差分隱私實戰-以保護新冠數據隱私為例
隨著AI技術的進步,攻擊AI的技術也越來越多,包括對抗樣本、后門攻擊等,這些是針對模型安全而言的,在數據層面,攻擊者甚至可以通過攻擊竊取訓練集中的個人隱私數據,為此,安全研究人員提出將差分隱私應用于AI,以保護AI的訓練集中樣本的隱私;在另一方面,借助差分隱私技術也可以促進各方的交流,避免數據孤島。在本文中,我們將以設想的新冠疫情下醫院之間互助的場景為例,通過實戰介紹PATE技術在利用AI賦能醫療行業的同時保護患者個人隱私。
場 景
由于新冠疫情的流行,由大量的病人拍攝的CT等待被醫生分析、診斷,我們嘗試在自己的醫院里創建一個二分類的圖像分類器,可以根據CT圖像判斷病人的是否得了新冠(陽性或陰性)。但是我們的CT圖像是沒有標記的,這意味著不能做監督學習。而有5家醫院有有標記的數據(醫生已經看過CT并給出結論了),并且愿意幫助我們這家醫院,可是如果直接把這些數據分享給我們,會侵犯病人的隱私,同時可能違反一些數據保護相關的法律法規。此時我們的目標是在為我們醫院構建深度學習模型的同事,保護這5家醫院的隱私,那么具體該怎么做呢?
背景知識
我們用到稱為差分隱私的方法。什么是差分隱私呢?
差分隱私確保統計分析不會損害隱私。它確保個人的數據對整個模型輸出的影響是有限的。換句話說,不論是否包括數據集中特定個體的數據,算法的輸出幾乎是相同的。
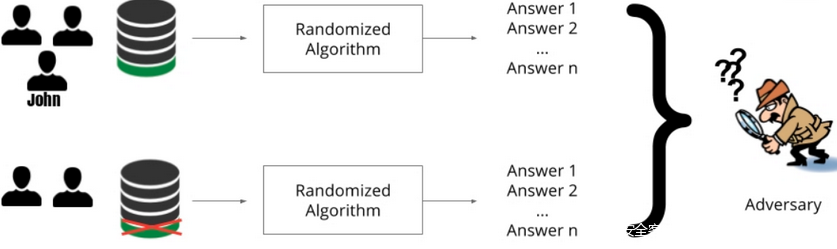
如上圖所示,John 的信息出現在第一個數據集中,不在第二個數據集中,但是模型輸出是相同的,所以想要獲得 John 的數據的對手不能確定數據集中是否存在 John,更不用說數據的內容了。因此,John的隱私得到了保障。
