POLYGLOT:使用語義驗證的通用語言處理器模糊測試引擎
一、 引言
語言處理器的主要作用是將高級語言程序翻譯為硬件可執行的機器代碼語言,其對于軟件開發至關重要,錯誤的語言處理器可以將正確的程序翻譯成故障代碼,從而導致安全漏洞,像解釋器中的漏洞可以使得攻擊者能夠實現拒絕服務。但是由于語言處理器對于輸入的測試代碼的語法和語義有效性具有很嚴格的要求,語法或者語義錯誤會導致無法檢測到語言處理器更深層次的邏輯,因此對語言處理器的測試存在一定困難。目前的模糊測試技術嘗試在抽象語法樹(AST)或者中間表示(IR)上對測試用例進行突變來保留其語法結構,或針對一種語言進行特定的約束來保證語義的正確性。然而當針對一種語言進行特定的語義約束會使測試不能普遍適用于通用的語言處理器。
因此,針對于上述問題,作者提出PolyGlot,使用語義驗證的一個通用的語言處理器模糊測試引擎,并提出如下方法:
01
為提高普遍性,本文設計一種中間表示語言(immediate representation,IR)。各種編程語言會首先根據其BNF語法和相關語義注釋,轉換為IRs進行變異等操作,經語義驗證有效后再轉換為源代碼形式在Fuzz引擎運行;
02
為提高語法有效性,對轉換后的IRs使用約束變異和語義驗證兩種方法用于測試用例的生成;
二、 概述
PolyGlot的基本框架如下圖所示,主要由兩部分組成:
01
用戶輸入:對應語言的BNF語法,語義注釋,種子(可選輸入);
02
PolyGlot:前段生成器、IR轉換器、約束突變、語義驗證;
其基本流程為:首先,前端生成器(Bison&Flex)根據用戶輸入的BNF語法和語義注釋生成相關的解析方法,各個解析方法構成IR轉換器。然后,對于每一輪模糊,我們從語料庫中選擇一個輸入。這個輸入會被載入到IR轉換器中,轉換為IR程序。轉換后的IR程序進行約束變異、語義驗證等操作后,轉換為源碼形式進入fuzz引擎運行,查看是否產生崩潰。Fuzz過程中如果有新的路徑發現,則將該測試用例保存至語料庫。

圖1 PolyGlot流程概述圖
三、 IR
01 基本形式
IR基本形式為IR。type對應于BNF語法中的每個標簽;left、right表示該IR的左右IR;op、val則用來存儲部分源代碼信息,像函數名稱、參數值等;semantic_property則對應于語義注釋中的相關語義屬性。如下圖所示為一個C程序對應的IR程序(圖a)、BNF語法(圖b)和語義注釋(圖c)。

圖2 示例IR及對應BNF語法和語義注釋
以ir2為例,其type為FunctionName對應于BNF語法中的標簽,val處則存儲函數名“main”,語義屬性處對應于語義注釋中對于標簽的注釋“FunctimeName”。通過設計這樣一種IR,就可以將各種編程語言轉換為統一的中間表示,并且包含相關語義屬性,可用于后續提高語義的有效性。
02 相關屬性
IR程序同時具有語法屬性和語義屬性。語法屬性一方面體現在部分IR可以存儲源代碼,另一方面IR通過左、右IR的定向連接,可以形成源程序的樹狀視圖,如下圖所示為IR程序即對應的樹狀圖,通過對樹狀圖的遍歷可還原源代碼。
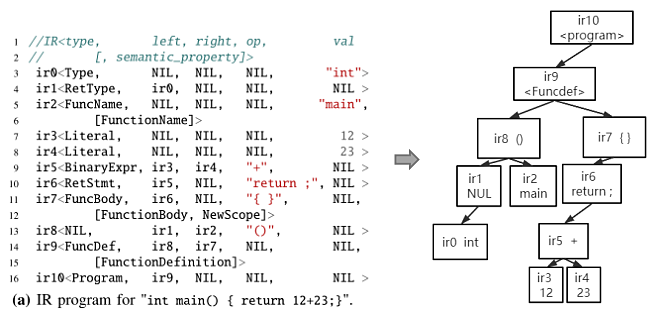
圖3 示例IR及對應樹狀圖
