隱私計算:四大技術路徑解析
近日,中國信息研究院發布《數據價值釋放與隱私保護計算應用研究報告(2021年)》,據了解,這是國內首份關于隱私計算應用研究方向的報告。在《數據安全法》、《個人信息保護法》陸續落地的2021年,隱私計算賽道迎來了崛起的契機。
在DT(數據技術)時代,數據已然成為一種重要的資源,是一種重要的新型生產要素。和傳統生產要素相比,數據要想真正成為既可以自由流通,又能具備安全性的戰略資源,就繞不開數據隱私計算這一環節。
隱私計算可以讓數據在流通過程實現“可用不可見”,在保護數據隱私的前提下,解決數據流通、應用等數據服務問題,成為解決數據利用和安全性這對矛盾的重要途徑。
在隱私計算的領域中也有不同技術路徑,它們采用不同的技術形式實現數據隱私安全的目標。根據數據是否流出、計算方式是否集中來劃分,隱私計算可以劃分為四個不同的象限,分別是:
數據流出、集中計算;
數據流出、協同計算;
數據不流出、協同計算;
數據不流出、集中計算。
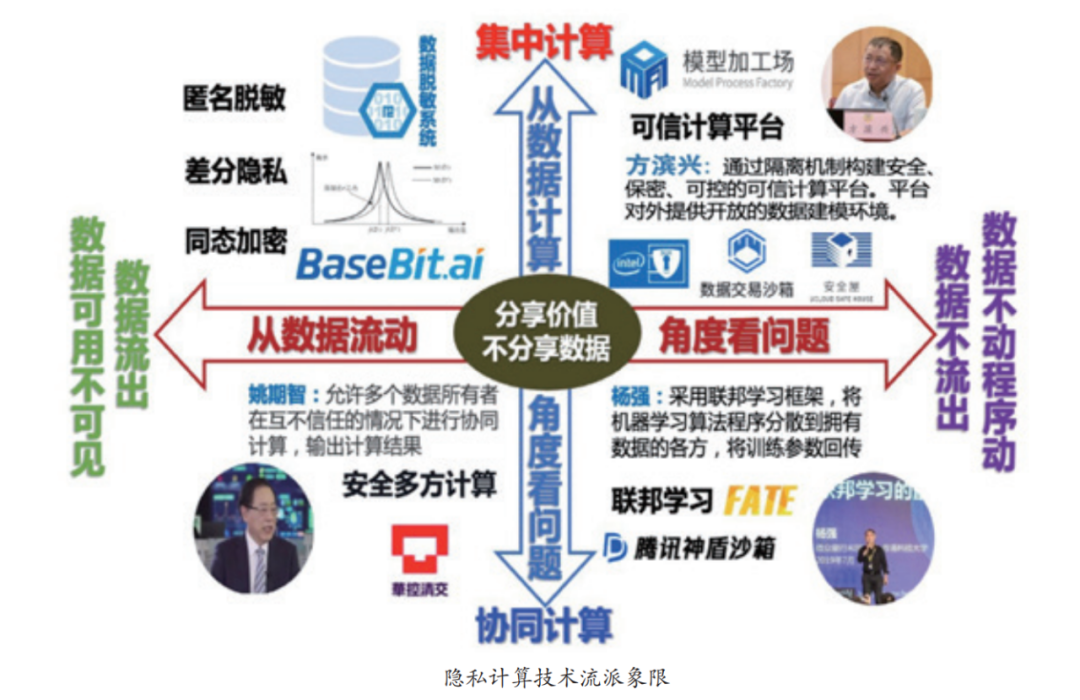
路徑一:數據流出、集中計算
代表技術:數據脫敏、差分隱私、同態加密
該技術路徑的核心,是對數據進行變形、擾動、加密等操作,可保障數據流出時的隱私安全,主要有三種安全技術:數據脫敏、差分隱私、同態加密。
數據脫敏(Data Masking)是指使用脫敏規則對數據中某些敏感信息進行數據的變形,從而達到保護敏感隱私數據的目的。
更具體來講,我們可以采用刪除可識別個人的信息的方式,讓數據描述的人保持匿名,也可以采用對數據去標識化,讓人們無法根據數據識別到具體的個人。
如果說數據脫敏是通過對敏感信息“做減法”的方式實現保護隱私,那么差分隱私(Differential Privacy)就是以“摻沙子”的方式,通過在數據或者計算結果上添加一定強度的噪聲,來保證用戶無法通過數據分析結果推斷出是否包含某一特定的數據。
而同態加密(Homomorphic Encryption)則是用技術方式,在不影響數據運算結果的前提下將數據變為密文,這也就不再涉及隱私的問題,而不同的加密技術允許不同的運算規則
整體看,這些技術通過對數據操作來保障數據流出時的隱私安全,但是它們也有一些局限性:
1)數據脫敏容易遭受攻擊,從技術恢復數據中的敏感信息較為容易。
2)差分隱私會降低機器學習準確率,較高強度的噪聲雖然較好地保護隱私,但對數據分析的準確性也有較大的影響。
3)同態加密運算效率低,也會影響使用該技術的意愿。
路徑二:數據流出、協同計算
代表技術:安全多方計算平臺
“兩個富翁的財富是1-10之間的整數,如何能在不透露雙方財富的前提下,比較出誰更富有?”這是姚期智院士在1982年提出的“百萬富翁問題”。富翁不露財卻又想做比較,按照這樣的邏輯,如何在一個互不信任的多方系統中,各參與方能協同完成計算任務,同時保證各自數據的安全性呢?這就是網絡安全版的“百萬富翁問題”。而解決之道就是安全多方計算。
安全多方計算是密碼學的一個子領域,其目標是為各參與方共同計算一個函數,這個函數的輸入來自不同的參與方,同時保證這些輸入內容不泄漏。
目前,隨著業界對安全多方計算技術的關注,其應用范圍越來越廣泛,國內外各大廠商也相繼推出各自的安全多方計算平臺或隱私計算平臺。
與此同時,開源的安全多方計算庫也越來越多,如在Google公司Tensorflow基礎上開源的TF-Encrypted,開源社區Openmined基于微軟SEAL開源的TenSEAL,以及安全多方計算的協議實現ABY3與MP-SPDZ等。
這一路徑下又有兩種主流技術。