差分隱私通常通過在模型或統計查詢的輸入層(本地差分隱私)或輸出層(全局差分隱私)添加統計噪聲來工作。增加的噪聲保證了個人對決策結果的貢獻被隱藏起來,但在不犧牲個人隱私的情況下獲得了對整體的深入了解。
噪聲的大小取決于一個稱為privact budget(隱私預算)的參數,這個參數通常用ε表示。ε的值越小(即添加的噪聲越多) ,它提供的隱私就越高,反之亦然。如下圖所示,我們可以看到,隨著越來越多的噪聲被添加到臉部圖像,它得到的匿名信息越多,但它變得越來越不可用。因此,選擇正確的ε值非常重要,需要在可用性與隱私之間做好權衡。

在本文中我們使用的隱私方法叫做PATE(Private Aggregation of Teacher Ensembles)。
PATE的工作流程如下:
首先在不相交的訓練集上分別訓練得到幾個模型,稱為教師模型。然后將一個輸入交給這些教師模型預測,教師模型預測得到各自的類標簽,最終以所以教師模型輸出的總和作為最終的預測類。不過這一步會分為兩種情況:1.如果所有或者大多數教師模型的預測都是相同的,那么最終應該輸出什么類就很容易知道了。這意味著不會泄露任何單個訓練樣本的私有信息,因為如果從某個數據集中刪除任何訓練樣本,不會影響模型最后的輸出。在這種情況下,privacy budget很低,算法滿足差分隱私;2.如果各個教師模型給出的預測不一致,則privacy budget很高,這會讓最終應該給出什么預測變得不那么直接,并最終導致隱私泄露。為了解決這個問題,我們可以使用Report Noisy Max(RNM算法),它會在每個模型的輸出中添加隨機噪聲。通過這種方法可以提供一種強力的隱私保護。這種情況下,算法滿足了完全意義下的差分隱私。