語義屬性則捕獲有關定義范圍和類型的語義。對于類型,它可以判斷哪些IRs屬于變量定義,變量基礎類型和類型間轉換規則,操作數類型和運算符輸出類型等。對于范圍,它可以判斷哪些IRs創建了新的作用域,以此確定變量的的可用范圍。
四、 約束變異
約束變異的基本原則是保證測試用例的語法有效性和盡量保持未變異部分的語義有效性。
它使用基于類型的變異來保證測試用例的語法有效性。在該變異階段有3種突變策略:插入、刪除和替換。在該部分中為了保證語法的有效性,通常在同類型間進行IR的替換,或者是在一些條件語句(if,else等)進行插入和刪除,以此來降低變異對語法結構的破壞。
它使用一種局部變異的方式來保證未變異部分的語義有效性。基本原則是選擇不包含定義的IR或者創建了新的范圍的IR進行變異。
01
不包含定義的IR主要是指僅對變量進行賦值或者調用,沒有對變量進行聲明定義,如下圖4第7行,僅對變量arr[1]進行賦值,這時如果執行刪除或者替換操作,程序語義仍然正確。
02
創建新的范圍IR:一般指函數;雖然在新范圍的IR內仍然存在變量定義,但是該變量的作用域僅在該IR范圍內,這時如果對IR整體進行變異則不會影響其他部分的語義。如下圖4第9行,for函數中定義了新的變量idx,但其僅在for函數作用域內調用,這時我們需要對每個idx同時進行變異或者直接對for函數進行變異。

圖4 示例JS程序
五、 語義驗證
由于約束變異階段可能會產生無效變量,從而導致語義錯誤,因此在該階段的主要目的是尋找有效變量來代替無效變量,從而完成語義有效性的驗證。該步驟實現的相關組件有:類型系統、范圍系統和符號表。
01 類型系統
類型系統的目的是收集變量類型信息,并使用Type map結構記錄變量基本類型和用戶自定義類型,便于根據類型查找有效變量。
(1) Type map 構建
變量的類型可以分為基本類型和復合類型。基本類型指的是編程語言中預定義的類型,像int、short等,基本類型是有限的,可以在語義注釋中進行完全描述。復合類型在這里主要是指結構體、函數和指針。復合類型的構建需要遍歷所有的IRs,再通過語義屬性查找滿足上述三個符合類型的IRs,搜索其組件,并用組件創建新類型。由于復合類型是特定于某個程序的,因此每完成一個測試用例,都需要刪除其存儲的復合類型。
基本類型和復合類型均存儲至Type map中,映射的鍵是類型的唯一ID,值是類型的結構。如下圖所示為某突變程序及其對應的Type map。

圖5 變異程序及對應Type map
(2) 變量類型推斷
根據上述構建的Type map我們就可以對程序中變量類型進行推斷,從而進行正常使用。對于變量定義,當變量為顯性類型,即直接聲明變量類型,如:int a,c等,直接再type map中查找變量類型名稱,返回索引TID。當變量為隱式類型,如:let y=1.0時,這時根據其賦值來對其進行類型判斷。對于已定義的變量調用,則直接根據變量名稱返回匹配類型的TID。對于表達式類型,如果表達式中僅包含一個變量或者一個常量,則視為變量調用處理或根據常量類型進行匹配。對于包含操作符的表達式,則根據語義注釋中包含的操作符輸出類型和左右操作數類型進行匹配。對于在動態執行中,變量類型不是固定不變的,則賦為AnyType。
02 范圍系統
