【技術分享】如何保護深度學習系統-后門防御

前言
后門攻擊是AI安全領域目前非常火熱的研究方向,其涉及的攻擊面很廣,在外包階段,攻擊者可以控制模型訓練過程植入后門,在協作學習階段,攻擊者可以控制部分參與方提交惡意數據實現攻擊,甚至在模型訓練完成后,對于訓練好的模型也能植入后門模塊,或者在將其部署于平臺后也可以進行攻擊,比如通過hook技術、row hammer技術等。
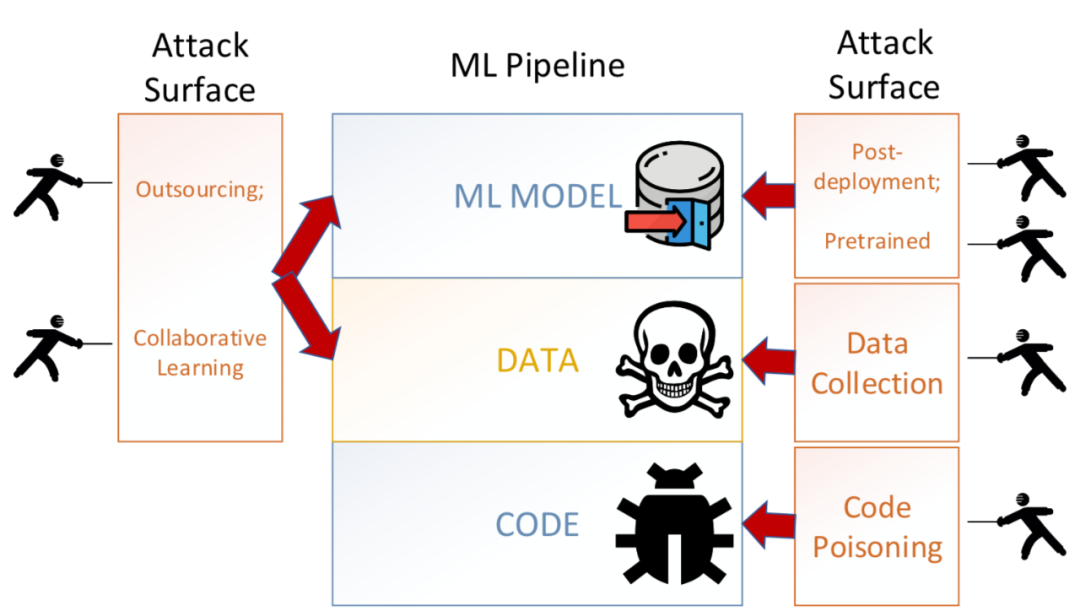
隨著攻擊的研究逐漸深入,相關的防御方案也被提了出來,對于攻擊者而言,接下來再要設計攻擊方案,必須要考慮是否能夠規避已知的防御方案,而對于防御者而言,需要考慮已有防御方案的缺陷,以及如何改正,才能進一步提高檢測效率,不論是從哪方面來看,都有必要對目前典型的防御方案做一個全面的了解。
本文就會從樣本和模型兩個角度,介紹目前典型的方案,這里說的“典型”的標準是指引用量高,常被研究人員哪來作為對比使用,以及發在頂會訂刊上的工作,限于篇幅,不可能面面俱到,但是從這些典型方案中基本能了解防御者的防御假設、設計思想等,對我們之后的工作具有參考價值。
防御
對于一個完整的AI系統而言,最重要的兩個組件就是數據和模型,做攻擊是從這兩門著手,所以我們在分析防御方案時,也分別從數據(樣本)和模型兩個角度進行研究。
樣本角度
從樣本的角度來分析,可以分成兩種,一種方案僅僅檢測是否為毒化樣本,另一種方案則是會對輸入樣本進行轉換,使樣本中可能存在的觸發器失效,以實現防御。
樣本檢測
[1]認為對抗樣本和毒化樣本之間存在一些相似之處,都需要通過小擾動強化錯誤的預測輸出,如下所示

