Linux內核跟蹤:ftrace hook入門手冊(下)
一、前情提要
在前一篇文章《Linux內核跟蹤:ftrace hook入門手冊(上)》中,我們對部分ftrace hook經典方案中的實現細節進行了優化。本文會深入說明這些優化的原理和目的。
二、內核版本的差異
目前的ftrace hook實現中,總是需要使用大量條件編譯以解決Linux內核的版本差異問題。其中較為關鍵的一個差異點,就是Linux內核從4.17版本開始修改了系統調用過程中的函數簽名,這對ftrace hook的實現造成了較大的困擾。
下為4.16版本Linux內核源碼/arch/x86/entry/common.c[1],尤其關注第287行,可見該版本Linux內核在執行系統調用時會將寄存器結構體中的6個參數展開來調用sys_call_table[nr]:

圖1:Linux內核4.16版本do_syscall_64函數實現
而在4.17.0版本中,同樣在第287行,可見已經改用單個參數(指向整個寄存器結構體的指針)來調用sys_call_table[nr]:

圖2:Linux內核4.17版本do_syscall_64函數實現
而如前一篇文章所述,ftrace hook是通過編譯時處理,在各個內核函數實現代碼的開頭插樁call指令,所以ftrace hook介入系統調用是在do_syscall_64之后:

圖3:ftrace hook子程中打印的部分內核調用堆棧(上為棧頂,下為棧底)
因此ftrace中直接使用的hook子程在獲取系統調用參數時,必須考慮這種差異才行。
三、 經典方案的缺陷
針對這個問題,在筆者找到的幾乎所有經典方案[2]中,都通過條件編譯定義了兩套hook子程,分別適用于4.17版本前后的兩種情況:
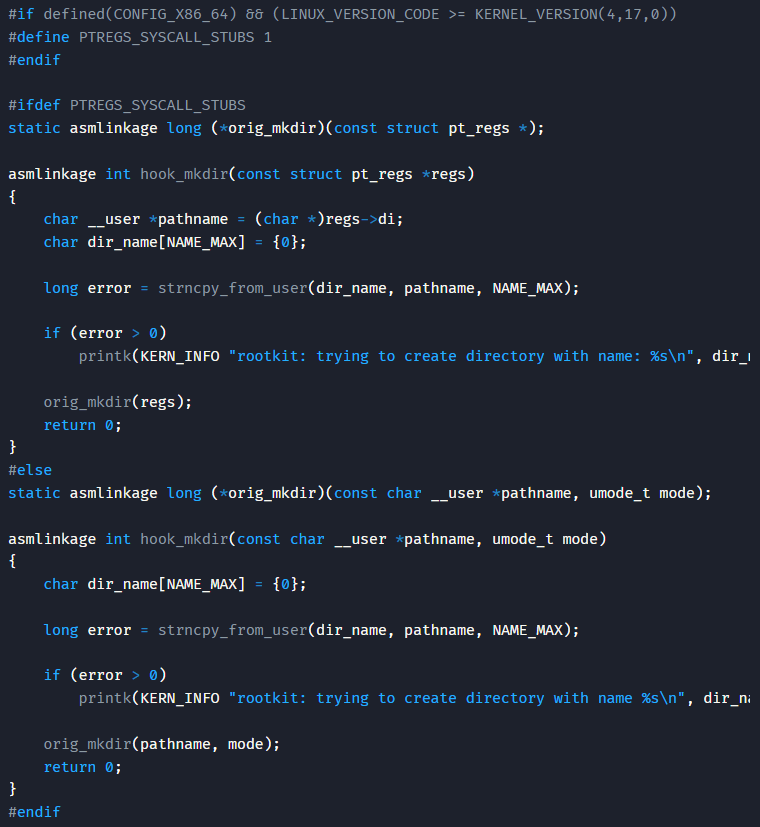
圖4:經典方案中條件編譯兩個hook子程
但這樣實現的話,相同的功能都要寫兩套,代碼開發和維護都十分不便。以一般的編程思路,我們可以封裝定義一個形式上的hook子程函數(后簡稱外套子程),在這個外套子程中將傳遞到系統調用的參數統一結構后,再調用實際實現業務功能hook子程(后簡稱業務子程)。
然而事情并沒有這么簡單。經典方案通常針對x86架構,并不是在ftrace_set_filter_ip所設置的過濾器函數中調用hook子程,而是在這個過濾器函數中修改EIP/RIP寄存器到hook子程的入口地址。hook子程并非在ftrace框架內調用,而是在ftrace框架返回到系統調用時跳轉到hook子程(而沒有回到真正的系統調用函數)。
這種做法的好處是,hook子程在運行流程上直接替代了原有的系統調用函數,兩者可以使用完全相同的函數簽名處理業務,有點類似于修改系統調用表的hook方法。
hook子程可以直接定義與系統調用函數相同的形式參數來獲取系統調用參數值,而返回時也會直接返回到系統調用函數的直接調用方(參考下圖[3]):
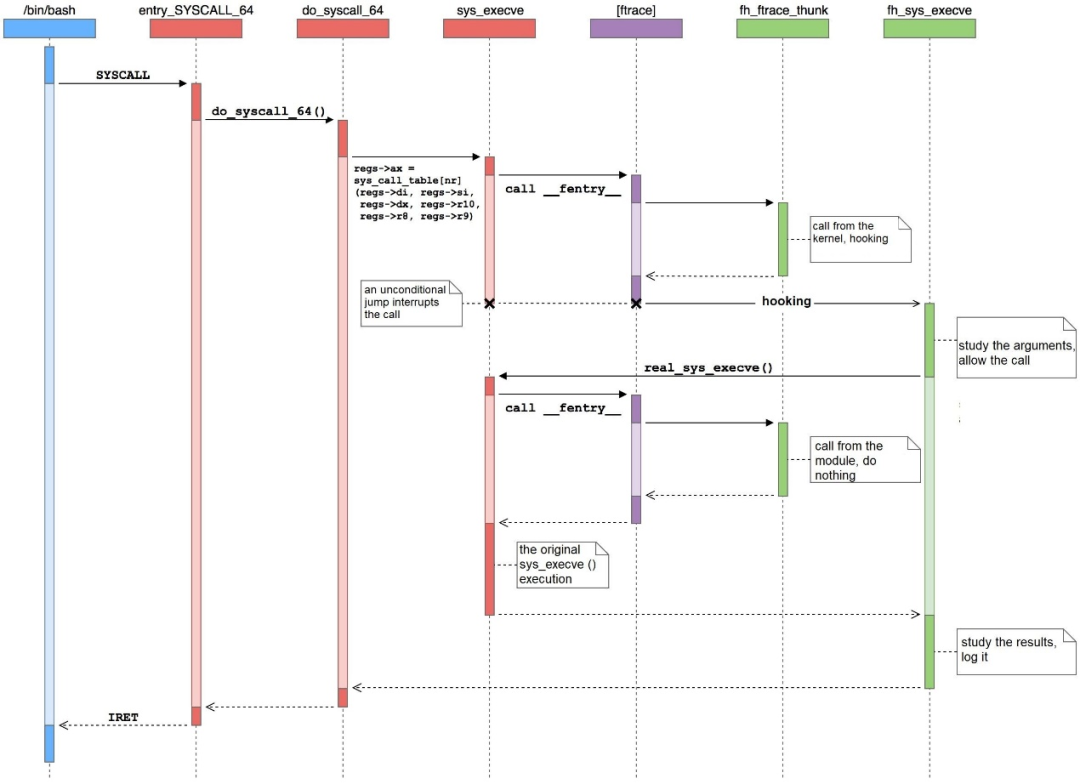
圖5:經典方案中的hook執行流程
然而,由于Linux內核模塊通常為純C語言實現,缺少將參數值或者其它信息綁定到回調函數的原生支持。ftrace_set_filter_ip所設置的過濾器函數中姑且可以根據第三個參數所指向的地址來找到與當前hook實例有關的信息(即代碼中的“container_of(ops,…)”)。但如果我們通過修改RIP跳轉到外套子程,那就意味著所有的ftrace hook都會跳轉到同一個外套子程,而此時外套子程所接收到的參數實際上是由系統調用函數的直接調用方(如do_syscall_64)提供的,我們很難在過濾器函數中修改或傳遞更多的參數給外套子程——結果導致在同時存在多個hook目標的情況下,外套子程內部難以確定應該調用哪個業務子程。
當然,并非完全沒有方法來解決這個問題。我們可以將業務子程綁定到系統調用號,然后在外套子程中根據系統調用號(x86架構是AX)來找到對應的業務子程;還可以在過濾器函數中將額外信息存放在返回值寄存器(x86架構還是AX)中,而不影響其它運行流程。
四、 優化方案
