SEVulDet:一種語義增強的可學習漏洞檢測器
Introduction
近年來越來越多的工作采用基于深度學習的漏洞識別框架來對漏洞模式進行識別。然而,不能全面地對源碼中的語義進行捕獲或是采用適當的神經網絡設計仍是大多數現有工作存在的問題。在此之上作者提出了SEVulDet,其具備兩個特點:(1)SEVulDet采用了一種路徑敏感的代碼切片方法來提取足夠的路徑語義和控制流邏輯至code gadget;(2)同時在結合多層注意力機制的CNN網絡中插入一層中空間金字塔池化層,使得SEVulDet能夠處理變長的code gadget語義,避免由傳統方法(截斷或填充)所導致的代碼語義缺失。
Background & Motivation
Problem
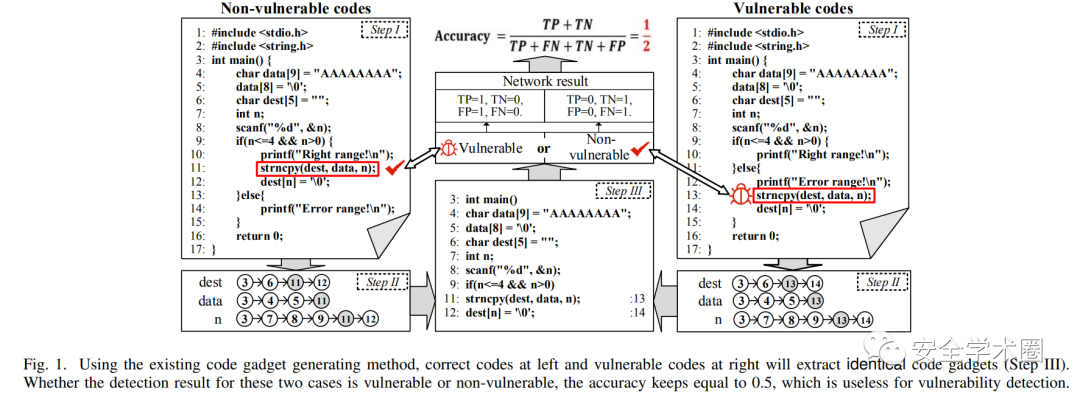
針對現有深度學習框架中存在的影響漏洞識別主要缺陷——語義缺失,作者采用一個例子對其進行了描述。
為了更好地描述,作者做了以下的一些定義:
- Program, statement, token: 程序 由一系列有序的statement組成,即 ,statement由一系列的有序token構成,即, token可以是標識符,常量,運算符,關鍵字等。
- data-dependence:在程序 中,如果存在兩個語句 , 中的變量標識符token被 使用,則稱 數據依賴于。
- control-dependence:對于程序 中的兩個語句, 當的結果會影響是否執行時,稱控制依賴于。
- special token:給定程序 , 且語句 由個special token組成, , 此處的special token指一些特殊的滿足語法特點的記號,如庫函數調用,數組使用,指針使用以及表達式等。
- code gadget:給定程序 , 且語句 由個special token組成, , code gadget 則是通過這些特殊記號遞歸生成的具有語義信息(存在數據依賴與控制依賴)的復數有序語句。
- PDG:給定程序 , 且語句 由個函數調用 , 其中的一個函數調用對應的PDG(Program Dependency Graphs)則可表示為有向圖 , 是由語句和判斷式組成的集合,而 則為表示依賴關系的有向邊集合。
接著作者指出了此前的兩項同領域工作[1][2]在提取code gadget時存在的問題,即路徑不敏感(path insensitive)。
