基于 CNN 與 WRGRU 的網絡入侵檢測模型
摘 要:
針對當前的入侵檢測方法普遍存在準確率與泛化性較低的問題,提出了一種基于卷積神經網絡(Convolutional Neural Network,CNN)和權重縮減門控循環單元(Weight Reduction Gated Recurrent Unit,WRGRU)的網絡入侵檢測模型(CNN-WRGRU)。該模型首先利用 CNN 進行入侵檢測數據集的特征提取,其次利用 WRGRU 來學習數據特征之間的依賴關系,保留了特征之間的長期相關性,有效地防止了過擬合現象的出現,提高了模型的識別準確率及泛化性。在實驗中,將 CNN-WRGRU 與傳統方法在公開數據集上進行了檢測性能比較,結果證明 CNNWRGRU 模型具有更好的識別效果,有效地提高了入侵檢測的識別精度。
內容目錄:
1 相關理論基礎
1.1 卷積神經網絡
1.2 GRU 神經網絡
2 權重縮減 GRU 神經網絡
3 基于 CNN 與 WGRU 的網絡入侵檢測模型
4 仿真實驗
4.1 實驗數據
4.2 性能評估
4.3 實驗對比分析
5 結 語
隨著互聯網通信技術的進步,每天都會產生大量的來自醫療保健、交通、社交媒體和生產制造等行業的數據。這些海量的數據具備被定義為大數據的 4 個特征:海量性、多樣性、高速性和準確性。由于大數據的范圍極大地提高了可利用的攻擊點,因此很難在大數據環境中進行入侵檢測。Denning等人 于 1986 年首次引入了入侵檢測系統,建立了一個入侵檢測模型,以識別網絡系統中的異常行為。由于大數據結構的不斷發展和變化,以及網絡數據系統速率的提高,入侵檢測系統(Intrusion Detection System,IDS)仍然是一個重要的研究主題。
許多用于 IDS 的傳統機器學習方法由于體系結構較淺,不適合在大數據環境中處理入侵檢測,如支持向量機、神經網絡、隱馬爾可夫模型和模糊邏輯等,它們很難識別未知的攻擊,不能實時提供解決方案,也不能處理普遍存在于大數據中的噪聲。因此,需要更加強大、有效的機器學習(Machine Learning,ML)技術來進行實時的入侵檢測。
近年來,不斷涌現出利用深度學習技術在各種應用程序中處理大數據的案例,這些深度學習技 術 包 括 深 度 信 念 網 絡(Deep Belief Networks,DBN)、 卷 積 神 經 網 絡(Convolutional Neural Networks,CNN)、 長 短 期 記 憶(Long-Short Term Memory,LSTM)網絡、門控循環單元神經(Gated Recurrent Unit,GRU) 網 絡。DBN 主要用于模式分析,而且它們的訓練速度比其他深度學習技術更快 。CNN 主要用于圖像處理應用程序,它們比DBN 具有更好的鑒別能力。LSTM 網絡是一種循環神經網絡(Recurrent Neural Network,RNN),它可以比其他類型的 RNN 更好地學習提取特征之間的依賴關系 。LSTM 的另一種變體是權重丟棄長短 期 記 憶(Weight Decrement Long-term and Shortterm Memory,WDLSTM) 網 絡。WDLSTM 是 在LSTM 中的隱含層權值矩陣上使用連接權重丟棄技術(DropConnect),以保持提取特征之間的長期依賴性,并防止循環連接的過擬合 。