但是PATE不限于此,它還額外增加了隱私。可能有些人會覺得將教師模型聚合在一起用于推理就可以了,但是這是不行的,原因有兩點:
1.每次我們做出預測,privacy budget就會增加,所以遲早都會達到一個點,那時候隱私是一定會泄露的
2.通過多次查詢,攻擊者可以獲取教師模型的訓練數據,這時隱私也完全泄漏了
所以我們不能簡單的聚合,而需要創建一個學生模型。學生模型使用的訓練集是沒有標簽的(如場景部分中提到的我們的醫院),我們把訓練集中的數據交給教師模型來預測,通過教師模型打標簽,一旦打上標簽,教師模型就可以被丟棄了。此時學生模型已經可以訓練了,訓練完畢后它實際上從教師模型中學習了有價值的信息。最重要的是,privacy budget不會隨著學生模型每次查詢而增加,而且在最壞的情況下,攻擊者只能得到教師模型給出的帶噪聲的標簽。
場景應用
回到我們的場景中來,我們希望為自己的醫院訓練一個分類器,用于判斷病人是否患了新冠。我們只有一些未標記的CT圖像,現在需要其他5家醫院的數據來標記你的數據集,但是出于隱私原因,我們不能直接訪問那5家醫院的數據。在聊了上一節的知識后,我們決定按照如下步驟進行處理:
1.讓這5家醫院各自在自己的數據集上訓練模型,完成這一步后,得到了5個教師模型
2.使用這5個教師模型,為我們醫院的每張CT圖像生成5個標簽
3.為了保護教師訓練集的隱私,可以對生成的標簽應用RNM算法。對于每張CT圖像,我們獲得生成的5個標簽中最頻繁的標簽,然后添加噪聲實現差分隱私