左邊是對抗樣本,加上的擾動為對抗噪聲;右邊為毒化樣本,加上的擾動為觸發器。它們在推理過程中會表現異常,所以可以用類似的方法檢測,所以研究人員將檢測對抗樣本的方法應用于檢測毒化樣本,根據毒化樣本的模型敏感性、特征空間和激活空間中的行為等,確定了四種檢測毒化樣本的方法,對應的示意圖分別如下
第一種是基于模型突變的:
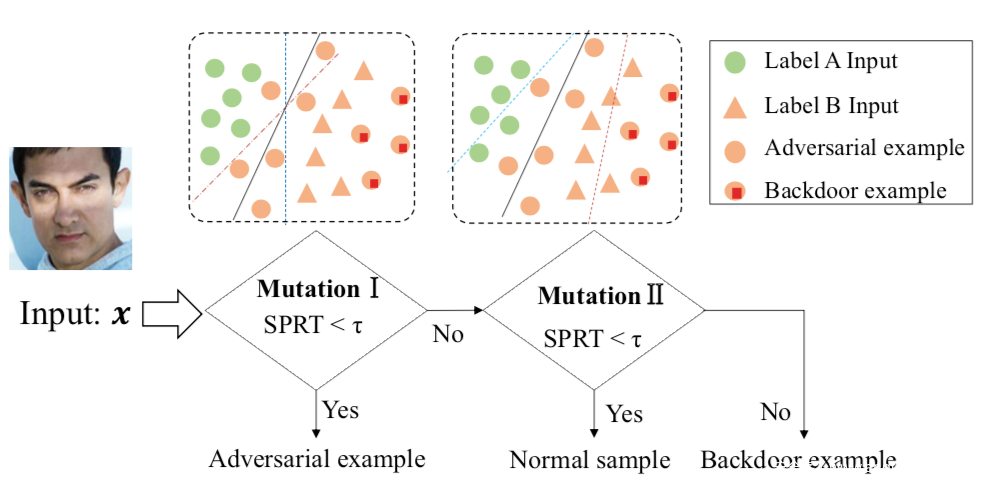
首先設置一個較小的突變率檢測模型是否為對抗樣本,如果不是,則以較大的突變率繼續,檢測是否為毒化樣本。
第二種,基于激活空間,其依據是毒化樣本和良性樣本在不同網絡層的激活空間的行為是不同的。
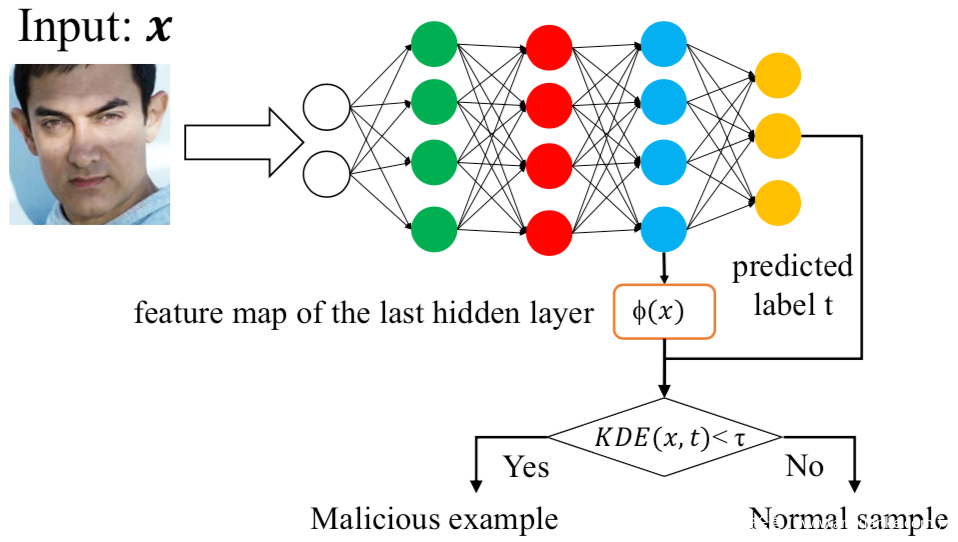
第三種,基于核密度估計,該方法專注于特征空間的異常檢測,在特征空間中,被錯誤分類到目標類別的毒化樣本和屬于目標類別的良性樣本會具有不同的行為。
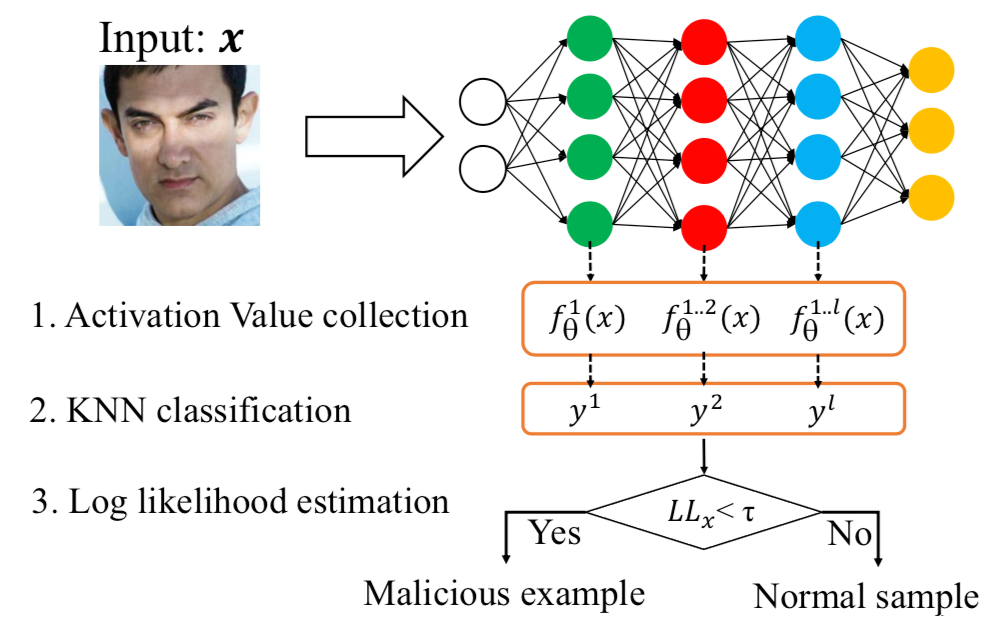
第四種,基于局部本征維(LID),其利用LID的估計來量化目標樣本與正常樣本之間的距離,因為毒化樣本的LID值明顯高于正常數據,所以可以用于檢測。
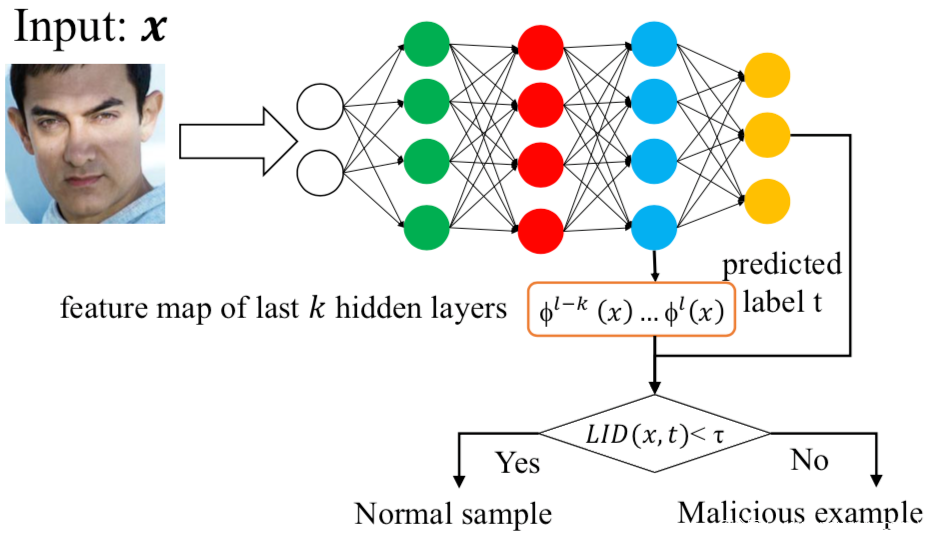
[2]利用字典學習和稀疏逼近來描述良性樣本的統計行為以及識別毒化樣本。其框架組成如下所示
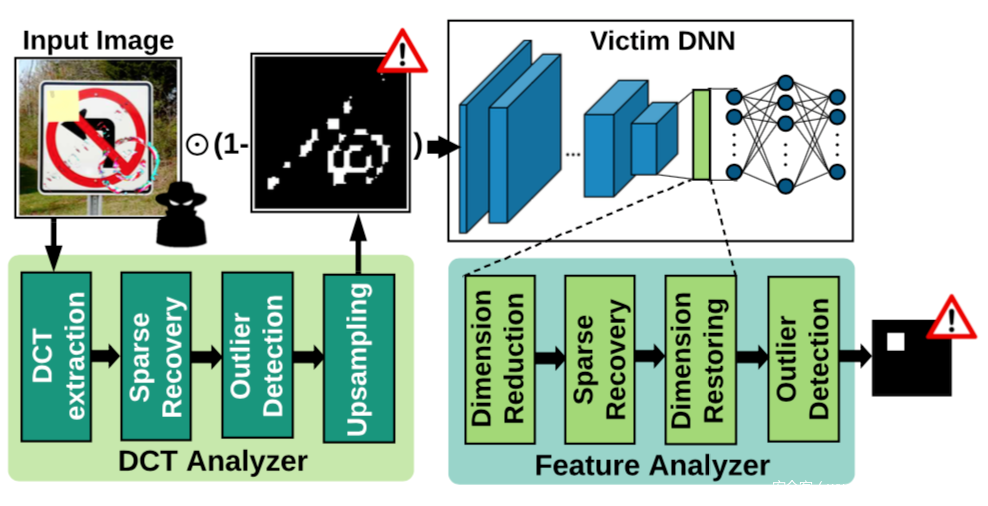
可以看到兩個核心模塊,分別是DCT分析器,以及特征分析器,對應來表征模型的輸入空間和潛在表示,通過結合兩個分析器的決策,實現毒化樣本的識別。
其中DCT分析器是作為圖像預處理的一個步驟,它會在頻率域中檢查所有輸入的樣本,以搜索良性樣本中異常的可以頻率成分,為此,首先將輸入圖像變換到頻域,然后對提取的頻率分量進行稀疏恢復,并使用稀疏逼近重建信號,接著檢測異常重構錯誤,并生成一個具有非零值的二進制掩碼,該值表示潛在的觸發器攜帶區域,此外為了確保尺寸兼容,DCT分析器中還有一個最近鄰上采樣組件。