根據code gadget的的定義,我們首先找到special token——strncpy,然后再分別提取strncpy數據依賴的三個記號(dest,data,n),提取記號相應前序與后序的代碼切片,結果如step II所示,最終根據這些代碼在文件中的位置與調用順序組合形成code gadget。然而此時存在漏洞的代碼與不存在漏洞的代碼提取結果是一致的,當模型的輸入不發生改變時,其輸出也不會發生改變,這也就意味著當模型對這些代碼進行分類時,其準確率是不會改變的。
Solution
為了解決上述的問題,作者從兩個方向出發:
- 改變對代碼的預處理方式。目前的處理方法對于語句間的控制依賴處理過于粗糙,且并未指明語句對應的路徑。并且在代碼片重組的過程中存在暴力堆疊的問題,使不在同一控制范圍內的語句彼此直接相鄰,從而導致了路徑不敏感。一種解決策略是標識每個控制語句的控制范圍。
在此基礎上作者給出了path-sensitive code gadget的定義:
- path-sensitive code gadget:給定程序 , 且語句 由個special token組成, , code gadget 則是通過這些特殊記號遞歸生成的具有語義信息(存在數據依賴與控制依賴)的復數有序語句或特殊記號所處的控制條件下的控制范圍語句。
- 在此前的工作中更多是選擇RNN作為漏洞識別模型,因為其能識別上下文并對文本進行分類。但是在RNN中token的長度必須被預定義且為定長,其所采用的處理方式也較為暴力(截斷和填充),這也導致對代碼語義產生了影響,因此作者針對網絡結構設計進行優化,使其得以處理變長的code gadget。
Design of SEVulDet
下圖展示了SEVulDet的訓練階段與檢測階段,訓練階段相較于檢測階段多了打標簽這一環節。整體上可分為兩個步驟:(1)從源代碼中提取必需的語法語義至路徑敏感的 code gadget;(2)使用模型學習潛在的漏洞模式。
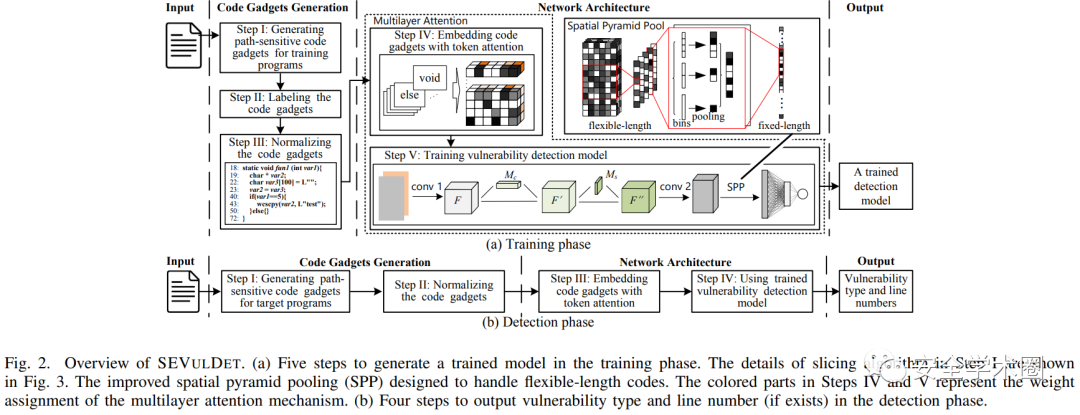
Path-sensitive Code Gadgets Generation
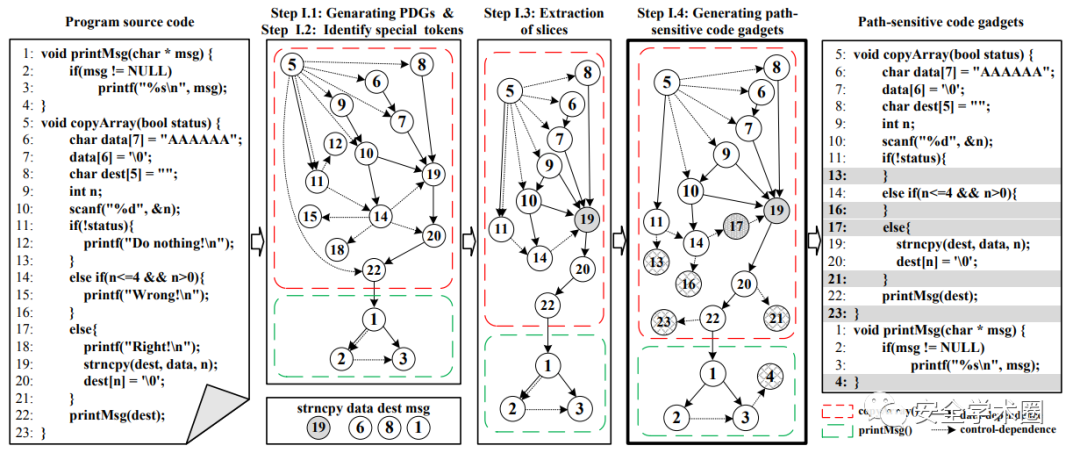
code gadget 的生成大體分為如下幾個步驟:
- 生成PDG,圖中的虛線與實線分別表示控制依賴與數據依賴。
