如何更高效的玩兒 nday 漏洞
最近又重新收集了一波 src 的信息,整理了上百萬的網站資產,主要步驟:
可能大家都知道互聯網上存在的漏洞中,nday 漏洞占比很可觀,那么針對上百萬的網站如何更快,更有效的從中挖掘 nday 漏洞呢?
有的人可能會說,poc 工具一把梭就可以了,比如 nuclei、xray、goby 等一鍵掃描,這種是最直接,最方便的打法,但是如果針對的是單個網站,或者幾個網站,一把梭下來也要不了多久,但是針對上百萬的資產,這么操作下來估計得個一年半載。
又有人說了,時間長,你不會采用分布式的打法嗎?一臺掃描器需要一年,你用十二臺不就之需要一個月了嗎?這種方式對于實現目標而言當然是可以的,但是對于服務器的操作和管理成本比較,服務器的租用成本與上一種一樣,但是我很窮,有沒有時間更短,服務器成本更低的方法?
poc 越多,對于單個網站的測試時間越長,比如 xray 高級版自帶近 800 個 POC,nuclei 有三千個,上百萬的網站,這么測試下來,以 xray 為例,需要 800 個一百萬,以每秒 100 次的請求計算,大概需要三個月,如果測試的速度再慢點,時間會更長。
在這個測試中,其實有大量的測試是無效的,因為 poc 測試之有針對對應的系統才有效果,如果系統類型不對,則測試的過程無效,那么我們可以基于要測試的系統進行指紋識別,然后針對要測試的 POC 進行分類,這樣精細化的測試,可以大大節約測試的時間,效果上面也不會太差。
0x01 基于 POC 定制指紋庫
我的第一個操作是,基于 poc 所對應的系統進行整理,并提取相關指紋,然后獲取這百萬網站的 header、首頁內容作為基礎數據,然后進行指紋識別,找出那些 poc 所針對的系統目標。
對于以上操作,需要解決兩個難點:
1、指紋提取
我的做法是,首先去 fofa(指紋識別能力還不錯) 上搜索,找到一個在線案例,然后通過觀察其 header 信息、body 內容、標題等關鍵點,提取與該系統相關的信息作為其識別的特征,比如:
以標題為特征:
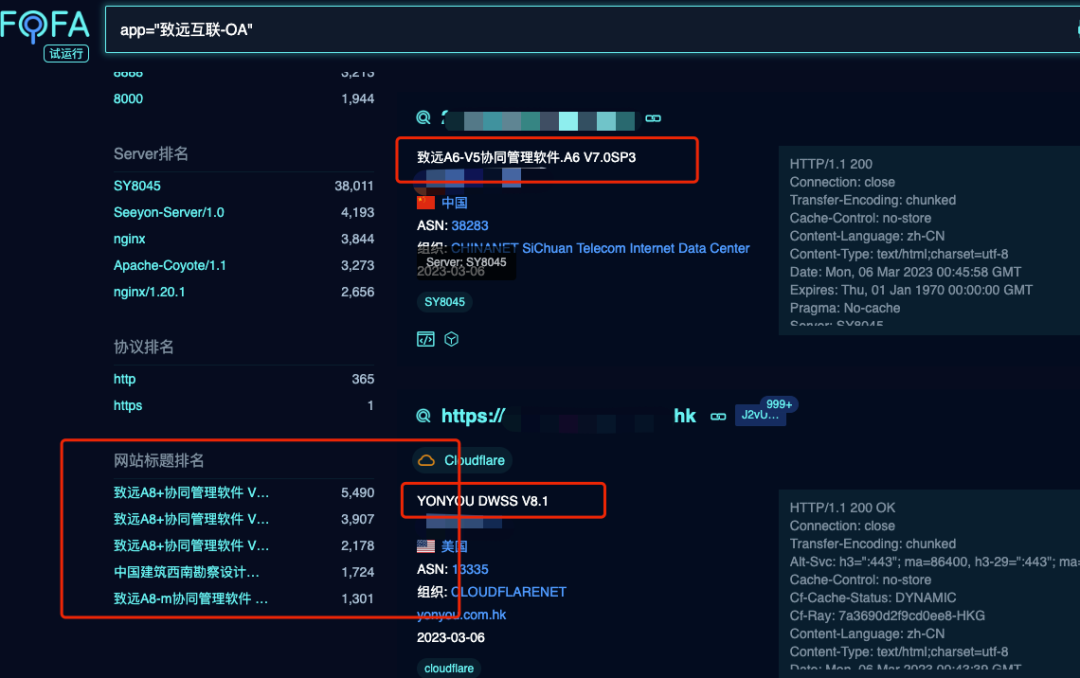
以 header 為特征:
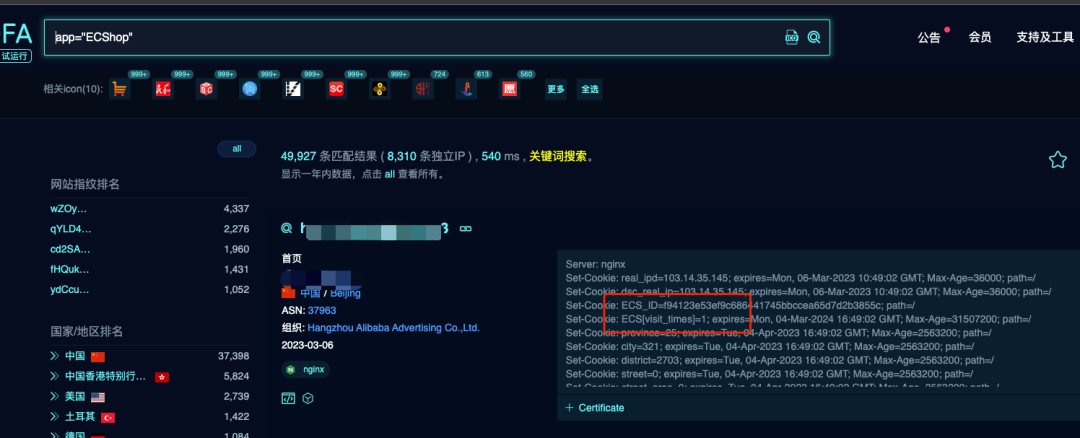
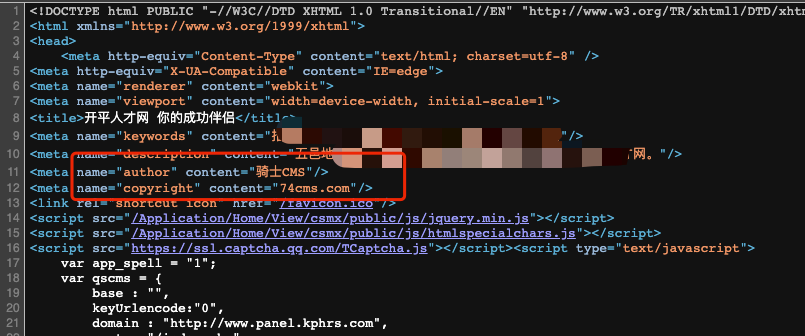
以 body 內容關鍵詞為特征:
基于以上三個部分的特征可以識別大部分的系統,這種系統主要為商業、開源的系統,客戶不做二次開發,直接拿來用的,除了這些系統,還有大量框架、組建、服務器之類的,無法很好的進行指紋識別,這類 poc,我會將其作為通用 poc,針對全部系統進行測試,以免因為指紋識別結果漏報而無法全面發現漏洞。
2、指紋規則與 poc 命名聯動
編寫指紋規則時,我們想要讓規則識別出的系統與其對應的 POC 聯動,那么就需要在命名上與 poc 的命名保持一致,比如 xray 中關于 wordpree 的 poc 命名如下:
那么我們就需要編寫一個可以產品名為 wordpress 的指紋規則,如圖:

那么在指紋識別結束后,就能知道那些系統是使用 wordpress 系統搭建,這個時候就可以使用其對應的 poc 列表進行測試。
0x02 基于指紋識別結果進行 POC 測試
經過第一步的操作,基于 xray 提供的 poc 列表,定制了一份包含 247 個系統的指紋庫,對于那些針對開發框架、服務器、通用組件測試的 POC 提取出來,大概 99 個,這些 poc 將作為后續,針對每一個系統測試的 poc 列表。
其余 POC 將基于指紋識別的結果進行針對性的測試,共計 713 個,經過以下兩個步驟,針對百萬網站做了指紋識別:
1、獲取百萬網站的首頁內容(響應碼、header、body內容)
2、基于指紋庫識別通用系統類型(7 萬左右目標,識別出的系統類型 166 個)
從實戰結果來看,整體測試下來相比全部測試,時間上至少提高 8 倍,原本需要三個月測試完成的目標,使用這種方式僅需要十來天即可完成。
有了這些基礎數據,漏洞測試就是一條命令的事兒,相信用過 xray 的都知道怎么用,這里就不多說了。?????
0x03 總結
當你擁有開發能力之后,一切想法都可以形成腳本或者工具來幫助你提高效率,解放人力,自動化挖漏洞是一件非常有意思的事情,寫工具寫腳本也會給自己帶來成就感,如果你對上面的內容感興趣,歡迎加入信安之路與我們一起交流。