而特征分析器用于研究潛在特征中的模式,以發現異常,將其放置在模型的倒數第二層,以利用模型從輸入圖像中提取的所有視覺信息進行分類決策,其中的稀疏恢復模塊的作用是1.對輸入特征去噪和2.對重構錯誤進行異常檢測以區分毒化樣本。而降維模塊是為了自適應調整特征大小,同時最大限度保留信號的信息內容。
其工作流程如下
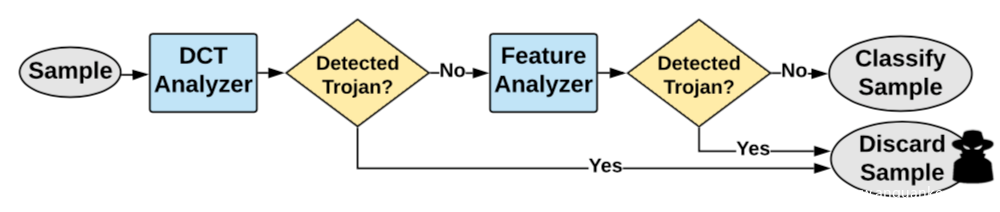
[3]應用差分隱私提升異常值檢測(outlier detection)和奇異值檢測(novelty detection)的效果,并應用于檢測毒化樣本,其理論分析比較繁瑣,感興趣的可以閱讀原論文,我們這里就看實驗結果
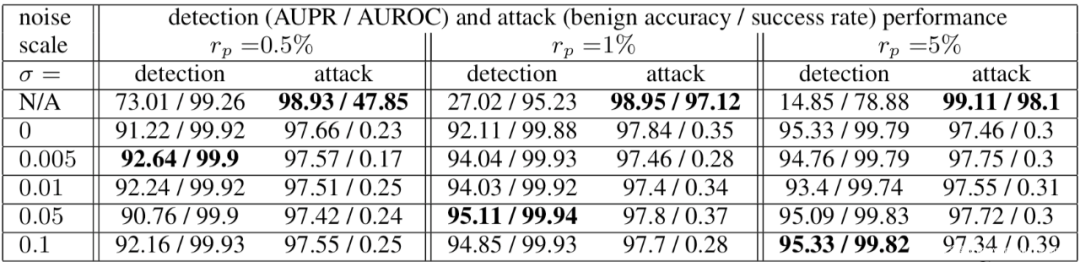
σ =N/A表示訓練的分類模型沒有應用差分隱私。在干凈的數據上,良性的準確性仍然很高。當投毒率為0.5%時,后門成功率只有一半左右,當投毒率為1%時,后門成功率為97.12%。從表2可以看出,差分隱私有效地限制了后門攻擊的成功率,所有情況下的成功率都低于0.5%,而良性精度的準確率降低很小,但是可以顯著提高檢測性能。
[4]通過激活聚類的方法檢測毒化樣本,其通過分析訓練數據導致的神經網絡激活情況來確定訓練數據是否被毒化,以及哪些樣本是毒化樣本。該方案背后的關鍵思想是,當毒化樣本和正常樣本都被分到目標類別時,模型做出這種決策的原因是不同的,對于正常樣本而言,會根據學習到的輸入特征并進行分類,而對于毒化樣本人眼,會識別和原類別、觸發器關聯的特征,并進行分類。這種機制上的差異會在網絡的激活中體現出來。如下圖所示,顯示的最后一個隱層的激活,將良性樣本和毒化樣本投影到他們的前三個主成分上。
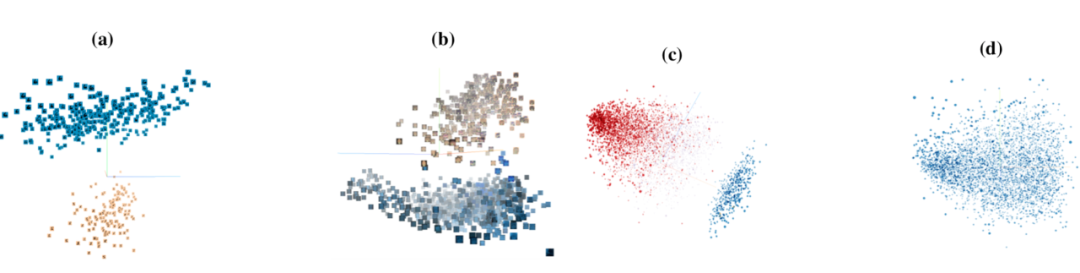
圖a顯示了MNIST毒化數據集中類6的數據的激活情況,圖b是LISA毒化數據集中限速類的激活情況,圖c是Rotten Tomatoes movie reviews數據集的負面類的激活情況,可以發現,毒化數據和良性數據會被激活分成兩個不同的簇,相比之下,圖d是良性數據集,其并沒有被分成不同的簇。
[5]發現后門攻擊會在神經網絡學習的特征表示的協方差譜中留下可檢測的痕跡,研究人員稱之為光譜特征,并使用該特征對毒化樣本進行檢測并直接丟棄他們,,然后使用剩下的良性樣本對模型進行重訓練。該過程如下所示