范圍系統的目的是收集變量可適用的范圍信息,該過程中使用Scope Tree對IR程序進行作用域劃分。首先選取全局作用域作為根節點。然后當語義屬性中聲明有新的作用域時,會創建葉節點,并為每個節點分配唯一的ID。在這里使用代碼行數來可視化作用域。如下圖所示為某突變程序及其對應的Scope Tree。

圖6 變異程序及對應Scope Tree
03 符號表
符號表的目的是集成變量的類型信息和作用域信息,用于查找有效變量來組成表達式來替換無效變量。Scope tree的每個葉節點都有一個符號表,符號表中包含了該節點作用域內的所有變量名稱,并使用TID和OID標記變量類型和作用行數。TID對應于Type map中的ID。OID則使用所在行數標識變量的作用范圍。如果一個變量位于當前節點的祖先節點中,并且該變量在該節點作用域之前被定義,則該變量可以被當前節點所調用。
如下圖所示為某變異程序及其對應符號表。

圖7 變異程序及對應符號表
以圖7中的變異程序和符號表為例,語義校驗的過程如下:
(1)
首先將無效變量替換為特殊字符串FIXME,即if語句中的變量x,y;
(2)
刪除在變異過程中產生的沒有詳細定義的變量,即11行中的結構體X,它僅對變量進行聲明,并沒有具體定義;
(3)
查找符號表生成有效表達式替換FIXME:
(a)
推斷變量FIXME的類型,首先將類型賦為AnyType,然后根據類型推斷步驟逐步向上推斷出具體類型,像如圖所示示例,因為其包含操作符“>=”,所以初步認定FIXME為數據類型,如:short\int等;
(b)
在符號表中查找在該語句作用域之前定義的變量,在該節點的祖父節點中,且OID在該節點作用域之前的變量均復合要求,像s、a、c、main()、e、b;
(c)
根據查找得到的變量列舉所有可能的表達式,并進行分類。在這里構成的表達式主要有兩個類型:int類型(a,c,s.d,b[0],b[1])、struct類型(s);
(d)
按照所需的類型,隨機選擇表達式替換FIXME,至不產生語義錯誤;
六、 實驗設計及結果
01 具體實現
本方法中的前端生成器是由Bison和Flex構成,BNF語法來源于各編程語言的官方文檔或者開源庫ANTLR[1],語義注釋則是本文作者提供了一個json模板,用戶根據需求進行輸入。Bison和Flex針對于BNF語法中各個標簽和語義注釋的解析方法構成IR轉換器。
本方法是基于AFL 2.52b進行構建的,保留了其fork-server機制和隊列調度算法,并將其測試用例生成模塊替換為POLYGLOT。
02 實驗設置
本實驗的測試目標為9種流行編程語言的21中解析器和編譯器;如:解析C語言的GCC/clang、解析JS代碼的JsCore等。
實驗比較的Fuzz引擎為:三個通用的模糊器 (AFL[2],混合QSYM[3],基于語法的Nautilus[4])、針對于C解析器的CSmith[5]和針對于JavaScript解析器的DIE[6]。
03 具體實驗
類型系統的目的是收集變量類型信息,并使用Type map結構記錄變量基本類型和用戶自定義類型,便于根據類型查找有效變量。
(1)實驗一:測試發現bug數量
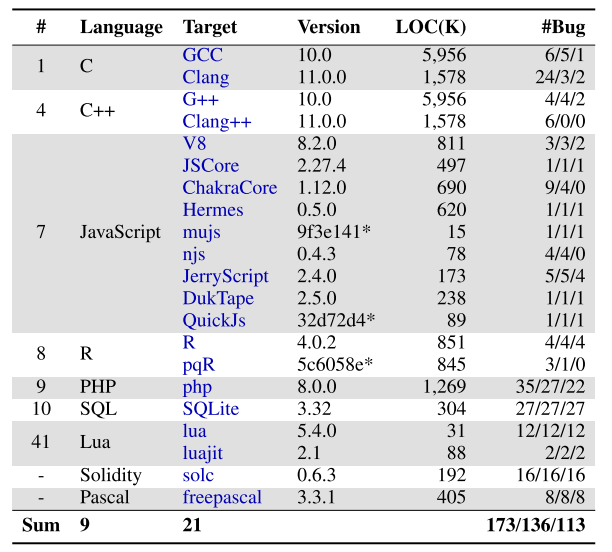
該實驗室將POLYGLOT應用在9種編程語言的21個代表性處理器上,總計發現報告173個漏洞,已經確認136個,已經修復113個,并分配了18個CVEs。具體結果如下表所示。
