應急響應之Linux 守護進程 | 內附應急手冊
最近被安排做一些應急響應的工作,所以學習了一下Linux進程相關的知識,越學越多,那就記下來吧!
應急響應手冊 V1.3版本:
https://pan.baidu.com/s/1O5qMHs14K94LGagjX_L8aA
提取碼: b6e7
在Linux中:
- 打開terminal,也就是終端程序,之后可以獲得一個shell
- 通過ssh連接到linux的ssh-server 服務器,也可以獲得一個shell
通常我們都是通過以上兩種方式來獲得一個shell,之后運行程序的,此時我需要糾正一個概念,我們通常都說獲得一個shell,本質上來說,我們獲取了一個session(會話,以下session都是會話)

拿兩種常見情況進行舉例
案例1
我們輸入
ping www.baidu.com
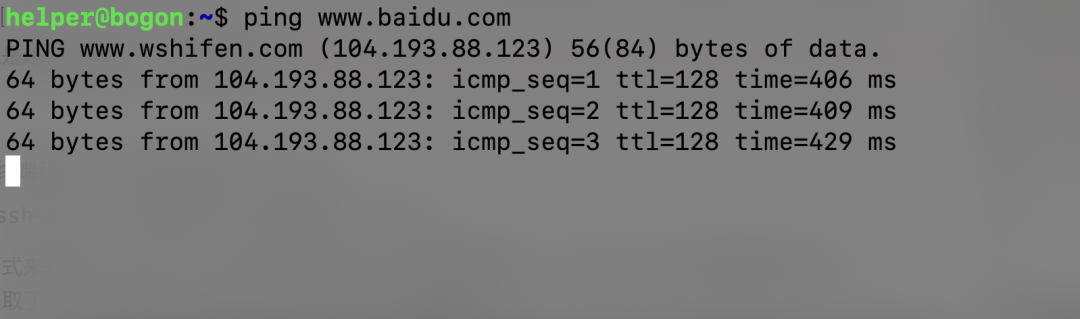
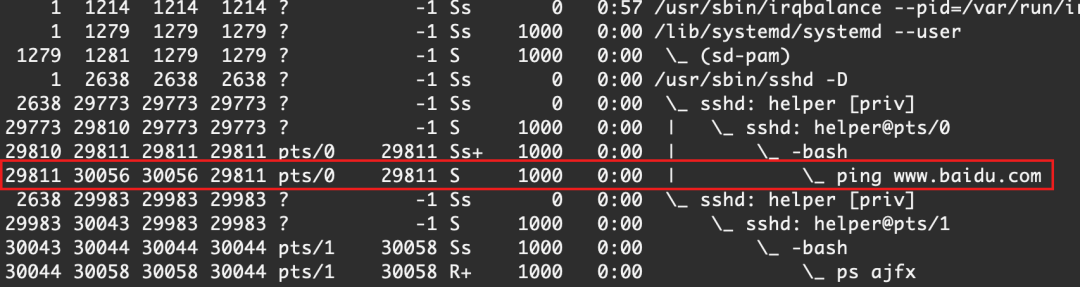
大家都知道,此時我們啟動了一個程序 ping ,并且創建了一個進程,我們再開一個終端ssh連接這個服務器看一下