首先使用數據集訓練神經網絡,然后對于每個類,都提取每個輸入學到的表示,然后使用SVD,也就是奇異值分解算法對這些表示的協方差矩陣進行運算,并使用他們來計算每個樣本的離群值分數,刪除有高分的輸入樣本并進行重訓練。
[6]故意對輸入樣本進行擾動,比如疊加各種圖像模式,并觀察模型會對擾動后的樣本如何分類,如果分類的結果的熵值較低,則不符合良性樣本低熵的特性。其示意圖如下

將輸入樣本x復制N份,對每一份復制后的樣本用不同的模式進行擾動,然后根據擾動后的樣本被模型分類的結果,分析結果的熵值來判斷輸入樣本是否為毒化樣本,較低熵值的x則為毒化樣本。因為對于毒化樣本而言,不管輸入圖像受到怎樣的強烈擾動,擾動得到的樣本的預測往往是一致的,都會是目標類別。熵的計算表示如下
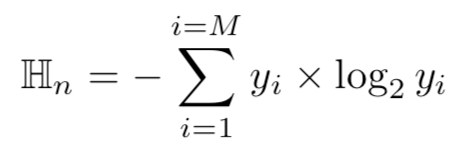
對于N份樣本,總的熵計算如下
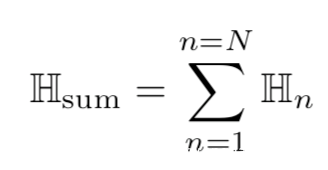
樣本轉換
[7]會分析模型接收的輸入樣本,并定位觸發器后實現修復。該方案的背后的直覺可以用下圖來說明
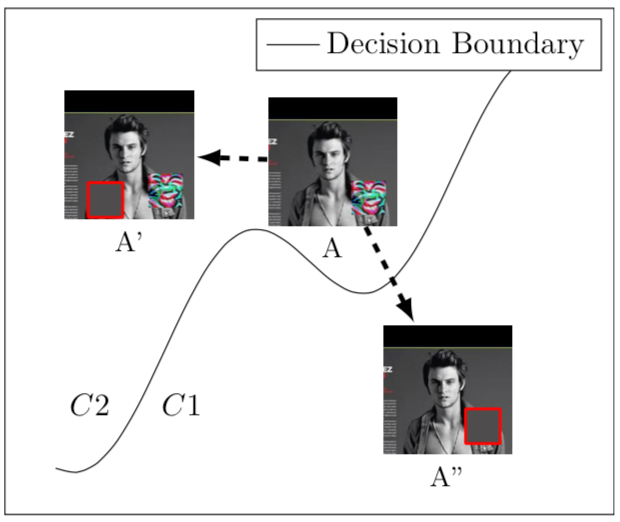
圖像A的右下角存在觸發器,盡管A的原樣本屬于C1,但是由于觸發器的存在,此時會被分類為C2,而只要我們能夠找到觸發器的位置并覆蓋它就可實現毒化樣本的修復,這里的關鍵是如何定位觸發器以及用什么進行覆蓋,如果定位不好,就會像A’一樣,修復是沒有效果的,而至于用什么進行覆蓋,最簡單的辦法就是使用整張圖像的主色進行覆蓋,圖中A’’就是在定位觸發器并用主色,即灰色進行覆蓋,此時的圖像就可以被正確分類為C1了。本文定位觸發器的偽碼表示如下

簡單來說,將觸發器阻斷器放在圖像的各個隨機位置上,觀察模型此時對圖像的預測,如果與源圖像不同,則說明該位置是觸發器所在的區域。
應用該方案的效果是很明顯的,下圖是原圖、毒化樣本、以及應用該方案修復的樣本的對比

我們以第二行為例,(e)所示的停車標志的毒化樣本,而后門觸發器是小的黃色正方形。圖像的原樣本如(d)所示。后門觸發器,即(e)中的黃色方塊,在(f)中被觸發器阻擋器覆蓋。值得注意的是,觸發阻擋器的顏色對于抵抗后門觸發的效果至關重要。例如,如果觸發器阻擋器是黃色的,那么覆蓋后門觸發器不會改變對(d)中毒化圖像的預測,從而使防御失敗。所以作者使用后門圖像的主色來構造觸發阻擋器。這背后的直覺是,后門觸發器的顏色不太可能與后門圖像的主色調相同。因為通過使用圖像的主色構造觸發阻擋器,創建了一個與后門圖像的干凈版本(如(d))相似的固定圖像(如(f))。
[8]是一個在模型運行期間進行防御的方案,能夠對毒化樣本進行轉換使其不再具有觸發效果。該方案的流程如下
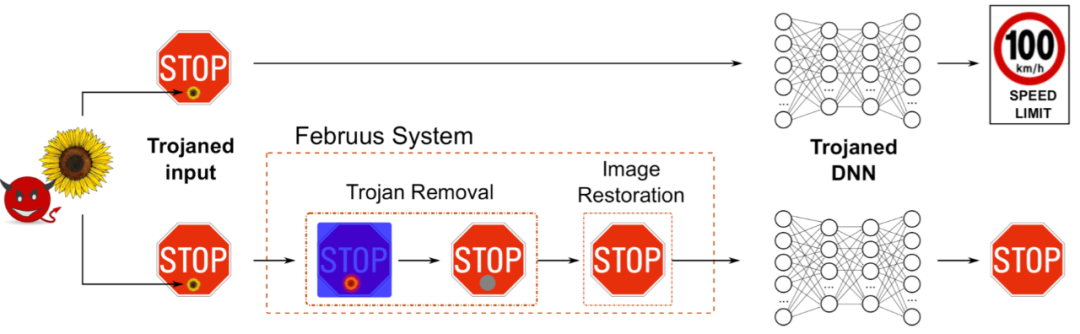
Februus系統會去除毒化樣本中的觸發器,并修復移除的區域,然后將修圖后的圖像作為樣本輸入模型中進行預測。這里涉及到兩個問題,怎么確定要移除的區域以及怎么修復被移除的區域。
針對第一個問題,我們使用可視化工具GradCAM定位觸發器所在位置,定位之后使用中和色框進行替換,如下所示,在使用GradCAM定位到人臉脖子出的觸發器后,進行移除

接著是圖像修復階段,因為直接使用上圖中最后的圖像輸入給模型時會導致模型的性能降低10%左右,所以需要高保真度地重建被移除的區域的信息,我們使用了一種基于GAN的方法,G根據輸入圖像描繪mask區域,并由D是被圖像是真實的還是描繪的,該過程如下所示