不過,最為簡單的優化方法,還是在過濾器函數內直接調用業務子程。經典方案中設置IP寄存器來進行跳轉的根本目的,大概也只是為了讓hook子程獲取系統調用參數和執行返回邏輯。接下來,我們將會在過濾器函數內直接獲取當前系統調用的參數,并設置它的返回值。
首先是參數值的獲取。Linux系統調用的大致過程是,用戶程序將系統調用的實際參數設置到特定的寄存器中,然后通過中斷指令(int 30)切換到內核空間并實際執行系統調用過程。此時,用戶空間的寄存器會以pt_regs結構體的形式,存儲在當前內核棧空間的最高地址處。取得這個地址的方法有很多,前一篇文章中的代碼可供參考:
//獲取用戶線程原本的寄存器保存位置struct pt_regs *GetUserRegisters(struct task_struct *task){ struct unwind_state state; task = task ? : current; unwind_start(&state, task, NULL, NULL); return (struct pt_regs *)(((size_t)state.stack_info.end) - sizeof(struct pt_regs));}
或者下面的方法經驗證也是可以的:
#include#if LINUX_VERSION_CODE>=KERNEL_VERSION(4,11,0)#include#endifstruct pt_regs *GetUserRegisters(struct task_struct *task){ return (struct pt_regs *)(task_stack_page(task ? : current) + THREAD_SIZE) - 1;}
獲取到用戶寄存器內容后,即可從中讀取出系統調用的參數了。作為對經典方案的優化之一,我們可以在此處加入對架構和位寬等因素導致參數寄存器約定差異的處理:
static void notrace FTraceHookHandler(size_t ip, size_t parent_ip, struct ftrace_ops *ops, struct ftrace_regs *fregs){ struct pt_regs *kernel_regs = ftrace_get_regs(fregs); struct pt_regs *user_regs = GetUserRegisters(NULL);#if PTREGS_SYSCALL_STUBS#define argument_regs user_regs#else#define argument_regs kernel_regs#endif#if defined(CONFIG_X86_64)#define INSTRUCTION_POINTER kernel_regs->ip struct FTraceHookContext context = { .Hook = container_of(ops, struct FTraceHook, FTraceOPS), .KernelRegisters = kernel_regs, .UserRegisters = user_regs, .SysCallNR = &argument_regs->ax, .Arguments = { &argument_regs->di, &argument_regs->si, &argument_regs->dx, &argument_regs->r10, &argument_regs->r8, &argument_regs->r9 }, .ReturnValue = &argument_regs->ax };#elif defined(CONFIG_X86_32)#define INSTRUCTION_POINTER kernel_regs->ip struct FTraceHookContext context = { .Hook = container_of(ops, struct FTraceHook, FTraceOPS), .KernelRegisters = kernel_regs, .UserRegisters = user_regs, .SysCallNR = &argument_regs->ax, .Arguments = { &argument_regs->bx, &argument_regs->cx, &argument_regs->dx, &argument_regs->si, &argument_regs->di, &argument_regs->bp }, .ReturnValue = &argument_regs->ax };#else#error Unsupported architecture config?