可以看到,我們起了一個PID為1779的進程,進程在不斷向我們打印ping的結果,那么本質上來講是什么樣的呢?
我們使用 ps ajfx 來看一下

- pid,pgid,sid均為890的 sshd 守護進程生成一個SID為1494的session,同時創建了一個pid為1494的子進程“sshd: helper [priv]” ,并且創建了一個進程組,此進程就是進程組的leader,進程組的PGID等于此進程的pid 1494,這個進程就是該session的leader
- “sshd: helper [priv]”創建了一個PID為1518子進程 “sshd: helper@pts/2” ,其實就是開了一個虛擬終端 pts
- 虛擬終端pts生成了一個SID為1519的session,創建了一個pid為1519的子進程 “bash”,并且創建了一個新的進程組,新進程組的PGID等于新的子進程的PID為1519,這個子進程為進程組的leader,也是這個session的leader。
- bash創建了一個pid為1779的子進程 “ping www.baidu.com”,同時創建一個新的進程組,PGID為1779,并且這是一個前臺進程
案例2
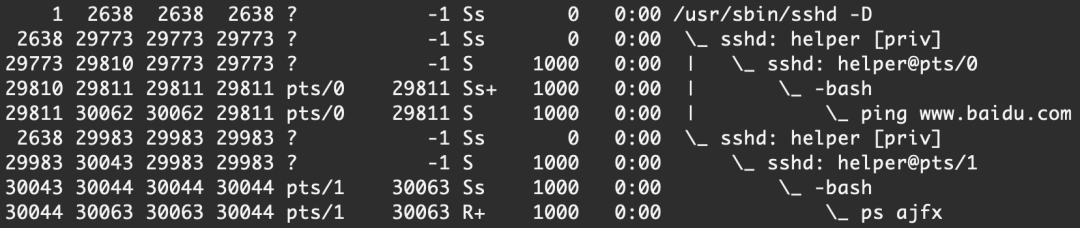
我們輸入
ping www.baidu.com &
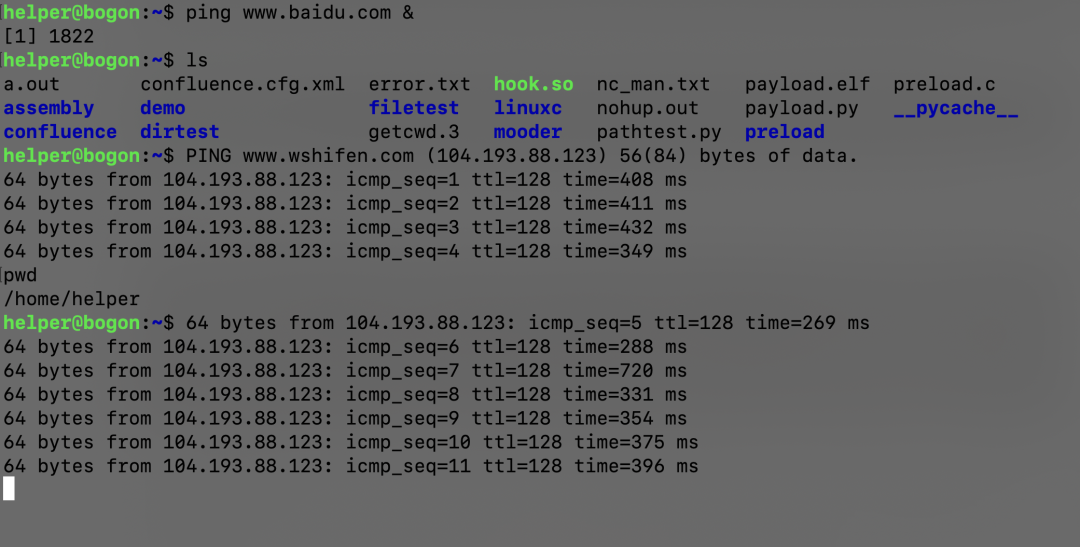
可以看到,ping百度 這個操作的“交互”已經放到后臺了,但是依舊像終端輸出,我們可以正常輸入命令ls,pwd等,執行返回也都正常
ps ajfx