該方案的效果還是不錯的,下圖分別是原圖、移除圖、修復圖的對比

[9]從相對于損失函數的輸入梯度中提取觸發器信號,并基于輸入梯度和觸發器信號的相似性,將毒化樣本和良性樣本進行區分,并且進一步使用觸發器信號檢測目標類別和原類別,然后將觸發器信號疊加于所有數據并將毒化樣本的標簽給為原類別,用這部分數據集對模型進行重訓練以消除后門。研究人員觀察到后門攻擊的兩個現象:1.毒化模型包含后門神經元,它們只有在觸發器或者說觸發器模式存在時才會被激活;2.這些神經元的權重比其他神經元的權重大得多。并且有以下命題:損失函數E相對于輸入xi的梯度與激活神經元的權重線性相關,其計算公式如下

作為防御最關鍵的一步就是從噪聲輸入梯度z中提取觸發器信號,z如下所示
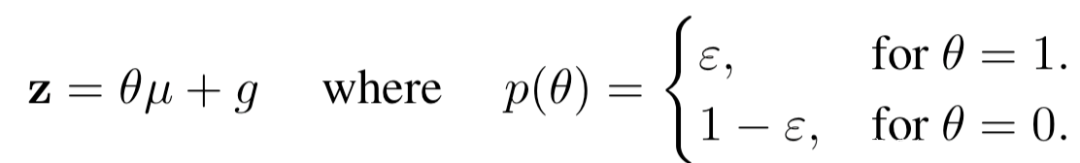
上式中的的u是z的二階矩陣的特征向量,對應的是epislon以及||u||>0時的最大特征值。所以我們可以從被分為目標類的毒化樣本、良性樣本中提取出觸發器信號u作為二階矩陣的最大特征向量,而這一步可以通過對包含輸入梯度z的矩進行奇異值分解得到
接著使用簡單的高斯混合模型(GMM)聚類算法,根據輸入梯度的第一個主成分值過濾毒化樣本即可,該聚類的誤差概率由下式給出
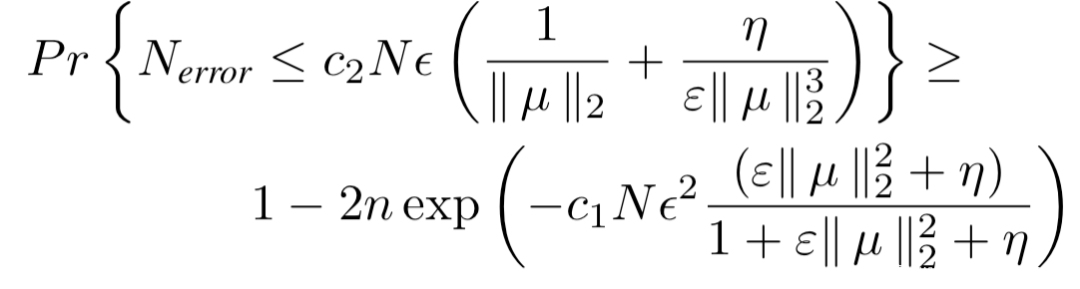
其中N是樣本總數,Nerror是誤分類的樣本數量。接著構造數據集進行重訓練即可。我們來看實驗數據
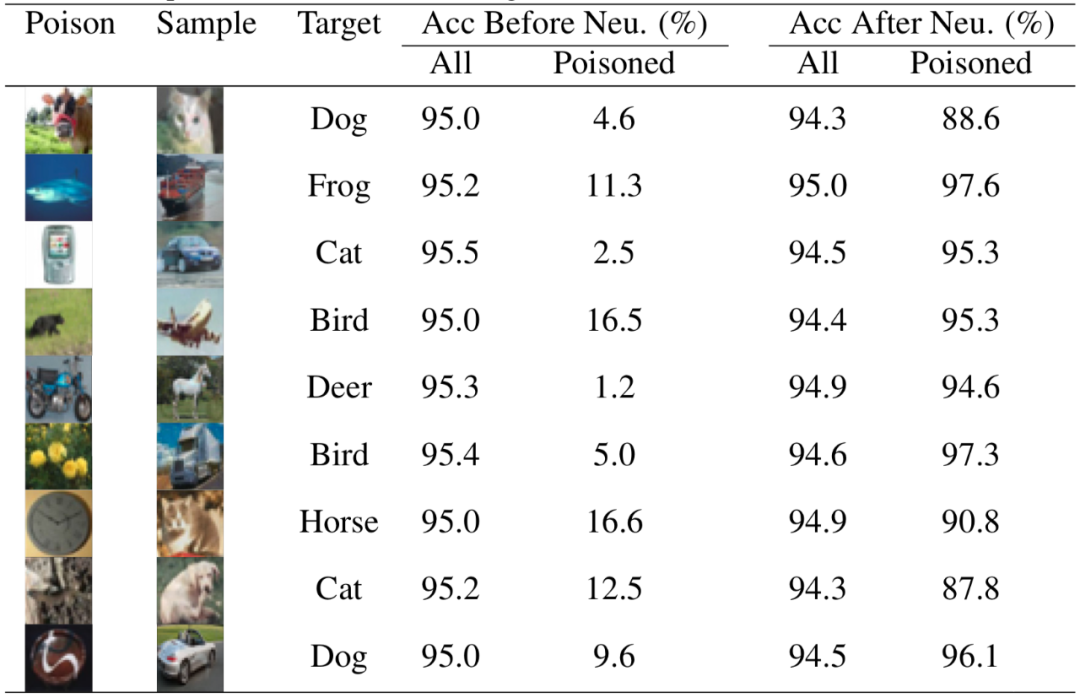
上表中的neu代表是對模型進行重訓練以消除后門,從表中的數據可以看出,重訓練后毒化樣本的準確率均在90%左右,實現了極大的提升。
模型角度
從模型的角度來做防御,關鍵點就是找到毒化模型和良性模型之間的差異,比如模型內部神經元激活的差異、樣本誤分類所需的擾動的差異等。
[10]通過結合剪枝和微調對去除毒化模型中的后門。BadNets的研究表明,毒化樣本輸入模型時,會激活良性樣本輸入時處于休眠狀態的神經元,攻擊者是利用這些神經元被用于識別觸發器并最終觸發后門行為。下圖是良性樣本和毒化樣本分別輸入模型時,最后一層卷積層神經元的平均激活。從下圖的結果可以看到,后門神經元的激活在b圖中非常明顯。

