基于多模態學習的視覺實體鏈接
Introduction
現有的視覺場景理解方法主要側重于粗粒度識別視覺對象以及他們之間的關系,而忽略了細粒度場景理解。事實上,例如新聞閱讀和網上購物等場景下,都存在細粒度識別出圖片中的元素為實體的需求。為此,這篇文章提出了一項新的研究任務:用于細粒度場景理解的可視化實體鏈接。首先從不同的模態中提取候選實體特征,然后設計了一個基于深度模態注意力神經網絡的學習排名方法,將所有的特征聚合起來,將視覺對象映射到知識圖譜中的實體。實驗表明,與baseline對比,這一方法的準確率從66%提高到了83%。
Method
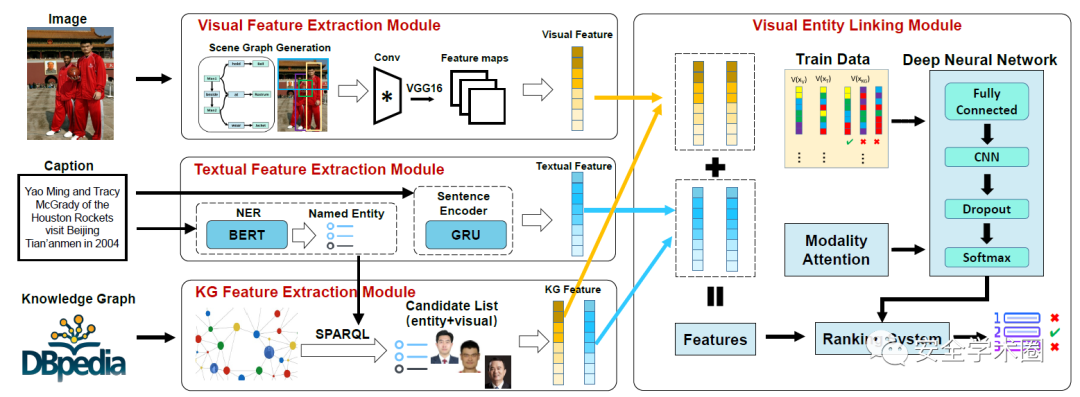
論文方法的整體框架圖如圖所示,由特征提取模塊和視覺實體鏈接兩個模塊組成。
圖像數據的處理是首先生成一個粗粒度的場景圖,再通過VGG-16網絡來提取圖像中物體的視覺特征。圖像的描述文本一方面會通過GRU網絡,提取物體的文本特征,另一方面會通過基于BERT的方法進行命名實體識別,并通過實體名在通用知識庫中搜索出候選的實體。分別獲得視覺特征、文本特征和知識圖譜特征后,利用提出的基于深度模態注意力神經網絡的學習排名方法(deep modal-attention neural network-based learning-to-rank method),匯總所有的特征并將視覺對象映射到知識圖譜中的實體。
Experiments
Datasets
目前計算機視覺數據集基本上沒有命名實體的數據,因此論文作者建立了VELD(Visual Entity Linking Dataset)數據集,由39k個左右的新聞圖片和文字說明對組成,并且全部經過人工標注和篩選,確保圖片說明文字中含有相關的命名實體。
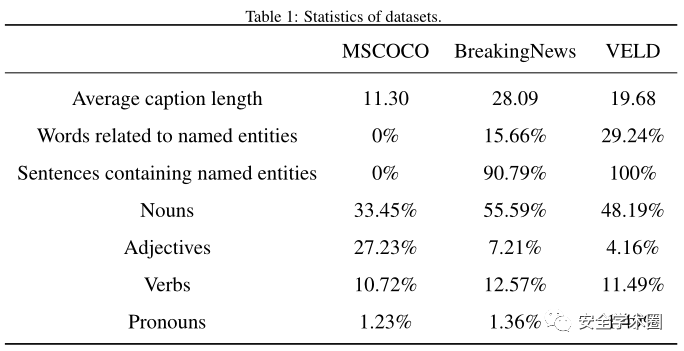 VELD數據集與MSCOCO和BreakingNews的比較
VELD數據集與MSCOCO和BreakingNews的比較
Tasks
給定一個圖像的邊界框和相應的說明文字,目標是將圖像邊界框與DBpedia知識庫中相應的實體進行鏈接。
Results
作者提出的研究任務相對較新,用于比較的模型比較有限。下表是作者選擇的對于實體鏈接和視覺對象識別目前最常見的幾種方法進行的對比實驗結果,T表示文本模態、V表示視覺模態、KG表示知識圖譜模態。
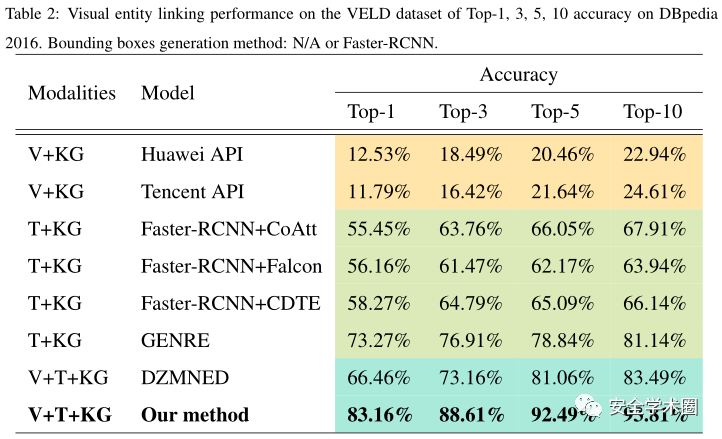
前兩個模型使用了視覺模態和知識圖譜模態信息,結果表明這類靜態離線訓練的深度神經網絡不能很好地完成視覺實體鏈接的任務,接下來的四個文本模態+知識圖譜模態的模型得到的結果也與作者的模型有較大差距。即使是與類似的多模態學習模型DZMNED對比,作者的模型依然有非常顯著的優勢。原因在于作者的模型是對于三種模態特征的融合,而不僅是簡單的基于模態的連接。

上圖是模態融合的一個例子,在不同情況下不同的模態有著不同的權重,顏色越深則權重越大。以第一行為例,首先生成了Jobs,Apple,iPhone的候選實體列表。在對Jobs進行鏈接的過程中,可以看到視覺模態的權重要更大,因為從文本上看Jobs這一名字可能對應了很多個人;而對于Apple和iPhone兩個實體來說,視覺模態的權重則比文本低得多,因為僅依靠文本就可以很容易地找到與上下文語義相對應的知識圖譜實體。