同樣的過程就不重復了,不一樣的地方在于


這里是 ps 命令的 STAT 列,具體字符含義如下
- D 不能中斷的進程(通常為IO)
- R 正在運行中的進程
- S 已經中斷的進程,通常情況下,系統中大部分進程都是這個狀態
- T 已經停止或者暫停的進程,如果我們正在運行一個命令,比如說sleep 10,如果我們按一下ctrl -z 讓他暫停,那我們用ps查看就會顯示T這個狀態
- W 這個好像是說,從內核2.6xx 以后,表示為沒有足夠的內存頁分配
- X 已經死掉的進程(這個好像從來不會出現)
- Z 僵尸進程,殺不掉,打不死的垃圾進程,占系統一小點資源,不過沒有關系。如果太多,就有問題了。一般不會出現。
下面一些是BSD風格的參數
- < 高優先級進程
- N 低優先級進程
- L 在內存中被鎖了內存分頁
- s 主進程
- l 多線程進程
- + 代表在前臺運行的進程
可以看出
- 執行 ping www.baidu.com 的時候ping是前臺運行的進程, bash是后臺運行的進程
- 執行 ping www.baidu.com & 的時候ping是后臺運行的進程, bash是前臺運行的進程
如果上面涉及的所有概念你都能清晰的理解,那么下面的內容你也可以看一看,畢竟來都來了...
進程組
進程的概念大家都能理解的話,進程組就很好說了,其實就是一堆進程捆一起了,之后形成一個組就叫進程組了
這么做肯定是有意義的,不然Linux也不會這么搞,主要還是為了方便管理。
公司為了方便管理,給人分組,方便分配工作;社會為了方便管理,給人區分成年人,未成年人,老人;我們又因為愛好,信念等被分成了各種各樣的小組...
系統把同一個job(作業)的進程分成一個組,既然有組織肯定得有組長,組的ID(PGID)就采用組長的PID
這里有一個問題,如果組長進程死亡了,小組還存在嗎?如果存在組長歸誰?
如果組長進程死亡了,小組只要還剩下進程就會存在,此時組長不會變,PGID也不會變;就像紀念一樣...
實驗一下:
#include
#include
int main()
{
setbuf(stdout, NULL);
pid_t pid;
pid = fork();
if(pid == 0){
printf("child pid: %d", getpid());
while(1){
sleep(1);
printf("child");
}
} else {
printf("father pid %d", getpid());
while(1){
sleep(1);
printf("father");
}
}
}
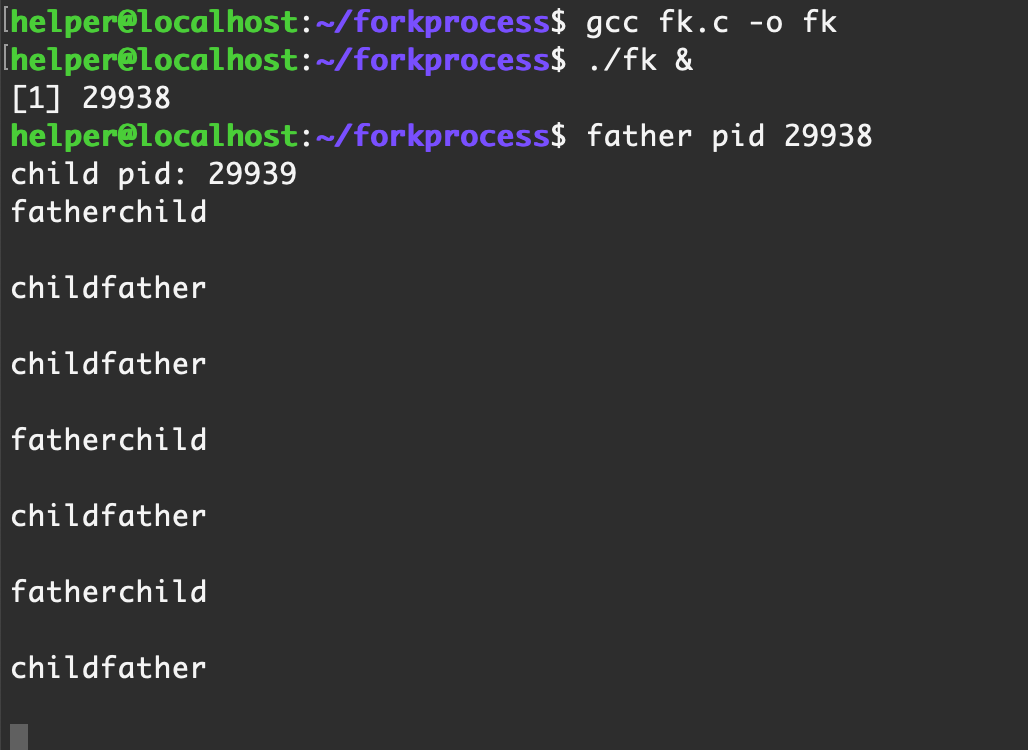
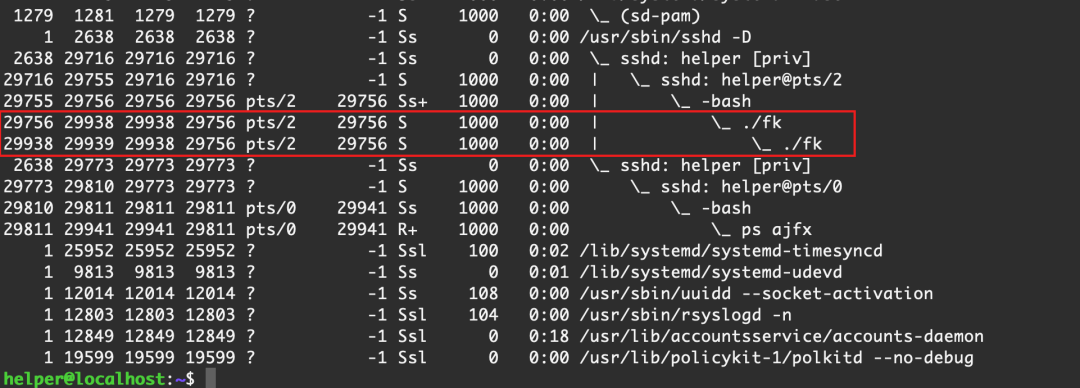
從ps的結果可以看到,我們的程序創建了兩個進程,兩個進程屬于同一個進程組,PGID為29938
現在我們kill 掉進程組leader 29938
kill -9 29938