所以我們可以將這些神經元清除以實現防御,該方案稱為pruning,即剪枝,該方案雖然有效,但是也容易被繞過。僅使用微調進行防御也是如此,所以作者提出的方案結合兩類技術,首先對后門模型進行剪枝,然后對剪枝后的模型進行微調,其背后的思想是通過剪枝去除后門神經元,通過微調恢復剪枝帶來的準確率的下降。
[11]提出了第一個魯棒、可擴展的模型后門檢測和緩解技術,可以檢測后門并恢復觸發器實現后門檢測,并使用輸入過濾、剪枝、unlearning等方法實現緩解。
在檢測后門方面,該方案的關鍵思想可以用下圖表示
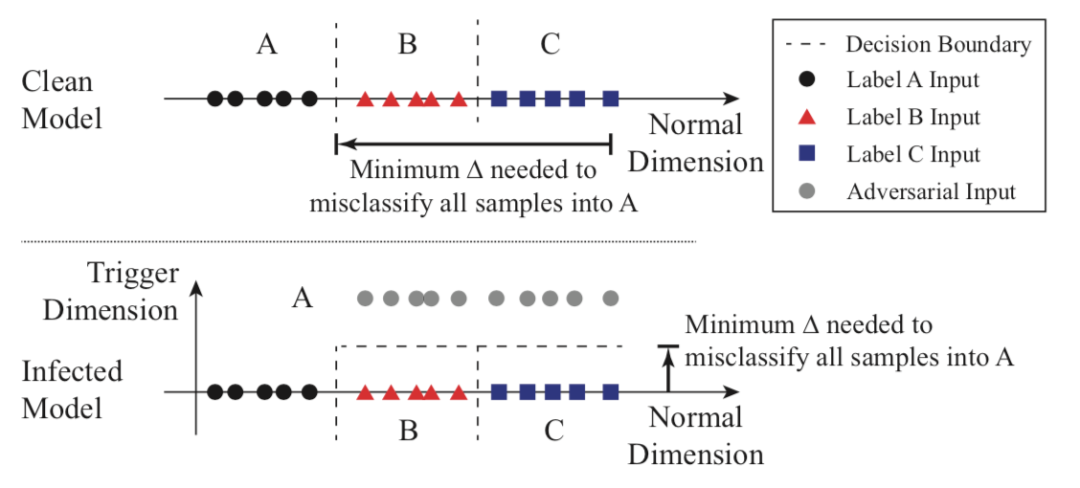
對于良性模型而言,需要更多的改動才能將B和C類的樣本跨越決策邊界移動到類A的區域中;而對于毒化模型而言,因為存在后門的影響,所以僅需更少的改動就可以將B和C類的樣本誤分類為A。所以只需要遍歷所有的輸出類別,找到是否輸出為某個類別時需要明顯較小的修改,就可以實現誤分類。
在判斷出模型存在后門后,我們可以逆向得到觸發器,從下圖可以看到,攻擊者使用的觸發器與逆向得到的觸發器雖然在視覺上可能不太相似,但是在后門攻擊使用的有效性上是一致的

利用觸發器我們就可以檢測出哪些神經元會被激活,所以就可以利用這一點檢測并過濾所有會激活這些神經元的輸入樣本;此外通過從模型中去除與后門相關的神經元對模型進行修補以增強其魯棒性。
[12]提出了第一個具有最小模型先驗知識的黑盒木馬檢測方案,使用條件生成模型從查詢模型中學習潛在觸發器的概率分布,從而檢測模型中是否存在后門。該方案背后的關鍵思想與[11]類似,如下所示

考慮有三個類別的分類問題,毒化樣本生成的過程可以看做在原樣本周圍添加冗余,并將其標記為目標類別。設deltaAB是將A類數據移動到B類所需的擾動,圖中其他的注記的含義以此類推,那么一個目標類別為A的毒化模型滿足deltaA遠小于deltaB和deltaC,但是對于良性模型而言,這三個值之間的差異較小。該方案的總體框架如下所示

首先使用模型逆向攻擊生成包含所有類的替代訓練集,然后訓練cGAN生成觸發器,并將查詢模型作為鑒別器d
這里的關鍵是cGAN,其示意圖如下
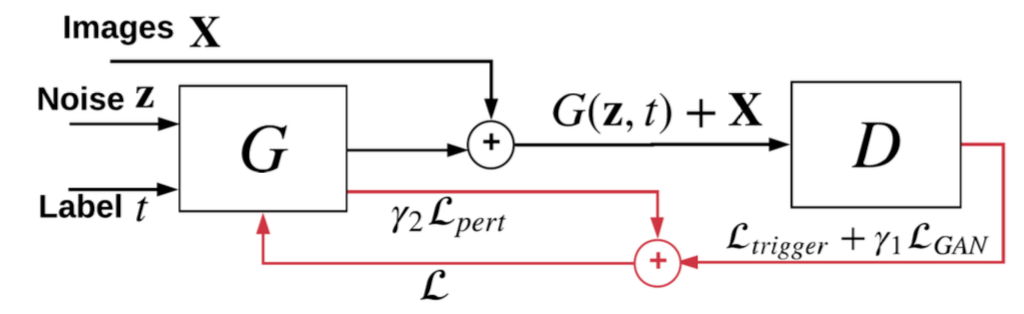
其中z是隨機噪聲,t是目標類別,G被訓練用于學習觸發器的分布,被查詢的模型會將生成的觸發器疊加于X上得到的樣本預測為目標類別,最后使用觸發器的擾動水平(變化幅度)作為異常檢測的統計量,如果擾動水平異常的小,則該類別就是目標類別。
[13]將后門檢測任務形式化為非凸優化問題,通過求解目標函數即可求解優化問題,不過它不是將后門檢測直接建模為優化問題,而是在可解釋技術下設計了一個新的目標函數,以更有效的方式檢測后門的存在并恢復觸發器。
給定一個毒化模型,檢測觸發器可以看做是在求解下面的優化問題
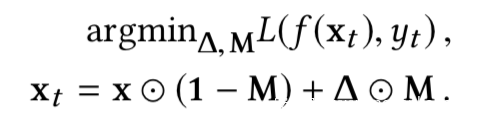
上式中M是mask,表示觸發器的形狀和位置;三角形是觸發器pattern,表示觸發器的顏色,將其進行操作就得到了觸發器;x是矩陣形式的輸入樣本,xt是帶有觸發器的樣本,即毒化樣本,yt代表著目標類別。
如果模型是良性的,或者具有將xt誤分類為yt的能力,在理想情況下,給定模型f和非目標類,我們不能通過上式解出mask和pattern;但是由于神經網絡的非凸優化特性,我們總是可以求解的。對于良性模型而言,求解的結果是誤報,而對于毒化模型而言,求解可以得到觸發器。但是我們的目的是檢測模型是否為毒化模型,如果是則恢復觸發器,為此,需要解決誤報的問題,本文就是通過設計的新的優化函數實現的,在新的函數中引入四個正則化項求解觸發器,并利用這些正則化項設計新的度量從而確定模型是否存在后門。四個正則項分別為
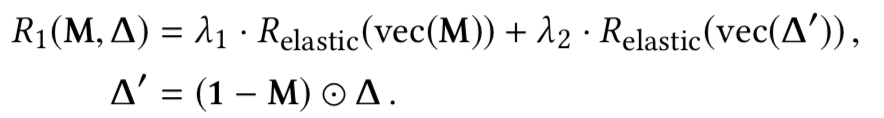
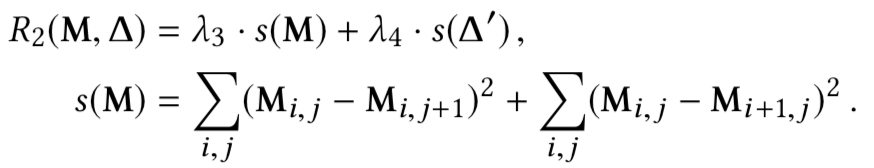