4.使用帶噪聲的標簽訓練學生模型(我們醫院自己的模型),將其部署在自己的醫院中用于診斷。
數據集
沒有多少開源數據集可以用于新冠病毒診斷,為了保護患者隱私,獲取這些數據集是不容易的。不過github上開源了一部分,地址在這里:https://github.com/UCSD-AI4H/COVID-CT,中國武漢同濟醫院的一位高級放射科醫生已經證實了該數據集的實用性。
在Images_Processed文件夾下有兩個文件夾,分別是COVID和Non-COVID,對應存放的是確診有新冠的和沒有新冠的片子。在Data_Split文件夾下是圖像的標簽。為了后續編程方便,可以將Image_Processe和Data_Split分別改為Image,labels
創新數據集
在labels文件夾下同樣可以看到COVID和Non-COVID,每個子文件下都有test,train,val,分別是測試集、訓練集、驗證集。
現在我們要模擬的場景是教師模型有私有數據(打上標簽的),學生只有公開的沒有標簽的數據,所以我們可以將這里的訓練集作為教師模型的新聯數據集,將測試集作為學生模型的訓練數據集,然后使用驗證集來分別測試學生模型和正常模型(不通過差分隱私訓練得到的模型)的性能。
首先創建一個自定義的dataset loader,創建數據轉換,并最終加載數據
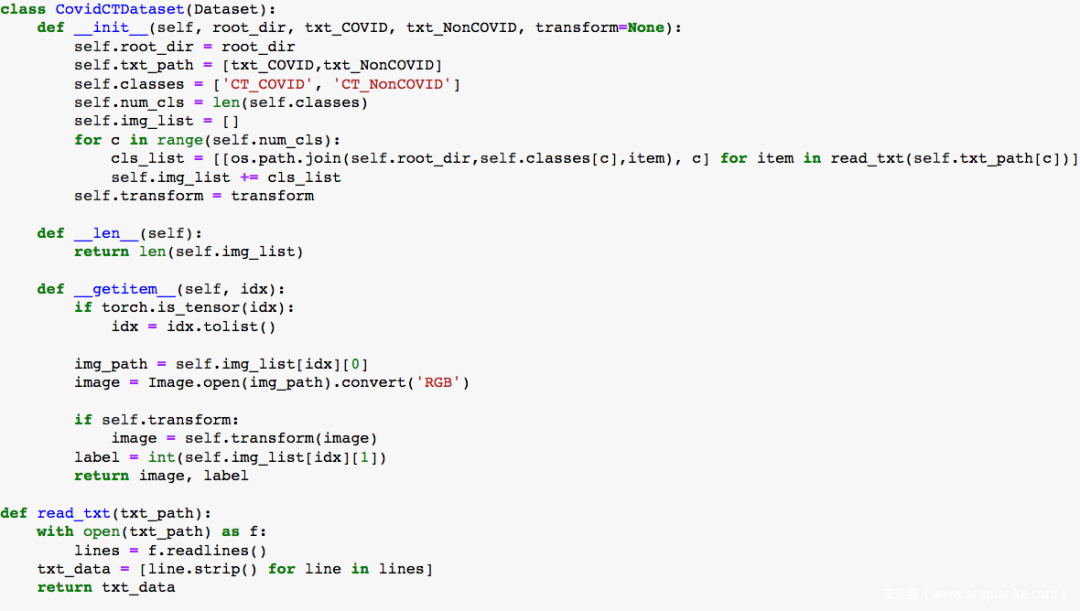
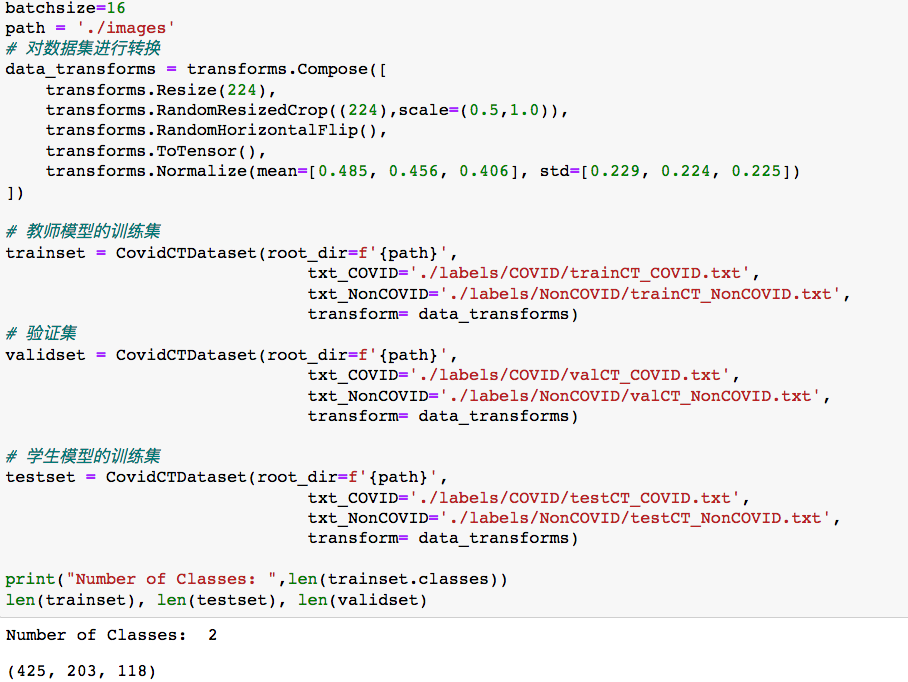
在成功加載數據后,可以可視化部分樣本
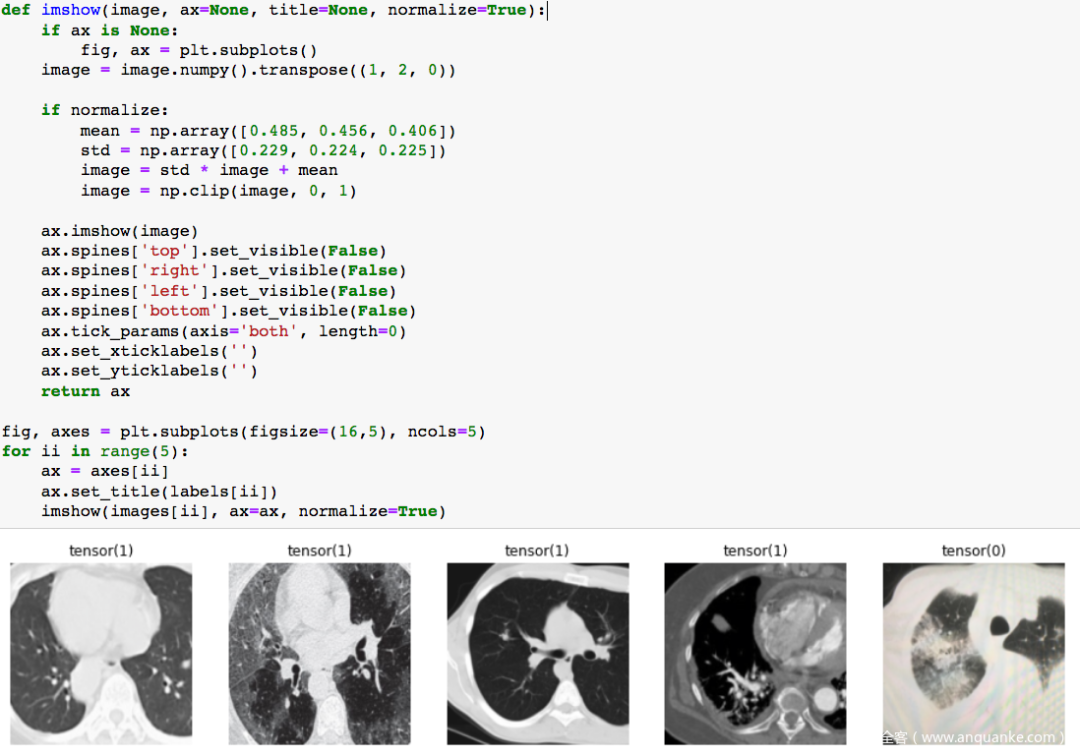