通過結果可知,POLYGLOT可以在多種編程語言的處理器中發現真實漏洞,證明POLYGLOT具有普遍適用性。
表1 POLYGLOT發現bug數量實驗結果
(2)實驗二:驗證語義校驗的有效性
該實驗的比較對象為POLYGLOT和POLYGLOT-syntax(本工具刪除語義驗證部分)。比較指標為:發現唯一崩潰的數量、語言的有效性和邊覆蓋率。
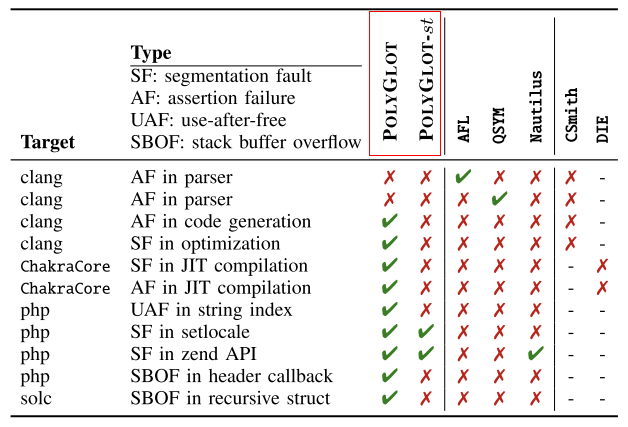
發現唯一崩潰數量的實驗結果如下表2所示。結果顯示完整工具可以發現9個錯誤,包括php,clang,ChakraCore;缺少語義驗證的工具只能發現php中的兩個錯誤。且經過對這兩個php bug分析,觸發該錯誤的代碼位于執行的第一行,所以沒有語義驗證的POLYGLOT只能發現php淺層次的漏洞。
表2 POLYGLOT&其他fuzzer發現bug數量實驗結果
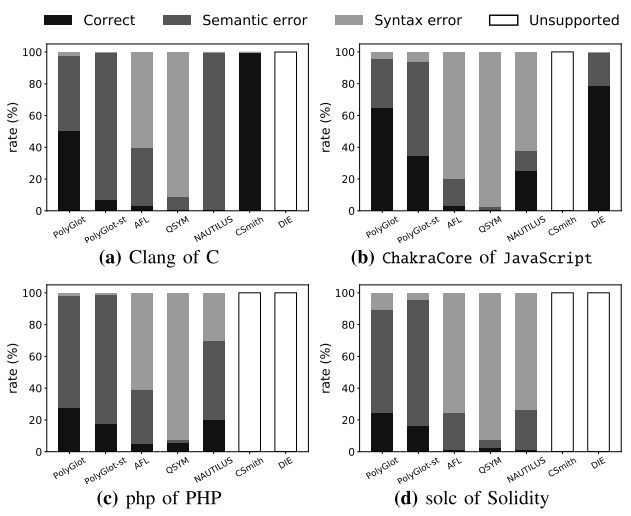
二者語言有效性的實驗結果如下表3所示。結果顯示,與POLYGLOT-syntax相比,針對于Clang、ChakraCore、php 和solc,POLYGLOT均提高了測試用例的語言有效性,表明語義驗證可以明顯提高測試用例的語義正確性。
表3 POLYGLOT&其他fuzzer語言有效性實驗結果
二者邊覆蓋率的實驗結果如下表4所示。結果顯示,針對于四種處理器,POLYGLOT的邊覆蓋率均高于POLYGLOT-syntax,說明POLYGLOT中的語義驗證機制可以使得測試用例探索到更深的層次,從而發現更多bug。
表4 POLYGLOT&其他fuzzer邊覆蓋率實驗結果
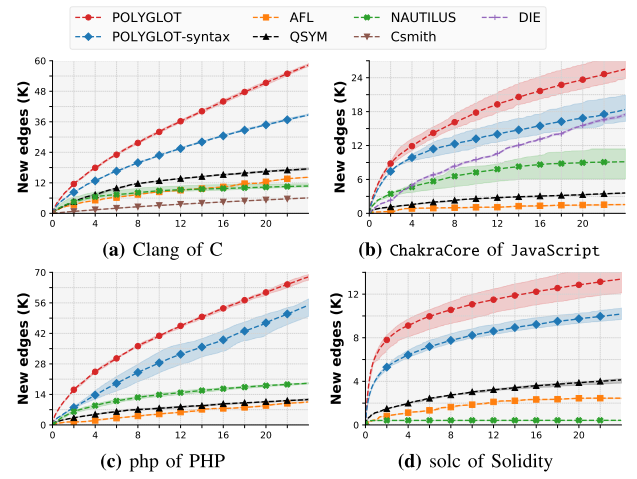
(3)實驗三:與其他fuzzer比較
該實驗的比較對象為POLYGLOT和三個通用的模糊器 (AFL,混合QSYM,基于語法的Nautilus)、針對于C解析器的CSmith和針對于JavaScript解析器的DIE。比較指標為:發現唯一崩潰的數量、語言的有效性和邊覆蓋率。實驗結果如上表2、3、4所示。
根據表2實驗結果可知,POLYGLOT發現了四種處理器上的9個bug,其他fuzzer引擎中只有AFL和QSYM各發現一個位于clang中的解析錯誤,這是POLYGLOT不曾發現的,但是仍然可以說明,POLYGLOT可以發現更多語言處理器中的bug。
表3結果表示,對于通用的模糊器,POLYGLOT生成的測試用例的語言有效性均高于其他3種fuzzer,但是對于兩種針對于特定語言的模糊器CSmith和DIE,POLYGLOT的有效性均低于二者,但是POLYGLOT具有普遍性,可以適用于多種語言處理器。
表4結果顯示,對于通用的模糊器,POLYGLOT的邊覆蓋率均高于其他3種fuzzer,這是由于其語言的有效性導致其可以執行到更深層次。但是對于兩種針對于特定語言的模糊器CSmith和DIE,POLYGLOT的邊覆蓋率仍然高于二者,這可能是由于其他機制導致的,像覆蓋引導機制、代碼結構等。經實驗驗證,當POLYGLOT刪除覆蓋引導機制時,其邊覆蓋率會低于CSmith。
七、 局限及不足
POLYGLOT的局限性以及可能的解決方法如下所示。
01 類型系統、范圍系統的局限:
POLYGLOT的語義驗證過程中所使用的類型系統比較適用于靜態作用域,動態作用域下會導致類型定義不準確。該缺陷可以利用動態執行在模糊之前收集種子輸入的運行時信息,進而可以準確收集變量信息。
02 BNF語法的局限
BNF語法并不能精準描述語言的語法,其通常是真實語法的超集,仍會導致語法錯誤。該缺陷的解決思路是在動態執行中推斷語法或者使用深度學習方法學習語法。
03 語義的局限
POLYGLOT目前校驗的語義為:變量的類型和范圍。后續可以繼續添加編程語言共享的更多語義問題進行校驗,以進一步提高語義正確性。
八、 總結
本文主要針對語言處理器模糊測試領域中語義有效性和普適性問題,提出POLYGLOT工具。這是一個通用的模糊框架,可生成用于測試不同編程語言的處理器的高質量輸入。經實驗驗證,POLYGLOT成功在9種語言的21個處理器上識別了173個新錯誤,且相較于其他fuzz引擎,本工具的代碼覆蓋率更高,說明POLYGLOT在測試語言處理器方面比現有的模糊器更有效。
參考文獻
1.
Grammars written for ANTLR v4. https://github.com/antlr/grammars-v4,2020.
2.
Michal Zalewski. American Fuzzy Lop (2.52b). http://lcamtuf.coredump.cx/afl, 2019.
3.
Insu Yun, Sangho Lee, Meng Xu, Yeongjin Jang, and Taesoo Kim. Qsym: A practical concolic execution engine tailored for hybrid fuzzing. In Proceedings of the 27th USENIX Conference on Security Symposium,USA, 2018.
4.
Cornelius Aschermann, Tommaso Frassetto, Thorsten Holz, Patrick Jauernig, Ahmad-Reza Sadeghi, and Daniel Teuchert. Nautilus: Fishing for deep bugs with grammars. In NDSS, 2019.
5.
Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. Finding and understanding bugs in c compilers. In Proceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’11, New York, NY, USA, 2011.
6.
S. Park, W. Xu, I. Yun, D. Jang and T. Kim, "Fuzzing JavaScript Engines with Aspect-preserving Mutation," 2020 IEEE Symposium on Security and Privacy (SP), 2020, pp. 1629-1642, doi: 10.1109/SP40000.2020.00067.