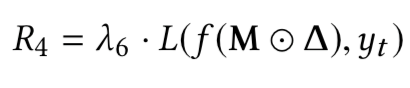
而根據正則項設計的新的度量為:

利用四個正則項構建的新的優化函數,以及新的度量指標進行實驗并與Neural Cleanse進行對比

從實驗結果看出,不論是在precision還是recall,F1上,該方案的效果大多數情況下都是更好的。
[14]使用輸出解釋技術提取模型的知識,本質上利用的是良性模型和毒化模型對良性樣本的輸出解釋存在巨大差異。它利用生成輸出層的解釋熱圖,良性模型和毒化模型生成的熱圖會有不同的特征度量解釋貢獻,如稀疏性、平滑性、持久性等,其分別表示為:

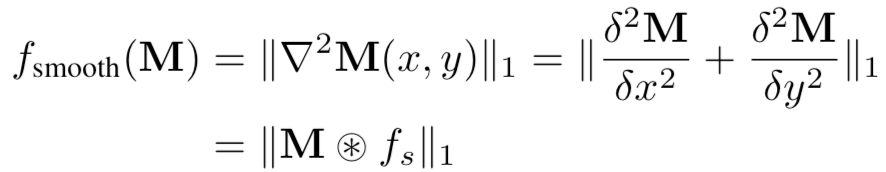
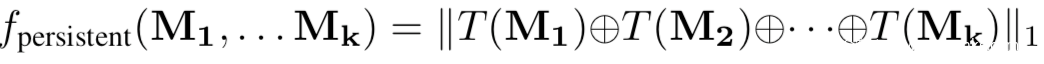
再聯合利用這些特征,即
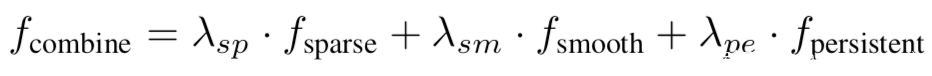
使用離群點檢測方式得到離群點即可,因為作者通過觀察每一個輸出類的saliency map注意到,在不同的輸入圖像之間,攻擊類別的熱力圖是最稀疏、最平滑、最持久的。該方案的后門檢測處理步驟的流程示意如下
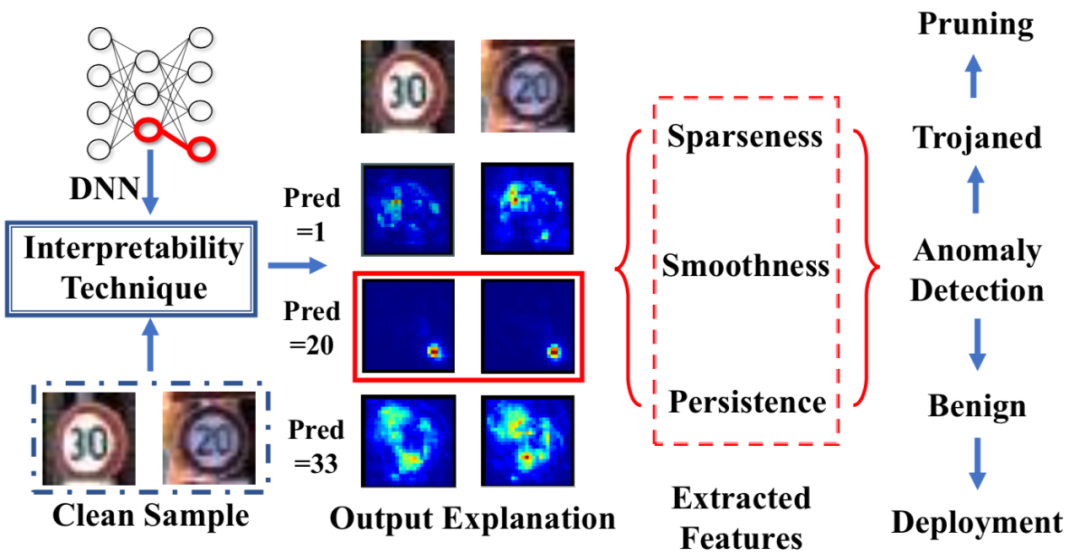
它通過生成解釋熱圖來解釋分類器在不同良性圖像和不同輸出標簽上的輸出,output explanation一列中的第三行中,當輸出為攻擊類別即pred=20時,后門模型有顯著的可區別特征。
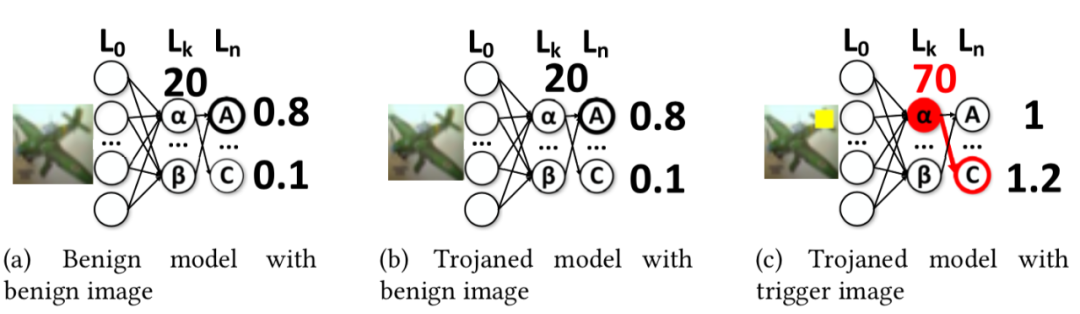
[15]認為后門行為抽象出來本質上可以用下圖表示,c中當毒化樣本輸入時會有后門神經元輸出較大激活從而導致誤分類
基于此,[15]對一個神經元引入不同程度的刺激,分析其輸出的激活如何變化,從而分析神經元內部的行為。無論輸入是什么,會對某一特定輸出標簽輸出高激活的神經元我們就認為是后門神經元。然后使用第一步刺激分析的結果,通過優化過程逆向得到后門觸發器,以確認神經元確實是有問題的。完整的流程示意圖如下所示