當我們kill掉進程leader之后,立馬father就不打印了,但是child依舊在打印,這說明父進程被殺死,子進程還活著,接下來看看子進程活得怎么樣
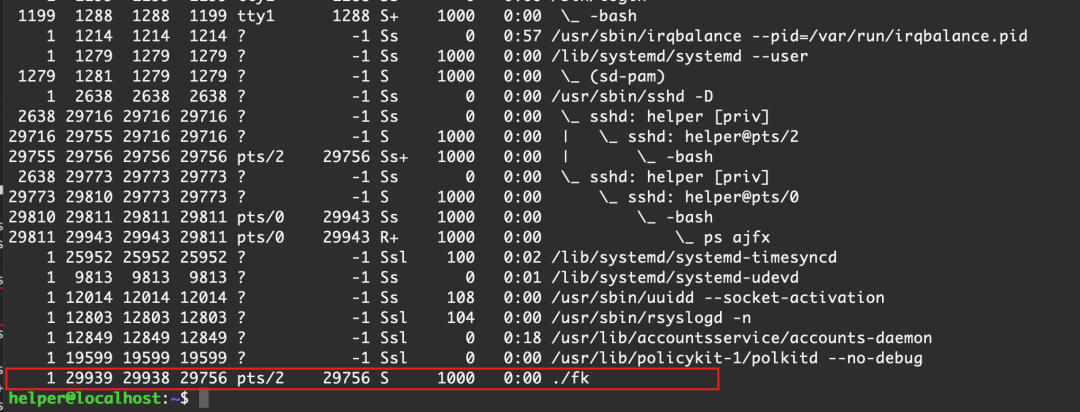
好家伙,父進程被殺死后,子進程直接把PPID設置為1,但是進程組PGID依舊沒變,還是29938 ,session的id SID也沒有發生變化,還是29756
此時這個子進程被稱為孤兒進程
這里我們就需要注意了,一個木馬或者后門如果主進程還存在子進程,僅僅 kill -9 pid 殺死主進程可能是沒用的,因為不會殺死子進程
問題來了,如果我想把這些木馬病毒進程都干掉,怎么操作?
我見過各種騷操作,有的是寫腳本,有的是手動挨個殺,用killall、pkill等等,這種回復一看就是沒遇到那種進程pid,進程名稱一直變化的
其實非常簡單,我們只需要把這個進程組給殺死就好了
kill -9 -PGID
沒有看錯,其實就是在 PGID前面加個減號
實驗開始:
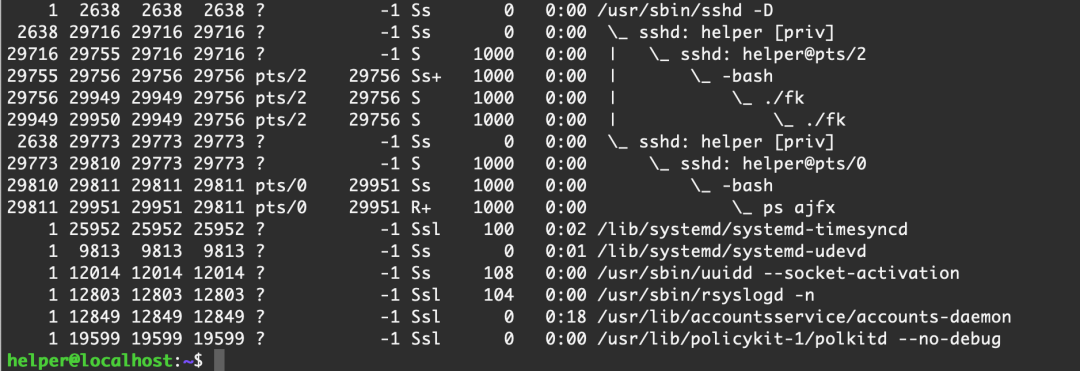
可以看到,父子進程都起來了,pid分別為29949和29950
這個時候我們殺掉這個進程組
kill -9 -29949