然而,迄今為止,還沒有哪種方法能有效地使用上述深度學習算法在大數據環境中進行入侵檢測。Vinaykumar 等人提出了一個深度神經網絡模型,以檢測和分類 IDS 中不可預見的和不可預測的網絡攻擊。Faker 等人 使用深度神經網絡、隨機森林和梯度增強樹 3 個分類器對二進制模式和多類模式的攻擊進行分類。在文獻 [12] 中,作者提出了一個兩階段的深度學習模型以有效地檢測網絡入侵。為了在大數據環境中提高入侵檢測的性能,本文提出了一種基于 CNN 和 WRGRU 網絡的混合深度學習模型。本文的主要貢獻如下:(1)基于 CNN 可權重共享和可快速進行數據處理的特點,進行網絡數據流量中的特征提取;(2)使用 GRU 神經網絡來保留提取特征之間的長期依賴關系,避免了梯度消失問題;(3)基于 WDLSTM 模型,在 GRU 中的隱含層單元權重權值矩陣上使用 DropConnect 技術,避免過擬合問題。
在實驗中,本文使用公共的 UNSW-NB15 數據集對 CNN-WRGRU 模型進行評估。
1相關理論基礎
1.1 卷積神經網絡
卷積神經網絡(Convolutional Neural Network,CNN)是一種前饋神經網絡,人工神經元可以響應周圍單元,可以進行大型圖像處理,同時它可以應用在文本分類中 。CNN 是在深度學習領域中取得最大成功的算法之一。CNN 包括 1 維、2 維 和 3 維神經網絡,序列類的數據處理是 1 維的 CNN主要應用,2 維 CNN 經常用于對于文本的識別,3維神經網絡主要應用在處理醫學圖像以及一些視頻數據。
如 圖 1 所 示,CNN 的整體結構是由輸入層(Import Layer)、卷積層(Convolution Layer)、池化層(Pooling Layer)、全連接層(Fully Connected Layer) 與 輸 出 層(Output Layer)按順序連接構成的,其中,卷積層和池化層可以在隱藏層出現多次。
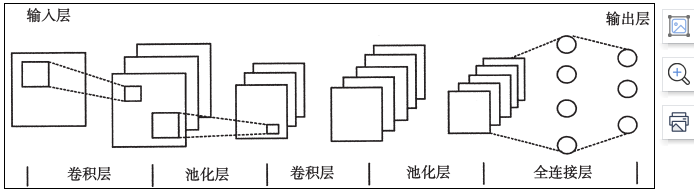
圖 1 CNN 結構
圖 1 的 CNN 結構與原始的 LeNet 類似,將輸入的圖像根據對應的類別進行分類,輸出層中所有概率的總和應為 1。卷積層內部包含多個卷積核,卷積核的各個元素對應有一個權重系數和偏差量。卷積層內每個神經元都與前一層位置接近的神經元相連。卷積層的功能是將輸入數據進行處理,得到相關特征,在工作時會有規律地掃過輸入特征,在前一層位置接近的區域內對輸入特征進行矩陣元素乘法求和并疊加偏差量。
池化層的作用是將經過卷積層處理后的特征進行選擇并進行信息過濾,再通過池化層預設的池化函數將單個點替換為相鄰區域的特征統計量。
CNN 中的全連接層等價于傳統前饋神經網絡的隱含層,全連接層位于神經網絡中的最后位置,信號只會傳遞給其他全連接層。全連接層的作用是將經過卷積層與池化層后的特征進行非線性組合得到輸出,將輸出結果傳遞給輸出層。
1.2 GRU 神經網絡
LSTM 中引入了 3 個門來控制網絡,輸出門控制輸入值,遺忘門控制記憶值,輸出門控制輸出值,而在 LSTM 的變體 GRU 中只需要更新門和重置門。由于 LSTM 具有 3 個功能各不相同的門,所以它的參數相對來說會比較多,在訓練時會比較困難。為解決這個問題,本文采用 GRU 的神經網絡,正如上文所述它只有兩個門,在解決 RNN 神經網絡長距離依賴問題上也能夠達到和 LSTM 一樣的效果,訓練易于實現。GRU 神經網絡的更新門可以看作將LSTM 的輸入門和遺忘門二者合一的結果,更新控制的是控制的前一時刻帶入的程度;重置門是控制前一時刻狀態代入候選集中的程度。GRU 的結構 [14]如圖 2 所示。