一種是混淆電路(Garbled Circuit)。通過將兩方參與的安全計算函數編譯成布爾電路,并將電路的真值表進行加密、打亂,就能保證電路的正常輸出而又不泄露參與計算的雙方私有信息。
另一種是秘密共享(Secret Sharing),類似于需要將所有的秘密拼在一起才能還原全貌的思路,這種技術在參與者之間分發秘密,每個參與者都被分配了一份秘密分割,只有當足夠數量的、不同類型的秘密分割組合在一起時,才能將秘密恢復出來;單個的秘密分割本身是沒有任何意義的。
這一技術實現了可證明的安全性,對于安全性要求較高的場景具有較好的應用價值。但在實際落地中,仍有一定的局限性:
1)性能低下:由于使用了很多密碼學方法,一些復雜的任務很難在在短時間內完成計算任務;
2)程序編寫難度大:由于安全多方計算涉及密碼學技術較多,且應用起來流程較其他技術相比非常復雜,通常需要通過借助額外的編程庫進行實現,這大大增加了應用編寫人員的學習成本和工作量,導致在實際落地過程中仍存在障礙。
3)調試難度大:由于安全多方計算僅輸出最終的執行結果,在面對復雜的分析問題時,使用者難以僅通過程序的最終執行結果獲得反饋去優化整個數據分析過程。
路徑三:數據不流出、協同計算
代表技術:聯邦學習平臺
聯邦學習(Federated Learning)的概念于2016年由Google率先提出,用于解決安卓手機終端用戶在手機端使用用戶數據訓練模型的問題,其本質上是一種分布式機器學習。
這一技術的核心思路是,盡管有同一個中央服務器或服務協同商,但參與方的原始數據都只會在本地,而不會用于交換傳輸,真正參與聚合的完成訓練的是經過模型轉換的數據信息。
由于場景的區別,聯邦學習還分為了橫向聯邦學習、縱向聯邦學習和聯邦遷移學習等形式。隨著歐盟《通用數據保護條例》(GDPR)的推出,數據隱私保護越來越受到各國重視,聯邦學習的應用范圍也愈加廣泛。
例如,Google公司開源了一個學習框架,用來完成分類、回歸等機器學習任務;國內以楊強教授為代表的微眾銀行開源聯邦學習框架FATE,提供一站式聯邦模型服務解決方案。
整體看,聯邦學習可以在數據不流出本地前提下,聯合多個參與方訓練模型,對于打破數據孤島具有重要意義。其局限主要在:
1)存在隱私泄露風險,聯邦學習的訓練模型是需要共享的,這就為攻擊者根據模型信息倒推隱私數據提供可能。
2)機器學習算法兼容性較差,且目前支持的機器學習算法較少。
3)機器學習任務調試困難,要想獲得最優的模型和參數往往通過不斷嘗試和調試獲得,一個標準機器學習工作流包括數據探索、特征工程、模型選擇、超參數優化等步驟,再加上在聯邦學習場景下,數據分散在各地,數據可用不可見,這些步驟很難在保證安全地前提下完成。
路徑四:數據不流出、集中計算
代表技術:可信計算平臺
可信計算平臺就是通過隔離機制構建出一個安全可控區域,在這個足夠安全的空間中,數據能夠被集中訓練且不流出,從而保證內部加載數據的機密性和完整性。
具體講,可信計算平臺又有兩種技術。
一種是可信執行環境(Trusted Execution Environment,TEE),該技術通過軟硬件隔離安全機制建立一個安全隔離的執行環境,從而防止外部攻擊者(包括系統管理員)竊取TEE內部運行的數據。硬件上,它依賴于將其預置在CPU等硬件,然后再通過應用程序的參與營造出一個安全世界。TEE具備支持多層次、高復雜度的算法邏輯實現,運算效率高以及可信度量保證運行邏輯可信等特點。然而,TEE由于依賴于CPU等硬件實現,必須確保芯片廠商可信。同時,TEE對服務器型號限制較大,其功能性和性能等均收到硬件限制。