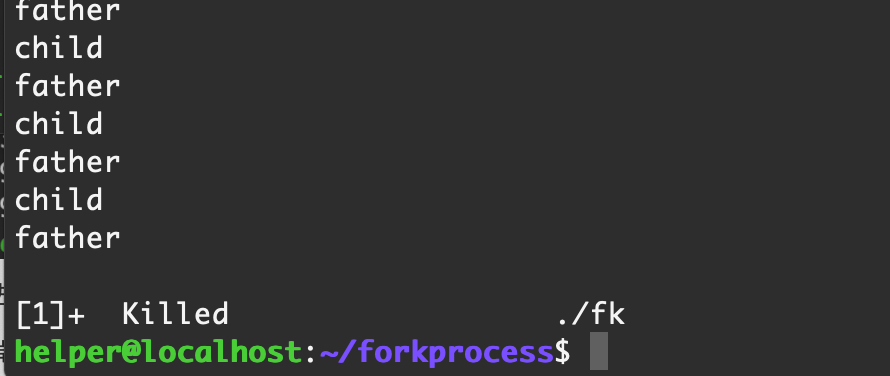
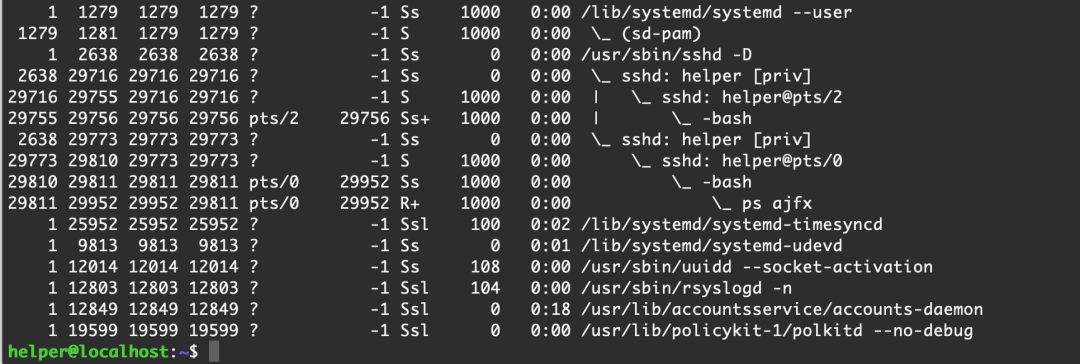
可以看到,這個進程組已經沒有了,渣都不剩!
這里一定要注意,你殺的是一個進程組,一定要注意,進程組里是否有正常業務進程,別殺錯了
Session
其實文章開頭我們已經簡單提到過了,我們一般討論的都是shell session,我們打開一個新的終端就會創建一個session,每個session都是由一個或者多個進程組組成的,每個進程組稱為 job,這里job不是任務,而叫作業
從描述中可以看出,session管理的范圍要比進程組大,打開一個終端,你執行100條命令,只要沒有新的session生成(調用 setsid()函數可以生成新的session ),那么這些命令可以通過session進行統一管理,當然最常見的管理方式還是全部殺死,但是這個殺傷力太大了,所以一般不使用,主要還是了解session的概念,從web安全過來對于session這種機制應該很容易理解。
session中的第一個進程(一般是bash)的PID就是session的SID
現在大招來了,如何干掉整個session呢?
pkill -s SID
實驗開始
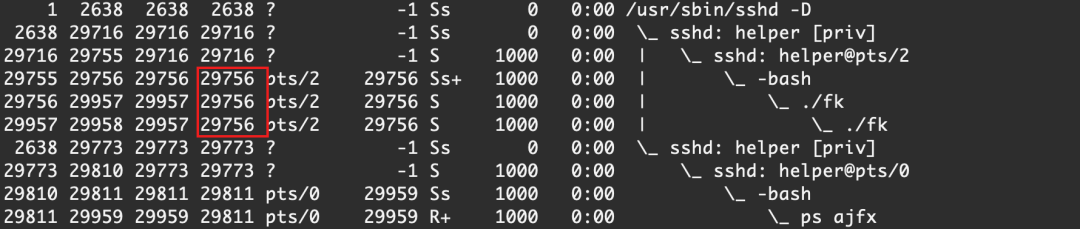
可以看到,fk的SID為29756
pkill -e -s 29756
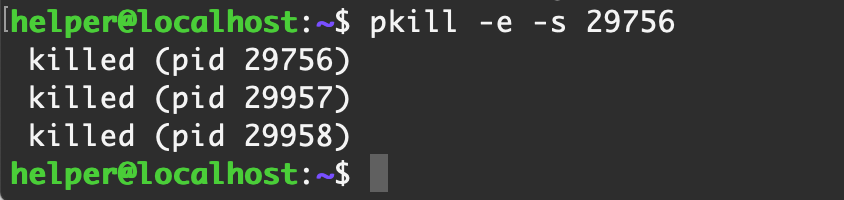
可以看到,殺掉了這個SID下的三個進程,分別為 29756, 29957, 29958
-e 參數是現實殺掉了誰,多人性化
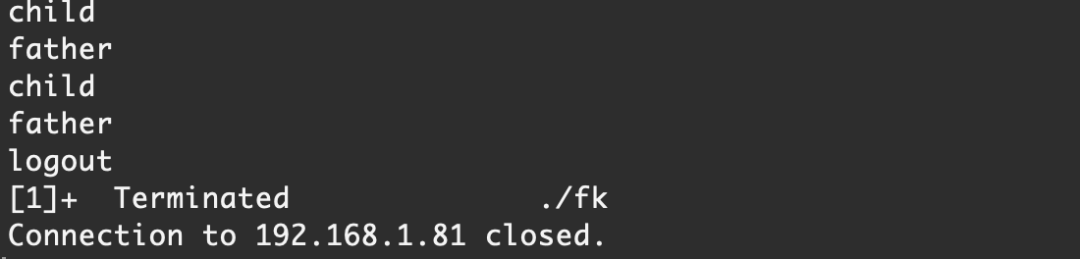
可以看到,殺掉了bash進程后,ssh鏈接就斷開了
守護進程(daemon)
守護進程這個詞經常聽到,名字還挺溫暖,遺憾的是總是在處理linux挖礦病毒的案例中聽到,簡直破壞美感
守護進程的一個特點就是進程不受任何終端控制
不受任何終端控制這個定義似乎有些模糊,所以我試圖去找到一些限定條件,大部分人是這樣說的:
- 隨系統啟動而啟動
- 父進程是init,也就是ppid為1
- 在后臺運行
- 進程名字通常以字母 d 結束
- ps顯示中終端名設置為問號(?),終端前臺進程組ID設置為-1
- 工作目錄為 \ (根)
這其中很明顯不完全準確,但是也都是基于實際情況分析出來的,所以我一直在糾結后臺進程、nohup起的后臺進程和守護進程是什么關系,直到遇到了這篇文章,我覺得才是說的比較透徹的
https://www.cnblogs.com/lvyahui/p/7389554.html
我直接摘過來:
- 沒有控制終端,終端名設置為?號:也就意味著沒有 stdin 0 、stdout 1、stderr 2
- 父進程不是用戶創建的進程,init進程或者systemd(pid=1)以及用戶人為啟動的用戶層進程一般以pid=1的進程為父進程,而以kthreadd內核進程創建的守護進程以kthreadd為父進程
- 守護進程一般是會話首進程、組長進程。
- 工作目錄為/(根),主要是為了防止占用磁盤導致無法卸載磁盤
守護進程在后臺默默提供著服務,但是不接受任何終端的管控,沒有標準輸入、標準輸出、標準錯誤,比較典型的有mysqld, sshd等,當然我們也是可以創建一個守護進程的,步驟如下:
直接摘抄吧:
執行一個fork(),之后父進程退出,子進程繼續執行。(結果就是daemon成為了init進程的子進程。)之所以要做這一步是因為下面兩個原因:
- 假設daemon是從命令行啟動的,父進程的終止會被shell發現,shell在發現之后會顯示出另一個shell提示符并讓子進程繼續在后臺運行。
- 子進程被確保不會稱為一個進程組組長進程,因為它從其父進程那里繼承了進程組ID并且擁有了自己的唯一的進程ID,而這個進程ID與繼承而來的進程組ID是不同的,這樣才能夠成功地執行下面一個步驟。
子進程調用setsid()開啟一個新回話并釋放它與控制終端之間的所有關聯關系。結果就是使子進程: (a)成為新會話的首進程,(b)成為一個新進程組的組長進程,(c)沒有控制終端。- 如果daemon從來沒有打開過終端設備,那么就無需擔心daemon會重新請求一個控制終端了。如果daemon后面可能會打開一個終端設備,那么必須要采取措施來確保這個設備不會成為控制終端。這可以通過下面兩種方式實現:
- 在所有可能應用到一個終端設備上的open()調用中指定O_NOCTTY標記。
- 或者更簡單地說,
在setsid()調用之后執行第二個fork(),然后再次讓父進程退出并讓孫子進程繼續執行。這樣就確保了子進程不會成為會話組長,因此根據System V中獲取終端的規則,進程永遠不會重新請求一個控制終端。(多一個fork()調用不會帶來任何壞處。)
清除進程的umask以確保當daemon創建文件和目錄時擁有所需的權限。修改進程的當前工作目錄,通常會改為根目錄(/)。這樣做是有必要的,因為daemon通常會一直運行直至系統關閉為止。如果daemon的當前工作目錄為不包含/的文件系統,那么就無法卸載該文件系統。或者daemon可以將工作目錄改為完成任務時所在的目錄或在配置文件中定義一個目錄,只要包含這個目錄的文件系統永遠不會被卸載即可。關閉daemon從其父進程繼承而來的所有打開著的文件描述符。(daemon可能需要保持繼承而來的文件描述的打開狀態,因此這一步是可選的或者可變更的。)之所以這樣做的原因有很多。由于daemon失去了控制終端并且是在后臺運行的,因此讓daemon保持文件描述符0(標準輸入)、1(標準輸出)和2(標準錯誤)的打開狀態毫無意義,因為它們指向的就是控制終端。此外,無法卸載長時間運行的daemon打開的文件所在的文件系統。因此,通常的做法是關閉所有無用的打開著的文件描述符,因為文件描述符是一種有限的資源。在關閉了文件描述符0、1和2之后,daemon通常會打開/dev/null并使用dup2()(或類似的函數)使所有這些描述符指向這個設備。之所以要這樣做是因為下面兩個原因:
- 它確保了當daemon調用了在這些描述符上執行I/O的庫函數時不會出乎意料地失敗。
- 它防止了daemon后面使用描述符1或2打開一個文件的情況,因為庫函數會將這些描述符當做標準輸出和標準錯誤來寫入數據(進而破壞了原有的數據)。
說了這么多,還是那一個實際的守護進程出來看一下吧,以sshd為例
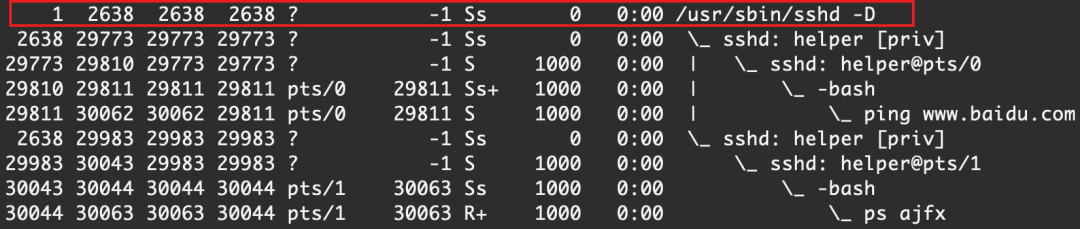
因為守護進程PPID為1,而且是在單獨的進程組、單獨的session中,所以PID=PGID=SID,同時終端處值為 ? , 終端前臺進程組ID設置為-1
殺死守護進程沒啥特別的,該殺殺,當然前提是權限要夠
看到這里已經可以了,基本上知識點都接觸到了,下面是我在關于進程相關知識學習過程中思考的一些問題,不解決不舒服那種,無聊的可以看一看
dies und das
1. ping www.baidu.com & 這種后臺進程是不是守護進程
不是
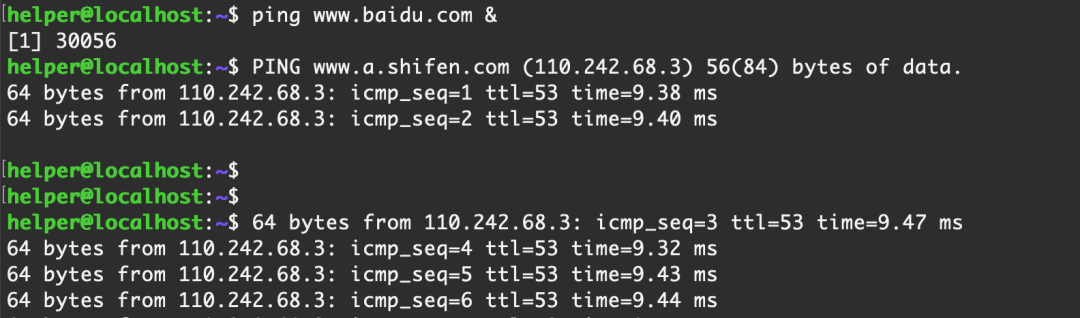
存在標準輸出和標準錯誤
2. nohup ping www.baidu.com &
不是