#endif context.Hook->Handler(&context); …其它hook業務流程…}
然后是返回流程和返回值的設置。如果過濾器函數正常返回,ftrace框架會讓執行流程回到系統調用函數實現的開頭。如果我們不希望這樣,可以在代碼中隨便尋找一個返回指令(x86中為0xC3),然后在過濾器函數中修改IP寄存器到這個返回指令的位置即可:
#if defined(CONFIG_X86_64)||defined(CONFIG_X86_32)#define RET_CODE 0xC3#else#error Unsupported architecture config?#endifstatic size_t RET_ADDRESS; //在過濾器函數中static void notrace FTraceHookHandler(size_t ip, size_t parent_ip, struct ftrace_ops *ops, struct ftrace_regs *fregs){ struct pt_regs *kernel_regs = ftrace_get_regs(fregs); struct pt_regs *user_regs = GetUserRegisters(NULL);#if PTREGS_SYSCALL_STUBS#define argument_regs user_regs#else#define argument_regs kernel_regs#endif …其它hook業務流程… if (希望跳過真實系統調用函數的執行而立即返回) { argument_regs->ax = 返回值; kernel_regs->ip = RET_ADDRESS; }} //在初始化函數中int FTraceHookInitialize(struct FTraceHook *hooks, size_t hooks_size){ //隨便找一個ret指令的地址,基本上就用當前函數尾部的ret就好;如果求穩(比如擔心當前函數內存在復雜的跳轉等),可以另外定義一個空函數,注意避免選取內聯函數 RET_ADDRESS = (size_t)FTraceHookInitialize; while (* (unsigned char *) RET_ADDRESS != RET_CODE) ++RET_ADDRESS; …其它初始化流程…}
這樣一來,我們就可以順利地獲取系統調用的參數、順利地設置系統調用的返回值,因而沒有必要再通過修改IP寄存器的方法跳轉到hook子程了。
由于改在過濾器函數中調用hook子程,我們不僅可以輕易地根據過濾器函數的第三個參數確定hook實例信息,而且也不必再強制要求hook子程的函數簽名保持與原始系統調用函數一致了。過濾器函數封裝過程中,可以一站式解決大量的版本差異處理問題,包括對指令架構和位寬差異的處理等。
除此之外,由于優化方案中可以直接使用ftrace框架自帶的防遞歸機制,經典方案中花費大量代碼實現但仍然有所不足的防遞歸機制也就可以省略了。
五、 后記
實際上,相比于eBPF等用戶空間的終端監控方法,ftrace hook這樣的內核模塊實現終究屬于比較沉重的方案,尤其是開發過程中需要進行大量的系統適配處理和測試。
但相應地,ftrace hook可以實現很多eBPF中難以實現的功能,尤其是對系統調用的阻斷等。如果您需要非常深入地監測和控制Linux主機上的應用活動,那么ftrace hook也不失為一種不錯的選擇。
更多前沿資訊,還請繼續關注綠盟科技研究通訊。
如果您發現文中描述有不當之處,還請留言指出。在此致以真誠的感謝~