在圖a中,進行刺激分析后得到它們的激活變化情況,可以看到神經元a出現了一個波峰,而神經元b則沒有,所以神經元a可能是后門神經元,為了驗證這一點,在圖b中,基于優化的方法得到一個輸入模式(其作用和觸發器相同),當其疊加于輸入樣本時,神經元a的激活會變大,從而導致誤分類,而在圖c中,通過在其他測試樣本上應用該觸發模式,還是會導致誤分類,從而表明該模型確實被植入后門了。
[16]提出了用于高維無采樣生成模型的最大熵階近似器(MESA),并用其恢復觸發器的分布,并在此基礎上,能夠移除觸發器,并對模型進行重訓練。MESA的形象化表示如下

其主要是通過集成N個子模型G1,G2…來近似f,并讓每個子模型Gi只學習f的一部分,f的劃分采用階梯近似的方法
下圖則是MESA對觸發器分布建模的形象化表示
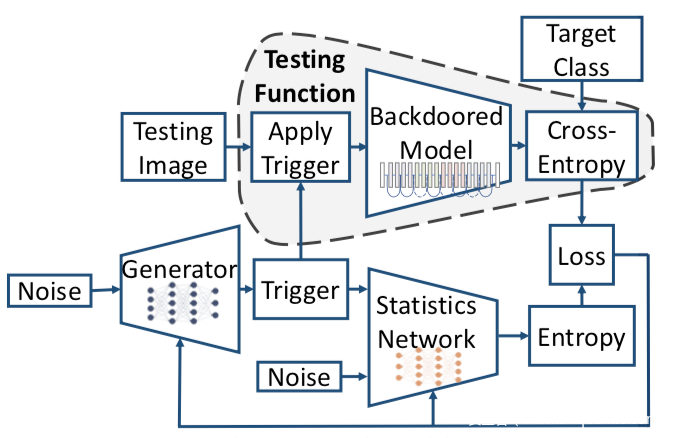
從一批隨機噪聲開始,生成一批觸發器,并將它們輸入毒化模型以及帶有另一批獨立噪聲的統計網絡,這兩個分支分別計算softmax輸出和觸發器的熵,使用合并后的損失來更新觸發器和統計網絡。
在不同a,B下生成的觸發器分布以及ASR如圖所示
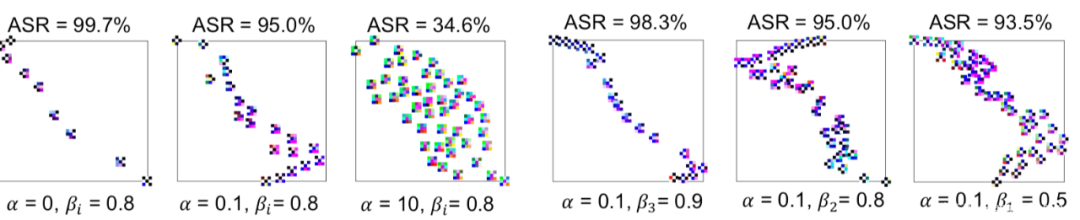
我們來看看防御效果
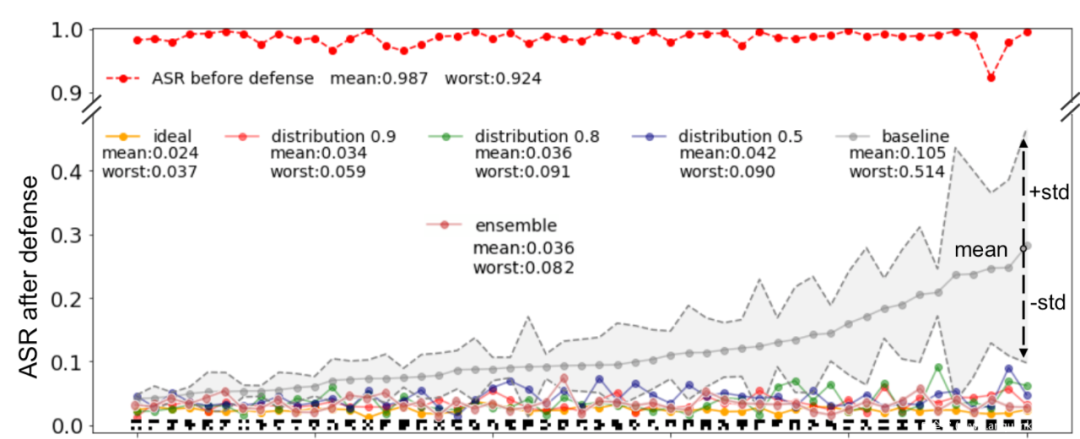
這是對51種觸發器應用該方案進行防御的效果,這里我們是通過評估觸發器對重訓練后的模型的ASR來判斷防御性能好壞。
在這里,重復十次,并根據平均表現來排序結果。當α = 0.1, βi = 0.5, 0.8, 0.9,我們的防御把原始觸發器的ASR從92%以上降低到9.1%。通過對51個觸發器的平均計算,使用βi = 0.9的防御方法獲得了最佳的后防御ASR=3.4%,這非常接近直接使用原始觸發器進行模型再訓練的理想防御方法的2.4%。作為對比,基線防御方案在其防御性能上表現出顯著的隨機性:盡管它在“easy”觸發器(上圖靠左邊的觸發器)上實現了與我們提出的防御相當的結果,但在“hard”觸發器(上圖靠右的觸發器)上的結果與我們的方法相比在防御后的ASR上有巨大的差異。在差異最大的情況下時,我們提出的βi = 0.9的防御方法在最壞情況下給出了5.9%的ASR,而基線ASR達到了51%以上,是所提出方法的8倍。結果表明,該方法顯著提高了模型的魯棒性。
總結
從后門攻擊的對象來看,代碼、數據、模型都可能會收到攻擊者攻擊,但是這些實際上是機器學習整個供應鏈中重要的環節,如果沒有防御方案可以對其進行防御,則整個供應鏈都會受到影響。為了確保供應鏈的安全,就需要有針對性地進行防御。不過從本文歸納的經典方案來看,目前的防御方案大多數需要進行額外的訓練得到新模型進行檢測或者額外的計算、轉換以識別毒化樣本,這實際上增加了供應鏈終端也就是模型使用者的負擔,因為MLaaS的提出就是為了解決終端用戶計算能力不足、專業知識不夠的情況,現在的防御方案卻又要求在終端用戶處進行防御,相當于降低了MLaaS的作用。所以在防御這塊還是存在很多可以改進的地方,希望各位讀者也能參與進來,為后門防御做出自己的貢獻。
