
當用戶需要使用湖中的冷數據進行重跑批時,平臺自動解析用戶在補數據模塊配置的表級依賴關系,并將用戶所需冷數據回流至數據倉庫,供重跑批使用,在緩存時間到期后由平臺再次自動遷移回數據湖。
2.異構數據統一元數據管理
數據湖通過開放底層文件存儲,給數據入湖帶來了極致的靈活性。進入數據湖的數據可以是結構化的文本,也可以是半結構化的網頁,甚至是完全非結構化的圖片。
為避免數據湖成為數據沼澤,我們對數據湖的上傳接口進行了定制開發:
● 強制用戶配置數據資產標簽,包括數據用途、數據生命周期以及所屬關系等內容;
● 針對結構化與半結構化數據,平臺可以基于特定的規則通過數據爬取功能自動識別并生成schema信息;
● 提供Hive MetaStore統一訪問層,方便數據湖計算引擎使用。
針對湖倉一體化的元數據管理,則是在一站式數據開發平臺的數據建模板塊落地實現的:
● 數據建模板塊提供了數據湖與數據倉庫的標準建表功能,用戶使用標準建表功能產生的元數據信息會統一注冊到數據建模板塊的元數據中心;
● 對于實現冷熱分層存儲的表,元數據中心則會根據用戶配置的存儲策略,精確關聯湖倉中的熱表信息與冷表信息,在邏輯層面將其作為一張表,并詳細展示這張表在數據倉庫中以及在數據湖中的表結構與日期范圍,方便用戶查看。
3.全域數據聯邦分析
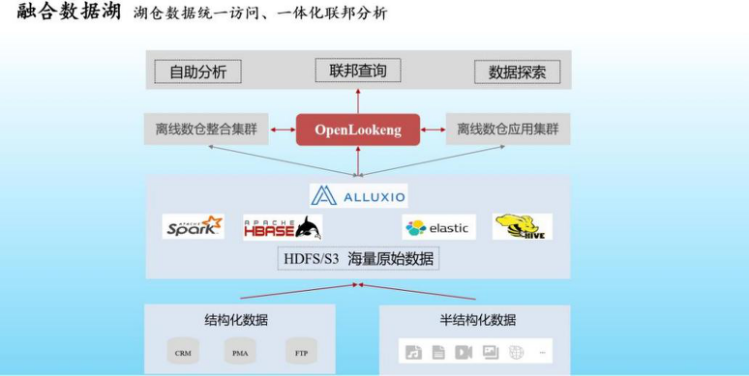
當一份數據按照冷熱分層策略,分別存儲到數據倉庫和數據湖后,如何實現跨湖倉的高效數據分析以及高性能的數據湖查詢,成為需要解決的另一個問題。
為此,通過對比分析主流開源的OLAP引擎,我們最終選擇Openlookeng作為全域數據聯邦查詢引擎。
一方面,Openlookeng在底層計算框架繼承了Presto的優勢,包括存算分離、全內存并行處理、索引能力、分布式流水線等,能夠實現高效的數據分析。另一方面,Openlookeng在高可用、緩存加速、動態catalog加載以及可擴展的連接器等方面做了加強,有效滿足了企業級場景應用的需求。
通過對接BI工具,用戶能夠輕松使用標準SQL直接分析湖倉中的數據,避免不必要的ETL。在使用過程中,結合具體應用場景,我們也對OpenLooKeng的部分功能進行了性能優化與二次開發。
(1)湖倉查詢性能優化
在實際湖倉聯邦查詢場景中,OpenLooKeng的查詢性并沒有達到預期,其主要原因是OpenLooKeng的connector端未實現GaussDB數據源的算子下推功能,導致源端所有數據直接加載到OpenLooKeng計算引擎側,造成嚴重的數據傳輸延遲。
通過參照OpenLooKeng源碼中已有其他數據源的算子下推方案,我們實現了GaussDB的算子下推與動態過濾功能,并以插件包形式通過SPI機制注冊到OpenLooKeng服務內。
同時為解決存算分離場景下,數據讀取本地性的問題,我們引入了開源數據編排技術組件Alluxio。通過將OpenLooKeng的worker節點和Alluxio的worker節點混合部署以及根據用戶對數據湖中數據的訪問頻次進行統計分析,提前將湖中頻繁訪問的數據預加載到Alluxio中,以此實現數據本地拉取的功能,在有效降低網絡傳輸IO的前提下,提高湖倉分析sql的執行效率。
(3)兼容GaussDB 函數和中文語法