我們現在可以繼續在5家醫院之間劃分訓練集。5家醫院,對應著5個教師模型,這里需要注意,數據集必須是不相交的,也就是說,任何2個數據集都不應該有重疊的訓練樣本。前面已經說過,差分隱私中,如果個人的數據被從數據集中刪除,數據集的輸出仍然是相同的,以為個人對數據集沒有貢獻。如果有某一個人的副本,即使刪除其中的一個副本,個人的數據仍然有助于輸出,這樣就無法保護個人隱私。
所以在將訓練集劃為5個子集時,我們必須非常謹慎。
下面的代碼就是在5個教師模型或者說5個醫院之間劃分我們的訓練集,并為每一個教師模型創建訓練集dataloader和驗證集dataloader。
現在對于教師模型來說,有5個trainloader,5個validloader;接著我們為學生模型(我們自己的醫院)創建trainloader,validloader
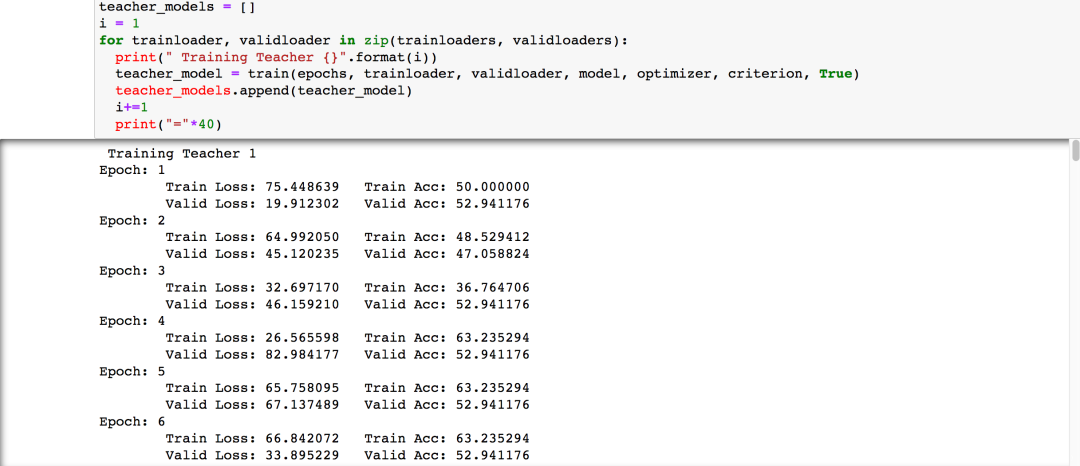
訓練教師模型
首先訓練教師模型,5家醫院會在不相交的數據集中訓練得到5個不同的模型
首先定義一個簡單的CNN模型
然后如下定義我們的訓練代碼

定義超參數,我們使用交叉熵損失CrossEntropyLoss和Adam優化器。
每個教師模型訓練50個epoch

然后開始訓練教師模型
獲取學生標簽
在訓練完成之后,我們得到了5個教師模型,使用這5個模型為學生模型生成標簽。這5個模型中的每個模型都會為我們(學生)數據集中的每張圖片生成標簽。換句話說,對于學生模型的數據集來說,其中的每張圖片都有5個生成的標簽。
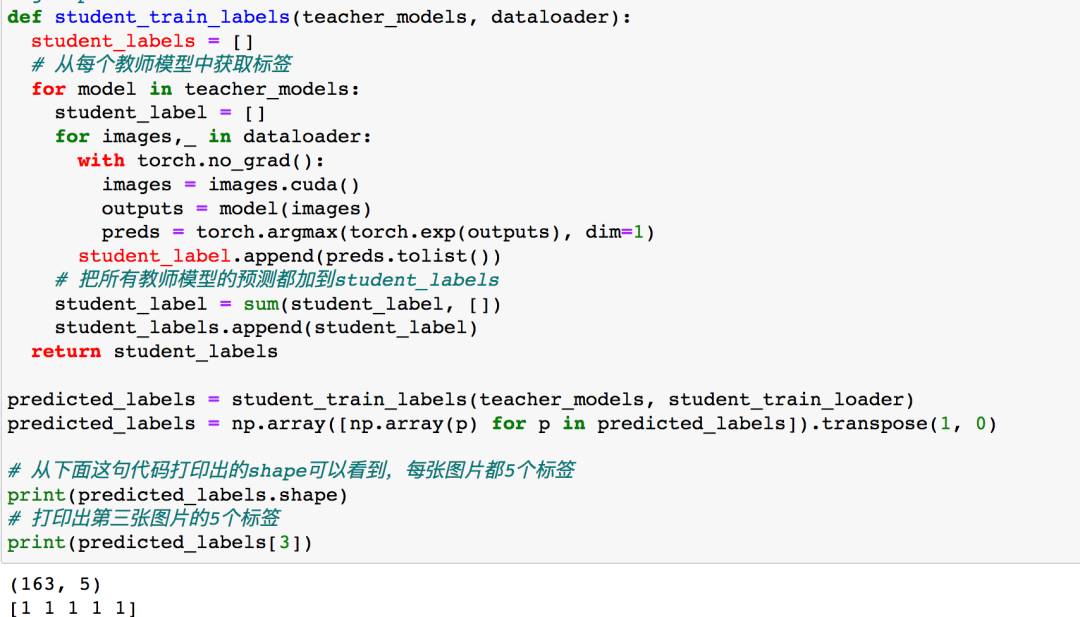