- 識別special tokens,此處作者定義的special token包括庫/API函數調用,數組使用,指針使用。在圖中的例子作者提取出了strncpy,data,dest以及prinMsg。
- 接著分別通過前序分析獲取special token所在語句的后繼statemen,后序分析獲取special token所在語句的前驅statement,而不存在這種關系的statement(12,15,18)則被移除。
- 最后則是補充上路徑信息。為了識別所有的路徑信息,作者通過語法樹對關鍵節點(if,else if,else,for,while,do while,switch and case)進行識別,然后確定其控制范圍。例如 14-16 為else if的控制范圍,17-21 是else的控制范圍,如果沒有正確聲明控制范圍,17-21則處在了else if的控制范圍。因此作者通過為PDG添加相應的葉子節點使其能夠確定控制范圍,避免了語義的缺失。
Network Architecture Design
作者在CNN中設計了多層注意力機制與一個空間金字塔池化層,后者消除了RNN中對于code gadget預定義長度的限制。
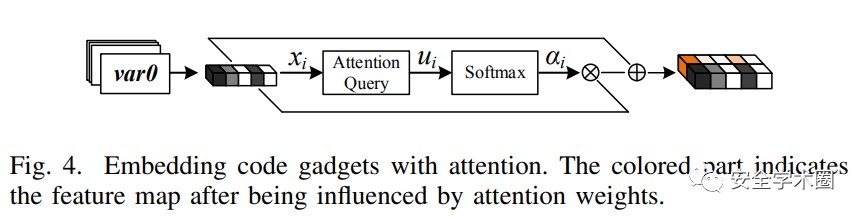
Embedding code gadgets with token attention
作者首先使用word2vec將token進行向量化,然后設計token注意力來學習哪些token是對檢測有幫助的。
Trainning vulnerability detection model
在多層注意力機制的第二部分作者采用了[3]的Channel Attention和Spatial Attention,并將二者進行了串聯。然后便是采用了空間金字塔池化層進行變長優化。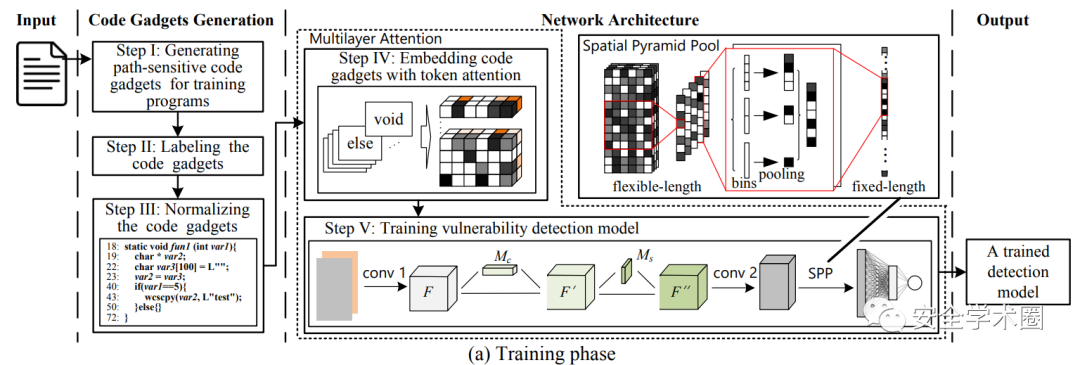
Evaluation
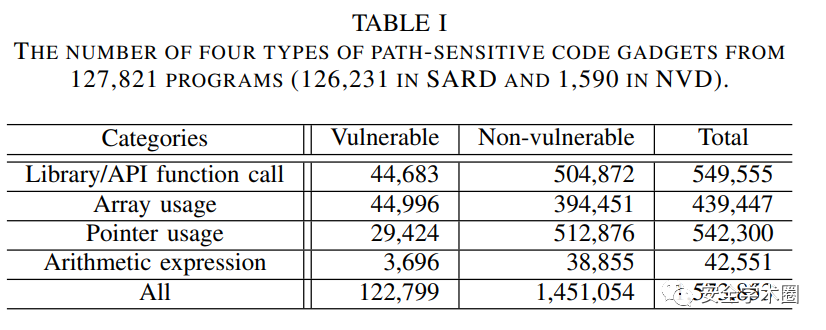
作者在驗證時采用了兩組通用的數據集Software Assurance
Reference Dataset (SARD)和Nation Vulnerability Dataset
(NVD)。
作者設計以下研究問題并作出了解答:
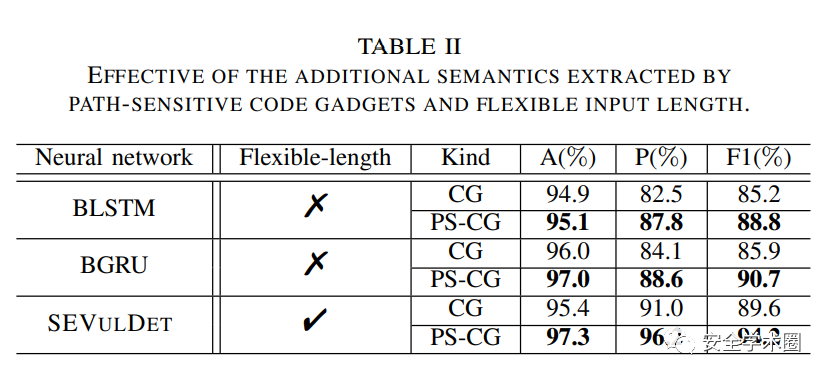
- 變長路徑敏感code gadget帶來的額外語義信息是否對于漏洞識別有幫助?