GaussDB(DWS)作為行內主要的數據倉庫,數據工程師已經熟練掌握了其語法規則。引入Openlookeng后,雖然兩者均支持ANSI SQL2003語法,但對用戶在GaussDB中高頻使用的函數以及中文字段,Openlookeng是存在兼容性差異的。
為此在Openlookeng引擎端,我們以plugin形式新增了函數插件包,擴展了to_date、instr、to_char的使用場景。對于decode、nvl這類多參數函數,通過對源代碼中的動態字節碼生成函數方案進行優化,擴展了不同參數的生成策略,滿足了參數類型和返回值類型不確定的使用場景。
針對Openlookeng不支持中文字段的問題,我們則是通過對源碼中antlr4定義的語法規則進行重構,在SqlBase.g4文件中擴展identifier,定義中文匹配規則,支持了中文的詞法匹配。
4.湖倉一站式數據開發與管理
在數據開發方面:我們自主研發了支持湖倉一體架構的數據開發與調度平臺,在執行引擎端實現基于多租戶的敏捷任務管理,無需人工干預由平臺自動根據任務類型下發任務到數據倉庫和數據湖中執行。同時依托于智能SQL解析服務,可以對湖倉任務SQL代碼進行掃描,按照相應的規則進行匹配,檢出質量隱患。
目前中原銀行自研的數據任務調度引擎,支持萬級別任務的復雜調度與全局依賴管理,支持豐富的調度參數,充分滿足用戶開發過程中的各類需求。
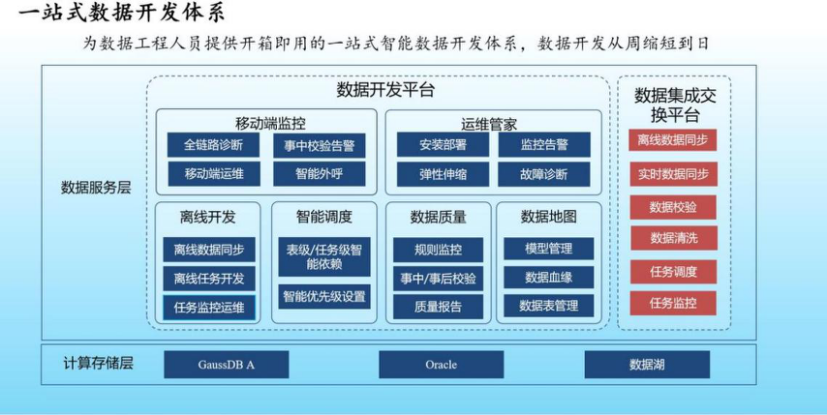
在數據集成與交換方面:平臺配置簡單靈活,無需編碼,Source和Sink端支持豐富的外部數據源,包括ES、HBase、StarRocks、Oracle、GaussDB等;針對相同的數據源表平臺采用一卸多裝的策略,避免資源重復占用,通過建立資源動態分配機制,實現資源細粒度管控。同時平臺采用Spark作為底層分布式執行引擎,支持多源異構數據高效入湖,將湖、倉與專門構建的數據服務有機的連接成為一個整體。
在數據分析方面:我們建設完成一站式數據分析平臺,集合固定報表、交互式分析、客戶洞察、可視化大屏、數據資產地圖、數據創新社區于一體,為業務人員提供搜索、文檔、批注等功能的一站式解決方案。平臺集成數據湖查詢服務,為用戶提供高效便捷的數據湖查詢、跨湖和倉的聯邦分析能力。用戶能夠輕松使用標準SQL直接分析數據湖中的數據。
融合數據湖方案應用成效
融合數據湖方案從2021年年初開始建設到最終落地,歷時1年左右時間。目前整體方案已在行內應用,并取得一定效果。
成本節約:融合數據湖方案支持多類型數據管理,PB級海量數據存儲,數據湖分析與計算服務。通過采用湖倉一體的數據智能分層存儲策略,有效降低行內數據單位存儲成本20%以上。同時也與行內模型管理平臺、反欺詐平臺完成對接,支撐了各類平臺對圖片數據的存儲與使用需求。
效率提升:通過Openlookeng提供的湖倉協同分析能力,在保持現有數倉業務模型和數據分析人員使用習慣的前提下,有效避免不必要的ETL,減少50%以上的數據搬遷,同時基于算子下推、元數據緩存、數據緩存等技術,支持數據湖查詢秒級響應。
開發管理:通過構建湖倉與數據類服務的一體化方案,實現數據高效自由流轉與統一管理,支持湖倉任務的協同開發與調度,為全行60多個項目組提供穩定高效的數據開發服務。截至目前,已累計承接行內2萬余個數據集成與交換任務,3萬余個跑批任務,每月完成20多萬sql代碼質量審核。