(163,5)的意思是說,在學生模型的數據中有163個訓練樣本,5個教師模型為每個樣本生成了5個標簽。第三張CT圖片的預測標簽為5個1,說明5個教師模型都認為這是新冠陽性。如果是[1,1,1,0,0]則表示兩個教師模型認為這是陰性,三個教師模型認為這是陽性,此時我們以多數原則為依據,認為這是陽性。
添加拉普拉斯噪聲
我們在模型訓練之后添加被廣泛使用的拉普拉斯噪聲,這可以保證不會泄露超過的信息。我們定義了add_noise,其將預測的標簽和值作為輸入,我們可以使用控制添加的噪聲量


我們把這些標簽保存下來就可以了,訓練好的教師模型已經用不到了

PATE分析
我們知道,這些標簽實際上是來自于私人信息的,所以這些新標簽中可能包含一定數量的泄露信息。泄露的信息量在很大程度上取決于添加的噪聲量,這是由決定的。所以選擇合適的很重要,我們可以使用PATE進行分析。它實際上可以告訴我們,如果發布這些標簽,會有多少信息通過這些標簽泄露。
我們使用perform_analysis方法,以所有教師模型的預測標簽列表和我們剛剛計算的帶噪聲的新標簽作為輸入,并返回兩個值:data_dep_eps,data_ind_eps,分別表示數據相關的和數據無關的。Perform_analysis目的在于告訴我們教師模型之間的一致性水平。data_ind_eps的表示在最壞情況下可能泄露的最大信息量,而data_dep_eps的表示教師模型的決策的一致性程度。一個小的data_dep_eps的表明,教師模型的預測具有很高的一致性,并且浙西模型沒有記憶私人信息(過度擬合)。因此,小的data_dep_eps的表示較小的隱私泄漏率。在試驗了不同的值以及noise_eps變量后,我們設=0.1,得到的結果如下