- 作者采用了定長的網絡結構進行對比,并且設置了不同的條件:(1)僅提取數據與控制依賴的code gadget——CG;(2)在CG的基礎上加上了路徑語義——PS-CG。
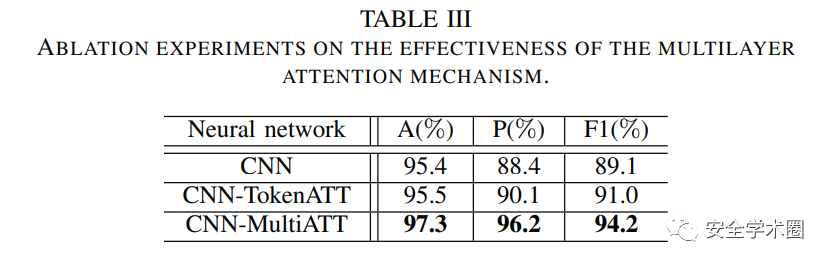
- 多層注意力機制是否使得SEVulDet更加有效?
- 與最先進的漏洞檢測框架相比,SEVulDet的效果如何?
- 與經典的靜態漏洞識別框架相比:
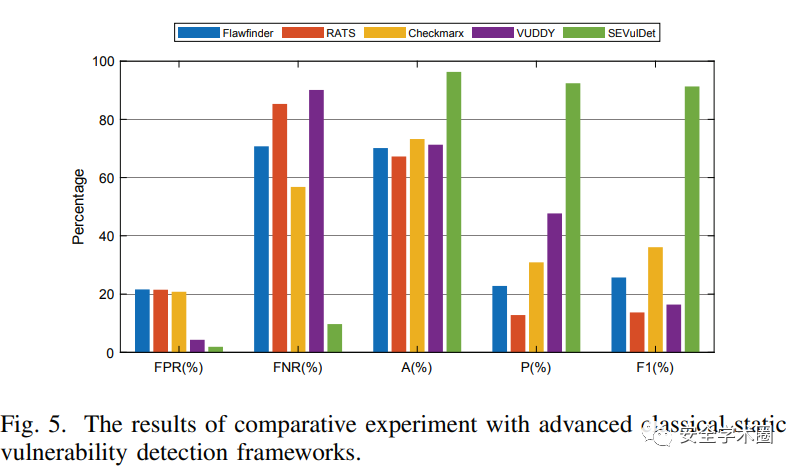
- 與其他深度學習漏洞識別框架相比:


- 在真實世界的軟件產品上測試:
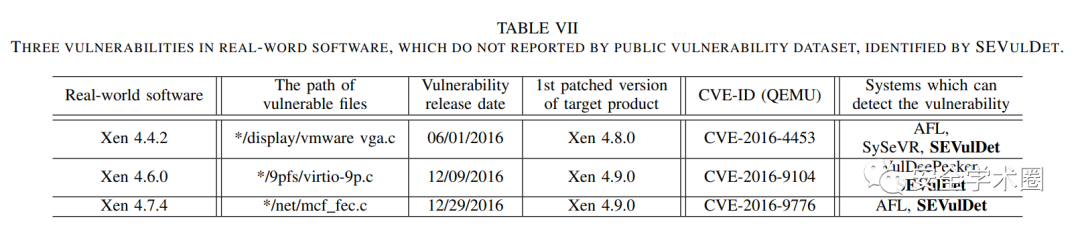
- 變長路徑敏感code gadget與多層注意力機制使得SEVulDet發現更多漏洞的原因是什么?
- 在這部分,作者選取了一個未報告過的漏洞作為例子,該漏洞導致的死循環可以被路徑敏感code gadget所捕獲,避免了語義信息的損失,并展示了由注意力機制計算所得的token權重,驗證了SEVulNet確實從code gadget中學習到了潛在的漏洞模式。