還是存在標準輸出,只不過是重定向到 nohup.out中了
3. ping www.baidu.com > /dev/null 2>&1 & 更像是守護進程了嗎
更像了,但還不是

這種形式確實是不在存在標準輸出,標準輸出,標準錯誤,但是PPID還不是1
4. 不就是PPID=1嗎?上代碼
#include
#include
int main()
{
setbuf(stdout, NULL);
pid_t pid;
pid = fork();
if(pid == 0){
system("ping www.baidu.com > /dev/null 2>&1 &");
} else {
exit(0);
}
}
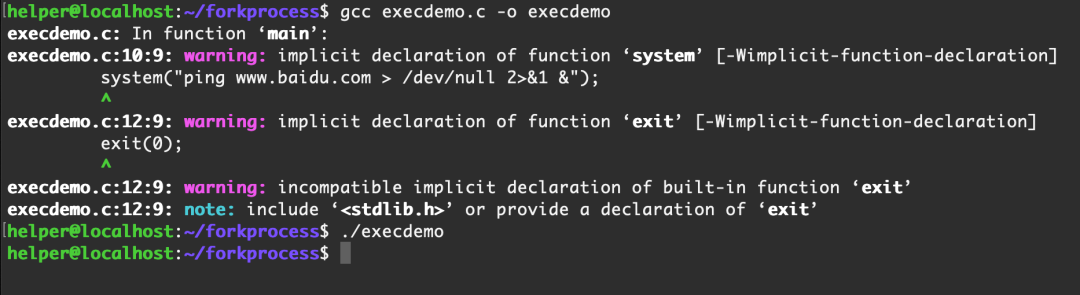
- 無標準輸入、無標準輸出、無標準錯誤
- ppid=1
現在更像是守護進程了,但是PID,PGID,SID還是不相等,終端處值不為 ? , 終端前臺進程組ID也不是-1,目錄也不是根目錄,換句話說還是受到終端的控制。
具體創建一個守護進程的代碼網上有的是,自己搜索吧,既有直接使用daemon()函數生成的,也有一步一步按照上面描述去生成的,推薦先看看后者。
5. 我們ssh斷開鏈接后session還在嗎?
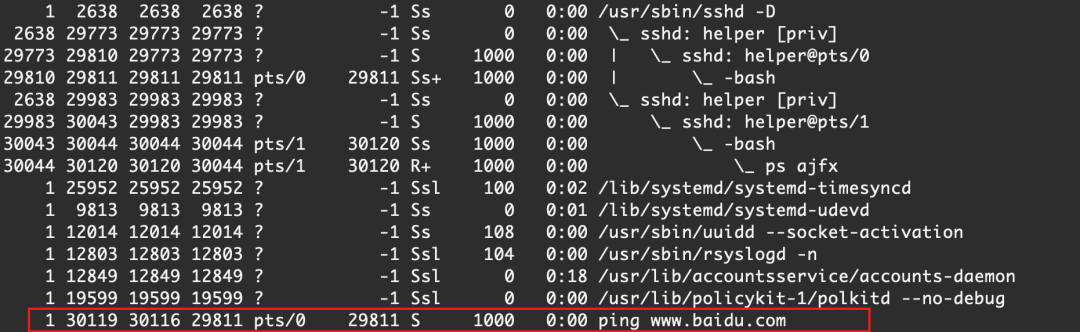
我使用兩個終端連接同一個服務器的ssh