圖2 GRU 結構
圖 2 中 σ 為 sigmoid 激活函數,tanh 為另一個激活函數,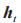 為序列輸出的當前狀態,
為序列輸出的當前狀態,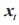 為序列輸入數據。相關公式為:
為序列輸入數據。相關公式為:
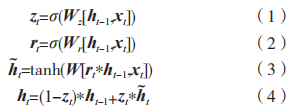
式中: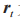 為重置門輸出;
為重置門輸出;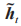 為候選狀態輸出;
為候選狀態輸出;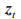 為更新門輸出;
為更新門輸出;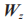 為更新門與隱含單元之間的連接權重;
為更新門與隱含單元之間的連接權重; 為序列上一時刻的輸出狀態;
為序列上一時刻的輸出狀態;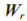 為重置門與隱含單元之間的連接權重;* 代表兩個矩陣相乘。
為重置門與隱含單元之間的連接權重;* 代表兩個矩陣相乘。
2權重縮減 GRU 神經網絡
權重縮減 GRU 神 經 網 絡(Weight reduction gated recurrent unit,WRGRU)是 GRU 神經網絡的一個變形,其主要使用 DropConnect 技術將動態稀疏性引入到神經網絡的連接權重上,使得每次迭代時神經網絡的權重參數規模得以縮減。DropConnect技術與神經元丟棄技術(Dropout)的不同之處在于,在每次迭代中神經元間每個連接權重被丟棄的概率為 p。在 WRGRU 中,為了避免過擬合現象的出現,隱含層單元間的權重參數被隨機地丟棄,WRGRU神經網絡的輸出 yt 可以被寫為:
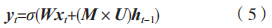
式中:M 為編碼連接信息的二進制矩陣;U 為神經網絡的權重參數矩陣。在訓練階段的每次迭代過程中,通過更改 M 中的元素可以實現對于神經網絡不同連接權重的丟棄。
3基于 CNN 與 WGRU 的網絡入侵檢測模型
使用混合深度學習模型進行數據流量的入侵分類, 并 將 CNN 與 WRGRU 相 結 合, 構 建 了 CNNWRGRU 模型。模型架構如圖 3 所示。與其他基于神經網絡的入侵檢測模型相比,該混合模型由于結合了 CNN 和 WRGRU 的優勢,因此可以更有效地進行入侵檢測。CNN-WRGRU 模型包含兩個 1 維卷積層,1 個 1 維的最大池化層,1 個 1 維的 WRGRU層和 1 個全連接層。ReLU 函數為兩個卷積層中的激活函數,其表達式為:

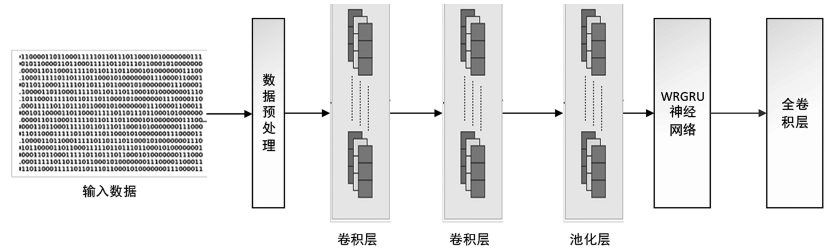
圖 3 CNN-WRGRU 模型結構
在 CNN-WRGRU 模型中,兩個 1 維的卷積層在進行特征提取后,提取的特征被傳輸至最大池化層,最大池化層的輸出又會被傳遞到 1 維 WRGRU層中進行提取的特征之間的依賴關系的提取,最后1 維 WRGRU 層的輸出被傳遞到全連接層。全連接層的激活函數為 softmax,利用該函數進行入侵類別概率分布的計算公式為:

式中: 和
和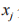 分別為類別 i 和 j 在經過模型計算后的數值;
分別為類別 i 和 j 在經過模型計算后的數值;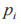 為類別 i 的判別概率。CNN-WRGRU 模型中的重要參數包括 CNN中 濾 波 器 的 數 量、 訓 練 次 數、 學 習 速 率, 以 及WRGRU 中隱含層單元的數量、連接權重丟失率drop-connect 的大小、批處理大小,所有這些參數在訓練階段通過試錯得到。
為類別 i 的判別概率。CNN-WRGRU 模型中的重要參數包括 CNN中 濾 波 器 的 數 量、 訓 練 次 數、 學 習 速 率, 以 及WRGRU 中隱含層單元的數量、連接權重丟失率drop-connect 的大小、批處理大小,所有這些參數在訓練階段通過試錯得到。
4仿真實驗
4.1 實驗數據
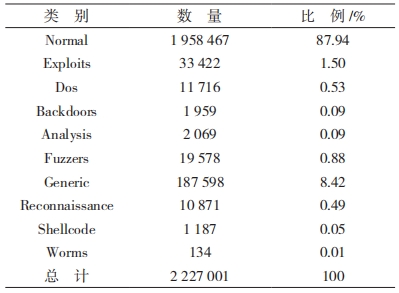
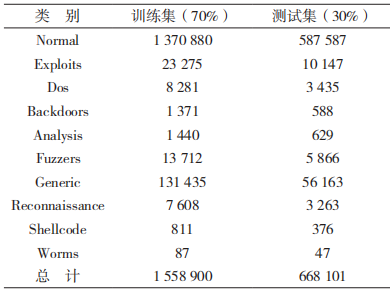
UNSW-NB15 是澳大利亞的新南威爾士大學于2015 年發布的用于網絡入侵檢測研究的開放數據集 [15]。UNSW-NB15 中包括 9 種攻擊類型和 1 種正常類型,各種類型所占比例如表 1 所示。UNSWNB15 數據集由 3 個名義特征、2 個二進制特征和37 個數值特征組成,UNSW-NB15 是按照時間順序進行排序記錄的,能夠充分代表數據之間的時序相關性。在實驗中,本文將 UNSW-NB15 數據集中的70% 用于訓練,30% 用于測試。表 2 說明了訓練集和測試集的分布。
表 1 各種類型數據所占比例
4.2 性能評估
為了評估 CNN-WRGRU 模 型 的 性 能, 利 用python 進行仿真實驗分析,采用準確率(Accuracy)、精度(Precision),召回率(Recall)和 F1 值作為評估指標。這些指標的計算方法如下:

式中:TP 為正樣本且分類正確的實例數量;TN 為負樣本且分類器識別正確實例的數量;FP 為負樣本且分類識別結果錯誤的實例數量;FN 為正樣本且分類識別結果錯誤的實例數量。
表 2 訓練集和測試集的分布
4.3 實驗對比分析
本文實驗在 CPU 為 i7 4510U,運行內存為8 GB,操作系統為 64 位 Windows 10 的筆記本電腦上進行。為了獲得 CNN-WRGRU 模型超參數的最佳設置,本文在模型訓練過程中為相關超參數選擇了初始值,然后對其進行動態調整,通過反復試驗獲得最佳結果。最終,當模型取得最佳檢測效果時,訓練次數為 50,學習率為 0.005,drop-connect 的大小為 0.1,第一層和第二層的卷積濾波器的數量分別為 32 和 64,最大池化長度為 2。
圖 4 給出了訓練中模型的準確率和損失,其中測試集被用于進行模型驗證。從中可以看出,CNN-WRGRU 模型在訓練中能夠穩定收斂,很好地抑制了模型的過度擬合。
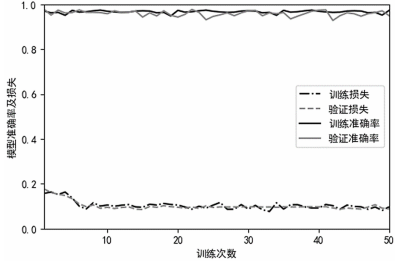
圖 4 模型在訓練階段的準確率及損失
表 3 模型在二元分類任務下的混淆矩陣