另一種技術為數據沙箱技術,該技術通過構建一個可信計算環境,使得外部程序可以在該平臺上進行執行。這樣,既可以使用外部程序對數據進行加工處理,也可以保障數據的安全。對于數據需求方人員,他們不能進入數據沙箱查看調閱真實的全量數據。對于數據分析師而言,由于數據沙箱將調試環境和運行環境隔離,所以他們也只能在調試環境中使用樣本數據調試代碼,然后將代碼發送到運行環境中運行全量數據,從始至終都無法接觸全量數據,這樣,隱私安全的保護就得以實現。
數據沙箱技術主要特點是將隱私安全能力植入大數據計算、存儲引擎等基礎設施,通過將調試環境與運行環境隔離,構建一個安全可控的數據環境,提升數據融合計算過程中的隱私安全水位,實現數據挖掘計算過程中的可用不可見,且不改變業務原有技術棧和使用習慣無需改造現有的數據分析算法和工具,同時使得業務算法模型精度折損微小。因此,這可以說是兼具安全性和可操作性的較為成熟的技術。
目前,國內學術界以中國工程院院士方濱興為代表,基于可信計算平臺技術打造AI靶場接收用戶程序,通過防水堡過濾用戶程序外傳結果時夾帶的原始信息。在國內產業界,奇安信、百度、京東數科、UCloud等各大廠商均有推出數據沙箱相關產品。
以奇安信率先推出的“數據交易沙箱”為例,它基于“數據不動程序動”、“數據可用不可見”的安全理念,采用調試環境與運行環境隔離的技術來解決數據流通交易過程中的數據隱私安全問題。
除了上述談及的四大技術路徑,在網絡安全領域,伴隨網絡技術的不斷發展,區塊鏈技術與上述技術流有著融合趨勢。區塊鏈具有數據可溯源、難以篡改、公開透明、智能合約自動執行等技術特點,能夠一定程度上解決多方協作、多方信任和數據共享流通的問題。
在與隱私計算相結合時,主要有三個關鍵技術:
一是基于區塊鏈的安全密鑰管理與可信身份認證;
二是鏈上、鏈下的安全計算協同;
三是數據生命周期管理。
安全密鑰管理與可信身份認證能夠實現相對安全靈活的密鑰管理體系,降低密鑰中心化存儲的安全風險,在防止中間人攻擊和丟包攻擊的同時,使得隱私管理更加安全、精細化。此外,該技術也能解決數據共享參與者身份及數據可信問題,這樣,不僅可以提升惡意參與者的作惡成本,還可以保障共享計算的數據質量。
鏈上、鏈下的安全計算協同又可分為鏈上與鏈下兩個部分。通過鏈上與鏈下相結合,區塊鏈專注業務邏輯可信執行與數據權屬憑證流通,而鏈下隱私計算網絡負責大規模運算和數據價值流通,最終實現一加一大于二的效果。
數據生命周期安全管理方面需要實現全流程管理,包括數據采集、傳輸、存儲、使用、流通、銷毀等環節。數據共享計算參與者可以在鏈上用智能合約來實現計算過程中的協作管理功能,由參與方之間共同治理隱私計算過程,協作過程公平公正、公開透明、權責對等,避免了中心化協調方參與帶來的隱私泄漏的風險,也能確保參與方按照約定方式計算,提升數據共享協作效率。
區塊鏈隱私計算目前也正投入到實際場景中得到應用。然而,它仍然有一些問題等待進一步解決。
例如,區塊鏈上數據處理能力不足,鏈上計算受限于虛擬機執行和網絡共識性能,容易出現鏈上無法承載大量交易和無法即時交付等問題,難以滿足支持高吞吐的交易量和即時交付的需求。
其次,由于在引入區塊鏈技術時數據半同態加密、用戶身份認證等密碼學保護手段。這會使得架構上引入了額外的申請審批流程,計算上引入了加密帶來的額外計算開銷,使得數據流通過程效率大幅降低。
綜上,隱私計算四大技術路徑各有千秋、各有利弊。但毫無疑問的是,既具有技術上的先進性,又具有操作執行上便捷性、延伸性以及高效率等特點的技術,無疑能夠在當前獲得更大認可。而把握未來技術的動向,占據技術發展的上風,將成為各方參與者需追求之事。