可以看到,我們得到的data_dep_eps的是15.536462732485106,data_ind_eps的是15.536462732485116
訓練學生模型
現在已經從教師模型那里得到了帶噪聲的標簽,現在就可以開始訓練了。在訓練之前需要用來自教師模型的新標簽替換掉舊的學生的dataloader(其中包含著我們下載數據集的時候附帶的原始標簽,當然,在實際情況下我們是不可能有原始標簽的,所以實際中是沒有這一步的)

接著訓練學生模型。我們使用換成新標簽的trainloader進行訓練,并使用validloader的數據集評估模型的性能。我們使用和教師模型相同的CNN架構以及超參數。
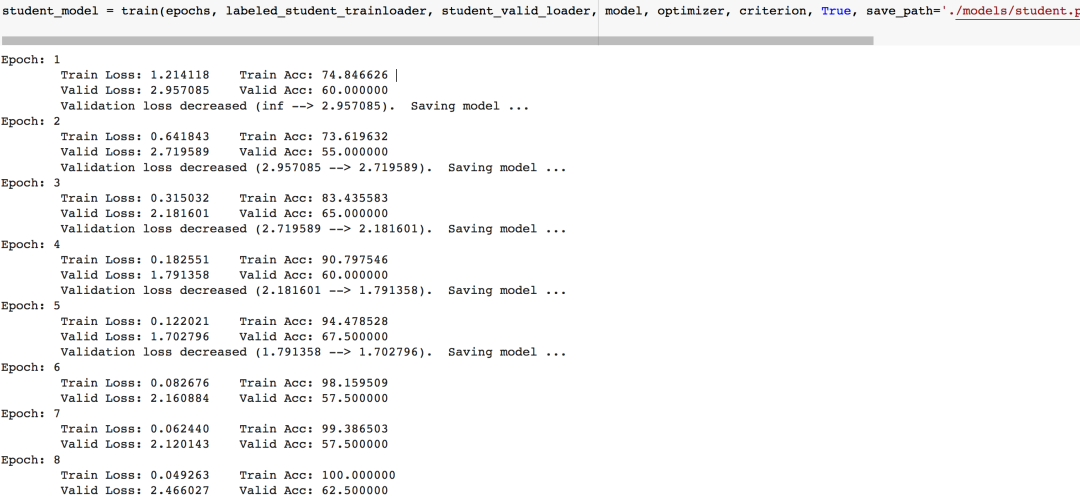
同時再訓練一個使用原始標簽的trainloader的數據的模型
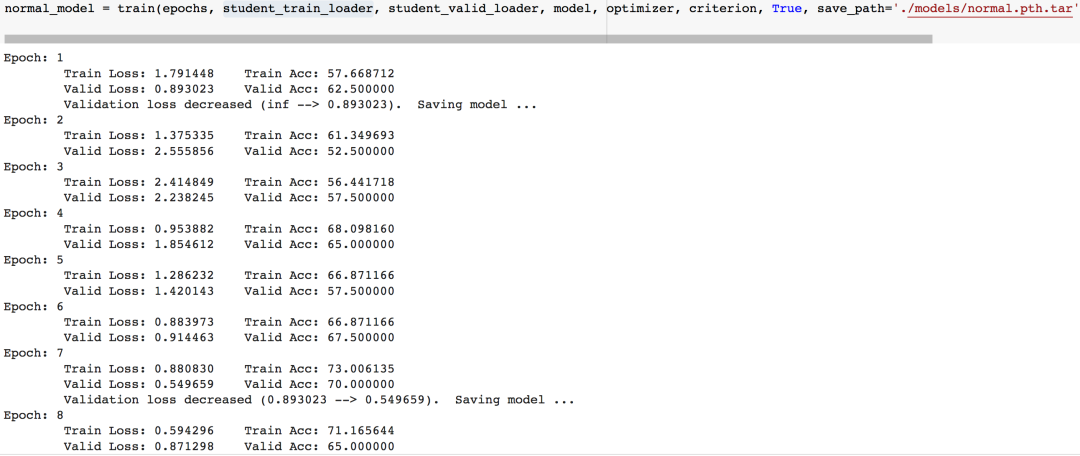
注意,這兩個模型只有所用的數據集的標簽是不同的
訓練完成后,在測試集上比較這兩個模型的性能

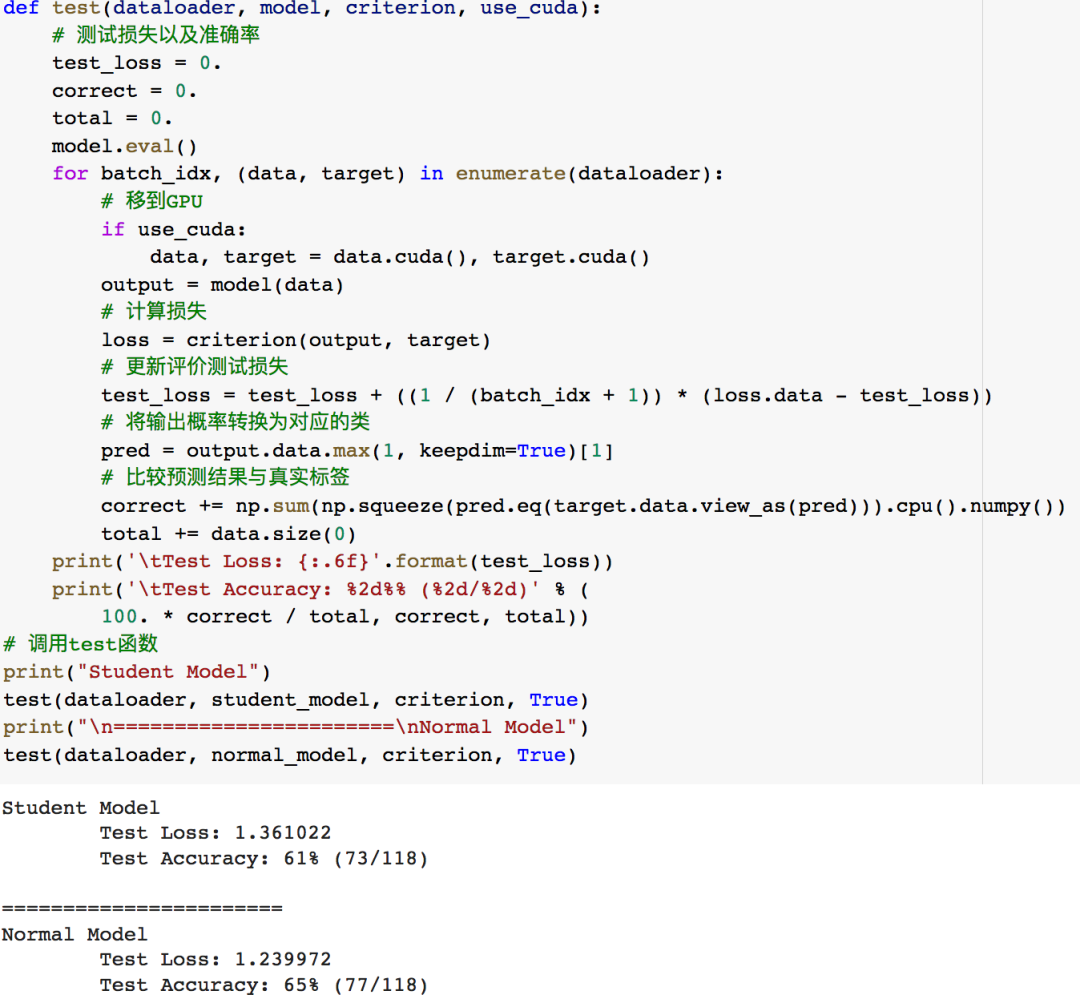
可以看到,學生模型的準確率稍微低于正常訓練的模型,原因包括教師模型預測的偏差、添加的噪聲等等,在不犧牲隱私、不違反數據隱私保護法律的情況下我們可以為5家醫院之外的其他醫院訓練出一個學生模型,可以提升醫療效率,拯救更多的生命。
總結
我們在本文中利用差分隱私保護方案PATE,以設想的醫院互助場景為例,在保護患者隱私數據的情況下,實現了在未標記CT圖像數據集上的訓練,得到了不錯的結果。