表 3 和表 4 分別為模型 CNN-WRGRU 在 UNSW-NB15 測試集上執行二元分類任務得到的正常和異常樣本的混淆矩陣,執行多元分類任務得到的所有分類的混淆矩陣。從表 3 中可以看出,該模型在執行二元分類任務時對測試集中的 649 336 個樣本進行了正確分類;表 4 中可以看出,該模型在執行多元分類任務時對 657 612 個樣本進行了正確分類。
表 4 模型在執行多元分類下的混淆矩陣
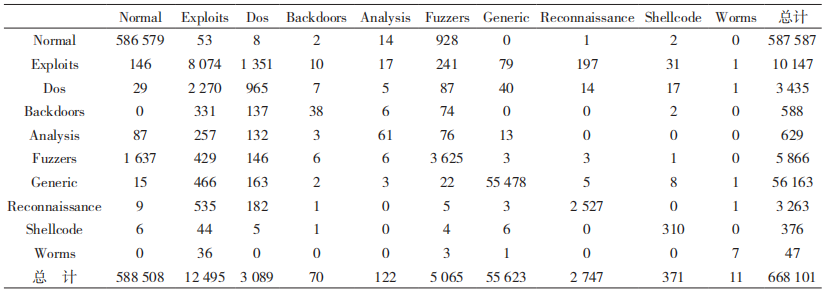
表 5 和表 6 分別給出了模型 CNN-WRGRU 在執行二元分類任務和多元分類任務時的性能指標值。
表 5 模型在二元分類任務下的性能指標
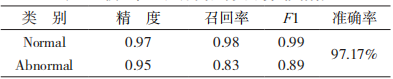
表 6 模型在二元分類任務下的性能指標
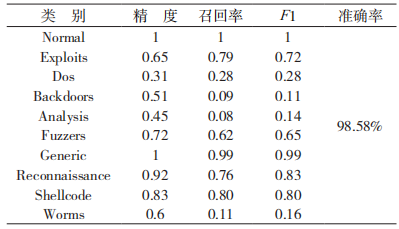
如表 5 和表 6 所示,模型 CNN-WRGRU 在二元分類和多元分類下的總體準確率分別為 97.17%和 98.58%。對于指標 F1-score,模型在 generic、reconnaissance、shellcode 和 exploit 4種類別數據上的結果分別為 0.99、0.83、0.80 和 0.72;對于稀有的類別數據(Shellcode、Backdoors、Analysis),由于數據規模不足,模型 CNN-WRGRU 的檢測效果較差。總體而言,隨著不同類別的數據分布存在不平衡現象,但是 CNN-WRGRU 模型仍取得了非常好的檢測結果。表7 給出了CNN-WRGRU 模型與TSDL、KDDwinne、CSVAC、CPSO-SVM、Dendron[19]模型在 UNSW-NB15 數據集上分別執行二元分類時的準確率結果。由表 7 中的對比結果可以看出,CNN-WRGRU 模型由于能夠從大量訓練數據中提取到更為準確的特征表示,相較于其他模型在進行入侵檢測時更為有效。
表 7 CNN-WRGRU 模型與其他模型的入侵檢測準確率

表 8 給出了 CNN-WRGRU 模型與其他 5 種模型在UNSW-NB15數據集上每條數據的平均執行時間。
如表 8 所示,CNN-WRGRU 模型的平均執行時間非常低(略低于 TSDL 模型),非常適合實時的入侵檢測。這主要是因為該模型能夠在離線模式下定期訓練最新的網絡流量特征,并且能夠檢測入侵攻擊在線模式。
表 8 每條數據的平均檢測執行時間

5 結 語
本文將 CNN 與權重縮減 GRU 神經網絡結合起來,提出了一種基于 CNN 與 WRGRU 的網絡入侵檢測模型(CNN-WRGRU)。該模型利用 CNN 進行入侵檢測數據集的特征提取,然后利用 WRGRU來學習數據特征之間的依賴關系。WRGRU 由于在訓練過程中使用 dropout 技術隨機地忽略了一些神經元,使得模型可以有效避免過擬合問題的出現。在實驗時,本文利用 TSDL、KDDwinner、CSVAC、CPSO-SVM、Dendron、CNN-WRGRU 等模型在UNSW-NB15 數據集上進行對比仿真實驗,結果表明:CNN-WRGRU 模型具有最好的識別精度。
CNN-WRGRU 模型在 UNSW-NB15 上雖具有較好的識別效果,但是在實際應用中還有若干問題有待解決,如入侵檢測的實時性,以及在具有更大規模的數據集上的有效性,這些問題都有待進一步研究。
引用本文:王運兵 , 姬少培 , 查成超 . 基于 CNN 與 WRGRU 的網絡入侵檢測模型 [J]. 通信技術 ,2022,55(4):486-492.