可以看到,現在有兩個SID,我們使用 1682 這個session來進行執行ping www.baidu.com之后ctrl+c 中斷,exit退出連接

我們使用1731的shell來查看

SID為1682的session不存在了,ping 的命令也被我們中斷了
現在我們還是使用兩個終端連接ssh

我們使用 1788的shell來執行
ping www.baidu.com & 之后exit退出ssh連接
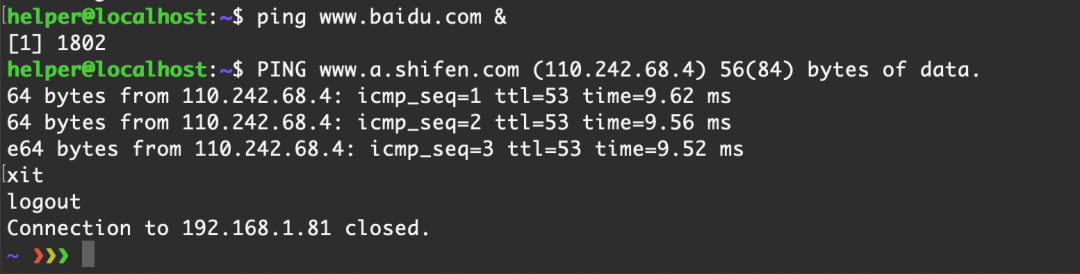

從這里可以看到,雖然我們把ssh連接退出了,但是后臺進行依舊在這個session上執行,還屬于這個會話,所以如果session存在還在執行的后臺進程,即使關閉終端或者斷開ssh等遠程連接,session還是會存在的
6. nohup 命令意義難道僅僅就是將標準輸出,標準錯誤重定向到 nohup.out 嗎?
如果僅僅是輸出重定向,我們可以直接使用 > ,為什么會有nohup命令呢?沒有點啥重要作用也對不起這個名字呀!
其實呢,產生這個疑問的主要就是因為問題5我們僅僅從表面現象就得出了結論,而沒有進行本質上的剖析,所以如果只看到問題5的哥們兒可能要被誤導了...
當一個終端關閉或者ssh等遠程連接退出的時候,系統會向session管理的所有進程發送一個SIGHUP信號,這個信號就是掛斷的意思,效果就是進程中斷,理論上問題5中 ping www.baidu.com 這個后臺進程也應該能夠收到,但是,在session要斷開這種情況是否給屬于session的后臺進程發送SIGHUP信號是受系統一個配置參數控制的——huponexit ,一般情況下,這個參數的缺省是off,在這種配置下,關閉終端后臺進程不會收到SIGHUP信號。
shopt | grep huponexit

可以看到,在當前系統中,該參數為off,所以才會出現終端關閉或者ssh等遠程連接斷開的時候,后臺進程能夠繼續以這個session運行
此時再說 nohup 應該就很清晰了,nohup其實就是忽略SIGHUP信號,這樣保證我們的程序在后臺平穩執行
7. tmux 后臺執行的效果更好,tmux的底層原理是什么呢?
還是使用兩個終端來進行


ctrl b+d tmux ls

我們使用另一個終端觀察一下:
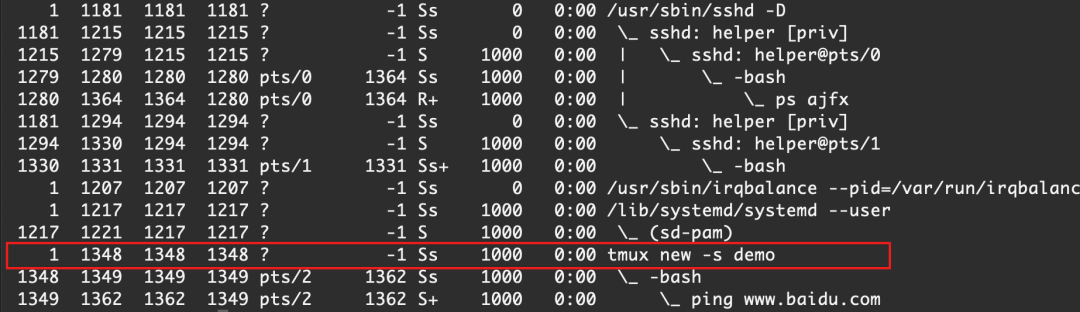
可以看到,其實tmux創建了一個守護進程,進程PID=1348,之后通過守護進程創建 bash,之后通過bash執行ping,創建ping www.baidu.com
為了更加嚴謹證實這個觀點,我們再創建一個tmux任務


現在是ping百度和新浪同時跑著,再觀察一下

中間STAT為Zs的進程是因為我忘了截圖,就退出了重新來導致的,不用關注
可以看到的是,對于每一個任務,tmux都會創建一個新的session、進程組、進程,這樣實現多個進程之間互不影響
至此,關于Linux的進程相關知識應該將明白了,如果想從更加底層去分析,就去學習學習C和匯編吧!
